SpringCloud(七.1)ES(elasticsearch)+kibana+IK分词器的安装和使用
随着业务的发展,数据量越来越庞大,传统的mysql数据库就难以满足业务需求,所以在微服务架构下都会用到分布式搜索技术。
官网地址:https://www.elastic.co/cn/
什么是elasticsearch?
elasticsearch是一款非常强大的开源搜索引擎,可以帮助我们从海量数据中快速找到需要的内容。并高亮显示。
elasticsearch是ELK技术栈的核心,底层是Lucene技术(Lucene是Apache的开源搜索引擎类库,提供了搜索引擎的核心API)。
插眼:在CSDN看到一篇ES相关不错的文章插眼记录 https://blog.csdn.net/weixin_44062380/article/details/121596538
1、文档
ES是面向文档存储,文档可以是一条商品数据,可以是一条订单信息。如图:

文档信息会被序列化为json格式后存储至elasticsearch。
2、索引
相同类型的文档集合称之为索引。如图:

elasticsearch优势?
- 支持分布式,可水平扩展形成集群。
- 提供Restful接口,可被任何语言调用。
elasticsearch和mysql区别?
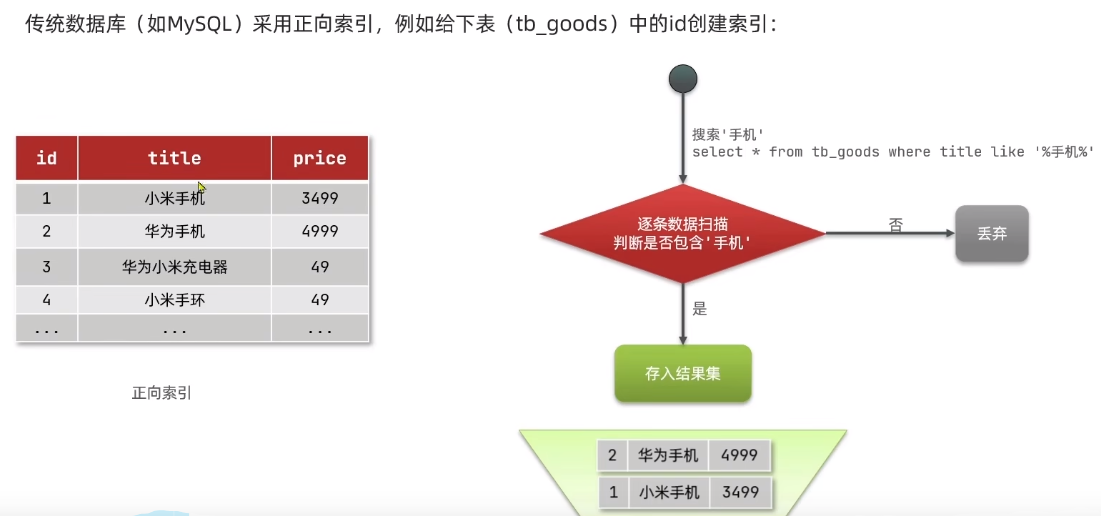
