2020系统综合实践 期末大作业 第5组
2020系统综合实践 期末大作业 第5组
基于树莓派的人脸识别考勤系统--地堡男孩小组
选题简介
选题背景
在当今快节奏的世界中,对于拥有几百名的公司组织而言,手动打卡出勤系统非常低效且耗时。诸如指纹,RFID或虹膜扫描之类的自动考勤系统的传统方法很容易被绕开,因为此类系统所考虑的生物特征远远少于面部特征。人脸识别考勤系统用于检测人的面部,然后将其与存储的面部数据库进行比较以进行识别。一旦识别出脸部,他的出席情况以及他的进出时间都会被标记出来并存储在数据库中。

选题意义
人脸识别实现快速便捷签到,既可以节省员工的排队打卡时间,又可以防止拿卡代签或者指纹破损导致无法签到等情况,大大地提高了公司的考勤效率。

预期结果
人脸识别打卡签到
①可以在短时间内快速识别员工人脸,记录签到信息
②可以录入新的员工信息(姓名,工号,人脸信息)
③语音播报员工签到成功或者录入成功,并在考勤表实时显示签到记录
后台管理
①管理员登录、注册或者删除
②按照姓名、工号、时间段查询历史签到记录,查看正常签到或者是否有迟到和旷工的现象
设计(重点说明系统部署所使用的容器)
系统结构
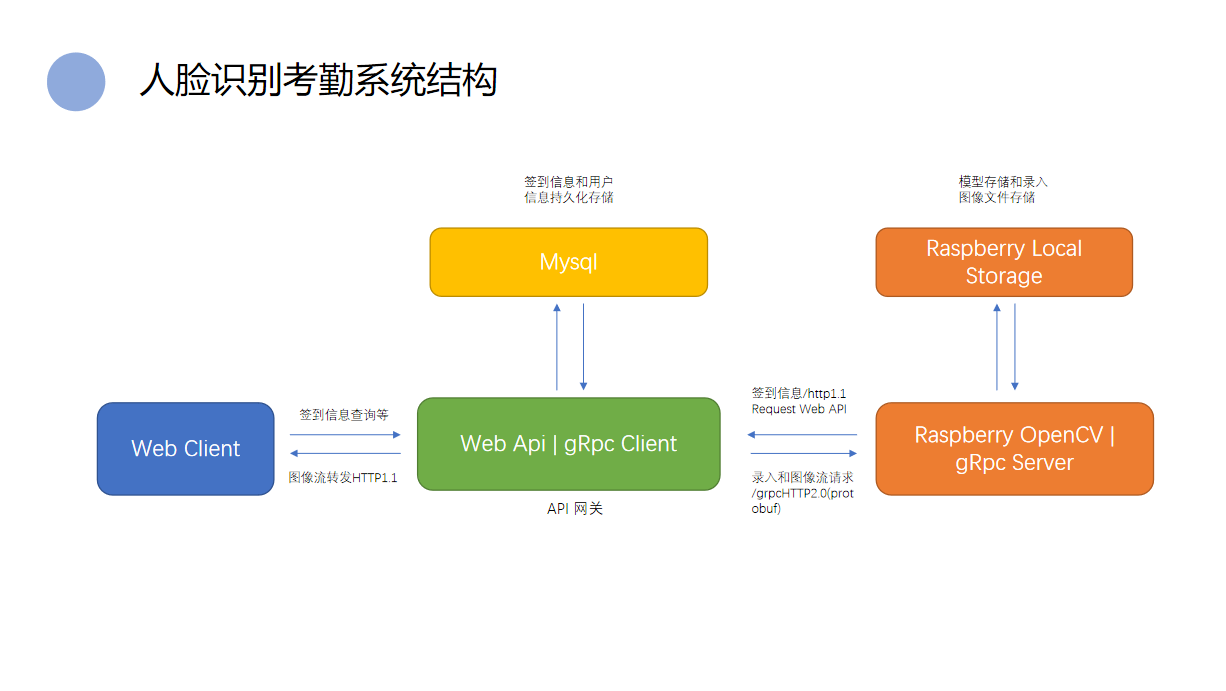
-
特色
①界面美观大方,简洁明了,使用了UI框架进行优化,使用简单方便易上手。
②人脸识别模型,准确度高
③使用gRPC的proto buf进行图片流传输
阿里云运行部署
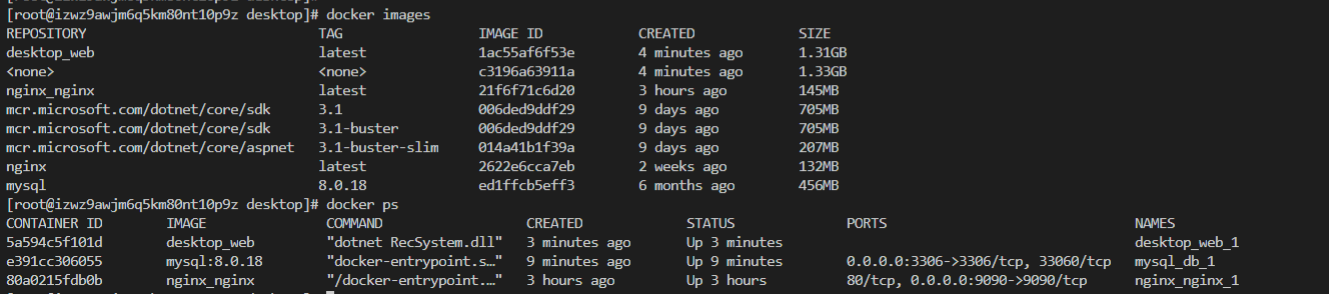
前端部署
WEB容器服务
- 目录结构

- 编写dockerfile
from nginx
COPY . /
COPY ./default.conf /etc/nginx/conf.d/
- 编写docker-compose
version : "3"
services:
nginx:
build: .
