Python之生成器
一、生成器:
可以理解为一种数据类型,这种数据类型自动实现了迭代器协议(其他的数据类型需要调用自己内置的 _iter_ 方法),所以生成器就是可迭代对象
二、生成器分类以及在 Python 中的表现形式:(Python有两种不同的方式提供生成器)
1.生成器函数:常规函数定义,但是,使用 yield 语句而不是 return 语句返回结果。yield 语句一次返回一个结果,在每个结果中间,挂起函数的状态,以便下次重它离开的地方继续执行
2.生成器表达式:类似于列表推到,但是,生成器返回按需产生结果的一个对象,而不是一次构建一个结果列表
三、生成器的优点:
Python使用生成器对延迟操作提供了支持。所谓延迟操作,是指在需要的时候才产生结果,而不是立即产生结果,这也是生成器的主要好处
优点一、生成器的好处是延迟计算,一次返回一个结果,也就是说,它不会一次生成所有的结果,这对于大数据量处理,将非常有用
优点二、生成器还能有效提高代码的可读性
理由:
1.使用生成器以后,代码行数更少。大家要记住如果想把代码写的 PythonIC,在保证代码可读性的前提下,代码行数越少越好
2.不使用生成器的时候,对于每次结果。我们首先看到的是 result.append(index),其次,才是 index 。也就是说,我们每次看到的是一个列表的 append 操作。只是 append 我们想要的结果。使用生成器的时候,直接 yield index ,少了列表 append 操作的干扰,我们一眼就能看出,代码是要返回 index
四、生成器小结:
1、是可迭代对象
2、实现了延迟计算,省内存
3、生成器本质和其他数据类型一样,都是实现了迭代器协议,只不过生成器附上了一个延迟计算省内存的好处,其余的可迭代对象可都没有这点好处
五、生成器表达式
* 三元表达式(将简单的条件判断精简写):
变量 = 值一 if 条件一 else 值二
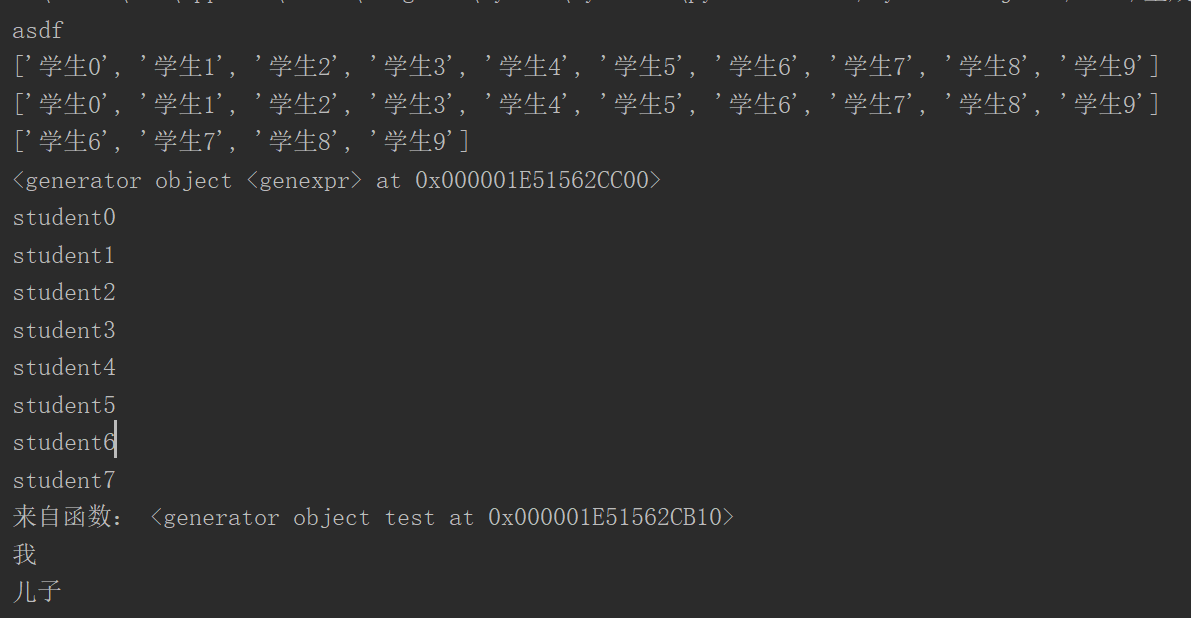
#!/usr/bin/env python # -*- coding:utf8 -*- # 三元表达式 # 主体):if name == 'alex',二元:res = 'as',三元(判断条件):else 'asdf' # 注意没有四元表达式 name = 'alex' name = 'sadfgsdfa' res = 'as' if name == 'alex' else 'asdf' print(res) #列表解析 student_list = [] for i in range(10): student_list.append('学生%s' %i) print(student_list) l1 = ['学生%s' %i for i in range(10)] l2 = ['学生%s' %i for i in range(10) if i>5] # l2_test = ['学生%s' %i for i in range(10) if i>5 else i] #没有四元表达式 #三元表达式: # 主体(一个for循环):for i in range(10),二元:'学生%s' %i,三元(判断条件):if i>5 print(l1) print(l2) # 生成器 SCQ = ('student%s' %i for i in range(10)) #生成器表达式 print(SCQ) print(SCQ.__next__()) print(SCQ.__next__()) print(SCQ.__next__()) print(next(SCQ)) print(next(SCQ)) print(next(SCQ)) print(next(SCQ)) print(next(SCQ)) # 定义函数 def test(): yield '我' yield '儿子' yield '孙子'
g = test() print('来自函数:',g) print(g.__next__()) print(g.__next__())