正向索引缺点:如上图,如果查询非索引字段会逐行进行判断。效率会非常低。
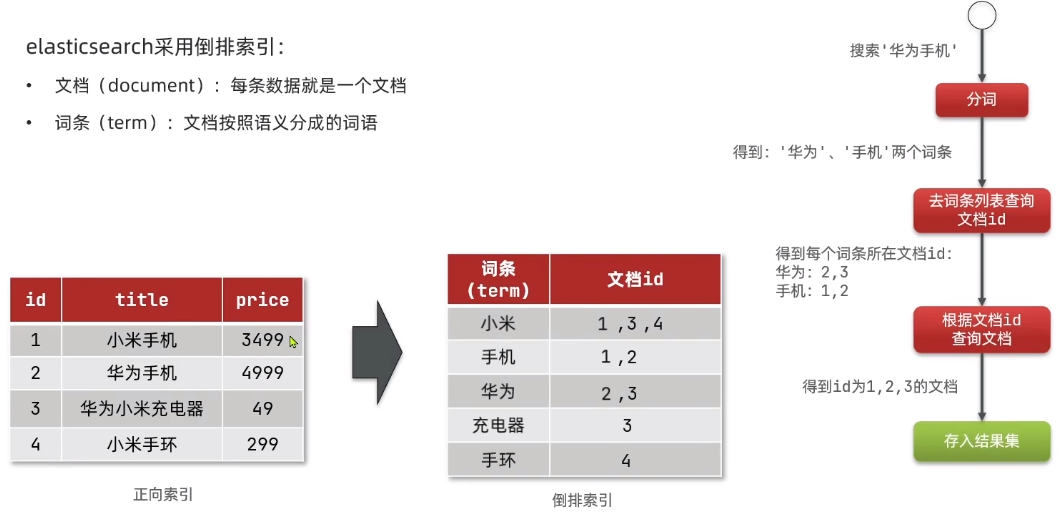
倒排索引:先根据词条查到文档id(主键)再根据id查到相应的文档。
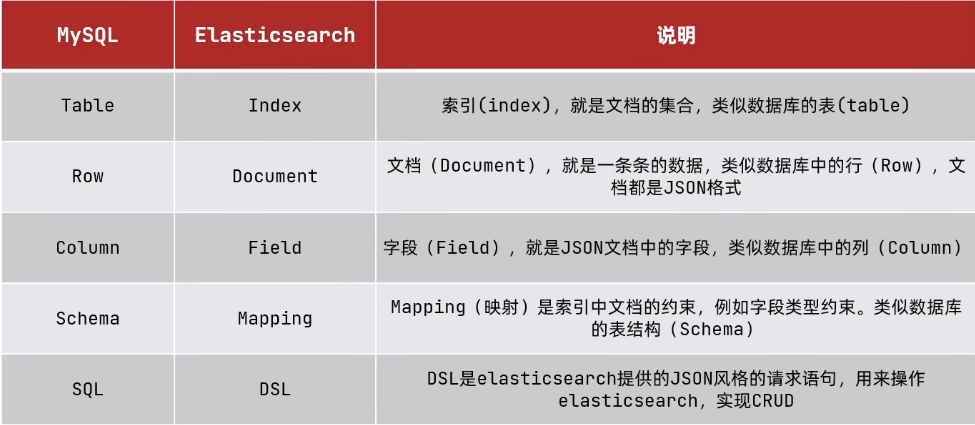
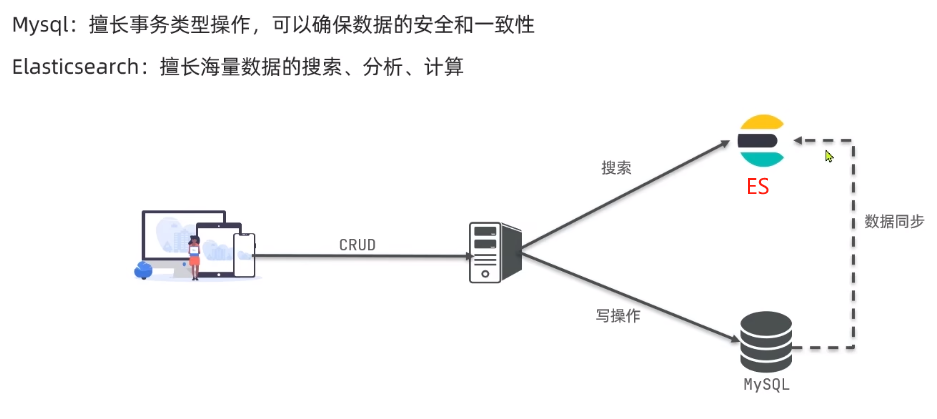
安装elasticsearch和kibana
为什么也要安装kibana?
kibana可以给我们提供一个elasticsearch的可视化界面,便于我们学习。可以非常方便的编写ES中的dsl语句,从而去操作ES。
安装资料
安装教程 --- 链接:https://pan.baidu.com/s/1qdOEQR9EjFJaySRIpM9K2Q 提取码:e6ch
ES tar包 --- 链接:https://pan.baidu.com/s/1z6E1neCyyY8BYuMh-R4s3A 提取码:h87v
Kibana tar包 --- 链接:https://pan.baidu.com/s/1FrDR3Bazv9DVOoLRehLAEA 提取码:zqud
IK分词器 tar包 --- 链接:https://pan.baidu.com/s/12C6aEGBxtTsOLPFojKhuOw 提取码:8vyc
注意事项:安装Kibana 版本一定要和ES保持一致!