restart: always
ports:
- 9090:9090
- 编写default.conf
server {
listen 9090;
listen [::]:9090;
server_name localhost;
#charset koi8-r;
#access_log /var/log/nginx/host.access.log main;
location / {
root /face-recognition2.0/;
index index.html index.htm;
}
#error_page 404 /404.html;
# redirect server error pages to the static page /50x.html
#
error_page 500 502 503 504 /50x.html;
location = /50x.html {
root /usr/share/nginx/html;
}
}
- 构建自定义镜像
docker-compose build
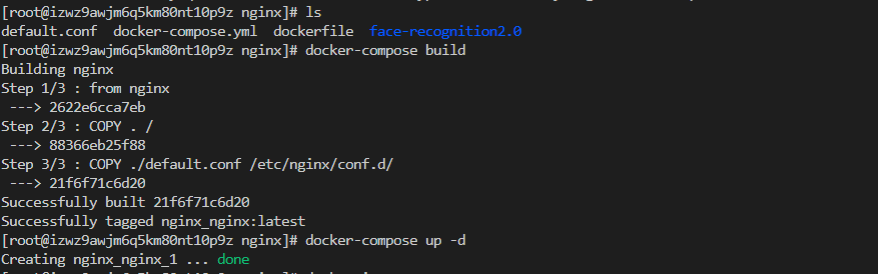
- 运行容器
docker-compose up -d
docker run -it --rm nginx_nginx:latest /bin/bash

- 查看index.html,成功访问web容器服务
后端部署
Mysql数据库服务
- 目录结构
- docker-compose.yml
# Use root/example as user/password credentials
version: "3.1"
services:
db:
image: mysql:8.0.18
command: --default-authentication-plugin=mysql_native_password
restart: always
environment:
MYSQL_ROOT_PASSWORD: fuzhoudaxue
ports:
- 3306:3306
volumes:
- ./data:/var/lib/mysql

应用程序
- 编写dockerfile
FROM mcr.microsoft.com/dotnet/core/sdk:3.1 AS build
WORKDIR /src
COPY ["RecSystem.csproj", ""]
# ENV PATH="/root/.dotnet/tools:${PATH}"
# RUN dotnet tool install --global dotnet-ef
# RUN dotnet ef --version
RUN dotnet restore
# RUN dotnet ef database update init
COPY . .
WORKDIR "/src/."
RUN dotnet build -c Release -o /app/build
FROM build AS publish
RUN dotnet publish -c Release -o /app/publish
FROM build AS final
WORKDIR /app
ENV ASPNETCORE_ENVIRONMENT="Development"
EXPOSE 8000
COPY --from=publish /app/publish .
