



常用激活函数:Sigmoid、Tanh、Relu、Leaky Relu、ELU优缺点总结
1、激活函数的作用
什么是激活函数?
在神经网络中,输入经过权值加权计算并求和之后,需要经过一个函数的作用,这个函数就是激活函数(Activation Function)。
激活函数的作用?
首先我们需要知道,如果在神经网络中不引入激活函数,那么在该网络中,每一层的输出都是上一层输入的线性函数,无论最终的神经网络有多少层,输出都是输入的线性组合;其一般也只能应用于线性分类问题中,例如非常典型的多层感知机。若想在非线性的问题中继续发挥神经网络的优势,则此时就需要通过添加激活函数来对每一层的输出做处理,引入非线性因素,使得神经网络可以逼近任意的非线性函数,进而使得添加了激活函数的神经网络可以在非线性领域继续发挥重要作用!
更进一步的,激活函数在神经网络中的应用,除了引入非线性表达能力,其在提高模型鲁棒性、缓解梯度消失问题、将特征输入映射到新的特征空间以及加速模型收敛等方面都有不同程度的改善作用!
2、目前常见的几种激活函数
常见的激活函数主要包括如下几种:sigmoid函数、tanh函数、Relu函数、Leaky Relu函数、ELU函数,下面将分别进行介绍与分析。

Sigmoid函数

如图所示,即为sigmoid函数,可以看到,它的值域在0~1之间;此类激活函数的优缺点如下:
优点: 1、将很大范围内的输入特征值压缩到0~1之间,使得在深层网络中可以保持数据幅度不会出现较大的变化,而Relu函数则不会对数据的幅度作出约束;
2、在物理意义上最为接近生物神经元;
3、根据其输出范围,该函数适用于将预测概率作为输出的模型;
缺点:1、当输入非常大或非常小的时候,输出基本为常数,即变化非常小,进而导致梯度接近于0;
2、输出不是0均值,进而导致后一层神经元将得到上一层输出的非0均值的信号作为输入。随着网络的加深,会改变原始数据的分布趋势;
