
mysql索引类型
最直观:https://www.cnblogs.com/zhuyeshen/p/12082839.html
https://blog.csdn.net/itguangit/article/details/82145322
https://www.cnblogs.com/happyflyingpig/p/7662881.html
聚集索引:
聚集(clustered)索引,也叫聚簇索引
将数据存储和索引放在一起、并且是按照一定的顺序组织的,找到索引也就找到了数据,数据的物理存放顺序与索引顺序是一致的,
即:只要索引是相邻的,那么对应的数据一定也是相邻的存放在磁盘上的。
定义:数据行的物理顺序与列值(一般是主键的那一列)的逻辑顺序相同,一个表中只能拥有一个聚集索引。
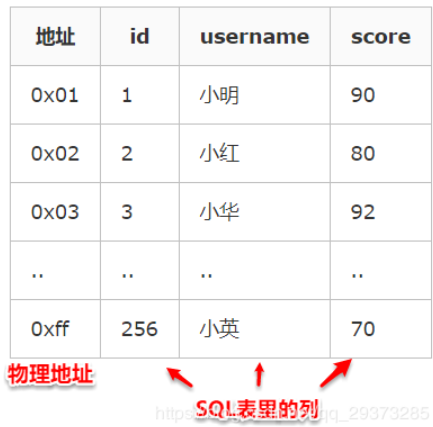
注:第一列的地址表示该行数据在磁盘中的物理地址,后面三列才是我们SQL里面用的表里的列,其中id是主键,建立了聚集索引。也就是根据主键建立了聚集索引(聚簇索引)可以这么理解:主键索引其实就是聚集索引。
结合上面的表格就可以理解这句话了吧:数据行的物理顺序与列值的顺序相同,如果我们查询id比较靠后的数据,那么这行数据的地址在磁盘中的物理地址也会比较靠后。而且由于物理排列方式与聚集索引的顺序相同,所以也就只能建立一个聚集索引了
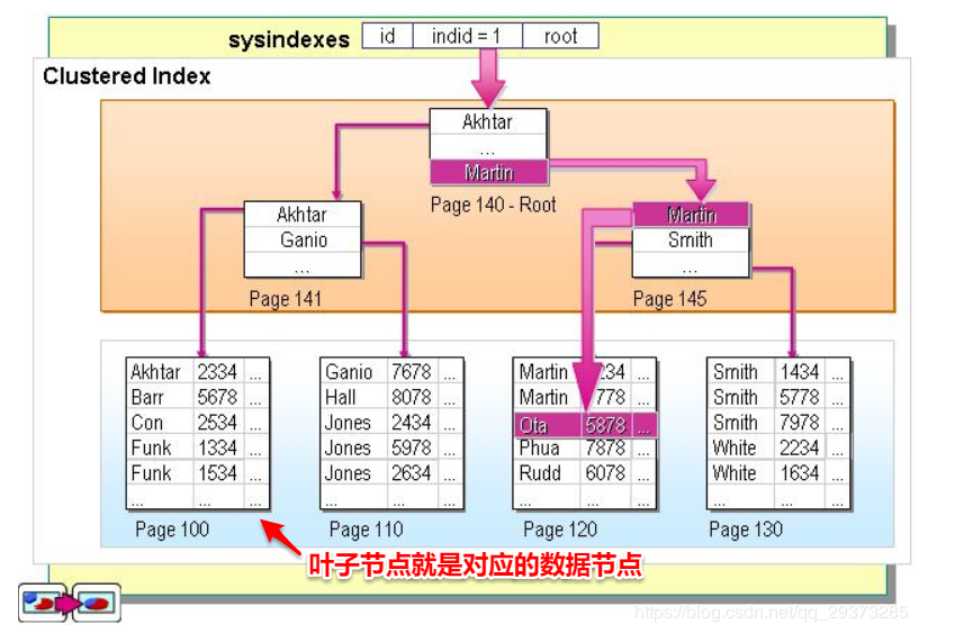
非聚集索引:
也称为 辅助索引(二级索引)
定义:该索引中索引的逻辑顺序与磁盘上行的物理存储顺序不同,一个表中可以拥有多个非聚集索引(可以认为是普通索引、辅助索引等)。
将数据存储于索引分开结构,索引结构的叶子节点指向了数据的对应行,
其实按照定义,除了聚集索引以外的索引都是非聚集索引,只是人们想细分一下非聚集索引,分成普通索引,唯一索引,全文索引。如果非要把非聚集索引类比成现实生活中的东西,那么非聚集索引就像新华字典的偏旁字典,他结构顺序与实际存放顺序不一定一致。
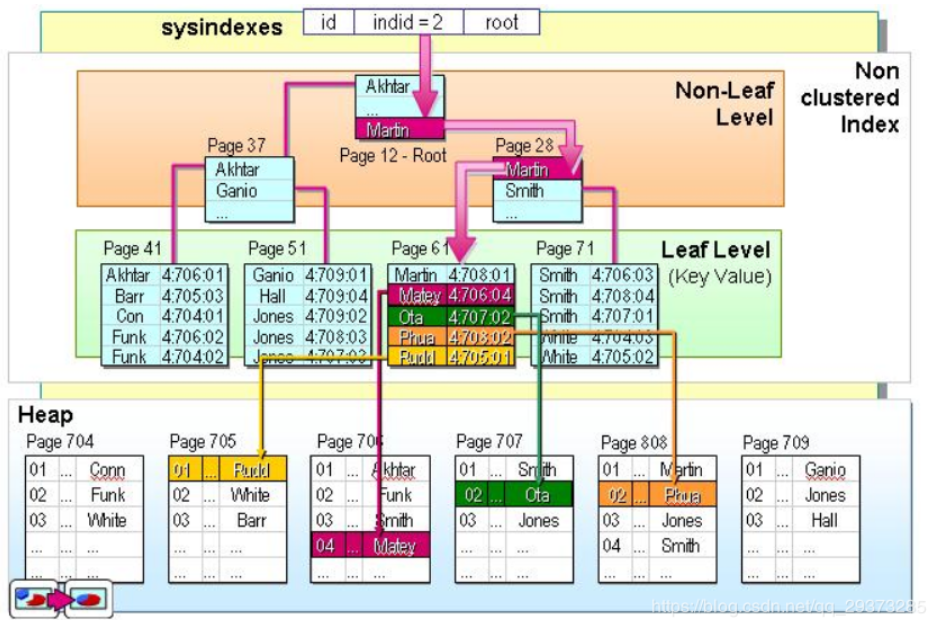
非聚集索引的二次查询问题:
非聚集索引叶节点仍然是索引节点,只是有一个指针指向对应的数据块,此如果使用非聚集索引查询,而查询列中包含了其他该索引没有覆盖的列,那么他还要进行第二次的查询,查询节点上对应的数据行的数据。
和聚集索引一样,采用平衡树作为索引的数据结构。索引树结构中各节点的值来自于表中的索引字段, 假如给user表的name字段加上索引 , 那么索引就是由name字段中的值构成,在数据改变时, DBMS需要一直维护索引结构的正确性。如果给表中多个字段加上索引 , 那么就会出现多个独立的索引结构,每个索引(非聚集索引)互相之间不存在关联。
