【回溯】力扣46:全排列
给定一个不含重复数字的数组 nums ,返回其 所有可能的全排列 。可以按任意顺序返回答案。
示例1:
输入:nums = [1,2,3]
输出:[[1,2,3],[1,3,2],[2,1,3],[2,3,1],[3,1,2],[3,2,1]]
示例2:
输入:nums = [1]
输出:[[1]]
回溯法
这个问题可以看作有 n 个排列成一行的空格,需要从左往右依此填入题目给定的 n 个数,每个数只能使用一次。那么很直接地可以想到一种穷举算法,即从左往右每一个位置都依此尝试填入一个数,看能不能填完这 n 个空格,在程序中可以用「回溯法」来模拟这个过程。
回溯法与搜索引擎:
搜索引擎帮助我们在庞大的互联网上搜索信息。搜索引擎的「搜索」和「回溯搜索」算法里「搜索」的意思是一样的。回溯算法用于 搜索一个问题的所有的解 ,通过深度优先遍历的思想实现。搜索问题的解,可以通过遍历实现。所以很多教程把「回溯法」称为爆搜(暴力解法)。
回溯法与动态规划
回溯法与动态规划都可以用于求解多阶段决策问题(求解一个问题分为很多步骤(阶段),且每一个步骤(阶段)可以有多种选择)。
但是,动态规划只需要求评估最优解是多少,最优解对应的具体解是什么并不要求。因此很适合应用于评估一个方案的效果;回溯算法可以搜索得到所有的方案(当然包括最优解),但是本质上它是一种遍历算法,时间复杂度很高。
回溯法的全排列问题理解
以数组 [1, 2, 3] 的全排列为例:
-
先写以 1 开头的全排列,它们是:[1, 2, 3], [1, 3, 2],即 1 + [2, 3] 的全排列(注意:递归结构体现在这里)
-
再写以 2 开头的全排列,它们是:[2, 1, 3], [2, 3, 1],即 2 + [1, 3] 的全排列
-
最后写以 3 开头的全排列,它们是:[3, 1, 2], [3, 2, 1],即 3 + [1, 2] 的全排列
按顺序枚举每一位可能出现的情况,已经选择的数字在当前要选择的数字中不能出现。按照这种策略搜索就能够做到不重不漏。这样的思路,可以用一个树形结构表示:
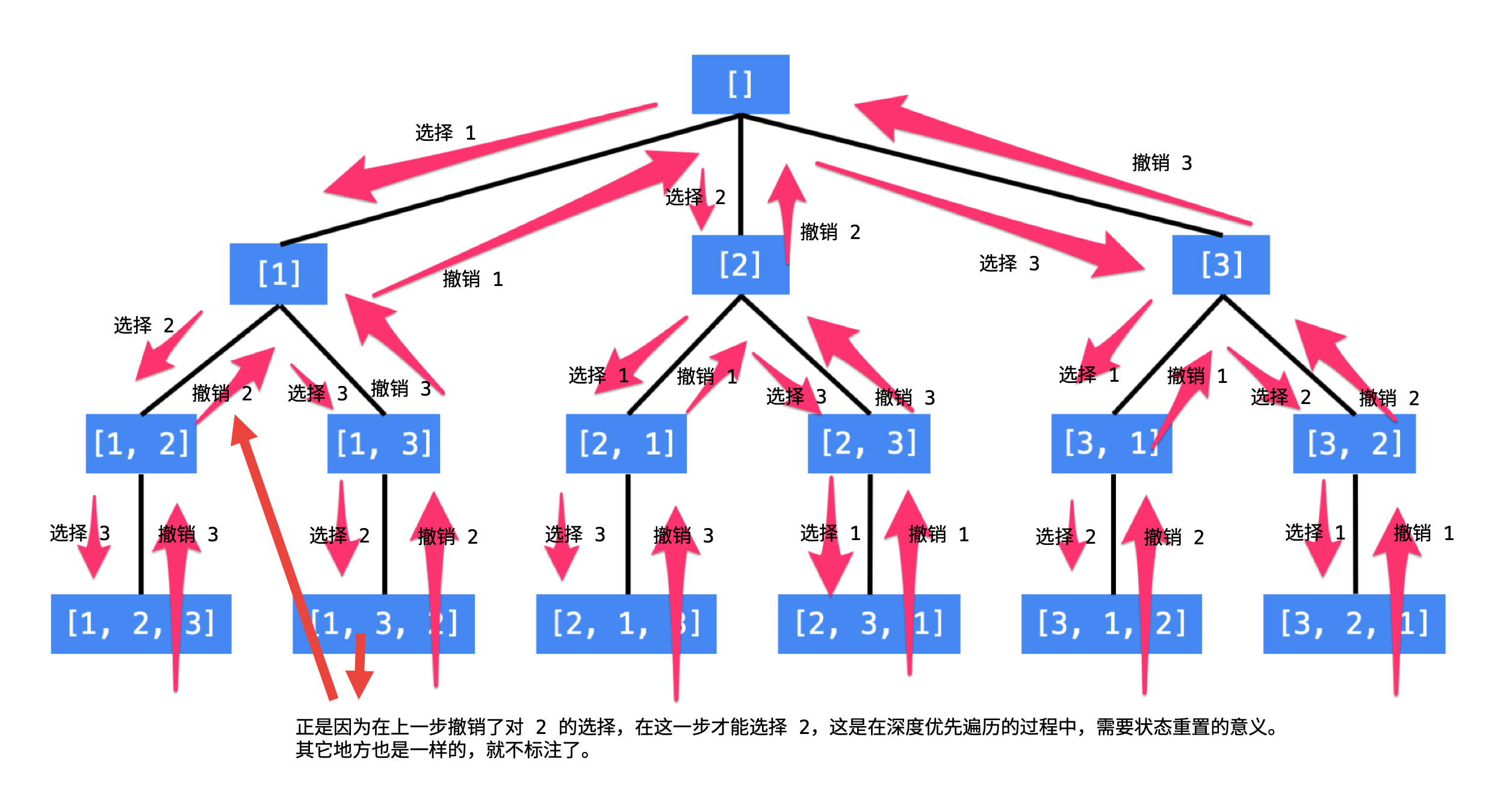
-
每一个结点表示了求解全排列问题的不同的阶段,这些阶段通过变量的「不同的值」体现,这些变量的不同的值,称之为「状态」
-
使用深度优先遍历有「回头」的过程,在「回头」以后,状态变量需要设置成为和先前一样 ,因此在回到上一层结点的过程中,需要撤销上一次的选择,这个操作称之为「状态重置」
-
深度优先遍历,借助系统栈空间,保存所需要的状态变量,在编码中只需要注意遍历到相应的结点的时候,状态变量的值是正确的,具体的做法是:往下走一层的时候,depth 变量在尾部追加,而往回走的时候,需要撤销上一次的选择,也是在尾部操作,因此 depth 变量是一个栈
-
深度优先遍历通过「回溯」操作,实现了全局使用一份状态变量的效果
- 注意:正是由于变量 depth 所指向的数组在遍历过程中只有一份,遍历完成以后,回到了根结点,成为空列表,所以每次加入结果集中的数组不是
nums而是nums[:]
- 注意:正是由于变量 depth 所指向的数组在遍历过程中只有一份,遍历完成以后,回到了根结点,成为空列表,所以每次加入结果集中的数组不是
步骤
-
定义递归函数 backtrack(index, output) 表示从左往右填到第 index 个位置,当前排列为 output。 那么整个递归函数分为两个情况:
-
如果 index == n,说明已经填完了 n 个位置(注意下标从 0 开始),找到了一个可行的解,那么将 output 放入答案数组中,递归结束
-
如果 index < n,考虑这第 index 个位置要填哪个数
-
不能填已经填过的数,因此很容易想到的一个处理手段是定义一个标记数组 vis 来标记填过的数,那么在填第 index 个数的时候遍历题目给定的 n 个数,如果这个数没有被标记过,就尝试填入,并将其标记,继续尝试填下一个位置,即调用函数 backtrack(index + 1, output)。回溯的时候要撤销这一个位置填的数以及标记,并继续尝试其他没被标记过的数