3、梯度可能会过早消失,进而导致收敛速度较慢,例如与Tanh函数相比,其就比sigmoid函数收敛更快,是因为其梯度消失问题较sigmoid函数要轻一些;
4、幂运算相对耗时。
Tanh函数

如图所示,即为Tanh函数;在下图中与Sigmoid函数对比,可见这两种激活函数均为饱和激活函数,该函数的输出范围在-1~1之间,其优缺点总结如下:
优点:1、解决了上述的Sigmoid函数输出不是0均值的问题;
2、Tanh函数的导数取值范围在0~1之间,优于sigmoid函数的0~0.25,一定程度上缓解了梯度消失的问题;
3、Tanh函数在原点附近与y=x函数形式相近,当输入的激活值较低时,可以直接进行矩阵运算,训练相对容易;
缺点:1、与Sigmoid函数类似,梯度消失问题仍然存在;
2、观察其两种形式的表达式,即2*sigmoid(2x)-1与(exp(x)-exp(-x))/(exp(x)+exp(-x)),可见,幂运算的问题仍然存在;
Relu函数
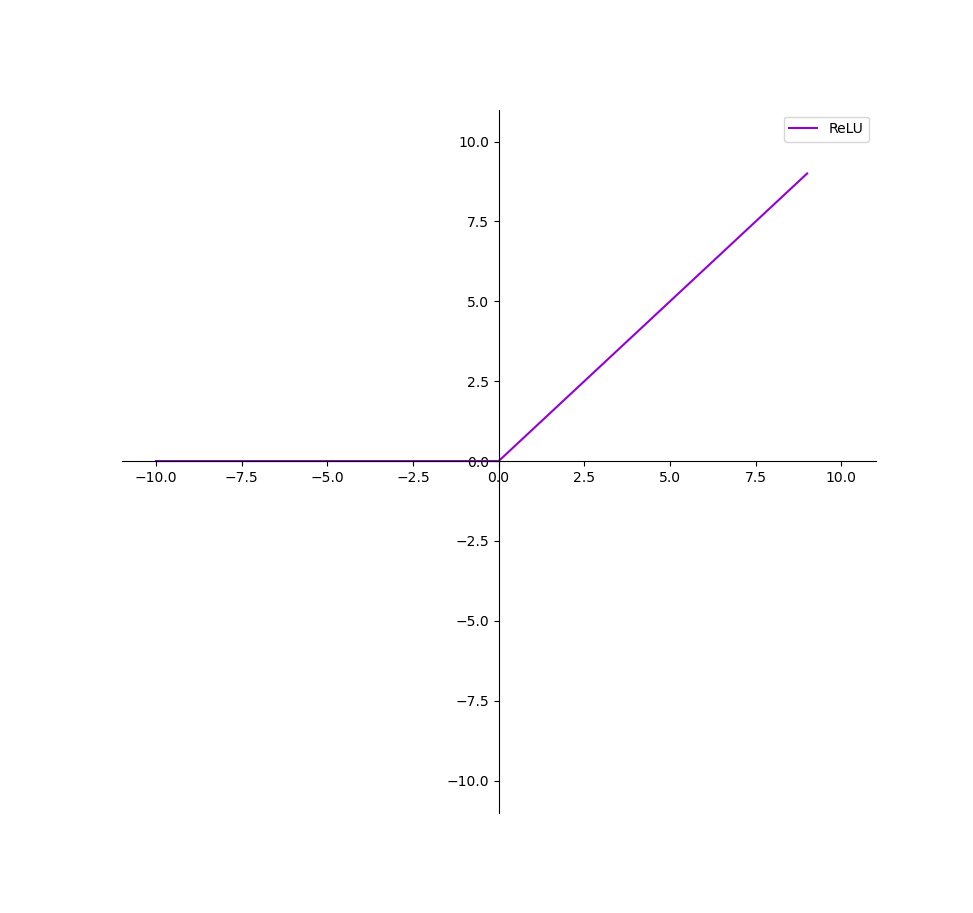
上图即为Relu函数的曲线图,可见在输入为负值时,输出均为0值,在输入大于0的区间,输出y=x,可见该函数并非全区间可导的函数;其优缺点总结如下:
优点:1、相较于sigmoid函数以及Tanh函数来看,在输入为正时,Relu函数不存在饱和问题,即解决了gradient vanishing问题,使得深层网络可训练;
2、计算速度非常快,只需要判断输入是否大于0值;
3、收敛速度远快于sigmoid以及Tanh函数;
4、Relu输出会使一部分神经元为0值,在带来网络稀疏性的同时,也减少了参数之间的关联性,一定程度上缓解了过拟合的问题;
缺点:1、Relu函数的输出也不是以0为均值的函数;
2、存在Dead Relu Problem,即某些神经元可能永远不会被激活,进而导致相应参数一直得不到更新,产生该问题主要原因包括参数初始化问题以及学习率设置过大问题;
