
缓存与数据库一致性原则
https://blog.csdn.net/striveb/article/details/95110502
一、场景:
两个用户发起下单请求,下单前需要查库存是否有剩余。
用户甲 :1、阶段1 :访问缓存库存,获取到缓存库存数量为1;
2、阶段1 :缓存数量为1,即有库存,准备更新,然后删除缓存库存;
3、阶段3 :然后更新数据库库存为 0;
用户乙:1、阶段2 :访问缓存库存,发现库存为空;
2、阶段2:然后再去访问数据库(此时用户甲,还没有修改数据库,此时数据库库存数量为1),发现数据库存为1,然后写入缓存库存改为1 。
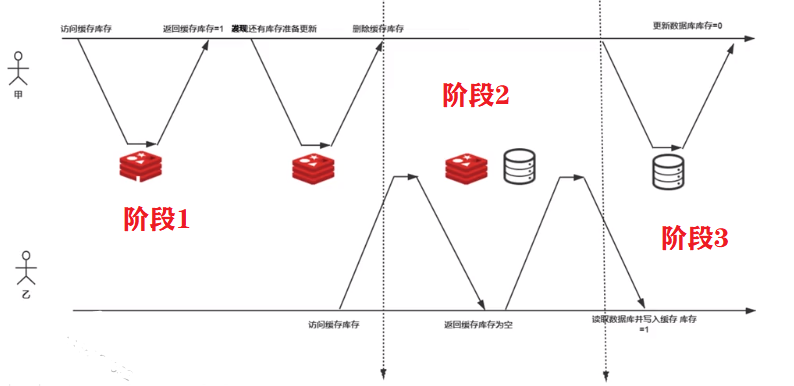
原因:
产生以上问题的原因是阶段2的时间长,延迟了用户甲在第三步的无法及时更新数据的库存数量的操作。
阶段2,这段时间那么长,有以下原因。
1、JVM垃圾收集的时候,会产生停止线程的场景。GC 产生 stop world
2、操作系统的时候,有上下文切换,耗时较长;
3、应用程序同步磁盘的时候,如果操作过程有是同步 io, 要等操作完成之后才能更新数据库;
4、内存的 free 空间已经很小, 这时候会 swap 到持久化层面,这时候访问操作很久;
5、操作更新数据库,由于网络的问题,包丢了;
6、在操作的时候,有人在运维,就可以挂起虚拟机;
二、常见缓存访问模式
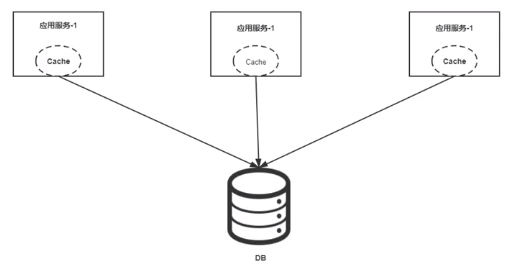
1、本地缓存(Cache-Aside)
缓存不直接与数据库交互
应用 服务1 访问数据库获取数据,再把数据存到本地缓存。
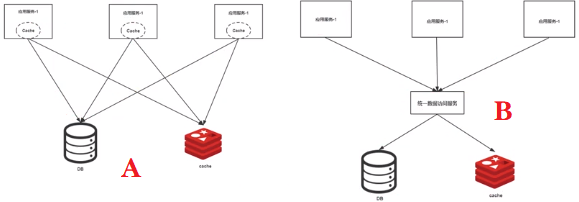