ENTRYPOINT ["dotnet", "RecSystem.dll"]
- 编写docker-compose.yml
version: "3.1"
services:
web:
build: .
ports:
- 5000:8000
network_mode: host
restart: always
- 构建镜像
docker-compose build
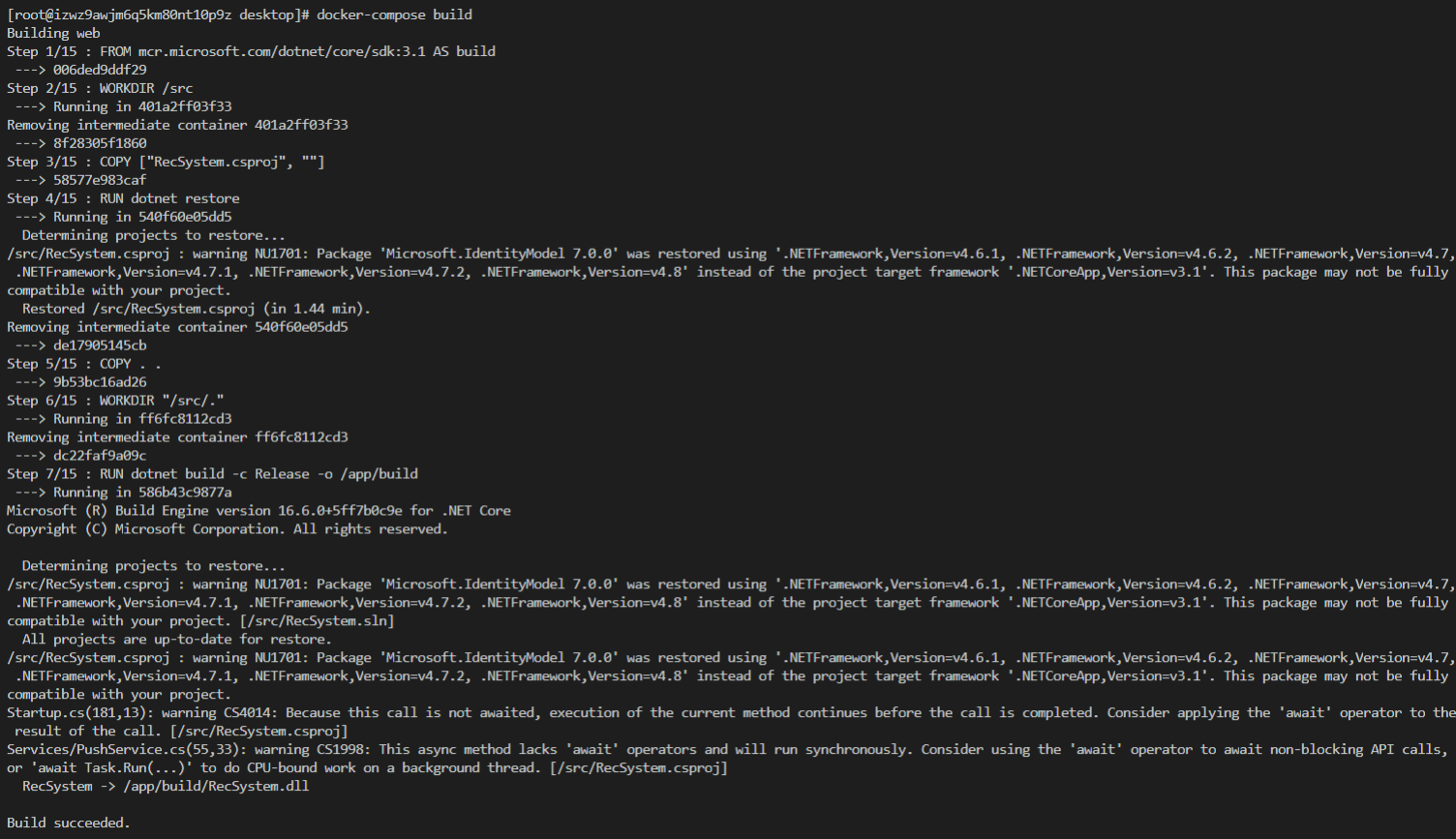
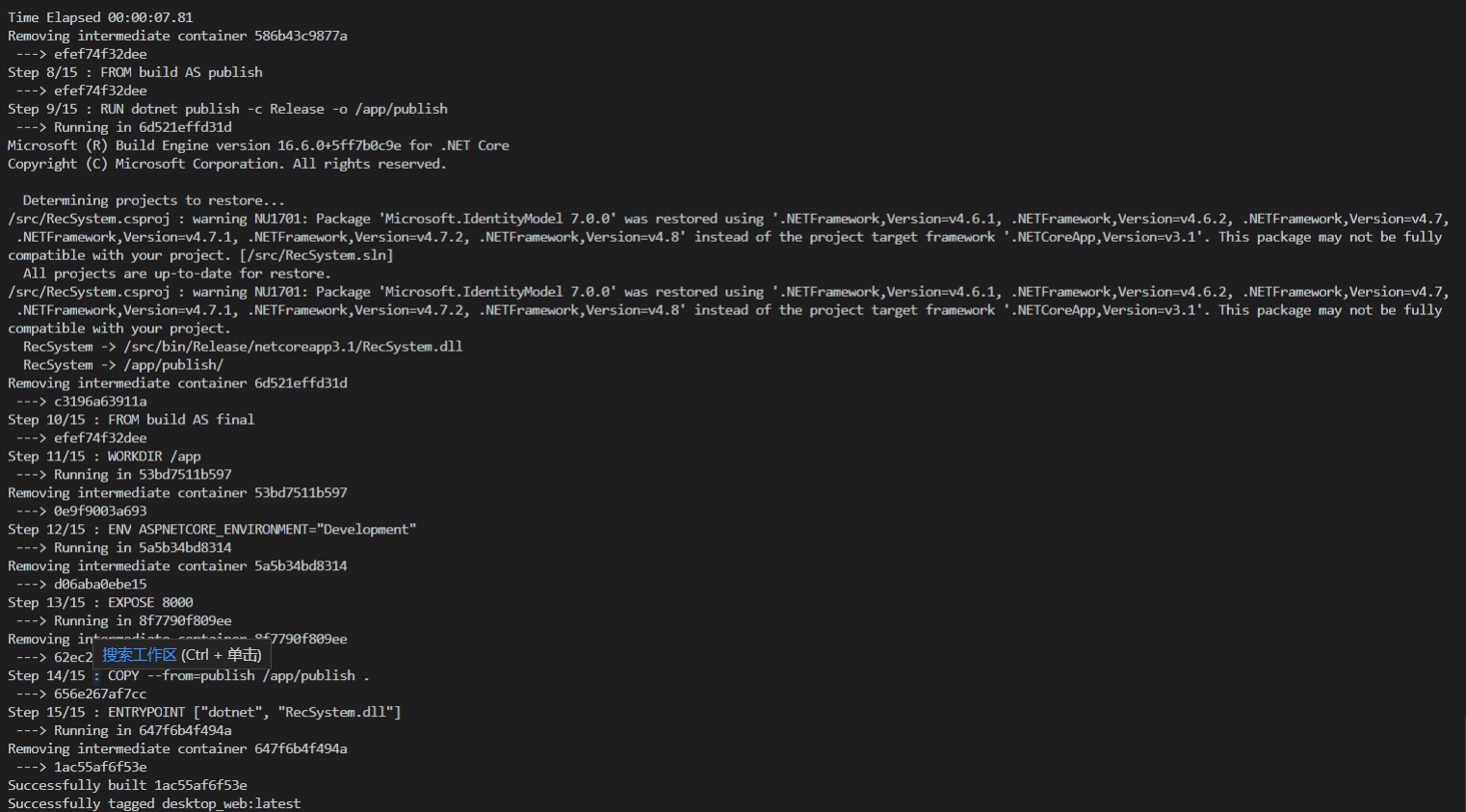
- 运行容器
docker-compose up -d

树莓派(人脸识别)
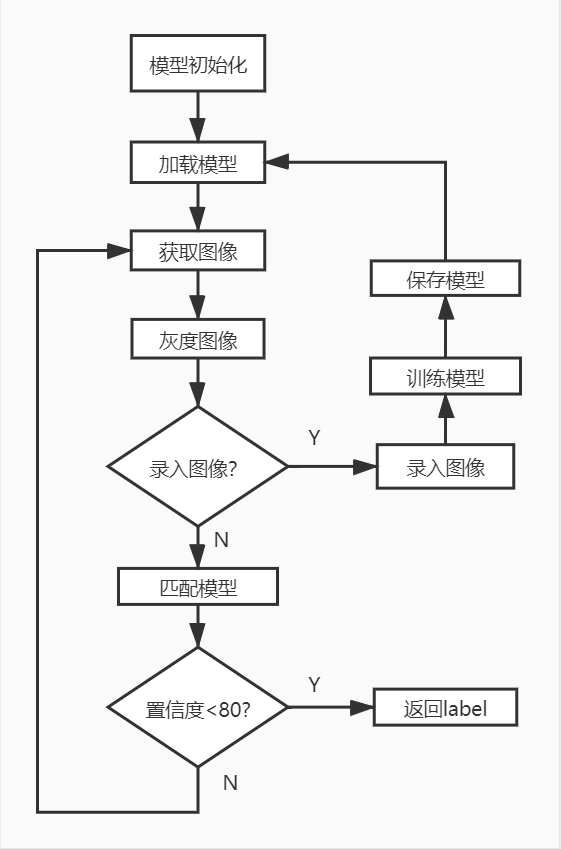
初始化
-
使用haarcascade_frontalface_alt.xml级联分类器进行人脸检测
-
使用OpenCV自带的LBPH算法进行人脸识别匹配
def __init__(self):
""" 构造函数 """
# 启动相机
self.camera = cv2.VideoCapture(0)
self.camera.set(cv2.CAP_PROP_FRAME_WIDTH, 640)
self.camera.set(cv2.CAP_PROP_FRAME_HEIGHT, 480)
# 人脸特征标识
self.cascade = cv2.CascadeClassifier("./data/haarcascade_frontalface_alt.xml")
# 录入的图像
self.images = "./pic_dir"
self.model = cv2.face.LBPHFaceRecognizer_create()
srcs, labels = self.load_data()
self.labels = labels
self.recs = []
self.modelLock = False
try:
self.model.read("./model/face.yml") # 加载模型
except:
# self.model = None
self.train()
人脸录入
这三个文件都在同一级目录下。从数据集文件夹中载入训练图片,获取到人脸,然后调用进行训练。
- pic_dir 存放的是人脸照片,将获取的人脸照片存放到此文件夹里面
- model 存放的是训练好的 yml 文件,将训练好的yml文件存放在此文件夹下面
- identity.py是人脸识别源码
def admit(self, name, count, max_count=200):
""" 异步录入信息 """
print("{} 录入人脸".format(name))
loop_count = 0
target_dir = "./pic_dir/{}/".format(name)
if os.path.exists(target_dir) is False:
os.makedirs(target_dir)
isAdmit = False
while loop_count < count and max_count > 0:
ret, frame = self.camera.read()
gray = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY)
