SpringCloud(九.1)ES 进阶 -- 自动补全
- 拼音分词器
- 自定义分词器
- 自动实例查询
- 实现酒店搜索框自动补全
一、拼音分词器
拼音分词器官方下载地址:https://github.com/medcl/elasticsearch-analysis-pinyin
elasticsearch-analysis-pinyin-7.12.1 百度网盘下载地址:链接:https://pan.baidu.com/s/1LBBfYNLZBUcG-y-WFRUp-g 提取码:4hwd
安装方式与IK分词器一样,分三步:
1、解压
2、上传到虚拟机中,elasticsearch的plugin目录 /var/lib/docker/volumes/es-plugins/_data

3、重启elasticsearch
docker restart es
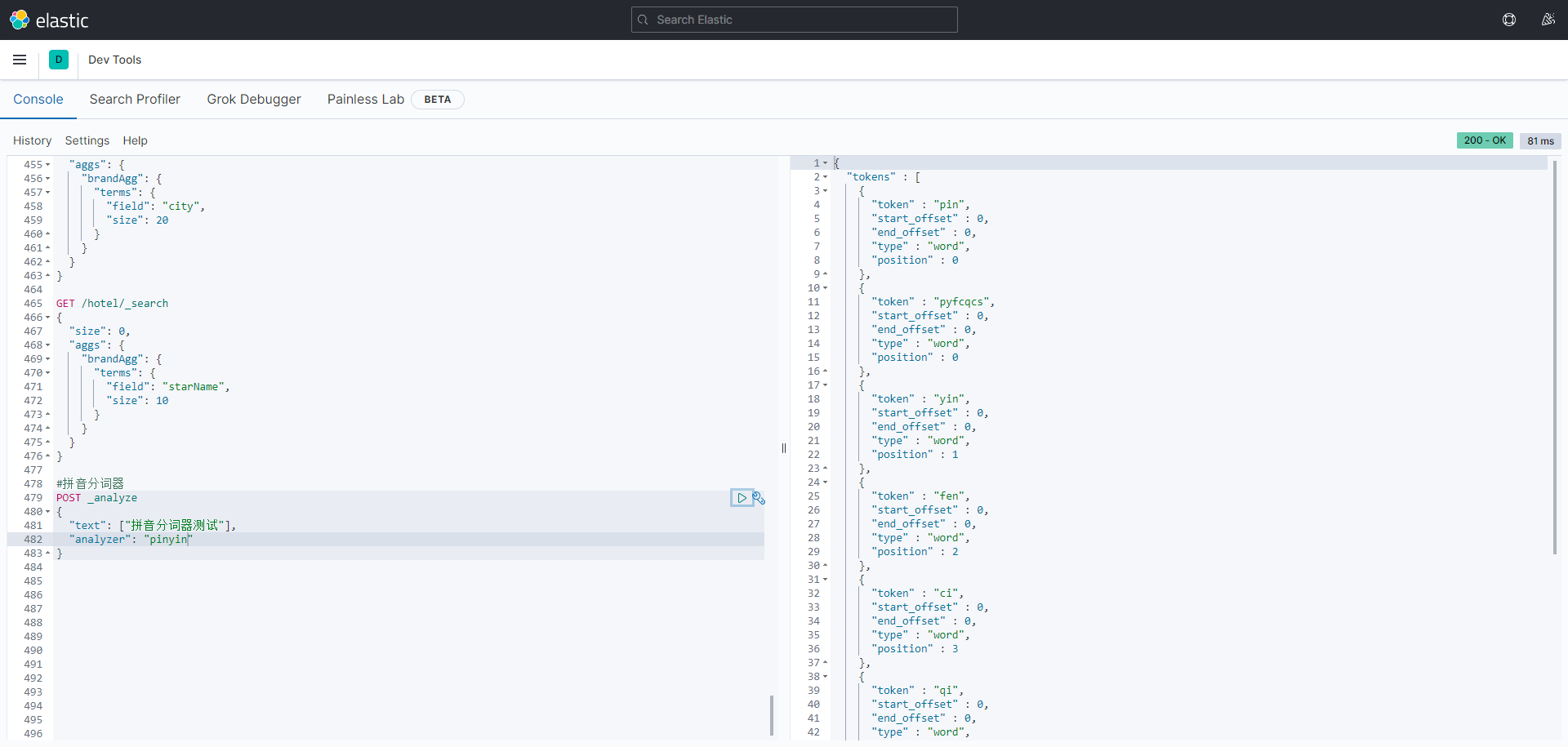
测试是否生效: 在kibana中用DSL语句测试
#拼音分词器 POST _analyze { "text": ["拼音分词器测试"], "analyzer": "pinyin" }
二、自定义分词器
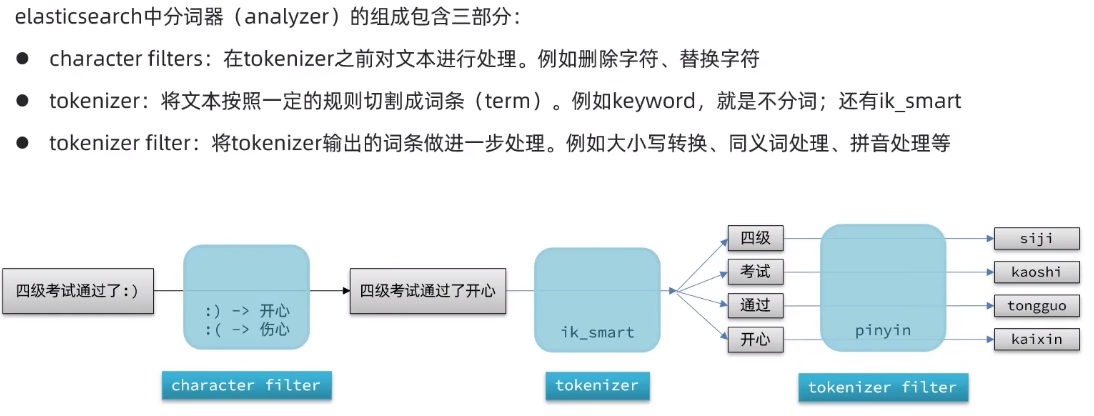
拼音分词器模板
// 自定义拼音分词器 PUT /test //索引库名称 { "settings": { "analysis": { "analyzer": { //自定义分词器 "my_analyzer": { //分词器名称 "tokenizer": "ik_max_word", "filter": "py" } }, "filter": { //自定义tokenizer