2、 缓存中间件(Cache-Aside)
左边全链路,右边统一数据访问服务
左边全链路的延迟更少,减少中间缓件。
右边的应用服务逻辑更简单,对用户更友好。
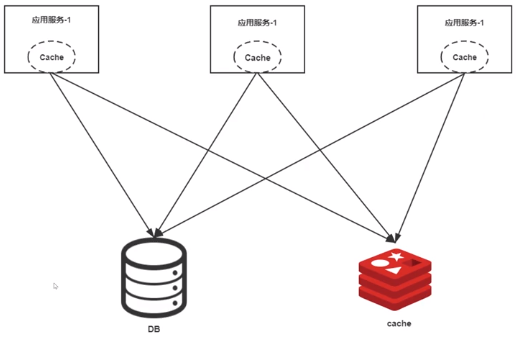
2.1、第一种
全链路
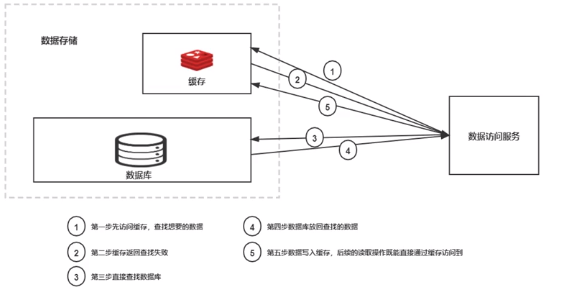
2.1.1、读取缓存
先访问缓存,查找数据;如果缓存返回失败,直接查找数据库,并放入缓存;
2.1.2、更新操作
1、先更新缓存,再更新数据库(更新不删除缓存)。
如果更新数据库不成功,导致缓存和数据库不一致。
如下问题
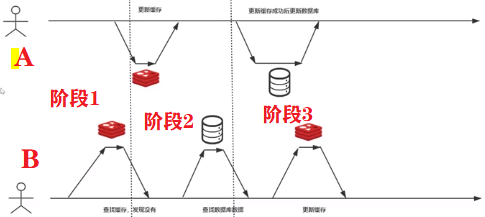
用户 B :1、阶段1:查找缓存,发现没有
2、阶段1到3:查找数据库
3、阶段3: 更新数据库
用户 A:1、阶段1到2:更新缓存;
2、阶段3:更新缓存成功,再更新数据库
A 更新的数据被B 更新的覆盖
2、先更新数据库,再更新缓存(更新不删除缓存)
也会出现问题,也会产生数据不一致。
3、先删除缓存,再更新数据库(更新删除缓存),
没有数据不一致的问题,但也有问题。
4、先更新数据库,再删除缓存(更新删除缓存)
也有问题。
2.2、第二种
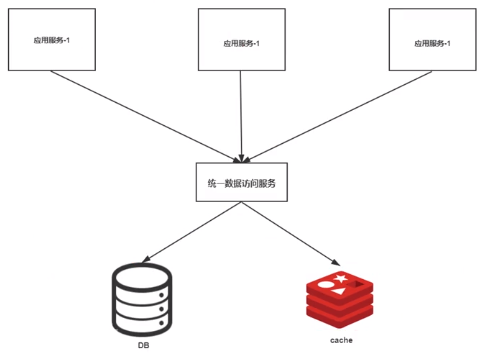
通过 统一数据访问服务,来决定先访问 数据库 还是 缓存,应用服务不直接访问数据库和缓存。
应用服务通过 get 和 set 访问,具体的由 统一数据访问服务决定。
2.3、缓存和数据库交互 Through
2.3.1、read Through
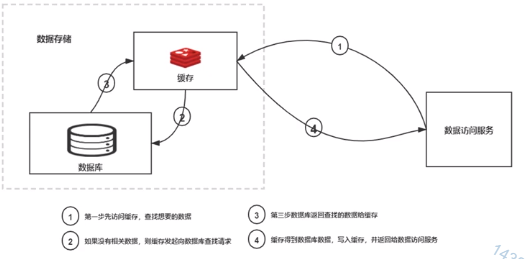
