Triplet Loss
Ranking loss在广泛的领域被使用。它有很多别名,比如对比损失(Contrastive Loss),边缘损失(Margin Loss),铰链损失(Hinge Loss)。还有常见的三元组损失(Triplet Loss)。
首先说一下什么是度量学习:
区别于常见的分类和回归。ranking loss的目标是去预测样本之间的相对距离,这个任务常常被称为度量学习(Metric learning)。
Ranking Loss的使用是比较灵活的,我们只需要一个可以衡量样本点之间相似度度量的东西就可以了。度量可以是二值的(相似/不相似)。也可以是连续的,比如余弦相似度。
使用ranking loss的过程中,我们可以从数据中抽出一些特征。然后基于一个距离度量函数以度量这些表达之间的相似度。以便于对特定的样本对产生特定的相似度度量。这种简单的度量被证明能够学习出强大的表征。
Ranking loss的表达式:
- 使用一对数据点。
- 使用三元组数据点。
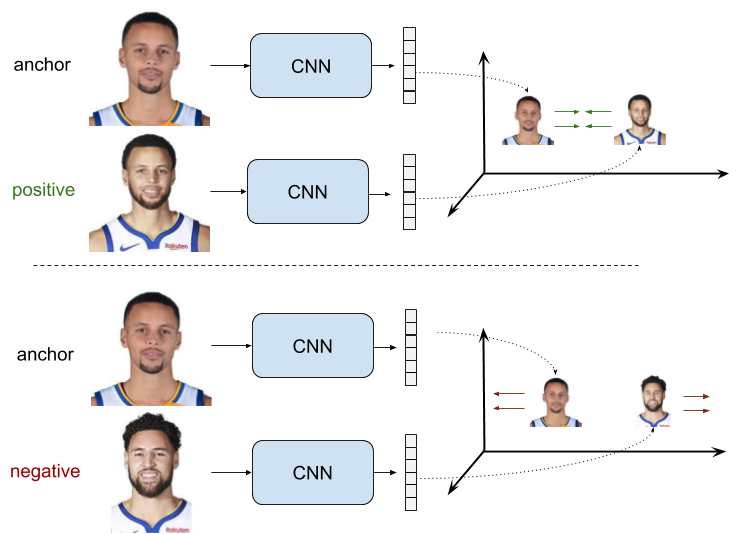
这个图就是ranking loss用于人脸验证的例子。CNN的权重是共享的,我们称之为Siamese Net。
在使用一对数据点进行训练输入使用时,正样本对由\((x_a, x_p)\)组成,这俩在我们需要评价的指标上是一致的。即度量上是相似的,这常常体现在标签相似。而\((x_a, x_n)\)这俩在我们需要评价的指标上是不一致的。即度量上是不相似的,这常常体现在标签不一致。
在正样本对中,我们常常需要它们靠的越近越好。在负样本对上,我们则需要它们的距离起码大于一个人为设定的阈值。
这里设置阈值的目的在于,当负样本之间的距离足够大之后,表征已经足够好了。没必要再去优化它了,将进一步的训练关注在更加难的样本中。一个unified的表达如下:
三元组对的Ranking Loss:
三元组的ranking loss被称之为triplet loss。在这个设置中,三元组由\((x_a, x_p, x_n)\)组成,其目标是,负样本对之间的距离和正样本之间的距离大于一个阈值m。可以表达为:
这个时候,根据他们之间的距离大小,可以分为:hard triplet, semi-hard triplet,easy triplet。
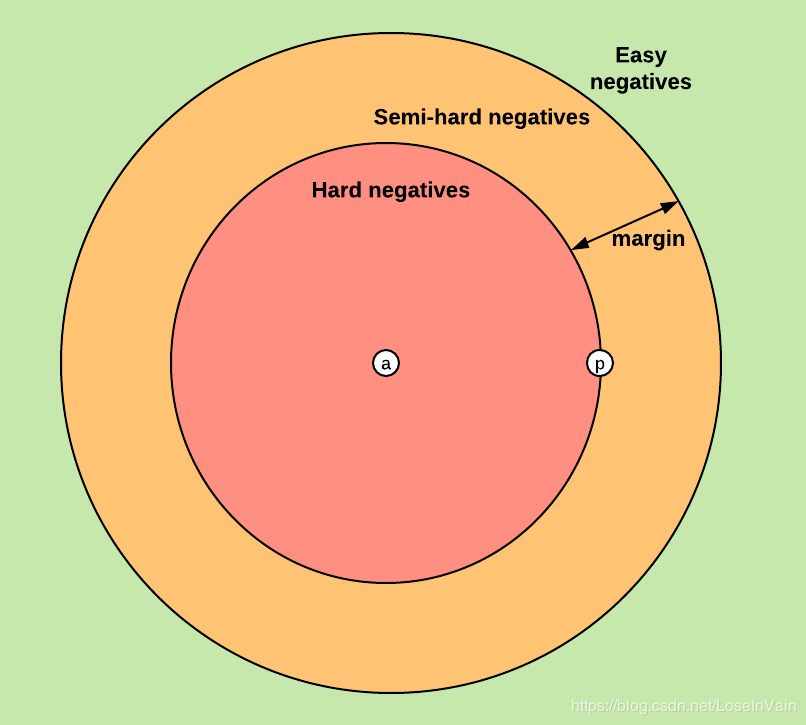
在训练的时候,一个重要的选择就是对于负样本进行挑选。称之为,负样本选择或者三元组采集(triplet mining)。一个原则时,easy triplet应该尽量避免被采集到,因为loss为0,所以对训练并没有贡献。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号