非主键索引,叶子节点=键值+书签。Innodb存储引擎的书签就是相应行数据的主键索引值
每次给字段建一个新索引, 字段中的数据就会被复制一份出来, 用于生成索引。
因此, 给表添加索引,会增加表的体积, 占用磁盘存储空间。
//建立索引 create index index_birthday on user_info(birthday); //查询生日在1991年11月1日出生用户的用户名 select user_name from user_info where birthday = '1991-11-1'
SQL语句的执行过程如下:
先通过非聚集索引 index_birthday 查找 birthday 为 1991-11-1 的所有记录的主键ID值。
然后,通过得到的主键ID值执行聚集索引查找,找到主键ID值对的真实数据(数据行)存储的位置。
最后,从得到的真实数据中取得 user_name 字段的值返回。
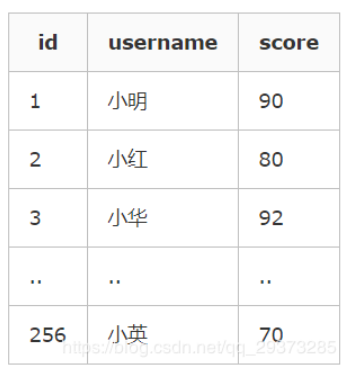
例子
其中有 聚集索引clustered index(id), 非聚集索引index(username)。
使用以下语句进行查询,不需要进行二次查询,直接就可以从非聚集索引的节点里面就可以获取到查询列的数据。
select id, username from t1 where username = '小明'
select username from t1 where username = '小明'
但是使用以下语句进行查询,就需要二次的查询去获取原数据行的score,其实也就是回表查询。
select username, score from t1 where username = '小明'
非聚集索引和聚集索引:
区别在于, 通过聚集索引可以查到需要查找的数据, 而通过非聚集索引可以查到记录对应的主键值 , 再使用主键的值通过聚集索引查找到需要的数据
聚集索引和非聚集索引的区别是什么?最根本的区别在于索引的顺序和表数据的顺序是否一致
覆盖索引:
就是平时所说的复合索引或者多字段索引查询。 文章上面的内容已经指出, 当为字段建立索引以后, 字段中的内容会被同步到索引之中, 如果为一个索引指定两个字段, 那么这个两个字段的内容都会被同步至索引之中。
就是select的数据列只用从索引中就能够取得,不必从数据表中读取,换句话说查询列要被所使用的索引覆盖。
索引是高效找到行的一个方法,当能通过检索索引就可以读取想要的数据,那就不需要再到数据表中读取行了。如果一个索引包含了(或覆盖了)满足查询语句中字段与条件的数据就叫 做覆盖索引。
是非聚集组合索引的一种形式,它包括在查询里的Select、Join和Where子句用到的所有列(即建立索引的字段正好是覆盖查询语句[select子句]与查询条件[Where子句]中所涉及的字段,也即,索引包含了查询正在查找的所有数据)
