java面试准备
黑马面试视频:https://www.bilibili.com/video/BV1yT411H7YK/?p=3&spm_id_from=pageDriver&vd_source=5f1d3bd68827f2b51120309172941a9e
面试大全:https://knife.blog.csdn.net/article/details/121219272
八股文视频:https://www.bilibili.com/video/BV1Nf421D7Dx/?spm_id_from=trigger_reload&vd_source=5f1d3bd68827f2b51120309172941a9e
一、JDK8新特性?
接口允许default和static;lambda;stream;时间新API(LocalDateTime等)CompletableFuture等
二、集合
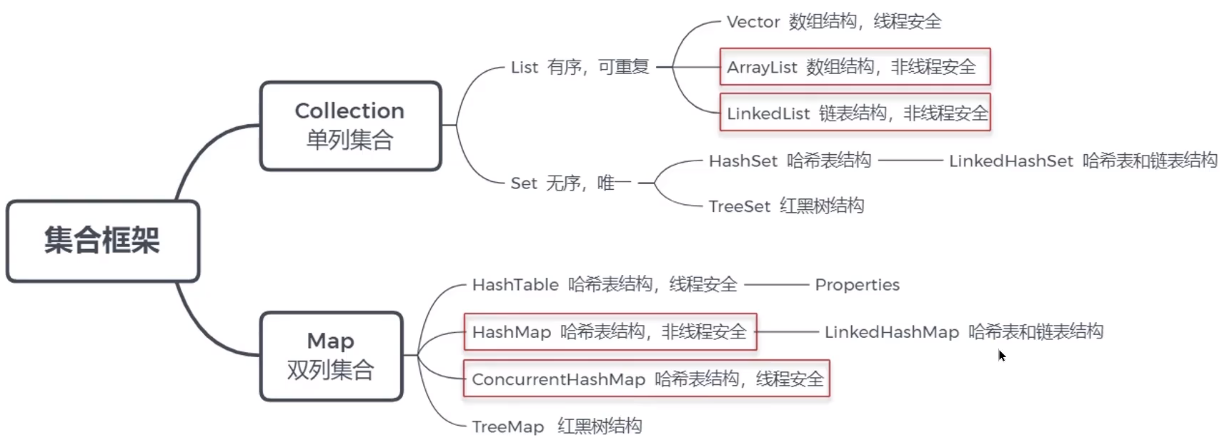
1、常用的集合有哪些?

2、集合内的数据能不能重复?
List 集合 :有序 可重复 有索引 有索引可以用for循环遍历
Set 集合 : 无序 不可重复 无索引 无索引不可用for循环遍历 可以用迭代器遍历
Map集合: 键值对集合 Key==>value Key不可重复 value可以重复并且一个value里面可以有很多值 A={1,2,3,4,5}
3、ArrayList和LinkedList的区别?
- 结构不同:
ArrayList是数组结构,LinkedList是链表结构。
- 插入删除操作:
ArrayList对末尾的新增和删除非常高效,但在开头或中间插入或删除需要移动其它元素来填补空缺,因此性能很差。
LinkedList对于任意位置的插入和删除操作都是非常高效的。
- 访问操作
ArrayList对于随机访问操作(根据索引获取元素)非常高效,因为可以通过索引直接计算出元素的位置。
LinkedList对于随机访问操作性能较差,因为需要从头节点开始遍历列表,直到找到指定索引处的元素。
- 内存占用
ArrayList的内存占用比LinkedList要小。ArrayList存储元素所需的内存是连续分配的,而LinkedList的每个节点需要额外的空间来存储指向下一个节点的引用。
三、锁
https://www.bilibili.com/video/BV1EM4m1Z7TR/?vd_source=5f1d3bd68827f2b51120309172941a9e
1、什么时候会死锁?
https://learn.skyofit.com/archives/641
四、多线程
多线程处理方案案例:https://learn.skyofit.com/archives/481
多线程相关面试题:https://blog.csdn.net/weixin_33712987/article/details/89686009
1、项目中哪些地方用到了多线程?
- 定时任务。 比如:定时处理数据进行统计等
- 异步处理。 比如:发邮件, 记录日志, 发短信等。比如注册成功后发激活邮件
- 批量处理,缩短响应时间。(比如:假设需要提供一个接口,获得多个订单的信息,按创建时间由近到远排序。这个订单信息在其他公司那里,他们只提供了查单个订单的接口,没有批量的接口。)
2、线程和进程的区别?
