第4次实践作业
第四次系统综合实践作业
一、使用Docker-compose实现Tomcat+Nginx负载均衡
(0) 要求
理解nginx反向代理原理;
nginx代理tomcat集群,代理2个以上tomcat;
了解nginx的负载均衡策略,并至少实现nginx的2种负载均衡策略;
(1) nginx.conf
user nginx;
worker_processes 1;
error_log /var/log/nginx/error.log warn;
pid /var/run/nginx.pid;
events {
worker_connections 1024;
}
http {
server {
listen 80;
location / {
proxy_pass http://blance;
}
}
upstream blance{
server tomcat01:8080 weight=1;
server tomcat02:8080 weight=1;
server tomcat03:8080 weight=1;
}
include /etc/nginx/mime.types;
default_type application/octet-stream;
log_format main '$remote_addr - $remote_user [$time_local] "$request" '
'$status $body_bytes_sent "$http_referer" '
'"$http_user_agent" "$http_x_forwarded_for"';
access_log /var/log/nginx/access.log main;
sendfile on;
#tcp_nopush on;
keepalive_timeout 65;
#gzip on;
include /etc/nginx/conf.d/*.conf;
}
重点内容是负载均衡的配置,负载均衡有不同的策略
1) 轮询
轮询是默认的方法。
server {
listen 80;
location / {
proxy_pass http://blance;
}
}
upstream blance{
server tomcat01:8080;
server tomcat02:8080;
server tomcat03:8080;
}
2) weight(权重)
在轮询策略的基础上指定轮询的几率,权重越高分配到需要处理的请求越多
server {
listen 80;
location / {
proxy_pass http://blance;
}
}
upstream blance{
server tomcat01:8080 weight=1;
server tomcat02:8080 weight=1;
server tomcat03:8080 weight=1;
}
这里写的权重相等情况下和轮询效果是一样的。
(2) index.jsp
内容任意,写下面的内容主要目的是区分我访问到的是哪一个tomcat主机
<%@ page language="java" contentType="text/html; charset=utf-8" import="java.net.InetAddress"
pageEncoding="utf-8"%>
<!DOCTYPE html PUBLIC "-//W3C//DTD HTML 4.01 Transitional//EN" "http://www.w3.org/TR/html4/loose.dtd">
<html>
<head>
<meta http-equiv="Content-Type" content="text/html; charset=utf-8">