把 birthday 字段上的索引改成双字段的覆盖索引
create index index_birthday_and_user_name on user_info(birthday, user_name);
SQL语句的执行过程就会变为:
通过非聚集索引index_birthday_and_user_name查找birthday等于1991-11-1的叶节点的内容,然而, 叶节点中除了有user_name表主键ID的值以外, user_name字段的值也在里面, 因此不需要通过主键ID值的查找数据行的真实所在, 直接取得叶节点中user_name的值返回即可。
Mysql目前主要有以下几种索引类型:FULLTEXT,HASH,BTREE,RTREE。
https://zhuanlan.zhihu.com/p/111362942
1. FULLTEXT即为全文索引,目前只有MyISAM引擎支持。其可以在CREATE TABLE ,ALTER TABLE ,CREATE INDEX 使用,不过目前只有 CHAR、VARCHAR ,TEXT 列上可以创建全文索引。
全文索引并不是和MyISAM一起诞生的,它的出现是为了解决WHERE name LIKE “%word%"这类针对文本的模糊查询效率较低的问题。
2. HASH
由于HASH的唯一(几乎100%的唯一)及类似键值对的形式,很适合作为索引。
HASH索引可以一次定位,不需要像树形索引那样逐层查找,因此具有极高的效率。但是,这种高效是有条件的,即只在“=”和“in”条件下高效,对于范围查询、排序及组合索引仍然效率不高。
3. BTREE
BTREE索引就是一种将索引值按一定的算法,存入一个树形的数据结构中(二叉树),每次查询都是从树的入口root开始,依次遍历node,获取leaf。这是MySQL里默认和最常用的索引类型。
4. RTREE
RTREE在MySQL很少使用,仅支持geometry数据类型,支持该类型的存储引擎只有MyISAM、BDb、InnoDb、NDb、Archive几种。相对于BTREE,RTREE的优势在于范围查找。
ps. 此段详细内容见此片博文:Mysql几种索引类型的区别及适用情况
三、索引种类
普通索引:仅加速查询
唯一索引:加速查询 + 列值唯一(可以有null)
主键索引:加速查询 + 列值唯一(不可以有null)+ 表中只有一个组合索引:多列值组成一个索引,专门用于组合搜索,其效率大于索引合并
全文索引:对文本的内容进行分词,进行搜索
ps.
索引合并,使用多个单列索引组合搜索
覆盖索引,select的数据列只用从索引中就能够取得,不必读取数据行,换句话说查询列要被所建的索引覆盖

 浙公网安备 33010602011771号
浙公网安备 33010602011771号