
关联容器
1.1标准化
1)map:STL中的标准容器
2)hash_map:非c++标准的容器
3)unordered_map:unordered_map原来属于boost分支和std::tr1中,现加入c++11中,是hash_map在STL中的实现
2.底层实现
2.1map
1)基于红黑树实现
2.2unordered_map
1)基于哈希表实现
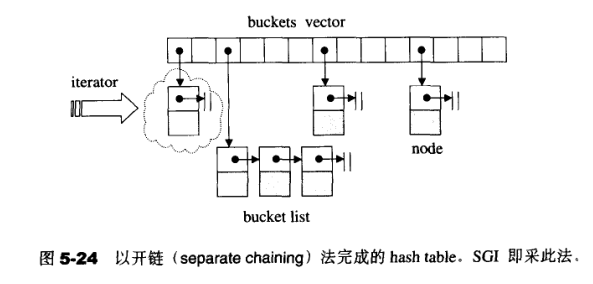
2)使用一个下标范围比较大的数组(用vector完成,以便有动态扩充能力,大小默认为28个质数中的一个),利用hash函数将key映射到数组的不同区域进行保存
3)vector中的元素称为桶,允许将不同的key映射到同一个桶中(哈希冲突),桶中用链表(并不是容器list,只是原始的链表,不含头节点)保存多个元素(节点),每次插入新节点时,插入到链表的头部而不是尾部。当桶中保存多个元素时,就要使用比较函数(默认为==运算符)来搜索这些元素来找到想要的那个
4)元素的直接地址用哈希函数生成,冲突用链地址法和比较函数解决,unordered_map的性能依赖于哈希函数的质量和桶的数量和大小
整个过程可以描述为:
- 首先分配一大片内存,形成许多桶
- 插入操作:得到key -> 通过hash函数得到hash值 -> 得到桶号(一般是hash值对桶数求模) -> 存放key和value在桶内
- 取值过程:得到key -> 通过hash函数得到hash值 -> 得到桶号(hash值对桶数求模) -> 比较桶内元素与key是否相等 -> 取出相等纪录的value
- 用户可以指定自己的hash函数与比较函数
2.3hash_map的扩容(resize函数)
1)如果总元素个数(现有元素+新增元素)大于bucket vector的大小,则进行扩容
2)由第1点可知,桶链表的最大长度和bucket vector的大小相等
3)扩容过程:
- 创建一个新vector tmp ,大小为满足总元素个数的质数
- 将旧vector buckets中桶链表上的节点一个一个地移动至 tmp对应的桶链表上
- 最后使用swap函数将buckets和tmp对调,函数结束后tmp作为局部变量被销毁
template <class V, class K, class HF, class Ex, class Eq, class A> void hashtable<V, K, HF, Ex, Eq, A>::resize(size_type num_elements_hint) { const size_type old_n = buckets.size(); if (num_elements_hint > old_n) { //确定真的需要重新配置 const size_type n = next_size(num_elements_hint); // 去28个质数的质数池里找出下一个质数 if (n > old_n) { vector<node*, A> tmp(n, (node*)0); // 设立新的 buckets __STL_TRY { // 以下处理每一个旧的bucket for (size_type bucket = 0; bucket < old_n; ++bucket) { node* first = buckets[bucket]; // 指向节点所对应之串列的起始节点 // 以下处理每一个旧bucket 所含(串列)的每一个节点 while (first) { // 串列还没结束时 // 以下找出节点落在哪一个新bucket 内 size_type new_bucket = bkt_num(first->val, n); // 以下四个动作颇为微妙 // (1) 令旧 bucket 指向其所对应之串列的下一个节点(以便迭代处理) buckets[bucket] = first->next; // (2)(3) 将当前节点安插到新bucket 内,成为其对应串列的第一个节点。 first->next = tmp[new_bucket]; tmp[new_bucket] = first; // (4) 回到旧bucket 所指的待处理串列,准备处理下一个节点 first = buckets[bucket]; } } buckets.swap(tmp); // vector::swap。新旧 buckets 对调。 // 注意,对调两方如果大小不同,大的会变小,小的会变大。 // 离开时释还local tmp的內存。 } } } }
3.key是否有序
1)map:红黑树是一棵二叉搜索树,具有排序功能,存放在map中的key-value对按照key排序
2)unordered_map:无序
4.默认支持的key的类型
1)map:内置类型或者类对象均可
2)unordered_map:内置类型或者类对象均可
3)hash_map:char、char *(会被默认当成地址,而不是字符串,小心)、const char *、unsigned char、signed char、short、unsigned short、int、unsigned int、long、unsignd long等内置类型
5.一般操作的时间复杂度
1)map:插入、查找、删除的时间复杂度为O(logn)
2)unordered_map:插入、查找、删除的时间复杂度为O(1)
6.需要定义的函数
1)map:比较函数,默认为<运算符,也可以自定义,但必须保证严格弱序:
- 两个关键字不能同时“严格弱于”对方:如果key1“严格弱于”key2,那么key2绝不能“严格弱于”key1
- 传递性:如果key1“严格弱于”key2,key2“严格弱于”key3,那么key1必须“严格弱于”key3
- 唯一性:如果key1和key2都不如果“严格弱于”对方,则认为key1和key2“等价”
2)unordered_map:哈希函数和比较函数,均可自定义,比较函数默认为==运算符
7.应用场景对比
1)选择时需要权衡三个因素:顺序性,效率,数据量,内存使用
2)如果需要排序则选择map
2)在元素数量达到一定数量级时如果要求效率优先,则采用unordered_map。但是注意:虽然unordered_map操作速度比map的速度快,但是unordered_map构造速度慢于map。其次,unordered_map由于基于哈希表,对内存的消耗高于map,是空间换时间
8.set
set与map的不同在于,元素的键值(key)就是实值(value),,实值就是键值,其余一样
9.multimap
multimap中的关键字允许重复,底层插入操作采用红黑树中的insert_equal()而非insert_unique(),红黑树的插入规则为要插入的pair的key如果比节点的key小,则向左走,如果大于等于则向右走,insert_equal()和insert_unique()都会按照此规则定位到合适的插入位置,与insert_unique()不同的是,insert_equal()会通过迭代器回溯到key可能相等的那个节点,再进行一次比较,如果相等,则不插入。具体过程可看源码
10.unordered_multimap
multimap中的关键字允许重复,底层插入操作采用哈希表的insert_equal()而非insert_unique(),插入时,定位到桶,两个函数都会遍历桶中的链表,遍历过程中如发现相同key,insert_unique()将不插入,直接返回,而insert_equal()会插入到相同key节点的后面
posted on 2019-03-22 08:18 JoeChenzzz 阅读(244) 评论(0) 收藏 举报

 浙公网安备 33010602011771号
浙公网安备 33010602011771号