概念:正则表达式是对字符串操作的一种逻辑表达方式,很多情况下我们需要在茫众多的文件中找到我们需要的文件时,就需要用到正则表达式了
正则表达式就如同一个过滤器,能够筛选出希望得到的字符串。它可以检索、替换符合我们自己规定格式的所有文本。
正则表达式分两类:
linux文本查找命令
先介绍一下linux中查找文本文件常用三个命令:
1.grep:最早的文本匹配程序,使用POSIX定义的基本正则表达式(BRE)来匹配文本。
2.egrep : 扩展式grep,其使用扩展式正规表达式(ERE)来匹配文本。
3.fgrep : 快速grep,这个版本匹配固定字符串而非正则表达式。并且是唯一可以并行匹配多个字符串的版本。
如下简单的介绍grep命令:
语法格式:
grep [OPTIONS] PATTERN [FILE...]
用途:
匹配一个或多个模式的文本行。
options:
--color=auto: 对匹配到的文本着色显示
-m: # 匹配#次后停止
-n: 显示匹配的行号
-c: 统计匹配的行数
-o: 仅显示匹配到的字符串
-E : 使用扩展正则表达式进行匹配, grep -E 或取代 egrep 命令。
-F : 使用固定字符串进行匹配, grep -F 或取代传统的fgrep命令,不支持正则表达式。
-e : 通常第一个非选项的参数认为是要匹配的模式,也可以同时提供多个模式,只要将其放入单引号,并用换行字符分隔他们。
模式以减号开头时,为防止混淆其为选项,-e选项说明其后的参数为模式,即使他以减号开头。
例如:
[root@centos7 data]# grep -e root -e ftp /etc/passwd #root或者ftp
root:x:0:0:root:/root:/bin/bash
operator:x:11:0:operator:/root:/sbin/nologin
ftp:x:14:50:FTP User:/var/ftp:/sbin/nologin
-f : 从pat-file文件读取模式作为匹配。
[root@centos7 data]# grep -f grep.log /etc/passwd #提前把搜索的关键字写在了grep.log的一个文件里面 然后-f进行搜索
root:x:0:0:root:/root:/bin/bash
operator:x:11:0:operator:/root:/sbin/nologin
xue:x:1000:1000:xue:/home/xue:/bin/bash
testbash:x:1002:1002::/home/testbash:/bin/bash
-i : 模式匹配时忽略大小写差异。
-l : 列出匹配模式的文件名称,而不是打印匹配的行。
-q : 静默的,如果匹配成功,不将匹配的行输出到标准输出;否则即是不成功。
-s : 不显示错误信息,通常与-q并用。
-v : 显示不匹配模式的行。
说明:可以同时查找多个文件中的内容,当指定多个文件时,每个显示出的文件行前会有文件名加一个冒号标识其来自哪个文件。
可以使用多个-e 或 -f 选项,建立要查找的模式列表。
-A: # after, 后#行
如:
[root@centos7 data]# grep -n -A 3 root /etc/passwd #后3行
1:root:x:0:0:root:/root:/bin/bash
2-bin:x:1:1:bin:/bin:/sbin/nologin
3-daemon:x:2:2:daemon:/sbin:/sbin/nologin
4-adm:x:3:4:adm:/var/adm:/sbin/nologin
--
10:operator:x:11:0:operator:/root:/sbin/nologin
11-games:x:12:100:games:/usr/games:/sbin/nologin
12-ftp:x:14:50:FTP User:/var/ftp:/sbin/nologin
13-nobody:x:99:99:Nobody:/:/sbin/nologin
-B: # before, 前#行
如:
[root@centos7 data]# grep -n -B 3 root /etc/passwd #前面3行 第1行的root上面没有行了