<title>Tomcat+Nginx负载均衡</title>
</head>
<body>
<%
InetAddress addr = InetAddress.getLocalHost();
out.println("主机地址:"+addr.getHostAddress()+"<br/>");
out.println("主机名:"+addr.getHostName()+"<br/>");
out.println("031702426 朱庆章");
%>
</body>
</html>
(3) docker-compose.yml
version: "3"
services:
tomcat01:
image: tomcat:8.5.0
ports:
- "8081:8080"
restart: "always"
container_name: tomcat01
hostname: tomcat01
volumes:
- ./index.jsp:/usr/local/tomcat/webapps/ROOT/index.jsp
tomcat02:
image: tomcat:8.5.0
ports:
- "8082:8080"
restart: "always"
container_name: tomcat02
hostname: tomcat02
volumes:
- ./index.jsp:/usr/local/tomcat/webapps/ROOT/index.jsp
tomcat03:
image: tomcat:8.5.0
ports:
- "8083:8080"
restart: "always"
container_name: tomcat03
hostname: tomcat03
volumes:
- ./index.jsp:/usr/local/tomcat/webapps/ROOT/index.jsp
nginx:
image: nginx
container_name: nginx_tomcat
volumes:
- ./nginx.conf:/etc/nginx/nginx.conf
ports:
- "81:80"
links:
- tomcat01:tomcat01
- tomcat02:tomcat02
- tomcat03:tomcat03
主要注意:
1.tomcat服务的容器名container_name在nginx.conf中负载均衡将会被用到,请注意这两个文件中使用一致。
2.restart: "always"参数能够使我们在重启docker时,自动启动相关容器,虽然这在这个实验中意义不大,但在实际生产使用
中还是有必要的。
(4) 运行
文件结构如下:
cd到工作目录
docker-compose up -d

可以看到四个容器都启动了

浏览器访问http://127.0.0.1:81/
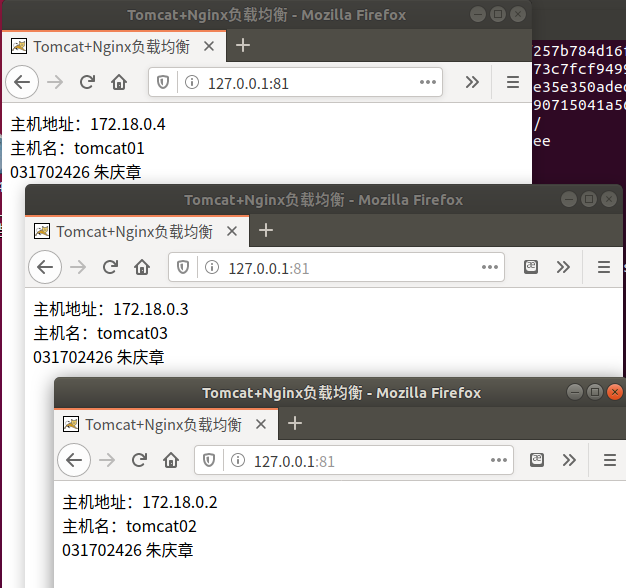
可以看到是不同的服务器在响应请求。
二、使用Docker-compose部署javaweb运行环境
参考链接: (https://blog.csdn.net/weixin_41043145/article/details/92834784#)
(0) 要求
分别构建tomcat、数据库等镜像服务;
成功部署Javaweb程序,包含简单的数据库操作;
为上述环境添加nginx反向代理服务,实现负载均衡。
(0.5) 准备
首先下载参考链接的工程,解压放到用户主目录
(1) docker-compose.yml
在原文件的基础上修改内容
version: "3"
services:
tomcat1:
image: tomcat:8.5.0
