牛客SQL-employees表(二):226-255
226. 将employees表的所有员工的last_name和first_name拼接起来作为Name,中间以一个空格区分
注:sqllite中字符串拼接为 || 符号,不支持concat函数;mysql支持concat函数
/*
# CONCAT() 用法1
SELECT CONCAT(CONCAT(last_name, ' '), first_name) AS Name -- 双引号也可
FROM employees
# CONCAT() 用法2
SELECT CONCAT(last_name, ' ', first_name) AS Name
FROM employees
*/
# CONCAT_WS()
SELECT CONCAT_WS(" ", last_name, first_name) -- 必须空格才表示有空格
FROM employees
233. 针对salaries表emp_no字段创建索引idx_emp_no,查询emp_no为10005,使用强制索引

SELECT *
FROM salaries
FORCE INDEX(idx_emp_no)
WHERE emp_no = 10005;
/*
# 应当先创建索引,再强制索引查找(可以发现题目已经创建了,所以只需要查找)
# MySQL强制索引:FORCE INDEX(<索引名>); SELECT * FROM <表名> FORCE INDEX (<索引名>);
CREATE INDEX idx_emp_no
ON salaries(emp_no);
SELECT *
FROM salaries
FORCE INDEX(idx_emp_no) -- 注意括号
WHERE emp_no = 10005;
235. 构造一个触发器audit_log,在向employees_test表中插入一条数据的时候,触发插入相关的数据到audit中

/*
1、用 CREATE TRIGGER 语句构造触发器,用 BEFORE 或 AFTER 来指定在执行后面的SQL语句之前或之后来触发 TRIGGER
2、触发器执行的内容写在 BEGIN 与 END 之间
3、触发器中可以通过 NEW 获得触发事件之后2对应的tablename的相关列的值,OLD 获得触发事件之前的2对应的tablename的相关列的值
*/
CREATE TRIGGER audit_log AFTER INSERT ON employees_test
FOR EACH ROW -- 注意insert后用on,for each row,不能少,否则会报错
BEGIN
INSERT INTO audit VALUE (NEW.ID, NEW.NAME); -- 必须有分号
END;
# 理解为 INSERT INTO audit (EMP_NO, NAME) VALUES (NEW.ID, NEW.NAME)。这里的 NEW.ID 是 触发器执行后,audit_log 表中 ID 字段的值,要将其插入到 audit 表的 EMP_NO 字段中
后台会往employees_test插入一条数据: INSERT INTO employees_test (ID,NAME,AGE,ADDRESS,SALARY)VALUES (1, 'Paul', 32, 'California', 20000.00 );
然后从audit里面使用查询语句: SELECT * FROM audit;
236. 删除emp_no重复的记录,只保留最小的id对应的记录

删除后titles_test表为(注:最后会select * from titles_test表来对比结果)
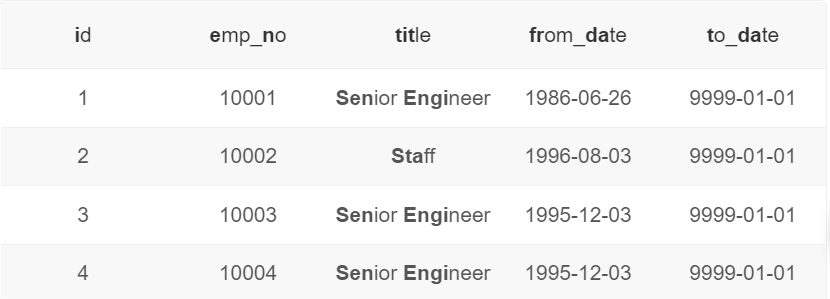
DELETE a
FROM titles_test a, titles_test b -- 也就是FROM titles_test t1 JOIN titles_test t2
WHERE a.emp_no = b.emp_no
AND a.id > b.id
237. 将所有to_date为9999-01-01的全部更新为NULL,且 from_date更新为2001-01-01
更新后 titles_test 表的值:
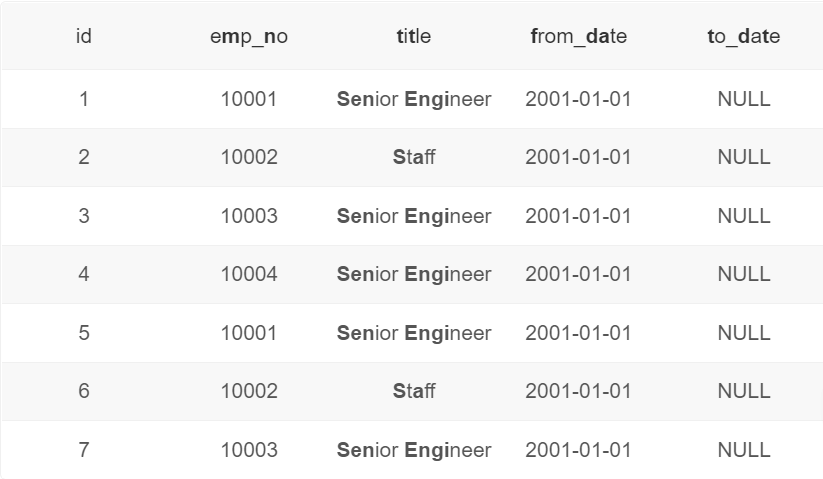
UPDATE titles_test
SET to_date = NULL, from_date = '2001-01-01' -- set 后面的内容用逗号隔开,而不是 and
WHERE to_date = '9999-01-01';
/*
1. Update 语句用于修改表中的数据:UPDATE 表名称 SET 列名称 = 新值 WHERE 列名称 = 某值
2. is null 和 =null 都可以用在判断是否为空时,在这个地方不是在判断,而是在做赋值操作,所以只能用 =null
*/
238. 将id=5以及emp_no=10001的行数据替换成id=5以及emp_no=10005,其他数据保持不变(使用replace实现,直接使用update会报错)
# 方法1. 全字段更新替换:由于 REPLACE 的新记录中 id=5,与表中的主键 id=5 冲突,故会替换掉表中 id=5 的记录,否则会插入一条新记录(例如新插入的记录 id=10)。并且要将所有字段的值写出,否则将置为空
# replace 语句的运用:replace into table values( , , , ),不可以用where条件定位
REPLACE INTO titles_test