faces = self.cascade.detectMultiScale(
gray, 1.3, 4, minSize=(30, 30), flags=cv2.CASCADE_SCALE_IMAGE
)
for (x, y, w, h) in faces:
# 画出预测框
cv2.rectangle(frame, (x, y), (x + w, y + h), (255, 0, 0), 2)
# f = cv2.resize(gray[y : y + h, x : x + w], (200, 200))
# 保存录入的图片
isAdmit = True
cv2.imwrite(
"./pic_dir/{0}/{1}.png".format(name, loop_count),
gray[y : y + h, x : x + w],
)
loop_count += 1
self.image = frame
# cv2.imshow("Recognize Face", self.image)
# cv2.waitKey(10)
max_count -= 1
return isAdmit
def load_data(self, resize=None):
""" 加载图像数据 """
labels = [] # 标签
index = []
srcs = [] # src数据
count = 0
for dirname, dirnames, filenames in os.walk(self.images):
for subdirname in dirnames:
sub_path = os.path.join(dirname, subdirname)
for filename in os.listdir(sub_path):
try:
if filename == ".directory":
continue
filepath = os.path.join(sub_path, filename)
im = cv2.imread(filepath, cv2.IMREAD_GRAYSCALE)
if im is None:
print("image " + filepath + " is none")
else:
print(filepath)
# if resize is not None:
# im = cv2.resize(im, (200, 200))
im = cv2.resize(im, (100, 100))
srcs.append(np.asarray(im, dtype=np.uint8))
# self.image = im
# cv2.imshow("读取", im)
# cv2.waitKey(1)
index.append(count)
labels.append(subdirname)
count += 1
except IOError:
print(
"I/O error({0}): {1}".format(
IOError.errno, IOError.strerror
)
)
except:
print("Unexpected error:", sys.exc_info()[0])
raise
return [srcs, index], labels
def train(self):