container_name: tomcat1
volumes:
- ./webapps:/usr/local/tomcat/webapps
networks: #网络设置静态IP
webnet:
ipv4_address: 15.22.0.15
tomcat2:
image: tomcat:8.5.0
container_name: tomcat2
volumes:
- ./webapps:/usr/local/tomcat/webapps
networks: #网络设置静态IP
webnet:
ipv4_address: 15.22.0.16
mysql:
build: .
image: mysql
container_name: mysql
ports:
- "13306:3306"
command: [ #设置编码模式
'--character-set-server=utf8mb4',
'--collation-server=utf8mb4_unicode_ci'
]
environment:
MYSQL_ROOT_PASSWORD: "123456" #root密码
networks: #网络设置静态IP
webnet:
ipv4_address: 15.22.0.6
nginx:
image: nginx
container_name: mynginx
ports:
- 80:2426 #注意和nginx的配置文件listen端口相对应
volumes:
- ./default.conf:/etc/nginx/conf.d/default.conf #挂载配置文件
depends_on:
- tomcat1
- tomcat2
tty: true
stdin_open: true
networks:
webnet:
ipv4_address: 15.22.0.7
networks: #网络设置
webnet:
driver: bridge #网桥模式
ipam:
config:
-
subnet: 15.22.0.0/24 #子网
(2) default.conf
这项文件在原作者目录中并没有,请新建一个
upstream blance {
server tomcat1:8080;
server tomcat2:8080;
}
server {
listen 2426; #这里监听端口注意与docker-compose里nginx服务的ports相对应
server_name localhost;
location / {
root /usr/share/nginx/html;
index index.html index.htm;
proxy_pass http://blance;
}
}
(3) 修改数据库连接IP
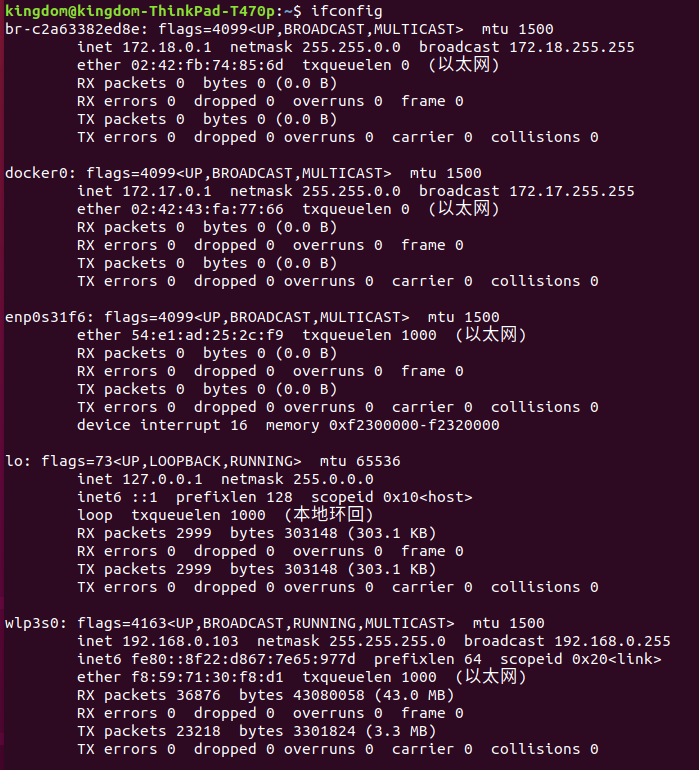
通过ifconfig查询本机IP地址
可以看到本机IP为192.168.0.103
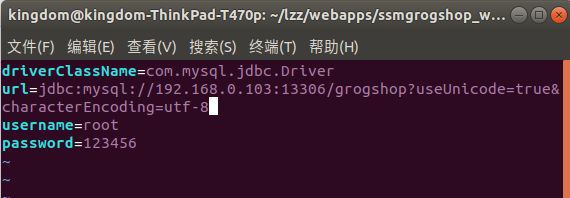
然后cd进入到
cd ~/lzz/webapps/ssmgrogshop_war/WEB-INF/classes
vim jdbc.properties
将连接数据库地址改为你的IP:端口号 (端口号要与docker-compose里的端口号相对应)
(4) 运行
文件目录如下

docker-compose up -d

打开网页
http://localhost/ssmgrogshop_war/
即可访问
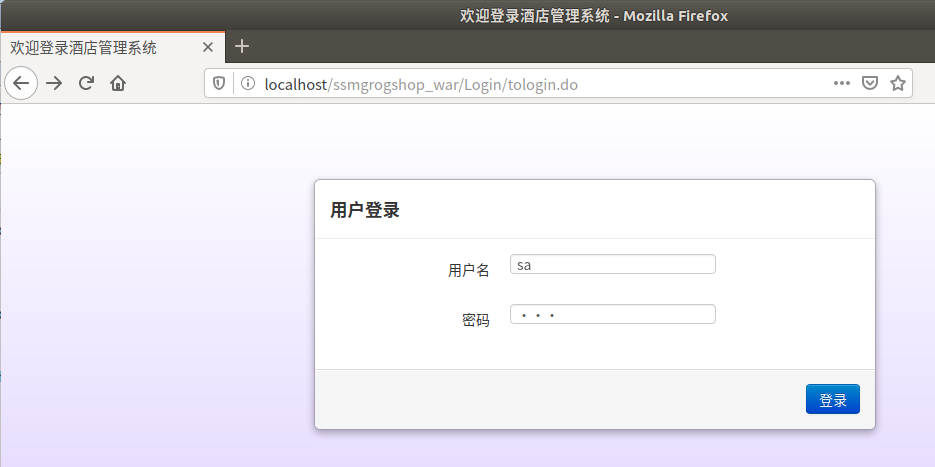
账号为sa
密码为123

三、使用Docker搭建大数据集群环境