VALUES (5, 10005, 'Senior Engineer', '1986-06-26', '9999-01-01'); -- 因为 id 和 emp_no 都是 int 型,加单引号的话就成字符串了,所以最好不要加单引号
# 方法2:运用 REPLACE(X,Y,Z) 函数:其中X是要处理的字符串,Y是X中将要被替换的字符串,Z是用来替换Y的字符串,最终返回替换后的字符串。以下语句用 UPDATE 和 REPLACE 配合完成,用 REPLACE 函数替换后的新值复制给 id=5 的 emp_no。REPLACE 的参数为整型时也可通过
UPDATE titles_test
SET emp_no = REPLACE(emp_no, 10001, 10005)
WHERE id = 5;
# 直接用 UPDATE 的方法
UPDATE titles_test
SET emp_no = 10005
WHERE id = 5;
239. 将titles_test表名修改为titles_2017
# 方法1
ALTER TABLE titles_test
RENAME TO titles_2017
# 方法2
RENAME TABLE titles_test TO titles_2017
240. 在audit表上创建外键约束,其emp_no对应employees_test表的主键id
(以下2个表已经创建了)
# alter table 表名 add constraint 外键约束名 foreign key(列名) references 引用外键表
ALTER TABLE audit
ADD CONSTRAINT FOREIGN KEY(emp_no)
REFERENCES employees_test(id);
242. 写出更新语句,将所有获取奖金的员工当前的(salaries.to_date='9999-01-01')薪水增加10%。(emp_bonus里面的emp_no都是当前获奖的所有员工,不考虑获取的奖金的类型)
UPDATE salaries
SET salary = salary * 1.1
WHERE to_date = '9999-01-01' -- 当前薪水
AND emp_no IN (
SELECT emp_no
FROM emp_bonus
)
244. 将employees表中的所有员工的last_name和first_name通过(')连接起来。(sqlite不支持concat,请用||实现,mysql支持concat)
与T226类似
# 方法1
SELECT CONCAT(last_name, "'", first_name) AS name -- CONCAT(last_name, '\'', first_name)
FROM employees
# 方法2
SELECT CONCAT_WS('\'', last_name, first_name) AS name
FROM employees\
245. string表-统计每个字符串中逗号出现的次数cnt
SELECT id, LENGTH(string) - LENGTH(REPLACE(string, ',', '')) AS cnt
FROM strings
/*
确定“,”出现的次数,将“,”在字符串中都去掉,用原来的字符串的长度减去去掉后的字符串的长度,即可得出
replace 函数用法:replace(列名,被替换的值,替换值)
*/
246. 将employees中的first_name,并按照first_name最后两个字母升序进行输出
/*
# right(str, num) 函数。从右边开始截取str字符串num长度
SELECT first_name
FROM employees
ORDER BY RIGHT(first_name, 2);
*/
# substr(str, start, len)函数。截取字符串str从start位置开始len长度,start为负时从末尾开始计算
SELECT first_name
FROM employees
ORDER BY SUBSTR(first_name, LENGTH(first_name) - 1, 2)
# ORDER BY SUBSTR(first_name, LENGTH(first_name) - 1) -- 总长度减1就是从倒数第二位开始
# ORDER BY SUBSTR(first_name, -2)
247. 按照dept_no进行汇总,属于同一个部门的emp_no按照逗号进行连接,结果给出dept_no以及连接出的结果employees
SELECT dept_no, GROUP_CONCAT(emp_no, SEPARATOR ',') AS employees
FROM dept_emp
GROUP BY dept_no
# 严谨点可以写为 GROUP_CONCAT(DISTINCT emp_no ORDER BY emp_no SEPARATOR ',')
248. 查找排除在职(to_date = '9999-01-01' )员工的最大、最小salary之后,其他的在职员工的平均工资avg_salary
SELECT AVG(salary) AS avg_salary
FROM salaries
WHERE to_date = '9999-01-01'
AND salary NOT IN (SELECT MIN(salary) FROM salaries WHERE to_date = '9999-01-01')
AND salary NOT IN (SELECT MAX(salary) FROM salaries WHERE to_date = '9999-01-01')