if self.modelLock:
return
print("训练数据")
[srcs, count], labels = self.load_data()
if len(labels) <= 0:
return
# labels = np.asarray(labels)
# count = np.asarray(count, dtype=np.int32)
self.modelLock = True
# if self.model is not None:
# self.model.update(srcs, np.asarray(count)) # 更新模型
# else:
self.model = cv2.face.LBPHFaceRecognizer_create()
self.model.train(srcs, np.asarray(count)) # 训练模型
self.labels = labels
self.model.save("./model/face.yml") # 保存模型
self.modelLock = False
人脸识别
最终实现的是人脸识别签到考勤,只有录入的人脸才能识别签到成功,这就要让树莓派知道识别的是哪张人脸,要将人脸图像和标签一一对应起来。在训练的过程中,获取到了人脸和标签,因此每个人脸都对应一个标签,使用函数将其返回,可以将标签和当前人脸对应起来,并可以用置信度(越小越相似度越高)进行判断。这里设置到置信度小于80即匹配识别成功。
async def rec(self, loop=True):
""" 识别匹对模型数据 """
print("Run")
rec_count = 0
new_face_position = {}
old_face_position = {}
while loop:
try:
rec_count += 1
ret, img = self.camera.read()
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
gray = cv2.equalizeHist(gray)
faces = self.cascade.detectMultiScale(
gray, 1.3, 4, minSize=(30, 30), flags=cv2.CASCADE_SCALE_IMAGE
)
self.recs = []
if not self.modelLock:
for (x, y, w, h) in faces:
roi = gray[y : y + h, x : x + w]
try:
# roi = cv2.resize(
# roi, (200, 200), interpolation=cv2.INTER_LINEAR
# )
roi = cv2.resize(roi, (100, 100))
params = None
if not self.modelLock:
params = self.model.predict(roi)
else:
continue
# 预测的label
key = self.labels[params[0]]
print("{} confience: {}".format(key, params[1]))
if key in old_face_position:
(ox, oy, ow, oh) = old_face_position[key]