-
标记数组增加了算法的空间复杂度。为了减少空间复杂度,可以将题目给定的 n 个数的数组 nums 划分成左右两个部分,左边的表示已经填过的数,右边表示待填的数,在回溯的时候只要动态维护这个数组即可
- 具体而言,假设已经填到第 index 个位置,那么 nums 数组中 [0, index−1] 是已填过的数的集合,[index, n − 1] 是待填的数的集合。然后尝试用 [index, n−1] 里的数去填第 index 个数,假设待填的数的下标为 i,那么填完以后将第 i 个数和第 index 个数交换,即能使得在填第 index + 1 个数的时候 nums 数组的 [0, index] 部分为已填过的数,[index, n − 1] 为待填的数,回溯的时候交换回来即能完成撤销操作
示例:
假设有 [2,5,8,9,10] 这 5 个数要填入,填到第 3 个位置时,已经填了 [8,9] 两个数,那么这个数组目前为 [8,9 ∣ 2,5,10] 这样的状态,分隔符区分了左右两个部分。如果现在要填数 10,为了维护数组,将 2 和 10 交换,即能使得数组继续保持分隔符左边的数已经填过,而右边的为待填 [8,9,10 ∣ 2,5] 。- 注意:交换方法生成的全排列并不是按字典序存储在答案数组中的,如果题目要求按字典序输出,还是要用标记数组或者其他方法
-
-
输出过程示例
递归之前 => [1]
递归之前 => [1, 2]
递归之前 => [1, 2, 3]
递归之后 => [1, 2]
递归之后 => [1]
递归之前 => [1, 3]
递归之前 => [1, 3, 2]
递归之后 => [1, 3]
递归之后 => [1]
递归之后 => []
递归之前 => [2]
递归之前 => [2, 1]
递归之前 => [2, 1, 3]
递归之后 => [2, 1]
递归之后 => [2]
递归之前 => [2, 3]
递归之前 => [2, 3, 1]
递归之后 => [2, 3]
递归之后 => [2]
递归之后 => []
递归之前 => [3]
递归之前 => [3, 1]
递归之前 => [3, 1, 2]
递归之后 => [3, 1]
递归之后 => [3]
递归之前 => [3, 2]
递归之前 => [3, 2, 1]
递归之后 => [3, 2]
递归之后 => [3]
递归之后 => []
输出 => [[1, 2, 3], [1, 3, 2], [2, 1, 3], [2, 3, 1], [3, 1, 2], [3, 2, 1]]
新建标记数组方法代码
class Solution:
def permute(self, nums: List[int]) -> List[List[int]]:
n = len(nums)
if n <= 1:
return [nums]
res = []
used = [False] * n # 标记数组:选定一个数的时候才将这个数组的相应位置设置为 true
def dfs(array, depth, stack, used, res):
n = len(array)
if depth == n: # 所有元素已被访问过
res.append(stack[:])
return # return res
for i in range(n):
if used[i]: # 如果当前元素已经被使用过则跳过
continue
stack.append(array[i])
used[i] = True
dfs(array, depth + 1, stack, used, res)
stack.pop() # 记得要撤回,然后取消标记
used[i] = False
dfs(nums, 0, [], used, res)
return res
递归函数里的参数其实没必要写那么多,只写必要参数比较好,不然思维容易被参数搅乱
class Solution:
def permute(self, nums: List[int]) -> List[List[int]]:
n = len(nums)
if n <= 1:
return [nums]
res = []
stack = []
used = [False] * n # 标记数组:选定一个数的时候才将相应位置设置为 true
def dfs(depth):
if depth == n: # 所有元素已被访问过
res.append(stack[:]) # 注意:加入的不是 num,因为变量 depth 所指向的数组在遍历过程中只有一份,遍历完成以后,回到了根结点,成为空列表
return # return res
for i in range(n):
if used[i]: # 如果当前元素已经被使用过则跳过
continue
stack.append(nums[i]) # 选择树上的元素加入栈中,并标记已选
used[i] = True
dfs(depth + 1) # 继续递归下一个数
stack.pop() # 状态重置,撤销选择并取消标记
used[i] = False
dfs(depth = 0)
return res
时间复杂度:O(N×N!)。
空间复杂度:O(N×N!)。递归树深度 logN,全排列个数 N!,每个全排列占空间 N。取较大者。
分区方法代码
class Solution:
def permute(self, nums: List[int]) -> List[List[int]]:
n = len(nums)
if n <= 1:
return [nums]
res = []
def backtrack(index = 0):
if index == n: # 所有数都填完了
res.append(nums[:])
# 回溯,动态维护数组 nums
for i in range(index, n):
nums[index], nums[i] = nums[i], nums[index] # 选中
backtrack(index + 1) # 继续递归 填入下一个数
nums[index], nums[i] = nums[i], nums[index] # 撤销
backtrack()
return res
时间复杂度:O(n×n!),其中 n 为序列的长度。算法的复杂度首先受 backtrack 的调用次数制约,backtrack 的调用次数为 次,其中 P(n, k) 是 n 的 k - 排列,或者部分排列,backtrack 的调用次数是 O(n!) 的。而对于 backtrack 调用的每个叶结点(共 n! 个),需要将当前答案使用 O(n) 的时间复制到答案数组中,相乘得时间复杂度为 O(n×n!)。因此时间复杂度为 O(n×n!)O(n \times n!)O(n×n!)。
空间复杂度:O(n),其中 n 为序列的长度。除答案数组以外,递归函数在递归过程中需要为每一层递归函数分配栈空间,所以这里需要额外的空间且该空间取决于递归的深度,这里可知递归调用深度为 O(n)。
python一行
import itertools
class Solution:
def permute(self, nums: List[int]) -> List[List[int]]:
return list(itertools.permutations(nums))
作者:powcai
链接:https://leetcode.cn/problems/permutations/solution/hui-su-suan-fa-by-powcai-2/



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· winform 绘制太阳,地球,月球 运作规律
· AI与.NET技术实操系列(五):向量存储与相似性搜索在 .NET 中的实现
· 超详细:普通电脑也行Windows部署deepseek R1训练数据并当服务器共享给他人
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理
· 上周热点回顾(3.3-3.9)