
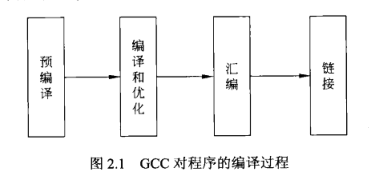
编译
1.编译过程
1.1预编译
将程序中的头文件包含进代码中,并进行一些宏替换
gcc -E test.c -o test.i //—E:预编译 .i文件为预编译后的文件
1.2编译和优化
将用户写的代码翻译成汇编代码,生成汇编代码文件,汇编代码和机器操作码之间是一对一的关系
gcc -S test.i -o test.s //—S:只进行编译而不进行汇编 .s文件为汇编代码文件 gcc -S test.c -o test.s //也可以直接对test.c操作
1.3汇编
1)GNU使用汇编器as将汇编代码汇编成CPU可识别的二进制代码,生成目标文件,默认后缀为.o(windows下默认为.obj)
2)目标文件仅解析了文件内部的变量和函数,对所引用的在其他文件中或库中的函数和变量还没有解析,所以还不可以执行
gcc -c test.s -o test.o //—c:生成目标文件 .o文件为目标文件 gcc -c test.c -o test.o //也可以直接对test.c操作
1.4链接
1)将所有的目标文件以某种方式链接起来,生成可执行文件,可执行文件的默认后缀为.out(windows下默认为.exe)
gcc test.o -o test gcc test.c -o test //直接一步到位
2)函数库一般分为静态库和动态库两种
3)静态库是指链接时,把库文件的代码全部加入到可执行文件中,因此生成的可执行文件比较大,但在运行时也就不再需要库文件 了。其后缀名一般为”.a”
4)动态库与之相反,在编译链接时并没有把库文件的代码加入到可执行文件中,而是在程序执行时动态地加载库,一来这样可以减小执行文件地大小,二里更新库后程序也不用重新编译。动态库一般后缀名为”.so”。gcc在编译时默认使用动态库
1.5gcc和g++
1)gcc和g++的误区:gcc只能编译c代码,g++只能编译c++代码,其实二者都可以编译c或cpp文件,但是请注意:
- 对于 .c和.cpp文件,gcc分别当做c和cpp文件编译,对于 .c和.cpp文件,g++则统一当做cpp文件编译
- 在编译阶段,g++会调用gcc,在链接阶段,gcc不能自动和c++库链接,所以要先用gcc进行预编译、编译、汇编,再用g++进行链接,或者使用 gcc cfq.cpp -lstdc++ -o cfq
- 为了统一起见,干脆编译/链接统统用g++了,这就给人一种错觉,好像cpp程序只能用g++似的
2)常用参数:

2.Makefile
2.1规则

1)许多程序在其makefile文件中将 all 指定为第一个目标,然后列出其他的all所依赖的目标。这个约定可以很清晰的指出当没有指定目标时makefile应尝试构建的默认目标。我们建议遵守这个约定
2.2变量
1)用户自定义变量:用户可以定义自己变量

2)预定义变量:Makefile中已经定义的变量

3)自动变量:为了Makefile看起来没那么冗长,用自动变量来代表目标文件和依赖文件


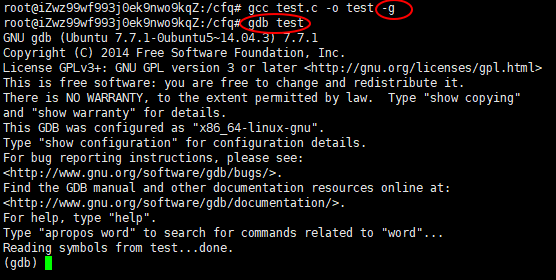
3.gdb调试
3.1常用命令
1)要是用gdb进行调试,在编译程序的时候必须加入-g选项,只有设置了-g选项,gcc才会向程序加入"锲子",GDB才能够利用这些锲子与程序交互

2)加载程序:
3)设置输入参数:

4)打印源代码内容:

list 1,20 //显示第一行到第二十行
5)设置断点:

6)多线程:

7)查看函数调用的栈帧:
frame:打印当前所处在的栈帧的简要信息
info frame:打印当前所处在的栈帧的详细信息
backtrace:打印当前全部栈帧的简要信息
frame N:切换到栈编号为N的上下文中
3.2core
1)core文件:程序崩溃后,产生“segmentation fault (core dumped)”的错误信息,这时会生成一个具有内存信息、寄存器状态、堆栈信息和调试信息的文件,名为core
2)发生core dumped的原因:
- 内存访问越界 ,如:数组越界、字符串无\n结束符、字符串读写越界
- 多线程程序中使用了线程不安全的函数,如不可重入函数
- 多线程读写临界资源时未加锁保护
- 非法指针,如:使用空指针(使用空指针也会崩的哦,亲测),使用野指针,使用空悬指针
- 堆栈溢出
3)core文件的默认保存路径为对应的执行程序的同一目录,默认文件名为core,若要修改,则在 /proc/sys/kernel/core_pattern 中修改,此文件的默认内容为 core
echo "/home/coredump/core.%e.%p" >/proc/sys/kernel/core_pattern //这样配置后,产生的core文件名中将带有崩溃的程序名以及它的进程ID,%e和%p会被替换成程序文件名以及进程ID,core文件将会放置到/home/coreddump下,注意:此目录必须是已存在文件系统的,不然报错;如果没写路径,直接是文件名,则保存在执行程序的同一目录下
需要说明的是,在内核中还有一个与coredump相关的设置,就是/proc/sys/kernel/core_uses_pid。如果这个文件的内容被配置成1,那么即使core_pattern中没有设置%p,最后生成的core dump文件名仍会加上进程ID
同时,在程序中使用chdir()函数更改了当前工作目录,core文件也会相应地存到那里
4)如何让系统生成core文件:
- 使用 ulimit -c 查看core开关,如果为0表示关闭,不会生成core文件;
- 使用 ulimit -c [filesize] 设置core文件大小,最小设为4,当最小设置为4之后才会生成core文件;
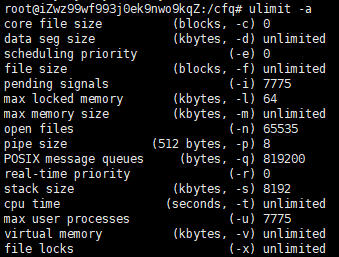
这里 file size 的单位是 blocks,可是这个 blocks 是多大呢?一般印象上是 512 字节,看了一下 bash 代码可知:
#define BLOCKSIZE(x) (((x) == POSIXBLK) ? (posixly_correct ? 512 : 1024) : (x))
- 使用 ulimit -c unlimited 设置core文件大小为不限制,这是常用的做法;
5)如何判断一个文件是core文件:
- 看名字
- core文件是ELF格式的文件,因此,可以通过readelf -h命令查看文件的头部信息:

6)查看core文件中的信息:gdb 可执行程序的名称 core文件的名称

posted on 2019-03-02 12:16 JoeChenzzz 阅读(365) 评论(0) 收藏 举报

 浙公网安备 33010602011771号
浙公网安备 33010602011771号