1:root:x:0:0:root:/root:/bin/bash
--
7-shutdown:x:6:0:shutdown:/sbin:/sbin/shutdown
8-halt:x:7:0:halt:/sbin:/sbin/halt
9-mail:x:8:12:mail:/var/spool/mail:/sbin/nologin
10:operator:x:11:0:operator:/root:/sbin/nologin
-C: # context, 前后各#行
如:
[root@centos7 data]# grep -n -C 3 root /etc/passwd #前后各3行
1:root:x:0:0:root:/root:/bin/bash
2-bin:x:1:1:bin:/bin:/sbin/nologin
3-daemon:x:2:2:daemon:/sbin:/sbin/nologin
4-adm:x:3:4:adm:/var/adm:/sbin/nologin
--
7-shutdown:x:6:0:shutdown:/sbin:/sbin/shutdown
8-halt:x:7:0:halt:/sbin:/sbin/halt
9-mail:x:8:12:mail:/var/spool/mail:/sbin/nologin
10:operator:x:11:0:operator:/root:/sbin/nologin
11-games:x:12:100:games:/usr/games:/sbin/nologin
12-ftp:x:14:50:FTP User:/var/ftp:/sbin/nologin
13-nobody:x:99:99:Nobody:/:/sbin/nologin
-w:匹配整个单词
正则表达式
REGEXP: Regular Expressions,由一类特殊字符及文本字符所编写的模式, 其中有些字符(元字符)不表示字符字面意义,而表示控制或通配的功能
1.正则表达式的组成
(1).一般字符:没有特殊意义的字符
(2).特殊字符(meta字符):元字符,有在正则表达式中有特殊意义
2.如下讲下正则表达式中的常见meta字符
(1).POSIX BRE与ERE中都有的meta字符:
\ : 通常用于打开或关闭后续字符的特殊含义,如\(...\)与\{...\}
. : 匹配任何单个字符(除NUL)
* : 匹配其前的任何数目或没有的单个字符,例: . 表示任一字符, 则 .* 匹配任一字符的任意长度
^ : 匹配紧接着的正则表达式,BRE中仅在正则表达式的开头有特殊的含义,ERE中在任何位置都有特殊含义
$ : 匹配前面的正则表达式,在字符串或者行结尾处。BRE中仅在正则表达式的结尾处有特殊的含义,ERE中在任何位置都有特殊含义
[] : 匹配方括号内的任一字符,其中可用连字符(-)指的连续字符的范围;^符号苦出现在方括号的第一个位置,则表示匹配不在列表中的任一字符,
(2).POSIX BRE中才有的字符:
\{n,m\} : 区间表达式,匹配在它前面的单个字符重现的次数区别。\{n\}指重现n次;\{n,m\}指重现n至m次;
\( \) : 保留空间,可以将最多9个独立的子模式存储在单个模式中。如\(ab\).*\1 : 指匹配ab组合的两次重现,中间可存在任意数目的字符。
\n : 重复在\(与\)方括号内第n个子模式至此点的模式。
(3).POSIX ERE中才有的字符:
{n,m} : 与BRE的\{n,m\}功能相同
+ : 匹配前面正则表达式的一个或多个扩展
? : 匹配前面正则表达式的零个或一个扩展
| : 匹配|符号前或后的正则表达式
( ) : 匹配方括号括起来的正则表达式群
(4). 方括号([])表达式
4.1.字符集 [: :]
标识字符集,有如下几种:
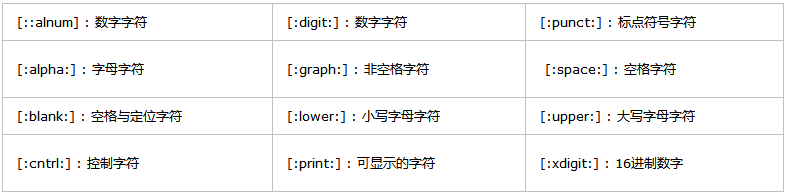
4.2.排序符号
指将多个字符视为一个符号,如[.ch.]即将ch视为一个符号
4.3.等价字符
认为多个字符相等,如[=e=]在法文的locale里,可匹配于多种与e相似的字符,此处不再列出。
说明:这三种构造除其自身的方括号之外,还必须使用额外的方括号括起来。
例 : [[:alpha:]!] : 匹配任一英文字母或感叹号。
[[.ch.] : 匹配ch排序元素,而不匹配单独的字母c或h.