# 由于可能存在多个最大salary,只用salary去做分组出来的结果不对
# min()和max()都是聚合函数,是对结果集中的列进行操作而不是对单个记录进行操作,不能在同一个select语句中操作
249. 分页查询employees表,每5行一页,返回第2页的数据
SELECT *
FROM employees
LIMIT 5 OFFSET 5 -- LIMIT 5, 5
# 每页5行,返回第2页,即返回第6-10行数据
/*
分页查询:
1. select * from tableName limit i, n -- i与n之间使用英文逗号","隔开
2. select * from tableName limit n offset i
i:查询结果的索引值(默认从0开始),也就是偏移量,当i=0时可省略i
n:查询结果返回的数量
*/
251. 使用含有关键字exists查找未分配具体部门的员工的所有信息
# 如果外表有n条记录,那么exists查询就是将这n条记录逐条取出,判断n遍exists条件。只要exists子句中有记录返回,那么外部的select子句就会返回当前记录。因此使用exists(a != b)不正确
SELECT *
FROM employees
WHERE NOT EXISTS (
SELECT emp_no
FROM dept_emp
WHERE emp_no = employees.emp_no
)
/*
如果可以用 IN 查询:
SELECT *
FROM employees
WHERE emp_no NOT IN (
SELECT emp_no
FROM dept_emp
)
*/
253. 给出emp_no、first_name、last_name、奖金类型btype、对应的当前薪水情况salary以及奖金金额bonus。bonus结果保留一位小数,输出结果按emp_no升序排序
SELECT emp_no, first_name, last_name, btype, salary, ROUND(per * salary , 2) AS bonus
FROM (
employees INNER JOIN (
SELECT emp_no, btype, salary,
(CASE btype WHEN 1 THEN 0.1
WHEN 2 THEN 0.2
ELSE 0.3
END) AS per
FROM emp_bonus t2 INNER JOIN salaries t3 USING(emp_no)
WHERE to_date = '9999-01-01'
) b USING(emp_no) -- 需起名
) -- 不需起名
ORDER BY emp_no
254. 按照salary的累计和running_total,其中running_total为前N个当前( to_date = '9999-01-01')员工的salary累计和,其他以此类推
# 方法1. 窗口函数
SELECT
emp_no,
salary,
SUM() OVER(ORDER BY emp_no) AS running_total
FROM salaries
WHERE to_date = '9999-01-01'
/*
# 方法2, 自联接:关联小于等于表t1编号的表t2后,对表t2的salary求和
SELECT t1.emp_no, t1.salary, SUM(t2.salary) AS running_total
FROM salaries t1 JOIN salaries t2 ON (t1.emp_no >= t2.emp_no AND t1.to_date = '9999-01-01' AND t2.to_date = '9999-01-01')
GROUP BY t1.emp_no
ORDER BY t1.emp_no
*/
255. 在不打乱原序列顺序的情况下,输出按first_name排升序后,取奇数行的first_name
# 方法1. 窗口函数
SELECT first_name
FROM (
SELECT
first_name,
RANK() OVER (ORDER BY first_name) AS ranking -- 用 ROW_NUMBER() 也可以
FROM employees
ORDER BY emp_no # 用窗口函数输出的结果会根据first_name排序,但是题目要求输出结果的顺序还是按照建表的顺序,因此要加上这句才能通过
) tt
WHERE ranking % 2 = 1
/*
# 方法2. 条件语句
SELECT first_name
FROM employees t1
WHERE (
SELECT COUNT(*)
FROM employees t2
WHERE t1.first_name >= t2.first_name
) % 2 = 1
# 方法3. 子查询(执行顺序为 t1-t2-t3)
SELECT first_name
FROM (
SELECT
first_name, (
SELECT COUNT(*) -- 对 t2.first_name 进行排名标号。即在给定 t2.first_name的情况下,不大于 t2.first_name 的 t3.first_name 的个数有多少,该个数刚好与 t2.first_name 的排名标号匹配,且将该值命名为 rownum
FROM employees t1
WHERE t1.first_name <= t2.first_name
) AS rownum
FROM employees t2
) t3
WHERE rownum % 2 = 1
*/