直接用机器搭建Hadoop集群,会因为不同机器配置等的差异,遇到各种各样的问题;也可以尝试用多个虚拟机搭建,但是这样对计算机的性能要求比较高,通常无法负载足够的节点数;使用Docker搭建Hadoop集群,将Hadoop集群运行在Docker容器中,使Hadoop开发者能够快速便捷地在本机搭建多节点的Hadoop集群。
(0) 要求
完成hadoop分布式集群环境配置,至少包含三个节点(一个master,两个slave);
成功运行hadoop 自带的测试实例
(1) 拉取Ubuntu、换源、安装配置JDK、ssh、vim并生成镜像
1) 拉取Ubuntu
docker pull ubuntu:18.04
运行Ubuntu
docker run -it -v /home/kingdom/WorkPath:/root/build --name ubuntu ubuntu:18.04
-v 参数 :docker内部的ubuntu系统/root/build目录与本地/home/kingdom/WorkPath共享;方便将本地文件上传到Docker内部的Ubuntu系统;
更新系统源
apt-get update
2) 安装vim
apt-get install vim
3) ssh
安装ssh
apt-get install ssh
开启sshd
/etc/init.d/ssh start

可以将sshd的启动命令写进~/.bashrc文件,每次登录Ubuntu系统时,都能自动启动sshd服务
vim ~/.bashrc
将下面内容添加到文件最后一行
/etc/init.d/ssh start
配置ssh
ssh-keygen -t rsa
三个回车
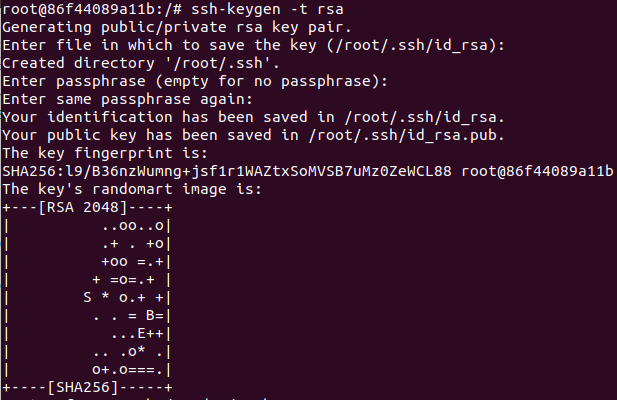
授权
cd ~/.ssh
cat id_rsa.pub >> authorized_keys
这样就可以免密登录了
4) 安装JDK
apt-get install openjdk-8-jdk
请注意版本,按照教程的方法可能会安装到其他版本的JDK,但是hadoop版本与jdk版本是有关的,不可以随意
加入环境变量
vim ~/.bashrc
将这段加入文件末尾
export JAVA_HOME=/usr/lib/jvm/java-8-openjdk-amd64/
export PATH=$PATH:$JAVA_HOME/bin
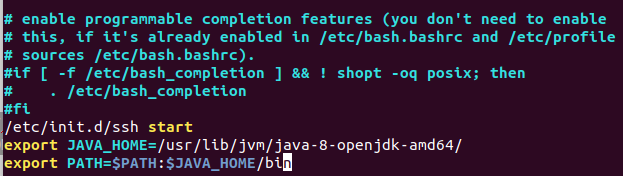
然后使用source命令使之生效
source ~/.bashrc
可以用java -version来检查环境变量是否配好

5) commit镜像
打开一个新的终端,通过docker ps -a查询到刚刚这个容器ID,然后commit
docker commit 86f44089a11b ubuntu-jdk

通过docker images查看
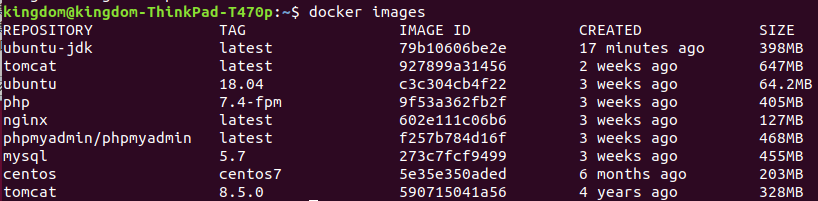
可以把之前的容器exit掉了
(2) 安装Hadoop
首先通过刚刚commit的镜像运行起一个容器
docker run -it -v /home/kingdom/WorkPath:/root/build --name ubuntu-jdk ubuntu-jdk
在WorkPath目录中放入下载好的hadoop安装包,它将会被同步到容器的/root/build目录中
将它解压到/usr/local目录下
cd /root/build
tar -zxvf hadoop-3.1.3.tar.gz -C /usr/local
然后进入到解压目录,尝试执行下检查是否安装成功
cd /usr/local/hadoop-3.1.3/
./bin/hadoop version

(3) 配置Hadoop集群