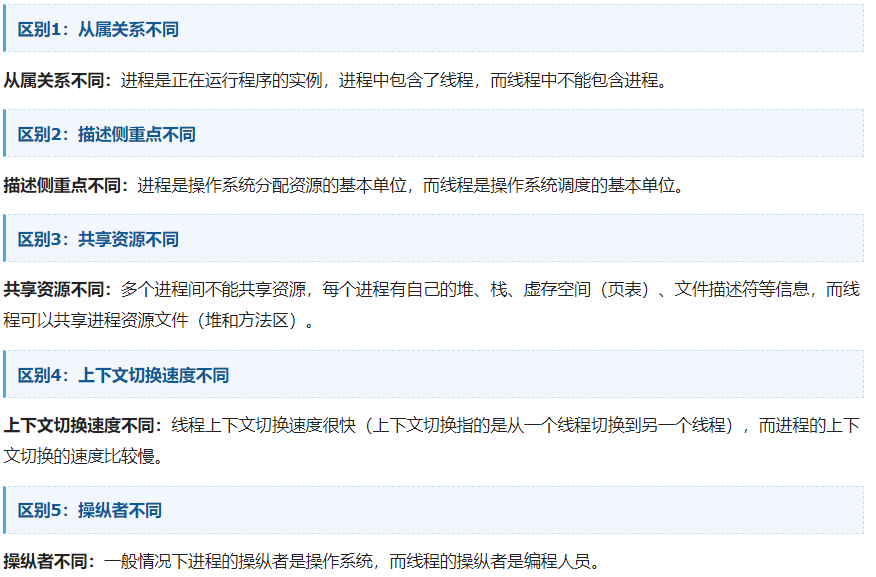
总结:进程是操作系统分配资源的基本单位,而线程是操作系统调度的基本单位。一个进程可以包含多个线程,至少包含一个线程,线程不能独立于进程而存在。进程不能共享资源,而线程可以。线程可以看作是轻量级的进程,它们的主要区别体现在:从属关系、描述侧重点、共享资源、上下文切换速度和操纵对象等不同。
2、实现线程有哪几种方式?
- 继承Thread类
- 实现Runnable接口
- 实现Callable接口
- 使用线程池
https://blog.csdn.net/AwesomeP/article/details/130175736
3、什么是死锁?如何避免死锁?
死锁是指多个进程或线程在互斥地请求资源时,由于彼此之间循环等待对方所持有的资源而无法继续执行的状态。
为了避免死锁,可以采取以下几种常见的方法:
-
避免使用多个资源:如果能够设计出仅需要一个资源的算法或方法,就可以完全避免死锁的发生。
-
破坏循环等待条件:通过定义资源的有序分配规则,使系统中所有进程按照一定的顺序请求资源,避免发生循环等待。如银行家算法(Banker's Algorithm)就是一种通过动态检测资源分配情况来避免死锁的算法。
-
使用资源预先分配策略:系统在进程启动时,要求事先申请所需的全部资源,确保资源的可用性,从而避免死锁的发生。这需要对系统进行资源管理和调度的规划。
-
引入超时机制:当一个进程等待某个资源的时间超过一定阈值时,可以放弃已获取的资源,释放资源,并重新申请。
-
死锁检测与恢复:通过使用死锁检测算法,及时发现死锁的发生,并采取必要的措施进行恢复。常见的死锁检测算法有资源分配图算法和银行家算法。
-
合理设计进程间资源竞争关系:在设计多线程程序或并发算法时,需要合理规划进程之间的资源竞争关系,避免出现不必要的资源争用情况。
以上方法都可以帮助避免死锁的发生,具体选择哪种方法取决于具体应用场景和需求。
五、MySql
1、数据库优化方式
建立索引、字段冗余(减少联表查询)、使用缓存、读写分离(写入主库 读从分库读 数据库同步机制)、分库分表(垂直拆分:不同模块拆分为多个数据库。水平拆分:当无法垂直拆分且数据量过大时使用。 分库分表之前,不要为分而分,先尽力去做力所能及的事情,例如:升级硬件、升级网络、读写分离、索引优化等等。当数据量达到单表的瓶颈时候,再考虑分库分表。)
2、索引加多了会有什么影响?