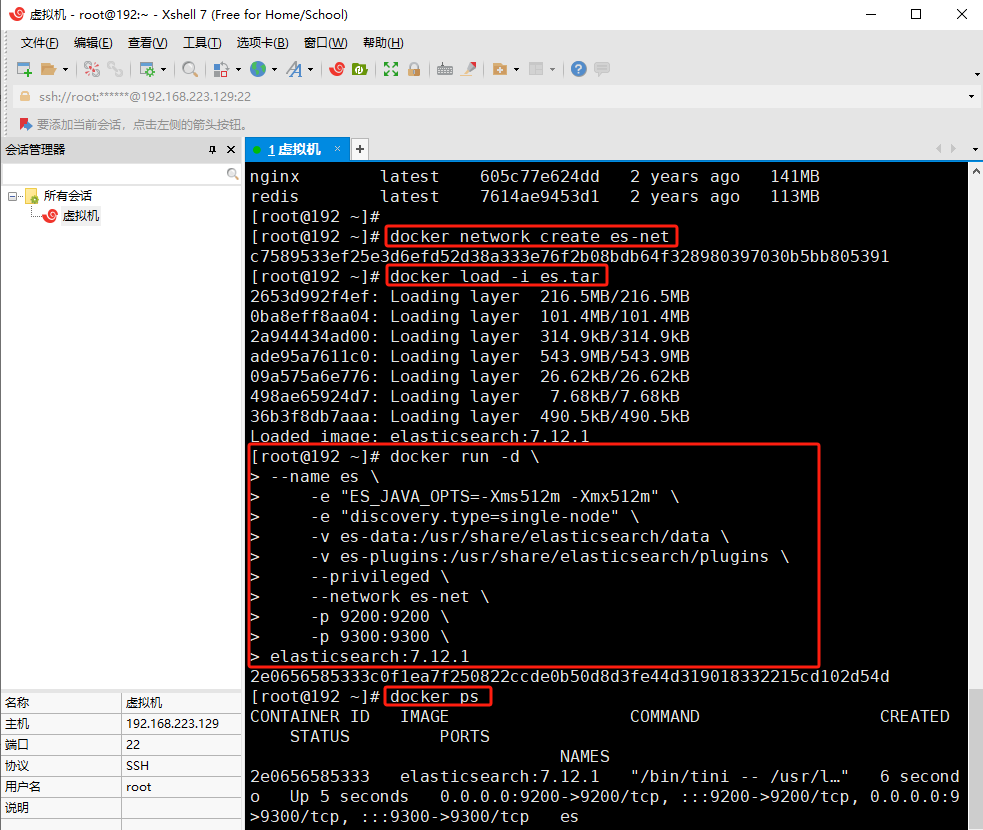
docker run -d \ --name es \ -e "ES_JAVA_OPTS=-Xms512m -Xmx512m" \ -e "discovery.type=single-node" \ -v es-data:/usr/share/elasticsearch/data \ -v es-plugins:/usr/share/elasticsearch/plugins \ --privileged \ --network es-net \ -p 9200:9200 \ -p 9300:9300 \ elasticsearch:7.12.1
安装好es之后我们在浏览器中访问一下,端口配置的是9200,直接访问 服务器/虚拟机:9200,可以看到以下界面:
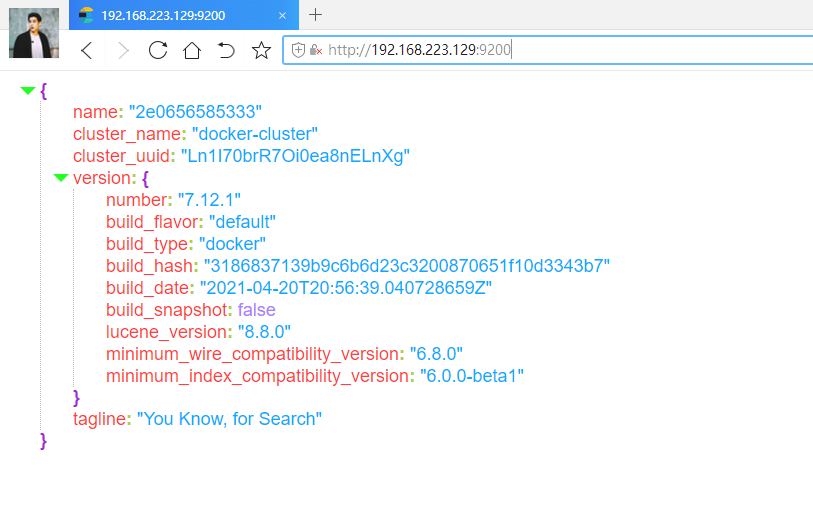
出现此界面就代表es安装启动成功了!