首先进入到存放配置文件的目录下
cd /usr/local/hadoop-3.1.3/etc/hadoop
1) hadoop-env.sh
原内容是全部注释的,在任意位置添加
export JAVA_HOME=/usr/lib/jvm/java-8-openjdk-amd64/
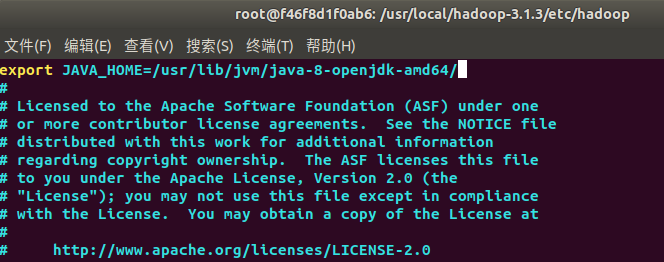
2) core-site.xml
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://master:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>file:/usr/local/hadoop-3.1.3/tmp</value>
<description>A base for other temporary derectories.</description>
</property>
</configuration>
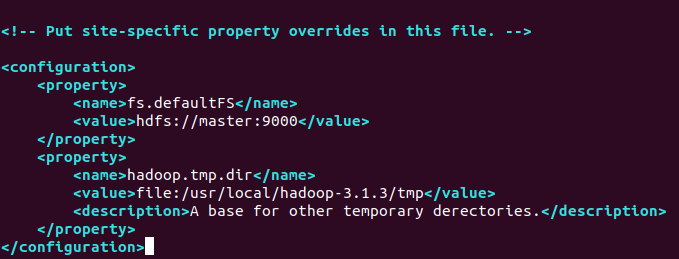
3) hdfs-site.xml
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/usr/local/hadoop-3.1.3/tmp/dfs/name</value>
</property>
<property>
<name>dfs.namenode.data.dir</name>
<value>file:/usr/local/hadoop-3.1.3/tmp/dfs/data</value>
</property>
</configuration>
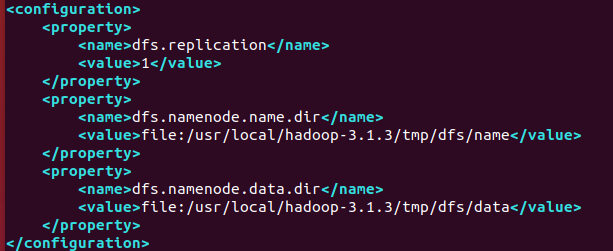
4) mapred-site.xml
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.jobhistory.address</name>
<value>master:10020</value>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>master:19888</value>
</property>
<property>
<name>mapreduce.application.classpath</name>
<value>/usr/local/hadoop-3.1.3/share/hadoop/mapreduce/lib/*,/usr/local/hadoop-3.1.3/share/hadoop/mapreduce/*</value>
</property>
</configuration>
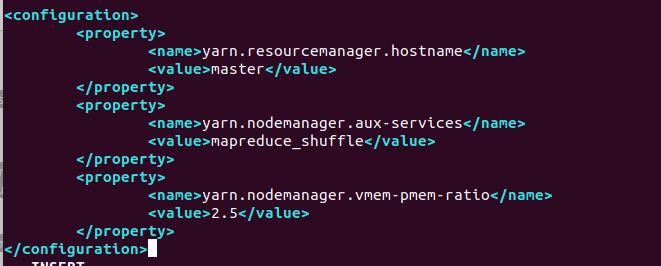
5) yarn-site.xml
<configuration>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>master</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.vmem-pmem-ratio</name>
<value>2.5</value>
</property>
</configuration>
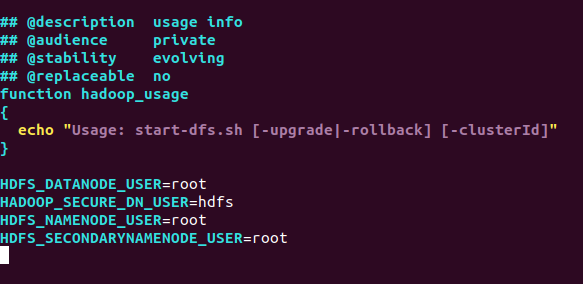
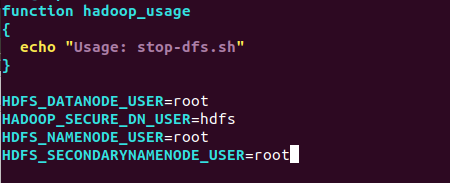
6) 配置.sh脚本文件
因为我们的容器默认是在root权限下跑Hadoop,按照原脚本的内容会出现错误,这里需要修改.