增加了存储空间的占用,降低了写操作的性能,增加了维护索引的时间成本。
3、分库分表的中间件?
Sharding-JDBC、Mycat
六、设计模式
1、项目里用到了哪些设计模式,怎么用的?
https://blog.csdn.net/weixin_43709538/article/details/135383377
单例模式(例如:枚举类)、工厂模式、观察者模式、责任链模式(拦截器)、模板模式(发短信、发通知模板)、状态模式(涉及状态变更的都可以用状态模式)、策略模式(例如微信支付,不同的支付方式对应不同的接口方法)
2、单例模式写法 https://learn.skyofit.com/archives/278
3、手写双重检验单例(为什么用volatile,为什么两次if判断)
第一次校验:也就是第一个if(singleton == null)
这个是为了代码提高代码执行效率。由于单例模式只要一次创建实例即可,所以当创建了一个实例之后,再次调用getInstance方法就不必要进入同步代码块,不用竞争锁。直接返回前面创建的实例即可。
第二次校验:也就是第二个if(singleton == null)
这个校验是防止二次创建实例。假如有一种情况,当singleton还未被创建时,线程t1调用getInstance方法,由于第一次判断singleton ==null,此时线程t1准备继续执行,但是由于资源被线程t2抢占了,此时t2页调用getInstance方法,同样的,由于singleton并没有实例化,t2同样可以通过第一个if,然后继续往下执行,同步代码块,第二个if也通过,然后t2线程创建了一个实例singleton。此时t2线程完成任务,资源又回到t1线程,t1此时也进入同步代码块,如果没有这个第二个if,那么,t1就也会创建一个singleton实例,那么,就会出现创建多个实例的情况,但是加上第二个if,就可以完全避免这个多线程导致多次创建实例的问题。
所以说:两次校验都必不可少。
4、静态代理与动态代理区别?https://learn.skyofit.com/archives/865

七、Spring相关
1、SpringBoot如何向容器注册bean?
6种方法:https://learn.skyofit.com/archives/2843

2、Spring-bean的生命周期?
简单来说Spring Bean的生命周期就是bean从被初始化到销毁的过程。 Spring Bean的生命周期分为五个阶段:实例化 Instantiation、属性赋值 Populate、初始化 Initialization、使用 In use、销毁 Destruction
八、Redis相关
1、Redis为什么那么快?
数据存放在内存中
2、Redis数据类型及其使用场景?
String(字符串)-- String数据结构是简单的key-value类型,key是String,value不仅可以是String,也可以是数字。最常用的 token
hash(哈希)-- 用一个对象来存储用户信息,商品信息,订单信息等等。
list(列表)
set(集合)
zset(有序集合)
bitmap (位图)
3、Redis持久化AOF,RDB区别?

4、Redis缓存击穿、 穿透、无底洞、雪崩 解决方案?
----缓存击穿
缓存击穿是指一个Key非常热点,在不停的扛着大并发,大并发集中对这一个点进行访问,当这个Key在失效的瞬间,持续的大并发就穿破缓存,直接请求数据库,就像在一个完好无损的桶上凿开了一个洞。
解决方案
1.设置热点数据永远不过期
2.互斥锁
可以在第一个查询数据的请求上使用一个互斥锁来锁住它。
其他的线程走到这一步拿不到锁就等着,第一个线程查询到了数据后放到缓存然后释放互斥锁,后面的线程获得锁之后,就可以从缓存中获取数据。
----缓存雪崩
缓存雪崩是指由于缓存层承载着大量请求,有效地保护了存储层,但是如果缓存层由于某些原因不能提供服务,于是所有的请求都会达到存储层,存储层的调用量会暴增,造成存储层也会级联宕机的情况。
解决方案
1. 保证Redis服务高可用
和飞机都有多个引擎一样,如果缓存层设计成高可用的,即使个别节点、 个别机器、 甚至是机房宕掉,依然可以提供服务。