if abs((ox - x)) <= 5 and abs((oy - y)) <= 5:
x = ox
y = oy
if (abs(x + w - ox - ow) <= 5) and abs(
(y + h - oy - oh) <= 5
):
w = ow
h = oh
if key not in new_face_position.keys() and params[1] < 80:
new_face_position[key] = (x, y, w, h)
# 当置信度小于80才加入
if params[1] < 80:
self.recs.append(key)
except:
continue
图像流传输
利用gRPC在后端搭建gRPC客户端和在树莓派上搭建gRPC服务器,利用proto buf传输图像流到后端进行转发。
def GetImages(self, request, context):
# global rec
data = cv2.imencode(".jpg", rec.image)[1].tostring()
return admiter_pb2.Stream(data=data)
优点:
第一点:强大的接口描述语言(Powerful IDL)
Protocol Buffers是一个强大的二进制序列化工具集和语言,你可以使用Protocol Buffers定义你的接口。
第二点:支持十种语言的类库
为各种语言编写的服务自动生成相应语言的客户端和服务端存根(也就是接口)
第三点:基于HTTP2协议
基于HTTP2标准设计,带了许多诸如双向流、流程控制、头部压缩、单TCP连接上的多路复用请求等特性。HTTP/2 传输的数据是二进制的。相比 HTTP/1.1 的纯文本数据,二进制数据一个显而易见的好处是:更小的传输体积。这就意味着更低的负载。二进制的帧也更易于解析而且不易出错,纯文本帧在解析的时候还要考虑处理空格、大小写、空行和换行等问题,而二进制帧就不存在这个问题。
protobuf二进制消息,性能好/效率高(空间和时间效率都很不错) ,proto文件生成目标代码,简单易用,序列化反序列化直接对应程序中的数据类,不需要解析后在进行映射(XML,JSON都是这种方式) 这些特性使得其在移动设备上表现更好,更省电和节省空间占用,同时加速了运行在cloud上的服务和web应用。gRPC默认使用protocol buffers—Google 的成熟开源机制,用来序列化结构化数据(即便如此,它还可以和其他数据结构例如JSON一起使用)。将使用proto文件定义gRPC服务,其方法参数和返回类型作为protocol buffer的消息类型。
运行结果,展示容器启动后,程序的运行结果
- 管理员登录
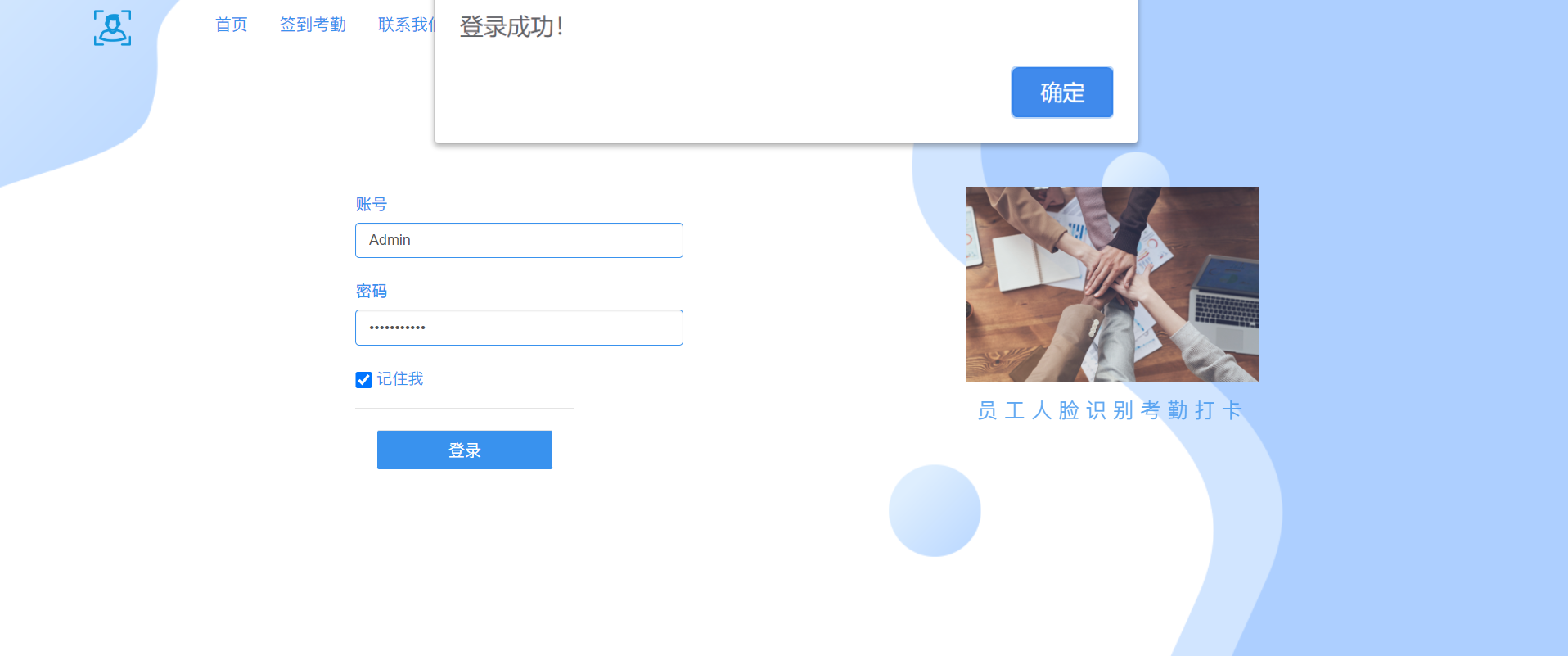
- 点击开启语音播报
点击开启之后,会有语音提示“开启语音播报成功”
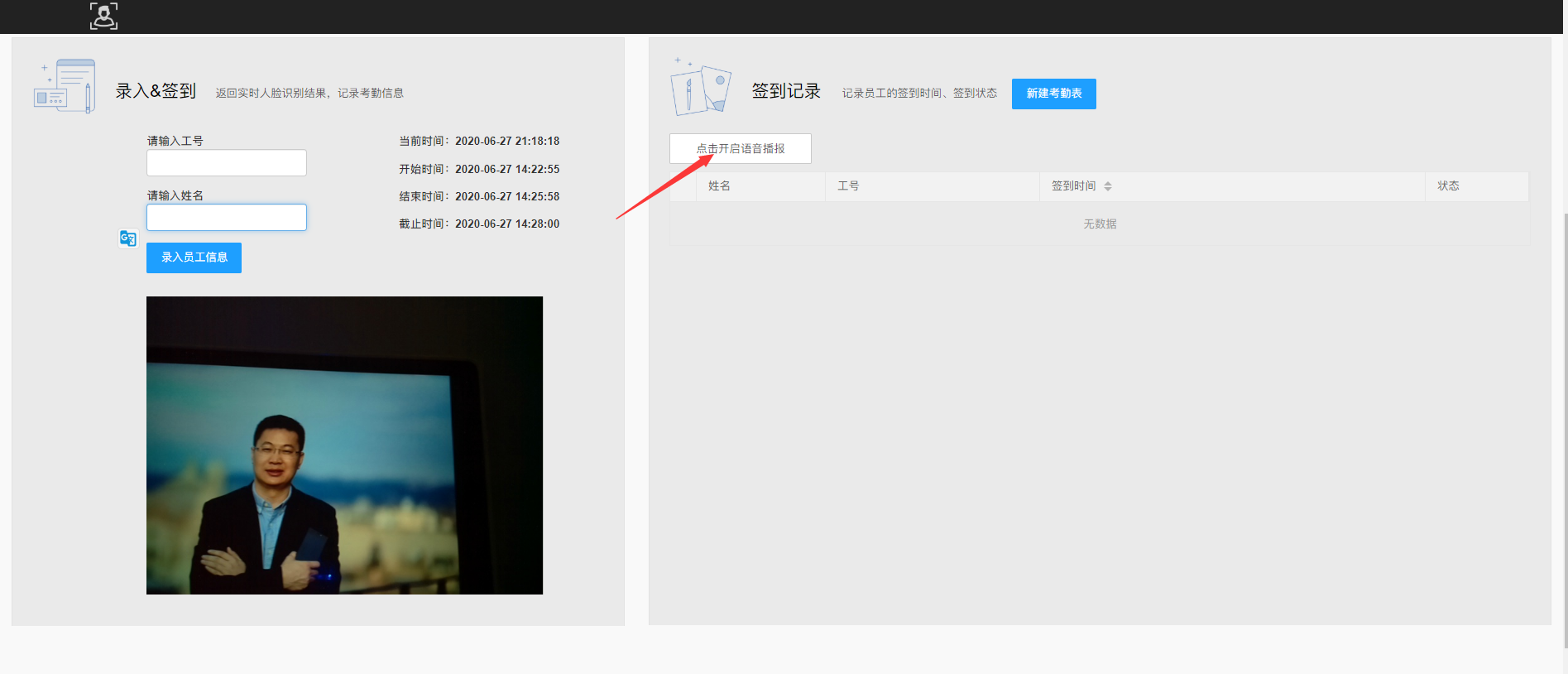
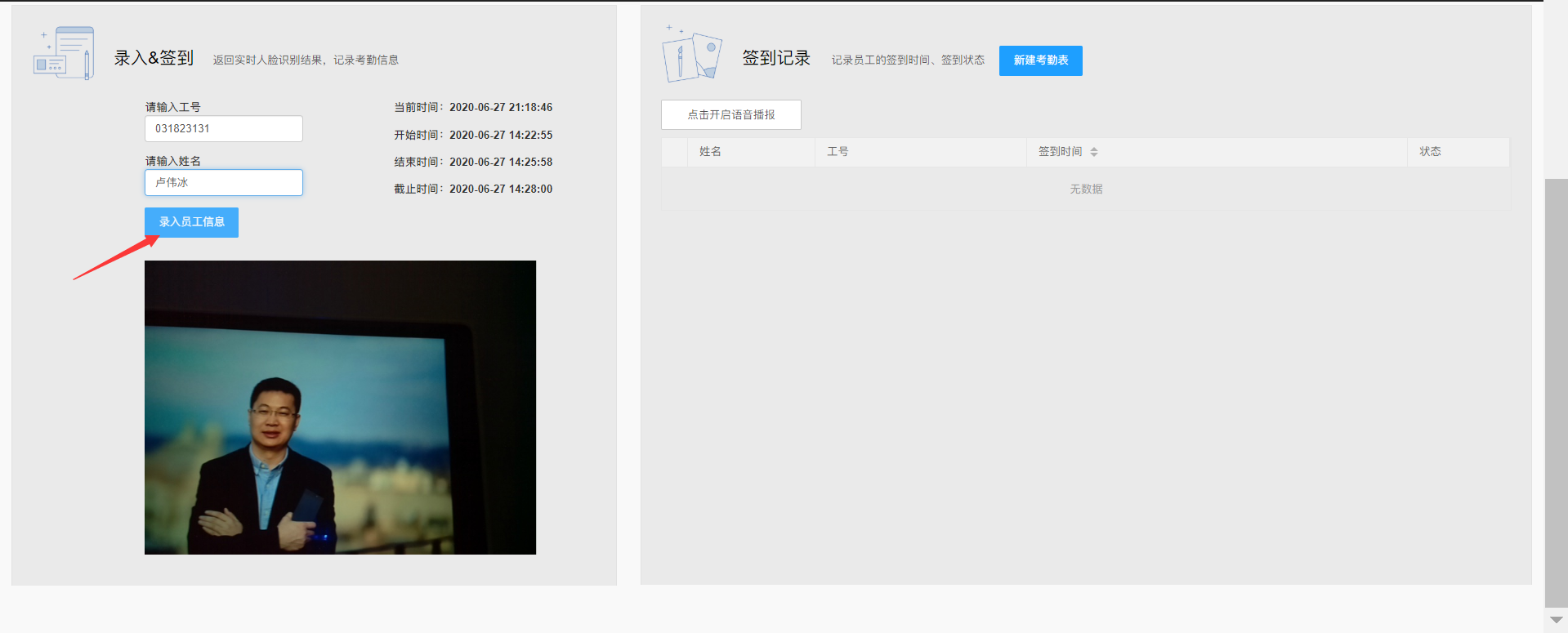
- 员工录入
输入员工工号姓名之后,点击录入员工信息
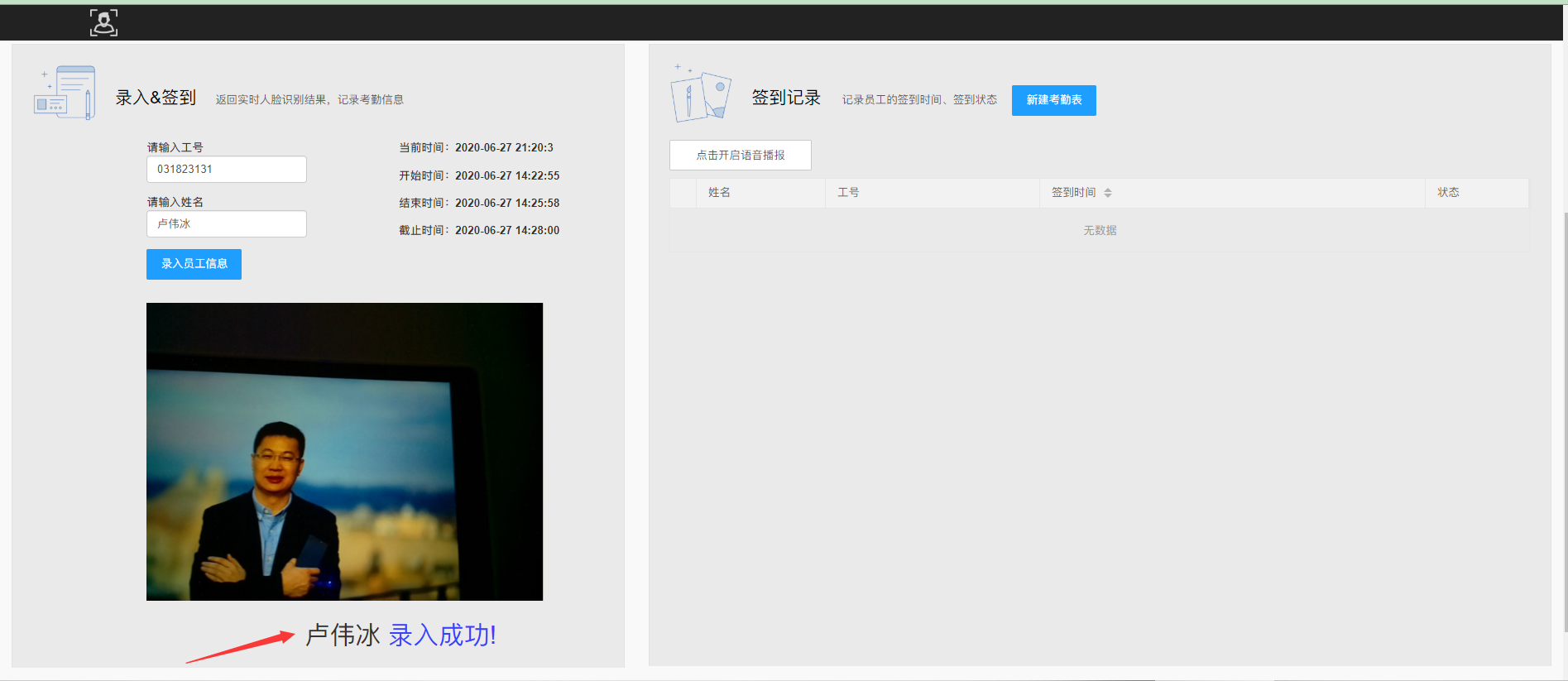
录入成功之后,会有文字提示和语音播报“xxx 录入成功!”