cd /usr/local/hadoop-3.1.3/sbin
将start-dfs.sh,stop-dfs.sh两个文件顶部添加以下参数
HDFS_DATANODE_USER=root
HADOOP_SECURE_DN_USER=hdfs
HDFS_NAMENODE_USER=root
HDFS_SECONDARYNAMENODE_USER=root
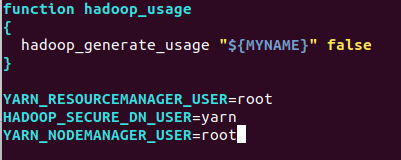
start-yarn.sh,stop-yarn.sh顶部也需添加以下
YARN_RESOURCEMANAGER_USER=root
HADOOP_SECURE_DN_USER=yarn
YARN_NODEMANAGER_USER=root
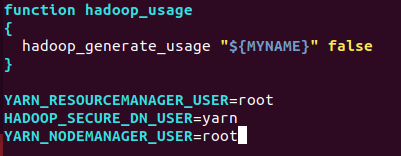
commit当前的容器
docker commit f46f8d1f0ab6 ubuntu-hadoop
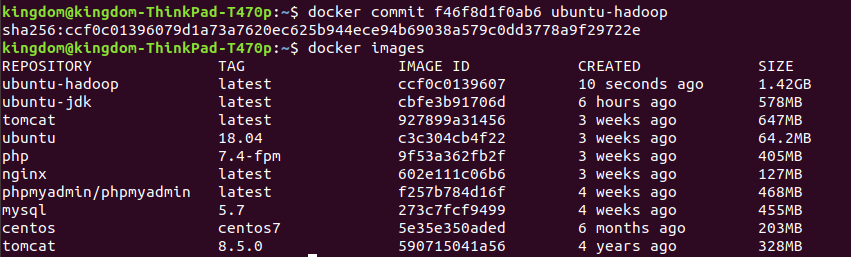
这时候可以把原来的容器exit了
(4) 运行Hadoop集群
1) 运行三个容器:master\slave01\slave02
需要打开三个终端,分别来从刚刚commit的ubuntu-hadoop镜像来运行三个容器
docker run -it -h master --name master ubuntu-hadoop
docker run -it -h slave01 --name slave01 ubuntu-hadoop
docker run -it -h slave02 --name slave02 ubuntu-hadoop
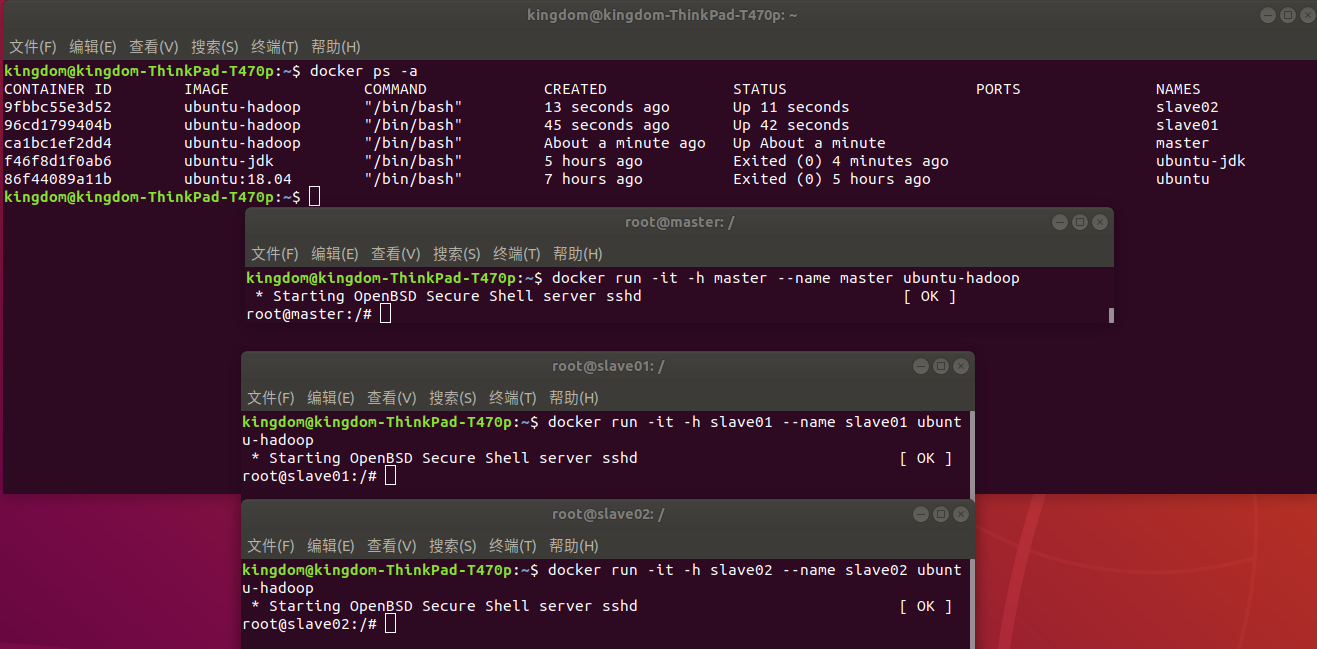
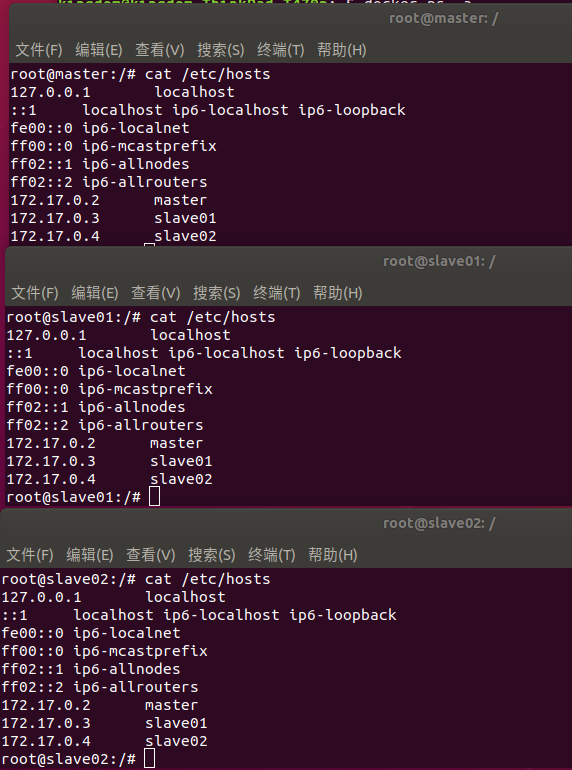
2) 修改hosts文件
查看一下各台机的IP
cat /etc/hosts

然后vim打开hosts文件,将三台机的IP对应主机名写入到各个host文件中,这样相互之间才可以根据主机名解析IP
'''
172.17.0.2 master
172.17.0.3 slave01
172.17.0.4 slave02
'''
写入后查看下
3) 尝试在master节点ssh登录到slave节点
在master结点测试ssh,分别登录到两个slave结点
请注意登录一个后记得exit退出
ssh slave01
登录到slave01并退出
登录到slave02并退出