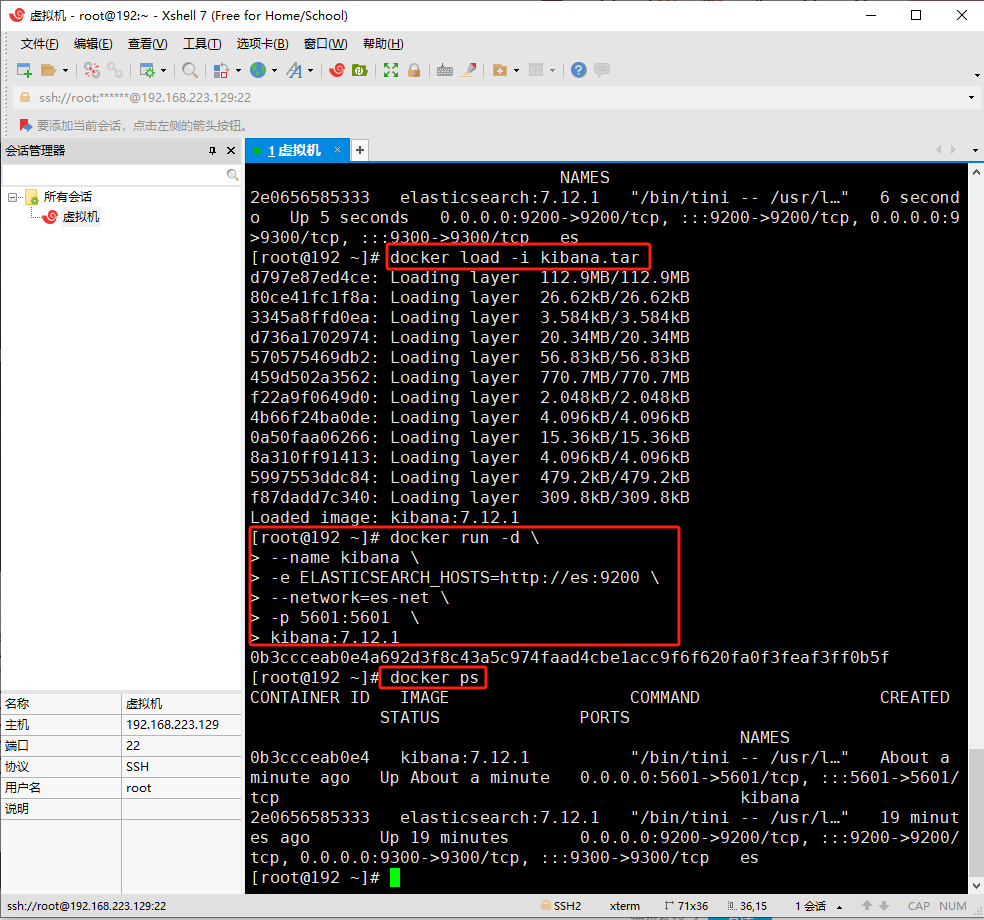
docker run -d \ --name kibana \ -e ELASTICSEARCH_HOSTS=http://es:9200 \ --network=es-net \ -p 