3、当输入为正值,导数为1,在“链式反应”中,不会出现梯度消失,但梯度下降的强度则完全取决于权值的乘积,如此可能会导致梯度爆炸问题;
Leaky Relu函数
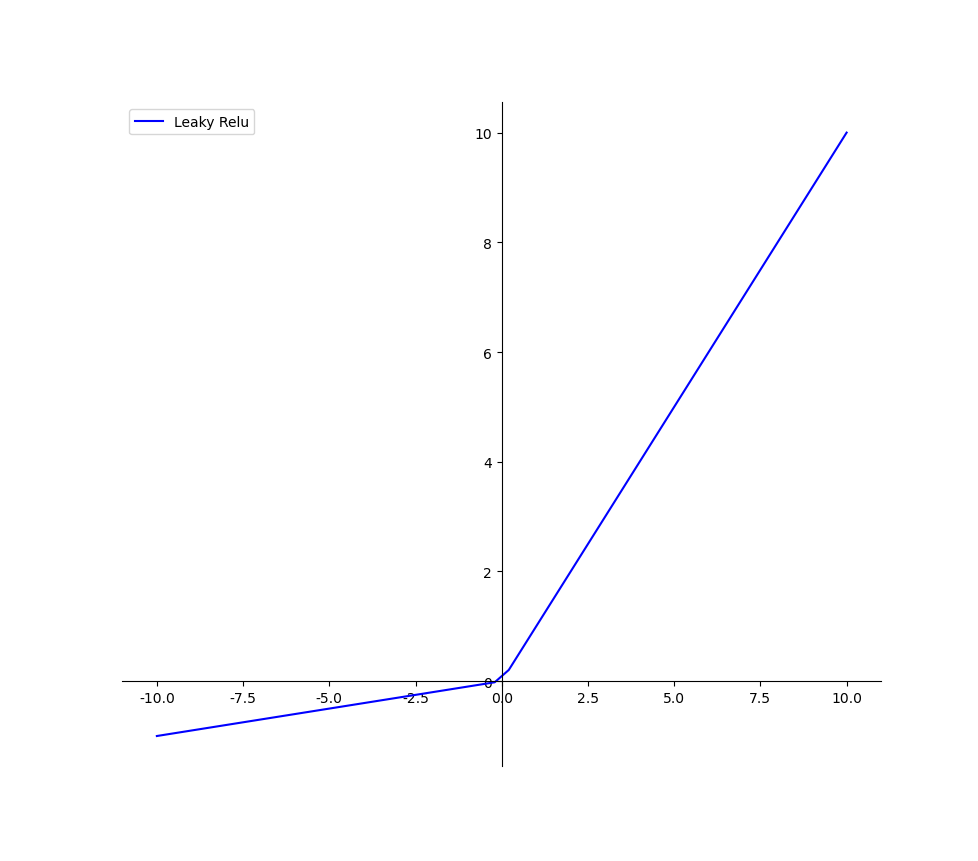
上图即为Leaky Relu函数的示意图,在x大于等于0时,y=x,x小于0时,y=α*x,图中选择的α值为0.1;其优缺点总结给如下:
优点:1、针对Relu函数中存在的Dead Relu Problem,Leaky Relu函数在输入为负值时,给予输入值一个很小的斜率,在解决了负输入情况下的0梯度问题的基础上,也很好的缓解了Dead Relu问题;
2、该函数的输出为负无穷到正无穷,即leaky扩大了Relu函数的范围,其中α的值一般设置为一个较小值,如0.01;
缺点:1、理论上来说,该函数具有比Relu函数更好的效果,但是大量的实践证明,其效果不稳定,故实际中该函数的应用并不多。
2、由于在不同区间应用的不同的函数所带来的不一致结果,将导致无法为正负输入值提供一致的关系预测。
ELU函数
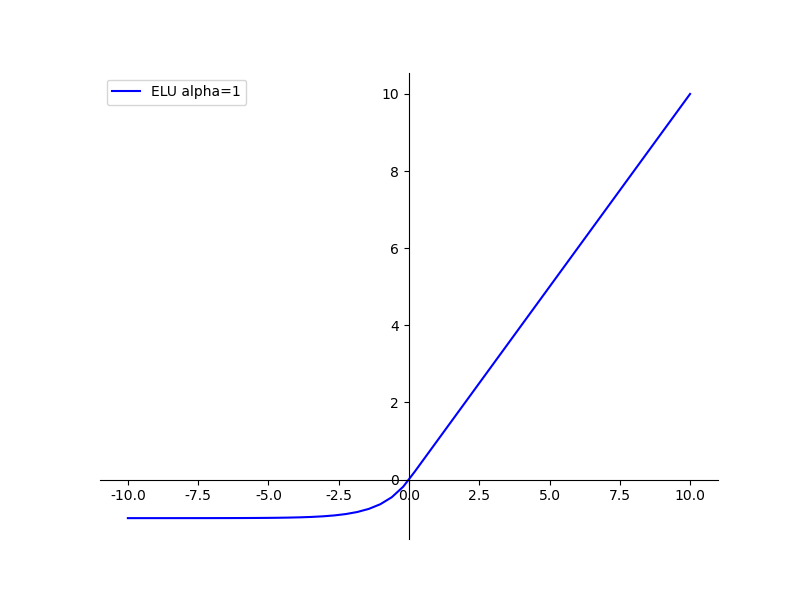
图中所示即为ELU函数,其也是Relu函数的一种变体,x大于0时,y=x,x小于等于0时,y=α(exp(x)-1),可看作介于Relu与Leaky Relu之间的函数;其优缺点总结如下:
优点:1、ELU具有Relu的大多数优点,不存在Dead Relu问题,输出的均值也接近为0值;
2、该函数通过减少偏置偏移的影响,使正常梯度更接近于单位自然梯度,从而使均值向0加速学习;
3、该函数在负数域存在饱和区域,从而对噪声具有一定的鲁棒性;
缺点:1、计算强度较高,含有幂运算;
2、在实践中同样没有较Relu更突出的效果,故应用不多;