Redis Sentinel和Redis Cluster都实现了高可用。2. 使用隔离组件为后端限流并降级
无论是缓存层还是存储层都会有出错的概率,可以将它们视同为资源。
作为并发量较大的系统,假如有一个资源不可用,可能会造成线程全部阻塞(hang) 在这个资源上,造成整个系统不可用。 降级机制在高并发系统中是非常普遍的: 比如推荐服务中,如果个性化推荐服务不可用,可以降级补充热点数据,不至于造成前端页面空白一片。
在实际项目中,我们需要对重要的资源(例如Redis、 MySQL、HBase、 外部接口) 都进行隔离,让每种资源都单独运行在自己的线程池中,即使个别资源出现了问题,对其他服务没有影响。 但是线程池如何管理,比如如何关闭资源池、 开启资源池、 资源池阀值管理,这些做起来还是相当复杂的。
这里推荐一个Java依赖隔离工具Hystrix(https://github.com/netflix/hystrix) ,如图2所示。 Hystrix是解决依赖隔离的利器,但是该内容已经超出本文的范围,同时只适用于Java应用,所以这里不会详细介绍。
3. 提前演练
在项目上线前,演练缓存层宕掉后,应用以及后端的负载情况以及可能出现的问题,在此基础上做一些预案设定。
----缓存穿透
缓存穿透是指查询一个根本不存在的数据,缓存层没有命中,然后去查数据库(持久层),数据库(持久层)也没有命中。通常如果从存储层查不到数据则不写入缓存层。
比如:用户不断发起请求,通过文章的id来获取文章,如果这个id没有对应的数据,则每次都会请求到数据库。如果这个用户是攻击者,在请求过多时会导致数据库压力过大,严重会击垮数据库。
解决方案
方案1:缓存空对象
如图所示,当第2步存储层不命中后,仍然将空对象保留到缓存层中,之后再访问这个数据将会从缓存中获取,这样就保护了后端数据源。
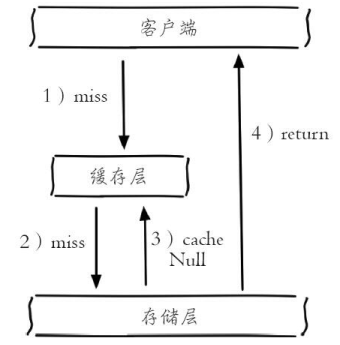
缓存空对象的两个问题
- 内存占用增加
- 说明:空值做了缓存,意味着缓存层中存了更多的键,需要更多的内存空间(如果是攻击,问题更严重) 。
- 解决方案:给这个缓存设置一个较短的过期时间(比如5分钟),让其自动删除。
- 缓存层和存储层的数据会有一段时间窗口的不一致,可能会对业务有一定影响。
- 说明:假设过期时间设置为5分钟,如果此时存储层添加了这个数据,那此段时间就会出现缓存层和存储层数据的不一致
- 解决方案:将数据插入到存储层时,清除掉缓存层中的空对象。
代码实现(Jedis)
String get(String key) { // 从缓存中获取数据 String cacheValue = cache.get(key); // 缓存为空 if (StringUtils.isBlank(cacheValue)) { // 从存储中获取 String storageValue = storage.get(key); cache.set(key, storageValue); // 如果存储数据为空, 需要设置一个过期时间(300秒) if (storageValue == null) { cache.expire(key, 60 * 5); } return storageValue; } else { // 缓存非空 return cacheValue; } }
方案2:布隆过滤器
如图所示,在访问缓存层和存储层之前,将存在的key用布隆过滤器提前保存起来,做第一层拦截。
查询的流程:
- 如果key在布隆过滤器中,去查询缓存
- 如果查询到,则返回缓存中的数据
- 如果没查询到,则穿透到db查询。
- 如果不在布隆器中
- 直接返回。
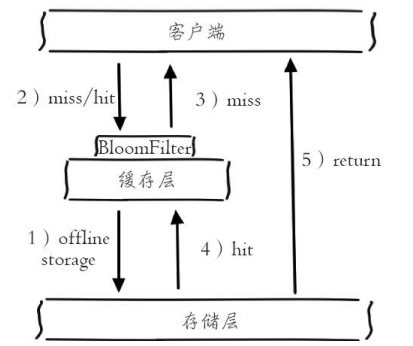
示例
比如:对于博客系统,一般是通过博客的id去访问。可以先将数据库中存在的博客的id放到布隆过滤器中,请求进来之后,如果id在布隆过滤器中,则允许通过id查到博客详情,否则直接返回空白的博客。在一定程度保护了存储层。
有关布隆过滤器的相关知识,可以参考: https://en.wikipedia.org/wiki/Bloom_filter。可以利用Redis的Bitmaps实现布隆过滤器,GitHub上已经开源了类似的方案,读者可以进行参考: https://github.com/erikdubbelboer/redis-lua-scaling-bloom-filter。