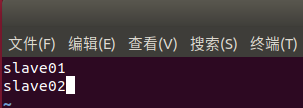
4) 修改master上workers文件
vim /usr/local/hadoop-3.1.3/etc/hadoop/workers
原内容仅有localhost,将原内容删除修改为
slave01
slave02
(5) 测试Hadoop集群
1)初始化(format)
在master节点
cd /usr/local/hadoop-3.1.3
然后执行初始化的format
bin/hdfs namenode -format
format会刷出很多信息
最下方
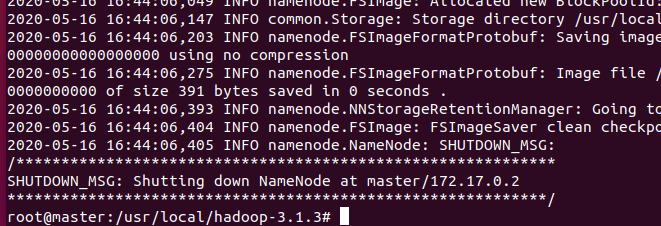
2) 启动服务
然后启动所有的服务
sbin/start-all.sh
当然这里你也可以分别启动各个服务,通过如下的方法
sbin/start-dfs.sh
sbin/start-yarn.sh
在你正确启动后,应该可以看到如下内容

这时候可以通过jps来分别查看各个节点是否启动了相应的服务
master节点:
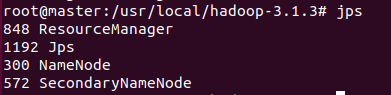
slave01节点:
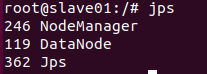
slave02节点:
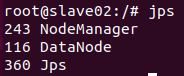
这说明相应服务都成功启动了。如果有服务没有启动说明你的配置有问题,或者是初始化的过程就出现问题了。
(6) 在Hadoop集群上测试样例
在master节点
1) 上传input文件
首先,创建相应的input目录
root@master:/usr/local/hadoop-3.1.3# bin/hdfs dfs -mkdir /user
root@master:/usr/local/hadoop-3.1.3# bin/hdfs dfs -mkdir /user/root
root@master:/usr/local/hadoop-3.1.3# bin/hdfs dfs -mkdir /user/root/input
root@master:/usr/local/hadoop-3.1.3# bin/hdfs dfs -ls -R /

然后cd到根目录随意新建一个txt文件用来测试wordcount样例
root@master:/usr/local/hadoop-3.1.3# cd /
root@master:/# vim testwordcount.txt
随意输入以下内容