filter "py": { //过滤器名称 "type": "pinyin", //过滤器类型,这里是pinyin "keep_full_pinyin": false, //把所有字都拆成一个一个的拼音关闭 "keep_joined_full_pinyin": true, //把字符串转换为拼音 "keep_original": true, // 要不要保留中文 "limit_first_letter_length": 16, "remove_duplicated_term": true, "none_chinese_pinyin_tokenize": false } } } } }
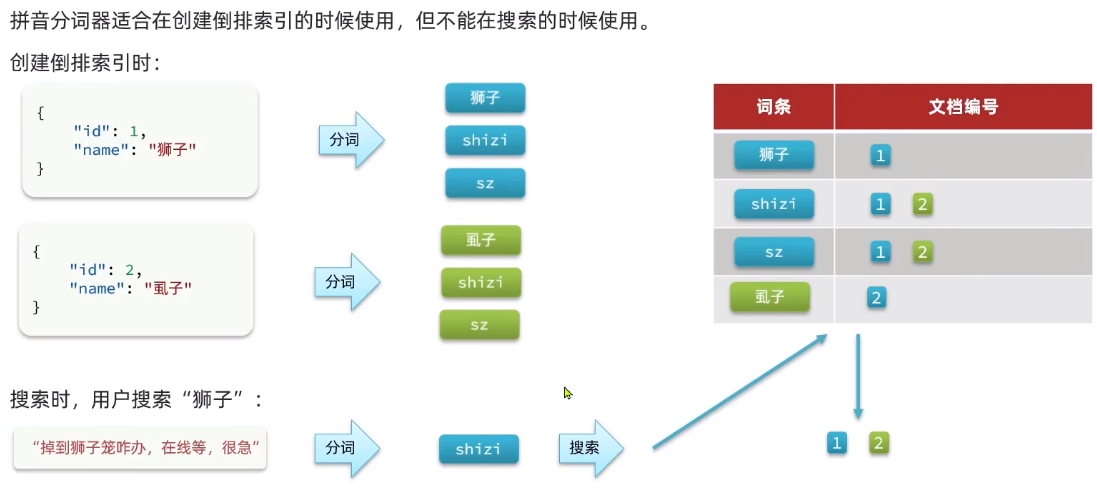
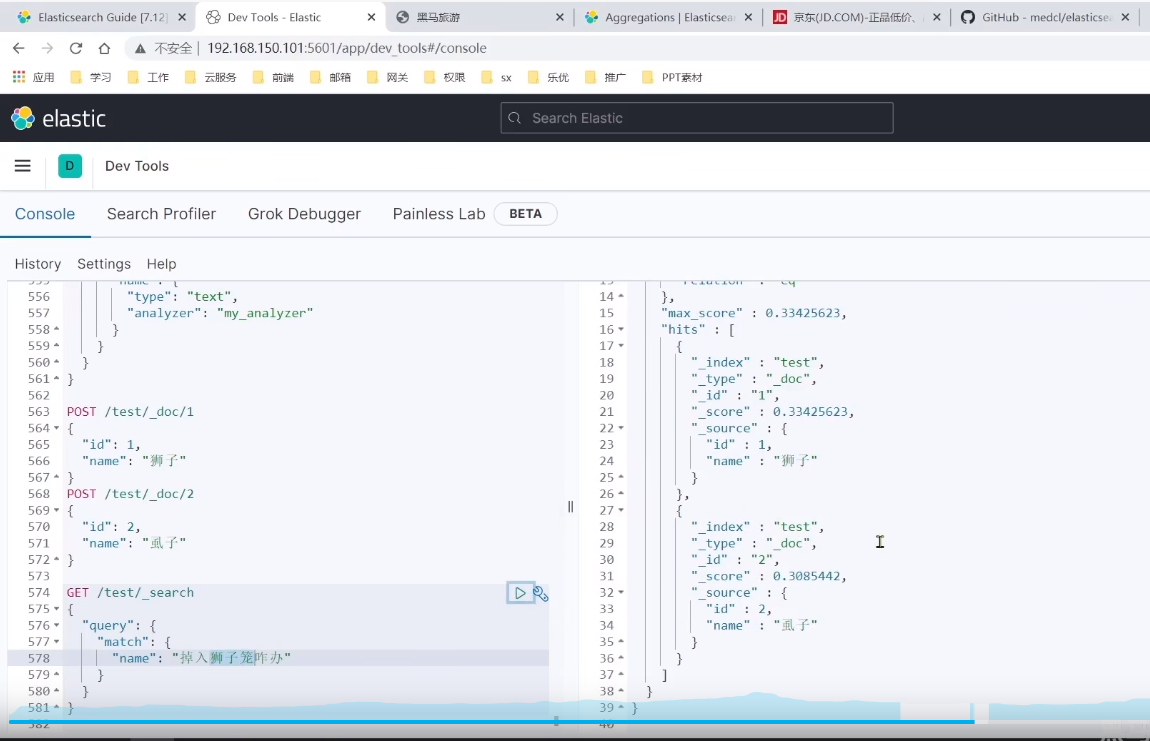
所以要做出区分,创建倒排索引时使用拼音分词器,搜索时使用ik_smart。
使用案例
#酒店索引创建 + 自定义拼音分词器 PUT /hotel2 { "mappings": { "properties": { "id":{ "type":"keyword" }, "name":{ "type":"text", "analyzer": "my_analyzer", "search_analyzer": "ik_smart", "copy_to": "all" }, "address":{ "type":"keyword", "index": false }, "price":{ "type":"integer" }, "score":{ "type":"integer" }, "brand":{ "type": "keyword", "copy_to": "all" }, "city":{ "type": "keyword", "copy_to": "all" }, "starName":{ "type": "keyword" }, "business":{ "type": "keyword", "copy_to": "all" }, "location":{ "type":"geo_point" }, "pic":{ "type":"keyword", "index": false }, "all":{ "type":"text", "analyzer": "my_analyzer" } } }, "settings": { "analysis": { "analyzer": { "my_analyzer": { "tokenizer": "ik_max_word", "filter": "py" } }, "filter": { "py": { "type": "pinyin", "keep_full_pinyin": false, "keep_joined_full_pinyin": true, "keep_original": true, "limit_first_letter_length": 16, "remove_duplicated_term": true, "none_chinese_pinyin_tokenize": false } } } } }
拼音分词器效果测试:
#自定义拼音分词器测试 POST /hotel2/_analyze { "text": ["拼音分词器测试"], "analyzer": "my_analyzer" }
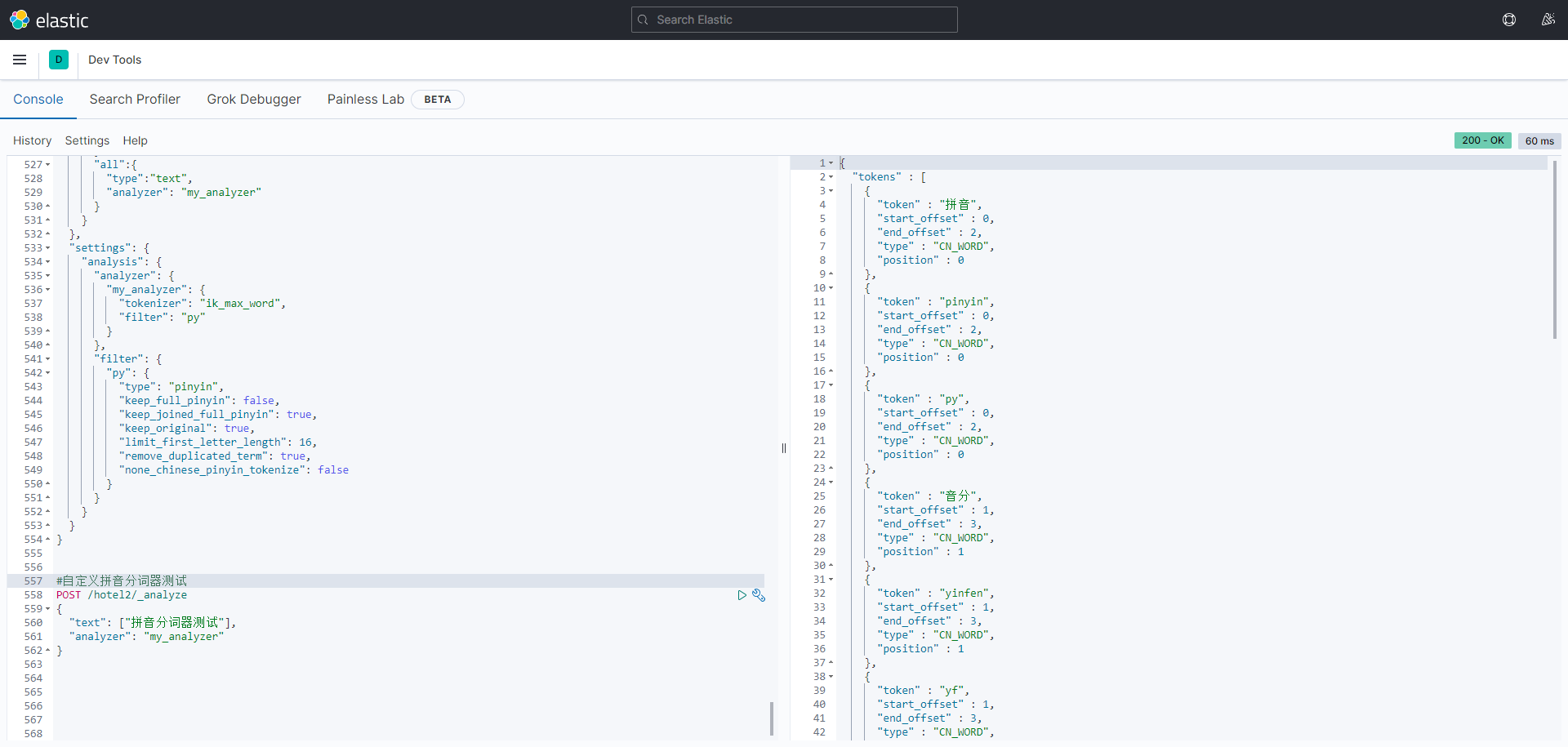
测试搜索:(因为与视频教程创建的索引库不同,这里给出个案例知道 区分创建倒排索引时使用拼音分词器,搜索时使用ik_smart。的作用和意义在哪就行。)

三、自动补全 - completion suggester 查询
elasticsearch提供了Completion Suggester查询来实现自动补全功能。这个查询会匹配以用户输入内容开头的词条并返回。为了提高实例查询的效率,对于文档中字段的类型有一些约束:
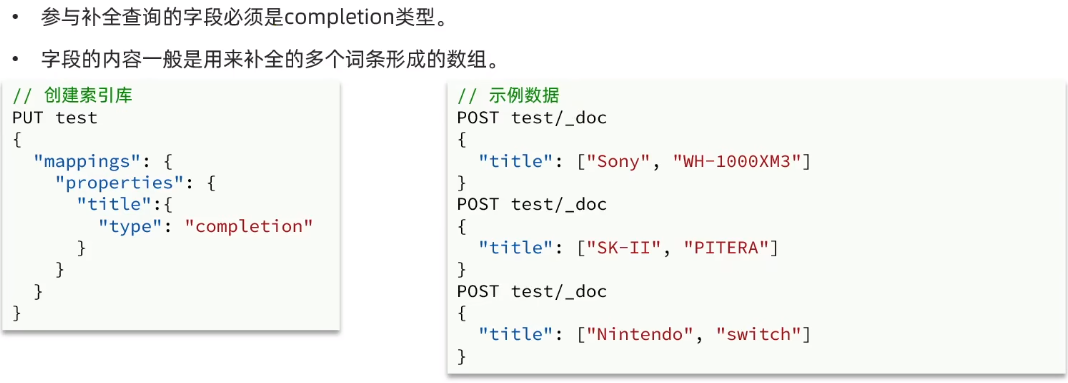

案例:
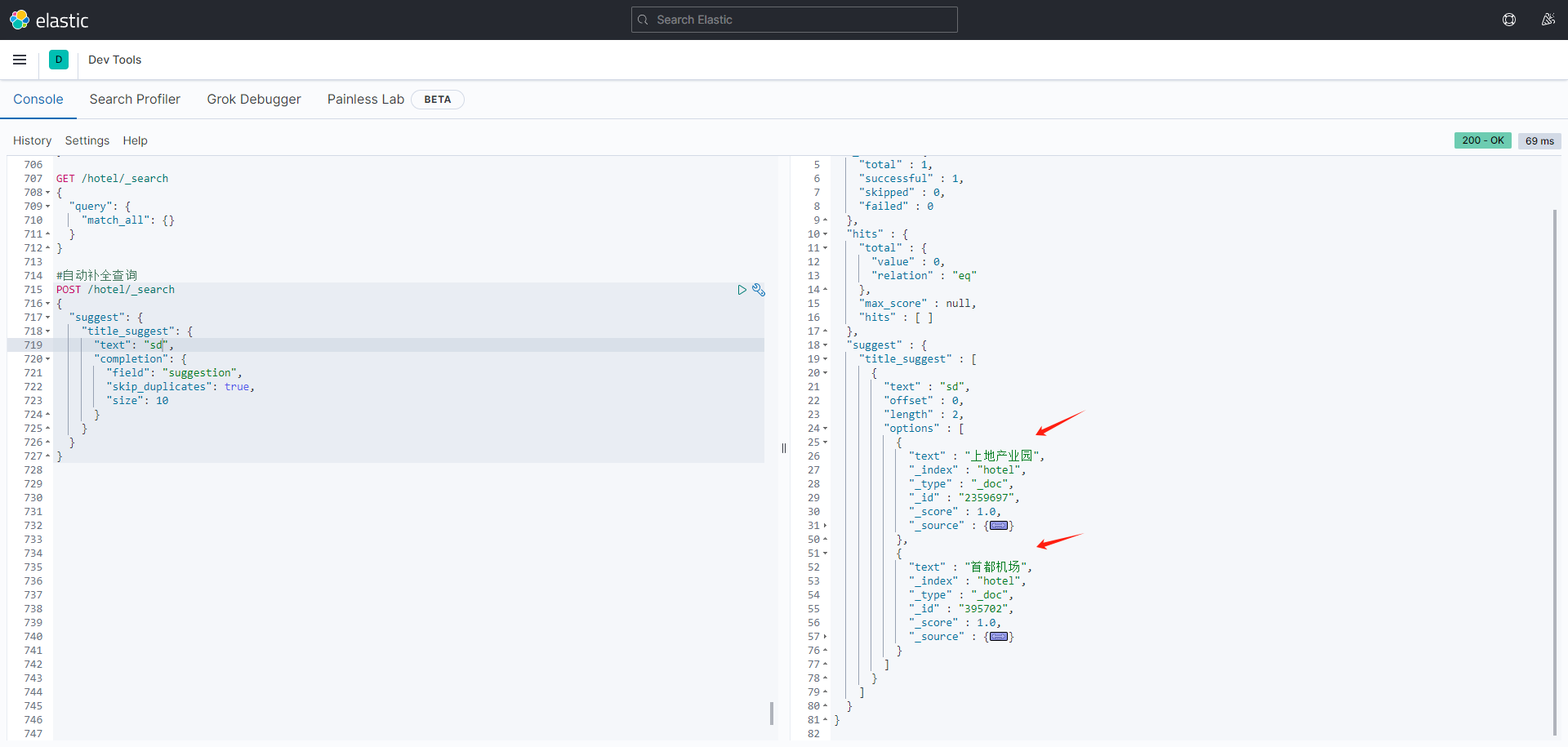
// 自动补全的索引库 PUT test { "mappings": { "properties": { "title":{ "type": "completion" } } } } // 示例数据 POST test/_doc { "title": ["Sony", "WH-1000XM3"] } POST test/_doc { "title": ["SK-II", "PITERA"] } POST test/_doc { "title": ["Nintendo", "switch"] } // 自动补全查询 POST /test/_search { "suggest": { "title_suggest": { "text": "s", // 关键字 "completion": { "field": "title", // 补全字段 "skip_duplicates": true, // 跳过重复的 "size": 10 // 获取前10条结果 } } } }