- 新建签到表
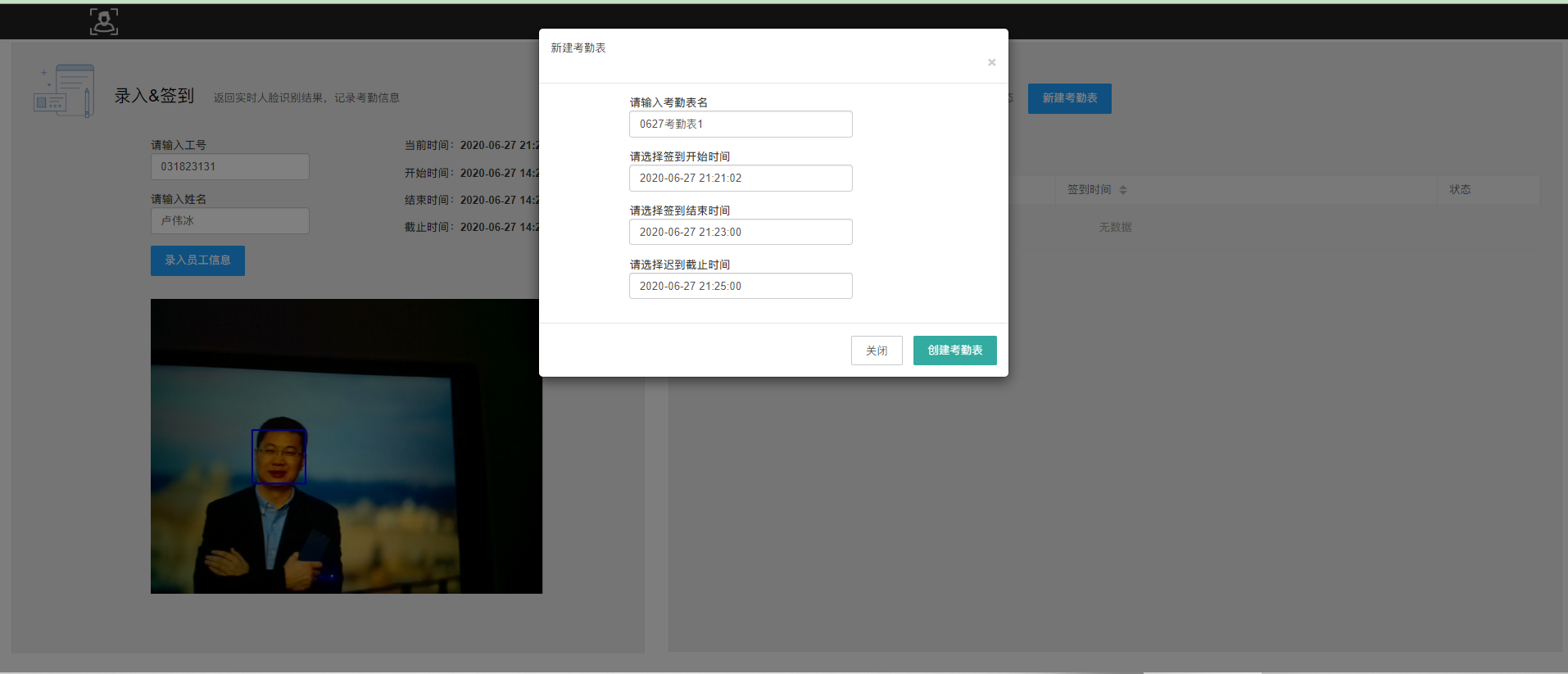
- 人脸识别打卡签到
识别到员工人脸之后,有语音提示“xxx 签到成功!”,并且右边考勤表会有记录显示。

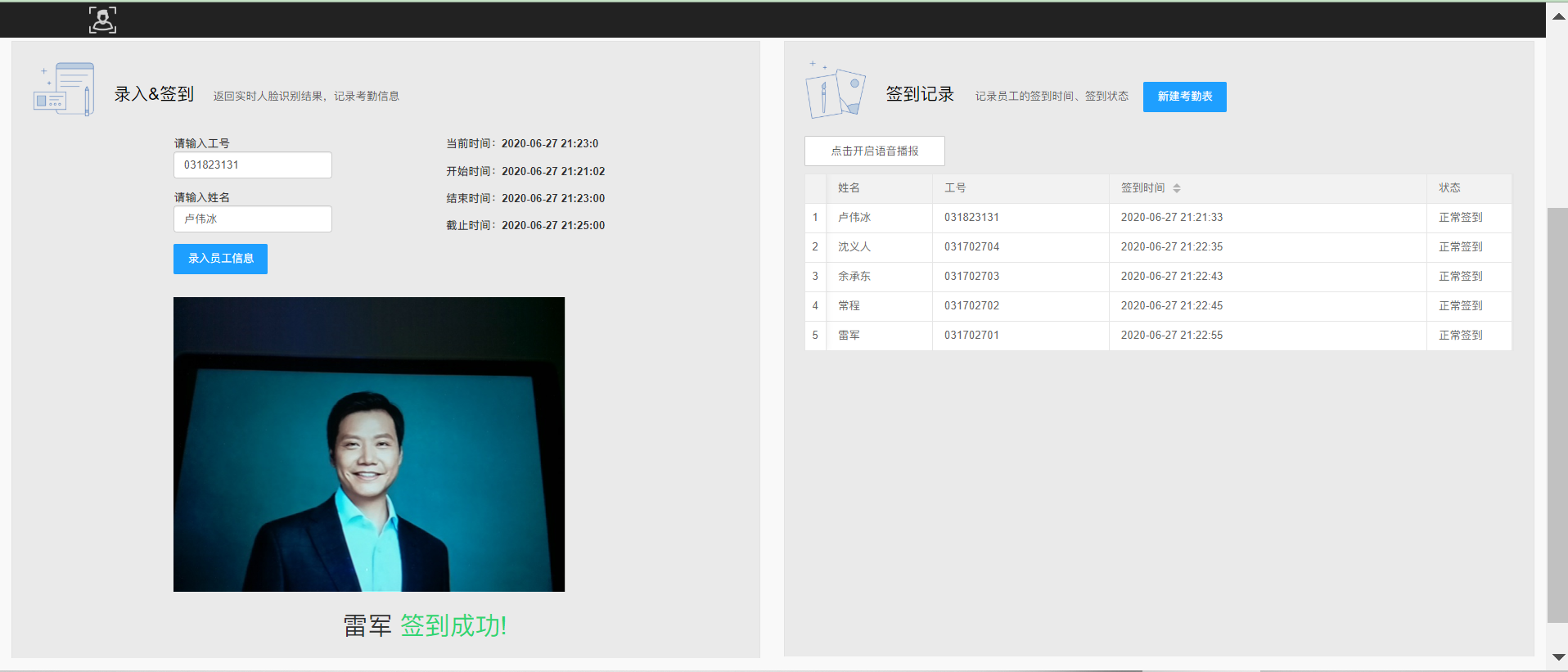
员工如果超过正常签到时间签到会被记录为“迟到”,超过最晚签到时间会被记录为“旷工”
- 查看历史打卡记录

可以根据姓名,时间段来查询签到记录
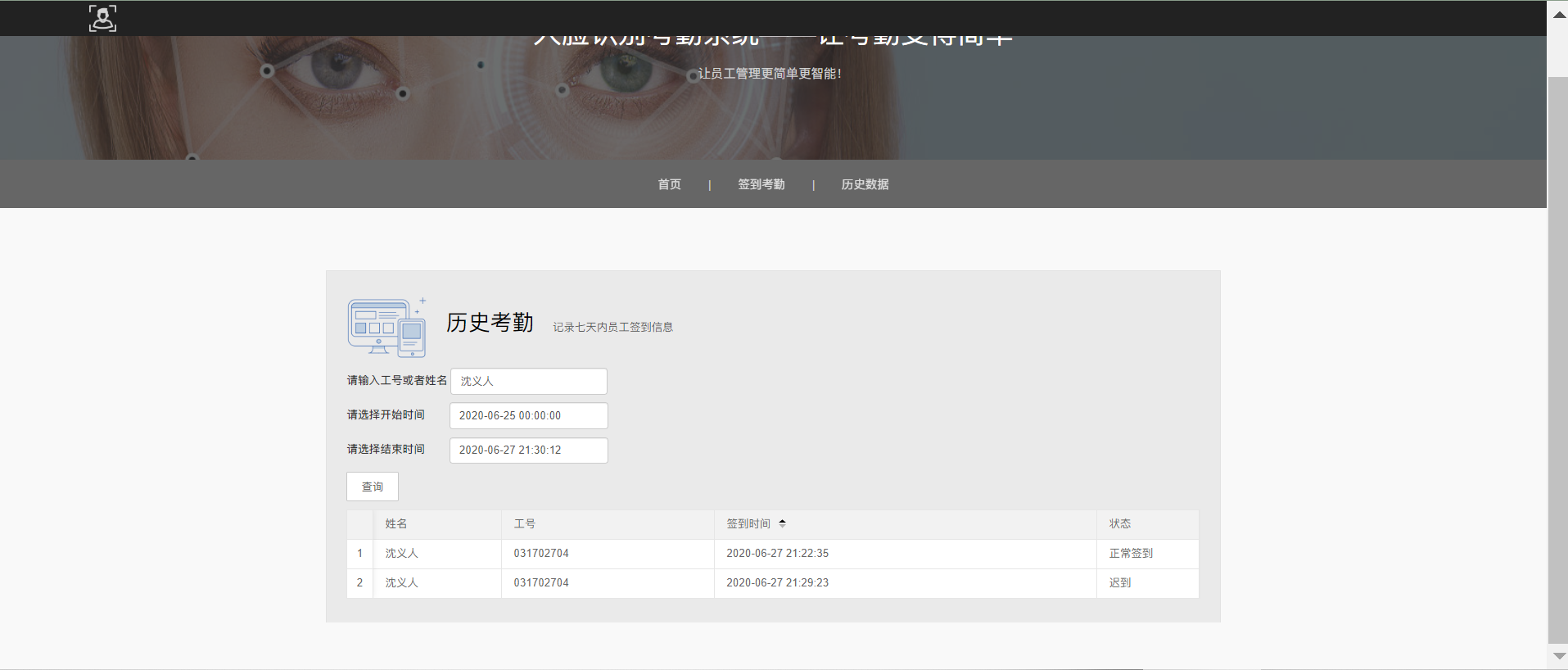
- 演示
提取码:ge14
最终的组内分工+贡献比
| 学号 | 姓名 | 分工 | 贡献比例 |
|---|---|---|---|
| 071703428 | 叶梦晴 | 前端,前后端对接,语音播报,前端运行部署 | 37 |
| 031702444 | 李尚佳 | 后端,前后端对接,人脸识别,后端运行部署 | 35 |
| 181700134 | 宋娟 | 数据库,接口测试,数据库运行部署 | 28 |
总结(组员分别撰写,统一提交)
叶梦晴: 终于到了完成大作业后的总结的时刻了!这学期在这门课上真的学到很多很多(时间也花了很多很多是真的,但是从静态页面编写完成、各种组件功能不断完善添加、前后端对接直到最终全部动态页面的实现,再到将整个项目成功用微服务运行部署成功的那一刻,感觉花的时间都值了!),关于docker方面及微服务部署方面的收获超级多,还有个人综合能力的一些提升也是很有意义的!
前端开发部分: 由于之前就有一些web前端开发的经验,所以本次实验前端静态页面的编写还挺顺利的。界面UI初衷是想以企业级界面(不知道这么说合不合适哈哈)为目标,因此在美化界面上花了较多的时间。整个前端是基于bootstrap的移动端适配,layUI实现对一些小组件的美化。语音播报本来觉得无从下手,后来队友找到的第三方文字转语音api提供了很大的帮助。
前后端对接: 接口方面大部分用的是jQuery的ajax,要说前后端对接也是时间花的比较久的了,因为前后端的编写习惯不太一样, 所以在很多小细节上出了一些bug,一些特定组件的接口规范也需要先学再使用。后来开了一个视频小会议与后端明确了一下各个接口的各个功能就清晰多了。