3.简单正规表达式匹配案例
china : 匹配此行中任意位置有china字符的行
^china : 匹配此以china开关的行
china$ : 匹配以china结尾的行
^china$ : 匹配仅有china五个字符的行
[Cc]hina : 匹配含有China或china的行
Ch.na : 匹配包含Ch两字母并且其后紧跟一个任意字符之后又有na两个字符的行
Ch.*na : 匹配一行中含Ch字符,并且其后跟0个或者多个字符,再继续跟na两字符
匹配次数:用在要指定次数的字符后面,用于指定前面的字符要出现的次数
* 匹配前面的字符任意次,包括0次
正则表达式匹配的是字符串(*表示同前面符号出现的次数) 通配符匹配的是文件名(*表示后面本身表示的任意字符)
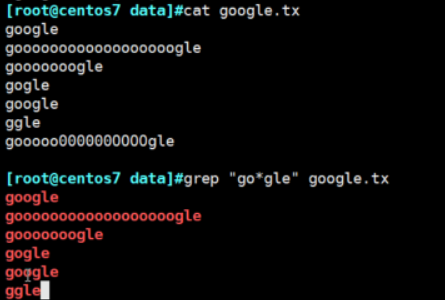
贪婪模式:尽可能长的匹配
.* 任意长度的任意字符
\? 匹配其前面的字符0或1次 可有可无
\+ 匹配其前面的字符至少1次 一次以上
\{n\} 匹配前面的字符n次
a\{10\} #a字母连续出现10次
\{m,n\} 匹配前面的字符至少m次,至多n次
a\{10,20\} #10-20次之间
\{,n\} 匹配前面的字符至多n次
a\{,20\}
\{n,\} 匹配前面的字符至少n次
a\{10,\}
u 位置锚定:定位出现的位置
^ 行首锚定,用于模式的最左侧
[root@centos7 ~]# grep "^[^#]" /etc/fstab
$ 行尾锚定,用于模式的最右侧
[root@centos7 ~]# grep "shutdown$" /etc/passwd
^PATTERN$ 用于模式匹配整行
^$ 空行
[root@centos7 ~]# grep -n "^$" /etc/fstab
^[[:space:]]*$ 空白行
\< 或 \b 词首锚定,用于单词模式的左侧
\> 或 \b 词尾锚定,用于单词模式的右侧
\<PATTERN\> 匹配整个单词
正则表达式
u 分组:\(\) 将一个或多个字符捆绑在一起,当作一个整体处理,如:\(root\)\+
u 分组括号中的模式匹配到的内容会被正则表达式引擎记录于内部的变量中,这些变量的命名方式为: \1, \2, \3, ...
u \1 表示从左侧起第一个左括号以及与之匹配右括号之间的模式所匹配到的字符
u 示例: \(string1\(string2\)\)
\1 :string1\(string2\)
\2 :string2
u 后向引用:引用前面的分组括号中的模式所匹配字符,而非模式本身
u 或者:\|
示例:a\|b a或b
C\|cat C或cat
\(C\|c\)at Cat或cat
找出/etc/passwd中的两位或三位数
[root@centos7 ~]# grep -o "\<[0-9]\{2,3\}\>" /etc/passwd #加词尾 词首锚定否则会包含四位数字的
[root@centos7 ~]# grep -o '\<[0-9]\+\>' /etc/redhat-release |head -1 #取出版本号 0-9
[root@centos7 ~]# grep -o '\<[0-9]\+\>' /etc/redhat-release |head -1 #取出版本号10以上
egrep及扩展的正则表达式
u egrep = grep -E
uegrep [OPTIONS] PATTERN [FILE...]
u 扩展正则表达式的元字符:
u 字符匹配:
. 任意单个字符
[] 指定范围的字符
[^] 不在指定范围的字符
扩展正则表达式
u 次数匹配:
* 匹配前面字符任意次
? 0或1次
+ 1次或多次
{m} 匹配m次
{m,n} 至少m,至多n次
u 位置锚定:
^ 行首
$ 行尾
\<, \b 语首
\>, \b 语尾
u 分组:
()
后向引用:\1, \2, ...
u 或者:
a|b a或b
C|cat C或cat
(C|c)at Cat或cat
[root@centos7 ~]# grep "^\([^:]\+\):.*\<\1$" /etc/passwd #取出用户名和shell同名的行 加词首锚定
sync:x:5:0:sync:/sbin:/bin/sync
shutdown:x:6:0:shutdown:/sbin:/sbin/shutdown
halt:x:7:0:halt:/sbin:/sbin/halt
注意:
1、grep默认不支持正则,因此正则表达式的符号对于grep来说就等同于普通字符含义,因此,想让grep直接处理正则符号必须通过转义字符\{\}来处理。
2、grep -E 强制让grep直接认识正则符号,不需要再进行转义
3、egrep 等效grep -E 天生就能认识正则符号
4、我们平时备份可以通过cp 文件名{,.bak}的形式进行,避免再打一次文件名 sed -r :让sed支持正则