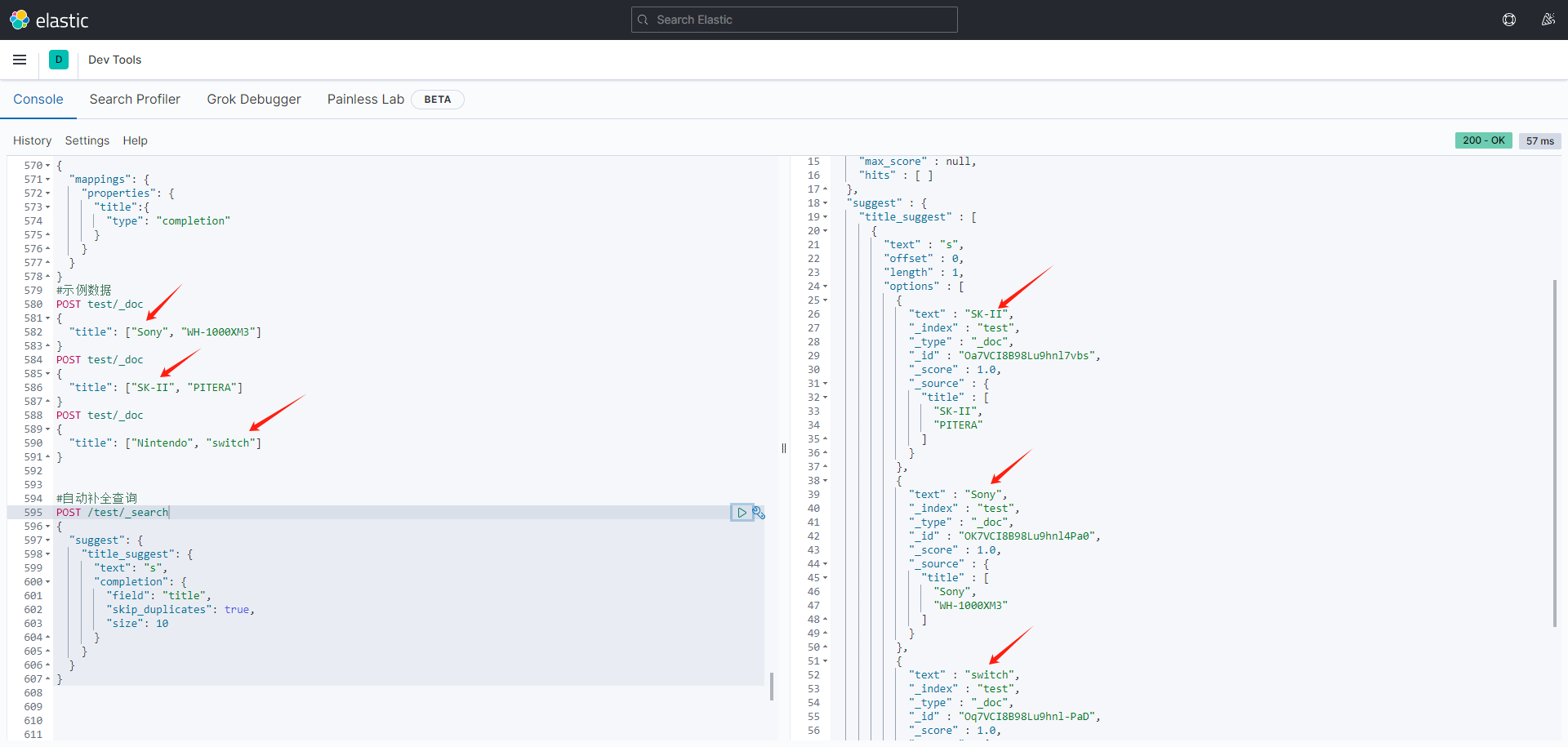
使用注意事项:
类型必须是completion类型
字段值是多词条的数组(以后可以把想要自动补全的字段放到数组中,如:名称、品牌、类型等等)。
四、实现酒店搜索框自动补全(优化)
因为前面创建了酒店的索引库,所以先删除,再优化。
// 删除酒店索引库 DELETE /hotel // 酒店数据索引库 PUT /hotel { "settings": { "analysis": { "analyzer": { "text_anlyzer": { "tokenizer": "ik_max_word", "filter": "py" }, "completion_analyzer": { //不分词拼音分词器 "tokenizer": "keyword", "filter": "py" } }, "filter": { "py": { //自定义拼音分词器 "type": "pinyin", "keep_full_pinyin": false, "keep_joined_full_pinyin": true, "keep_original": true, "limit_first_letter_length": 16, "remove_duplicated_term": true, "none_chinese_pinyin_tokenize": false } } } }, "mappings": { "properties": { "id":{ "type": "keyword" }, "name":{ "type": "text", "analyzer": "text_anlyzer", "search_analyzer": "ik_smart", "copy_to": "all" }, "address":{ "type": "keyword", "index": false }, "price":{ "type": "integer" }, "score":{ "type": "integer" }, "brand":{ "type": "keyword", "copy_to": "all" }, "city":{ "type": "keyword" }, "starName":{ "type": "keyword" }, "business":{ "type": "keyword", "copy_to": "all" }, "location":{ "type": "geo_point" }, "pic":{ "type": "keyword", "index": false }, "all":{ "type": "text", "analyzer": "text_anlyzer", "search_analyzer": "ik_smart" }, "suggestion":{ //自动补全 "type": "completion", "analyzer": "completion_analyzer" } } } }
因为索引库字段映射mapping这里新增了自动补全字段 suggestion ,所以需要在实体中新增此字段并在构造中赋值。
@Data @NoArgsConstructor public class HotelDoc { private Long id; private String name; private String address; private Integer price; private Integer score; private String brand; private String city; private String starName; private String business; private String location; private String pic; private Object distance; private Boolean isAD; private List<String> suggestion; public HotelDoc(Hotel hotel) { this.id = hotel.getId(); this.name = hotel.getName(); this.address = hotel.getAddress(); this.price = hotel.getPrice(); this.score = hotel.getScore(); this.brand = hotel.getBrand(); this.city = hotel.getCity(); this.starName = hotel.getStarName(); this.business = hotel.getBusiness(); this.location = hotel.getLatitude() + ", " + hotel.getLongitude(); this.pic = hotel.getPic(); // 自动补全字段的处理 this.suggestion = new ArrayList<>(); // 添加品牌、城市 this.suggestion.add(this.brand); this.suggestion.add(this.city); // 分割案例 , business有多个值,需要切割 // 判断商圈是否包含 / if (this.business.contains("/")) { // 需要切割 String[] arr = this.business.split("/"); // Collections 工具可批量添加 Collections.addAll(this.suggestion, arr); }else{ this.suggestion.add(this.business); } } }
重新批量导入文档
查看效果:

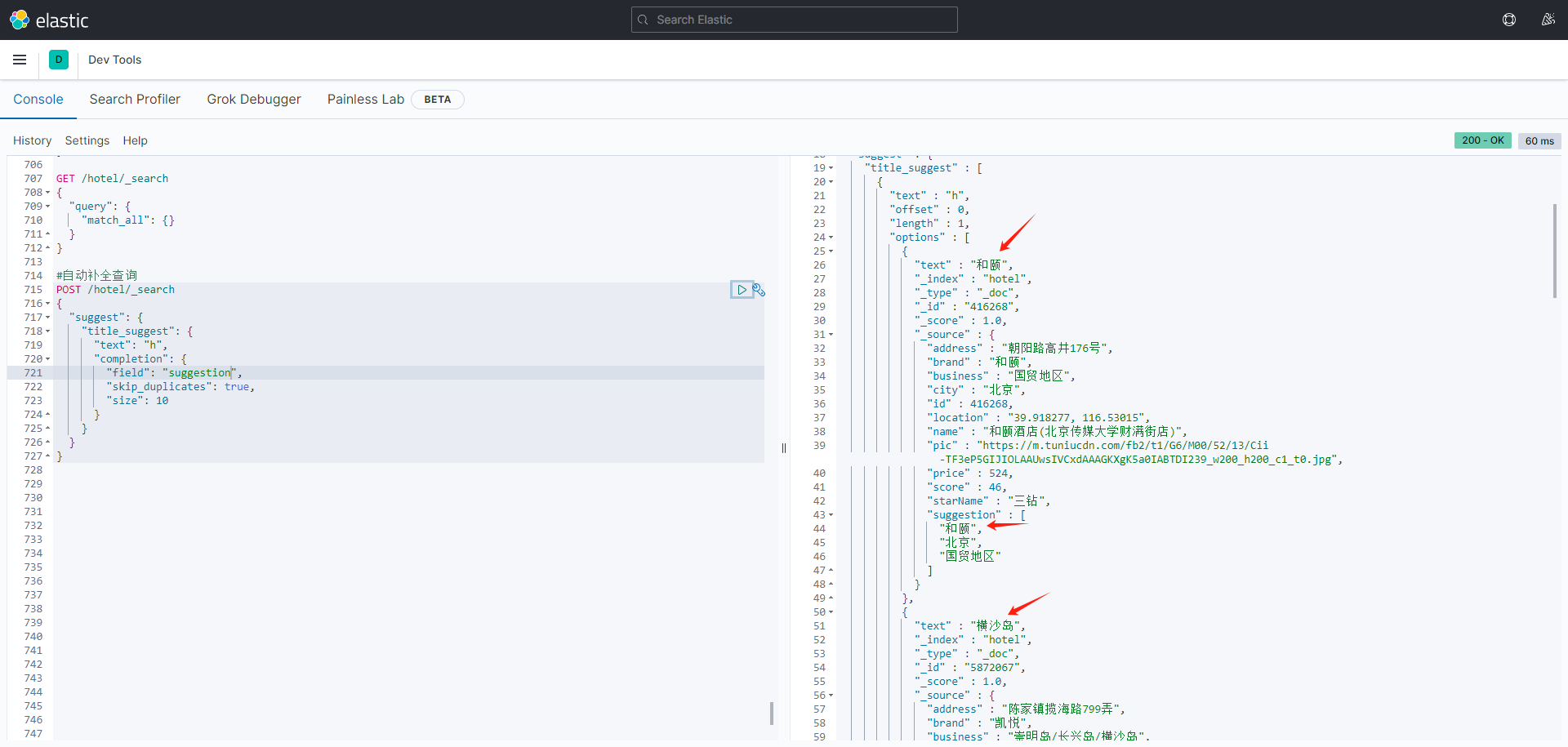
测试自动补全功能:
#自动补全查询 POST /hotel/_search { "suggest": { "title_suggest": { "text": "h", "completion": { "field": "suggestion", "skip_duplicates": true, "size": 10 } } } }

 浙公网安备 33010602011771号
浙公网安备 33010602011771号