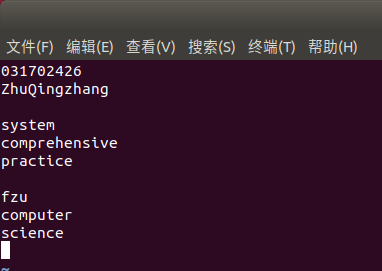
然后把它上传到刚刚创建的input目录
root@master:/# cd /usr/local/hadoop-3.1.3/
root@master:/usr/local/hadoop-3.1.3# bin/hdfs dfs -put /testwordcount.txt /user/root/input

2) 执行样例
运行程序
root@master:/usr/local/hadoop-3.1.3# bin/hadoop jar /usr/local/hadoop-3.1.3/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.1.3.jar wordcount /user/root/input /user/root/output

3) 查看结果
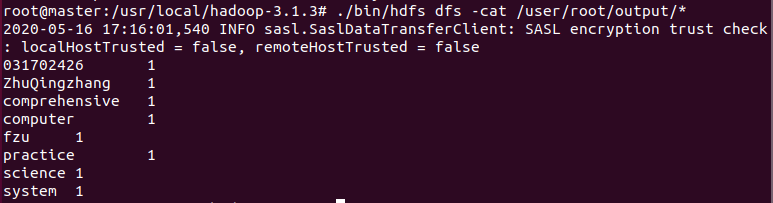
查看结果
root@master:/usr/local/hadoop-3.1.3# ./bin/hdfs dfs -cat /user/root/output/*
这是一个词数统计的样例
4) 关闭所有服务
root@master:/usr/local/hadoop-3.1.3# sbin/stop-all.sh
四、总结
(1) 遇到的问题
1) Java与Hadoop的版本适配问题
在老师给出的参考链接中,即(http://dblab.xmu.edu.cn/blog/1233/),关于jdk的安装,使用了apt-get install default-jdk的命令
这不仅会造成安装缓慢,而且这条命令所获取的jdk很可能并不是jdk-8。
例如,在我的环境中,这条命令将会安装jdk-7。
这就造成了问题,Hadoop的版本对于JDK的版本是有需求的,两者不匹配就会无法运行。
所以这里我安装jdk的时候直接指定了版本。
使用命令apt-get install openjdk-8-jdk
2) Hadoop样例运行的问题
这不是我自己遇到的问题,同学在样例运行时不能正常输出结果来问我。
原因是output目录不可以自行创建,output目录只能由程序自行创建。否则无法正常输出。
另外,建议运行时output目录写绝对路径。
(2) 用时
超过一整天的时间,大概一天半。原因是学习JavaWeb。但最终没有学成,使用了教程的样例工程。一周四门实践课,实在没时间了。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号