1、应用服务先访问缓存,找需要的数据;
2、如果没有相关数据,则缓存向数据库查找请求
3、数据库返回数据给缓存
4、数据写入缓存,并返回给应用服务
2.3.2、write through
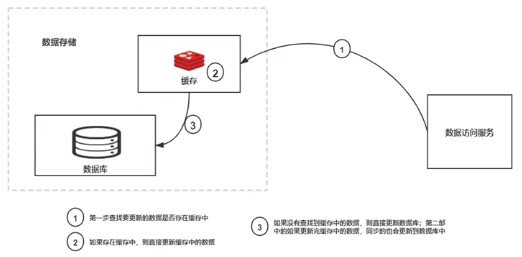
1、第一步查找更新缓存是否在缓存中
2、如果在缓存中,则直接更新缓存中的数据
3、如果没有查找到缓存中的数据,则直接更新数据库
第二部中的数据更新完缓存中的数据,同步也会写回到数据库
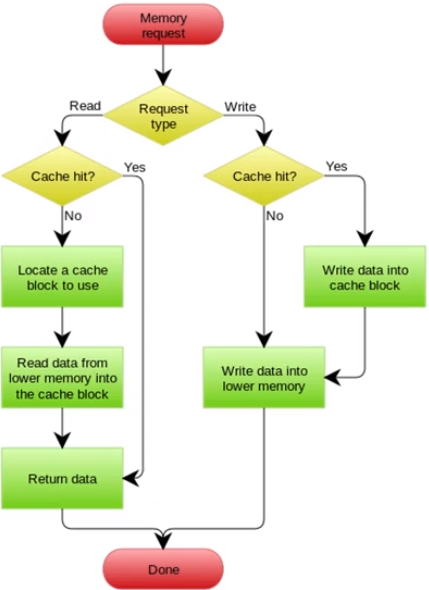
2.3.3、write behind
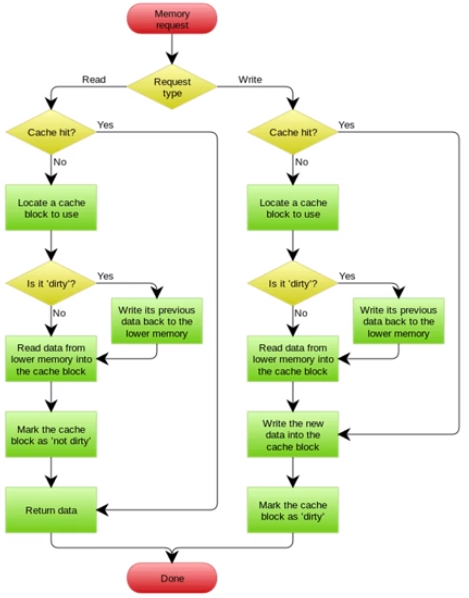
三、一致性更新目标
过期时间 TTL
1、最终一致性:过期了回取数据库最新值
2、剔除冷的缓存,节省缓存空间,提升效率
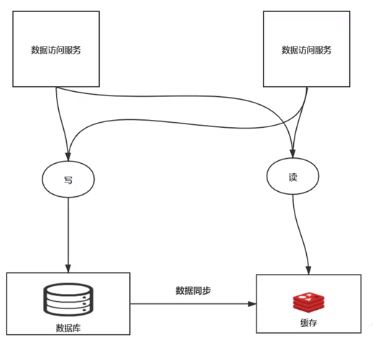
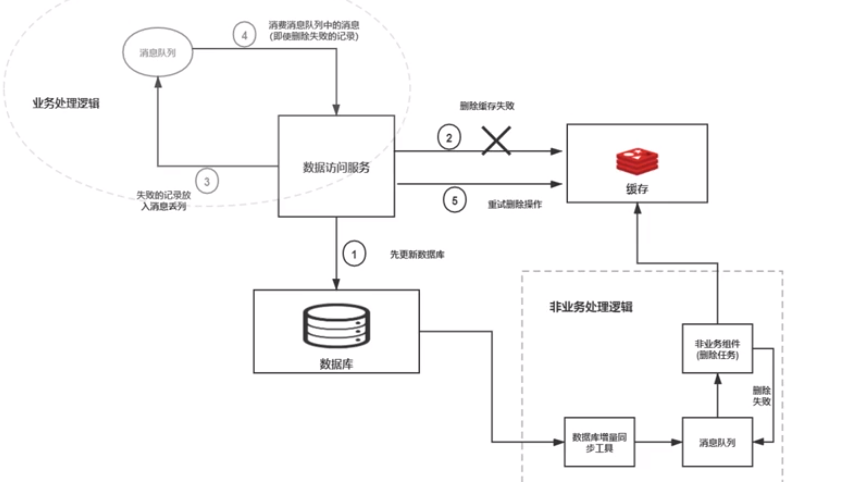
3.1、异步更新(最终一致性)
3.2、重试机制(最终一致性)
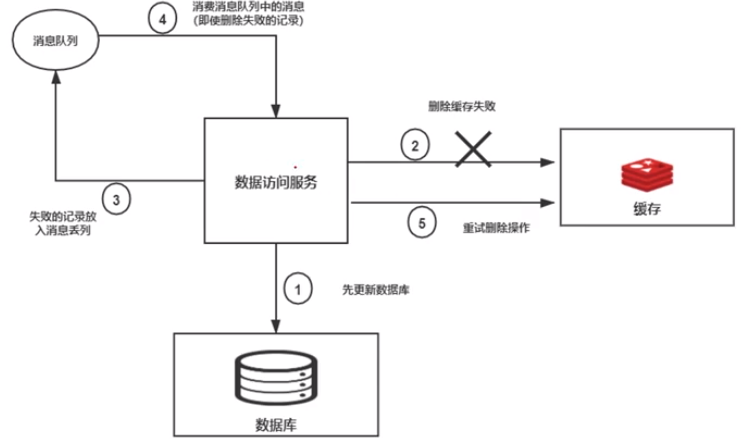
1、数据访问服务先更新数据库
2、再删除缓存,如果删除缓存失败
3、失败的记录放入消息队列
4、消费消息队列的消息(即使删除失败的记录)
5、重试删除操作
3.3、强一致性
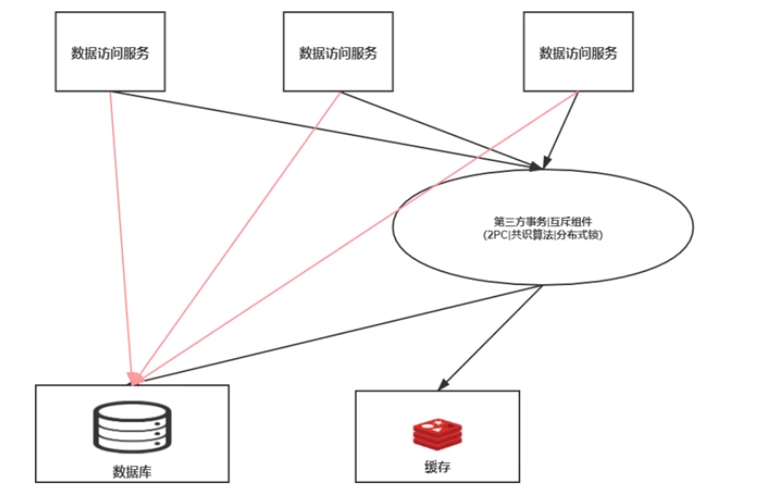
将更新数据库和更新缓存当作事务依据 ACID 的原则。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号