def S(): print('** 1 **') print('** 2 **') yield '我' print('** 3 **') yield '你' print('** 4 **') print('** 5 **') yield '他' res = S() print(res.__next__()) print(res.__next__()) print(res.__next__())

做包子案例:
# # 全部做好才返回: # def product_baozi(): # ret = [] # for i in range(100): # ret.append('包子%s' %i) # return ret # # baozi_list = product_baozi() # print(baozi_list) # # 做好一个就返回: def product_baozi(): for i in range(100): print('正在生产包子') yield '包子%s' %i print('开始卖包子') pro_g = product_baozi() baozi_1 = pro_g.__next__() print('来了个人 \n',baozi_1) baozi_2 = pro_g.__next__() print('来了个人 \n',baozi_2) baozi_3 = pro_g.__next__() print('来了个人 \n',baozi_3)

总结:
1.把列表解析的 [] 换成 () 得到的就是生成器表达式
2.列表解析与生成器表达式都是一种便利的编程方式,只不过生成器表达式更节省内存
3.Python不但使用迭代器协议,让 for 循环变得更加通用,大部分内置函数,也是使用迭代器协议访问对象的。例如,sum函数是Python的内置函数,该函数使用迭代器协议访问对象,二生成器实现了迭代器协议,所以,我们可以直接这样计算一系列值的和:
sum(x**2 for x in range(4))
而不用多此一举地先构造一个列表:
sum([x**2 for x in range(4)])
六、send 语句的使用
* yield 相当于 return 控制的是函数的返回值
* yield 的另外一个特性,接受 send 传过来的值
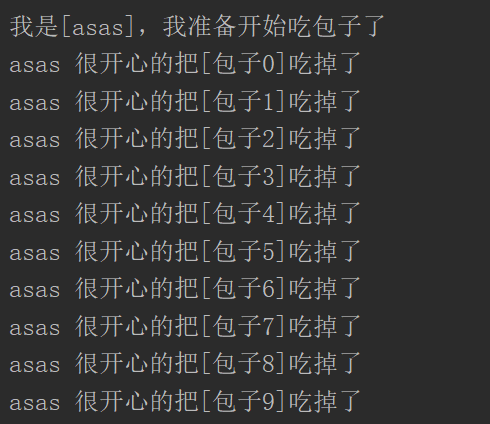
生产者和消费者模型:
import time def consumer(name): print('我是[%s],我准备开始吃包子了' %name) while True: baozi = yield time.sleep(1) print('%s 很开心的把[%s]吃掉了' %(name,baozi)) def producer(): c1 = consumer('asas') c1.__next__() for i in range(10): time.sleep(1) c1.send('包子%s' %i) producer()
七、生成器总结
* 语法上和函数类似: 生成器函数和常规函数几乎是一样的。他们都是使用 def 语句进行定义,差别在于,生成器使用 yield 语句可返回一个值,而常规函数使用 return 语句返回一个值
* 自动实现迭代器协议:对于生成器,Python会自动实现迭代器协议,以便应用到迭代背景中(如 for 循环,sum 函数)。由于生成器自动实现了迭代器协议,所以我们可以调用它的 next 方法,并且,在没有值可以返回的时候,生成器自动产生 StopIteration 异常
* 状态挂起:生成器使用 yield 语句返回一个值。yield 语句挂起该生成器函数的状态,保留足够的信息,以便之后从他离开的地方继续执行
* 注意事项:生成器只能遍历一次(母鸡一生只能下一定数量的蛋,下完就死了)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号