这种方法适用于数据命中不高、 数据相对固定、 实时性低(通常是数据集较大) 的应用场景,代码维护较为复杂,但是缓存空间占用少。
方案对比

----无底洞
通常来说添加节点使得Memcache集群性能应该更强了,但事实并非如此。键值数据库由于通常采用哈希函数将key映射到各个节点上,造成key的分布与业务无关,但是由于数据量和访问量的持续增长,造成需要添加大量节点做水平扩容,导致键值分布到更多的节点上,所以无论是Memcache还是Redis的分布式,批量操作通常需要从不同节点上获取,相比于单机批量操作只涉及一次网络操作,分布式批量操作会涉及多次网络时间。
用一句通俗的话总结就是,更多的节点不代表更高的性能,所谓“无底洞”就是说投入越多不一定产出越多。但是分布式又是不可以避免的,因为访问量和数据量越来越大,一个节点根本抗不住,所以如何高效地在分布式缓存中批量操作是一个难点。
解决方案:https://learn.skyofit.com/archives/734
5、内存回收机制是怎样的?(或者说:淘汰策略)?
6、Redis与数据库如何同步?各个方式的缺点是什么?
7、秒杀的时候怎么使用Redis?
九、微服务相关
分布式事务:https://blog.csdn.net/u011397981/article/details/129829072
1、springcloud常见的组件有哪些?
2、注册中心eureka和nacos区别?
eureka只能当注册中心,nacos既能当注册中心也能当配置中心。
3、ribbon负载均衡?
十、消息中间件MQ、Kafka
1、
其它
1、JDK和JRE和JVM的区别?
---- JDK ( Java SE Development Kit ), Java 标准的开发包,提供了编译、运行 Java 程序所需要的各种工具和资源 ,包括了 Java 编译器、 Java 运行时环境、以及常用的 Java 类库等。
---- JRE ( Java Runtime Environment ) , Java 运行时环境,用于解释执行 Java 的字节码文件 。普通用户只需要安装 JRE 来运行 Java 程序即可,而作为一名程序员必须安装 JDK ,来编译、调试程序。
---- JVM ( Java Virtual Mechinal ), Java 虚拟机,是 JRE 的一部分。 它是整个 Java 实现跨平台的核心 ,负责解释执行字节码文件,是可运行 Java 字节码文件的虚拟计算机。所有平台上的 JVM 向编译器提供相同的
接口,而编译器只需要面向虚拟机,生成虚拟机能识别的代码,然后由虚拟机来解释执行。当使用 Java 编译器编译 Java 程序时,生成的是与平台无关的字节码,这些字节码只面向 JVM 。也就是说JVM 是运行 Java 字节码的虚拟机。
不同平台的 JVM 是不同的,但是他们都提供了相同的接口。 JVM 是 Java 程序跨平台的关键部分,只要为不同平台实现了相同的虚拟机,编译后的 Java 字节码就可以在该平台上运行。
2、什么是HashMap?
HashMap是一种比较好用和常用的集合,是一种键值对KV形式的,它不是线程安全的,实现了Map接口。最多允许一条记录的值为null。无序,无索引。不能存储重复元素。
2、集合、锁、多线程相关问题?
4、SQL怎么优化?
5、Redis相关问题(例如:持久化、缓存雪崩、穿透、击穿、双写一致性、数据过期、数据淘汰策略、主从、哨兵、分片集群)
6、微服务相关问题(例如:什么是分布式事务?使用场景?)
7、Docker容器操作相关命令?
8、ES相关问题
9、MQ相关问题、Kafka的使用?
10、口述一下你做过的项目以及用到的知识点
11、自学的两个项目相关知识点的复习尤其是SpringCloud项目
12、其它
JDK ( Java SE Development Kit ), Java 标准的开发包,提供了编译、运行 Java 程序所需要的各种工具
和资源 ,包括了 Java 编译器、 Java 运行时环境、以及常用的 Java 类库等。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号