前端运行部署: 虽然有了之前搭建web容器服务实验的经历与基础,但是在有的地方还是出错了,这部分也是本次实验收获最大的部分,实现了将自己开发的项目用微服务运行部署感觉还是很不一样的。很感人(?)很有意义!!
最后,感谢我的队友们,真的都是神仙队友!在此特别鸣谢我的好兄弟们!
李尚佳: 转眼间这门课就要结束了,从一开始对微服务、docker,树莓派这些名词一无所知,到后面一知半解,懵懵懂懂,到最后终于能用这学期所学的微服务部署自己的应用程序,感觉收获良多。这次实验我负责人脸识别和后端业务逻辑代码部分,从一开始用flask框架转发视频流觉得画面卡成ppt感到十分烦恼,到后面学习到简单高性能的gRPC,用proto buf传输图片流;从一开始用facerec_from_webcam_faster.py做简易人脸识别,到后面学习用opencv库里面自带的一些分类器,下载器,用一些封装好的函数进行人脸的模型训练,预测模型进行人脸识别匹配;从之前需要对环境进行繁琐的配置,到后面用docker轻松运行部署;从对树莓派搞笑的认为是一种好吃的水果派到后面学习到树莓派还可以做这么多有趣的应用......这门课真的是收获颇丰!
还有当然是感谢hxdm!真的是太给力了!!!
宋娟: 如开学的猜想一样,每一次和博客园有关系的课都不是那种能够轻轻松松快快乐乐的课。作为一个全新的课,我一开始就带着对Linux的极度恐惧。安装两小时,再重装一小时的痛苦实在是不想体验。但是没想到后面还有树莓派,当时对树莓派真的就是一无所知,充满迷茫。就算是在本次大作业开始时,看见其他同学们的选题,我也觉得难度好高。
因为有之前的实验基础,数据库的部署还算轻松。所以本次实验我收获最大的是前后端对接的环节,在确定需求以后接口代码的编写以及接口测试都花了比较多的时间。这个环节中,因为合作经验不足,导致前后端接口对接的问题,也麻烦了队友修改了非常非常多次接口。中途也因为各种奇怪的小问题,走了很多弯路。运行部署了mysql对docker有了进一步的认识,对镜像,容器的构建过程以及运行过程的认识都有了提升。
这次的实践课从微服务与docker开始,到树莓派的人脸识别结束,一步步的学习相关知识。途中遇到了不少困难,但是也在队友的帮助下一一化解,真的非常感谢队友们对我的帮助。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号