5601:5601 \ kibana:7.12.1
安装完成后,我们在浏览器中访问kibana的地址,我们这里的端口配置的是5601,直接访问 服务器/虚拟机:5601,可以看到以下界面:
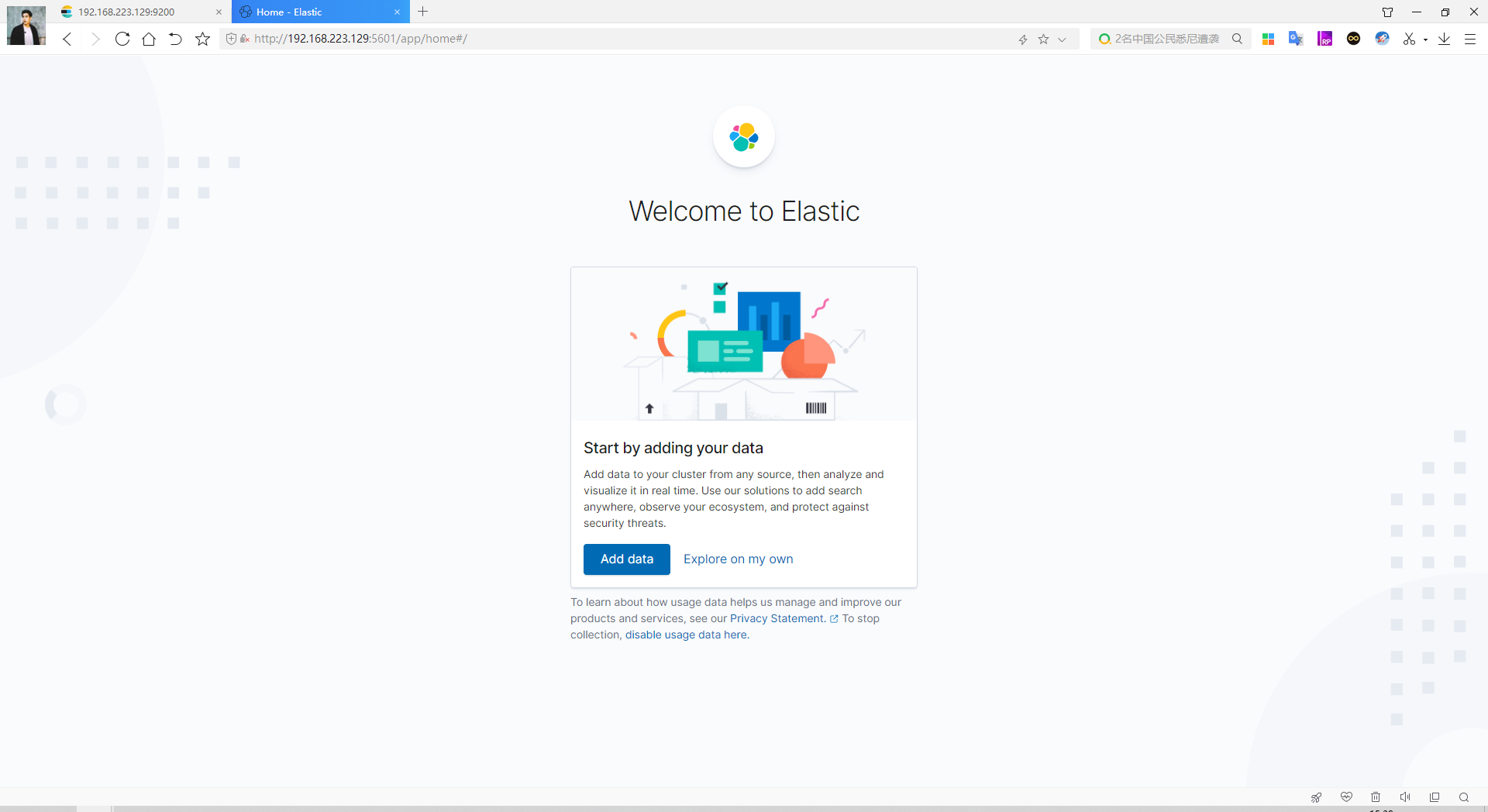
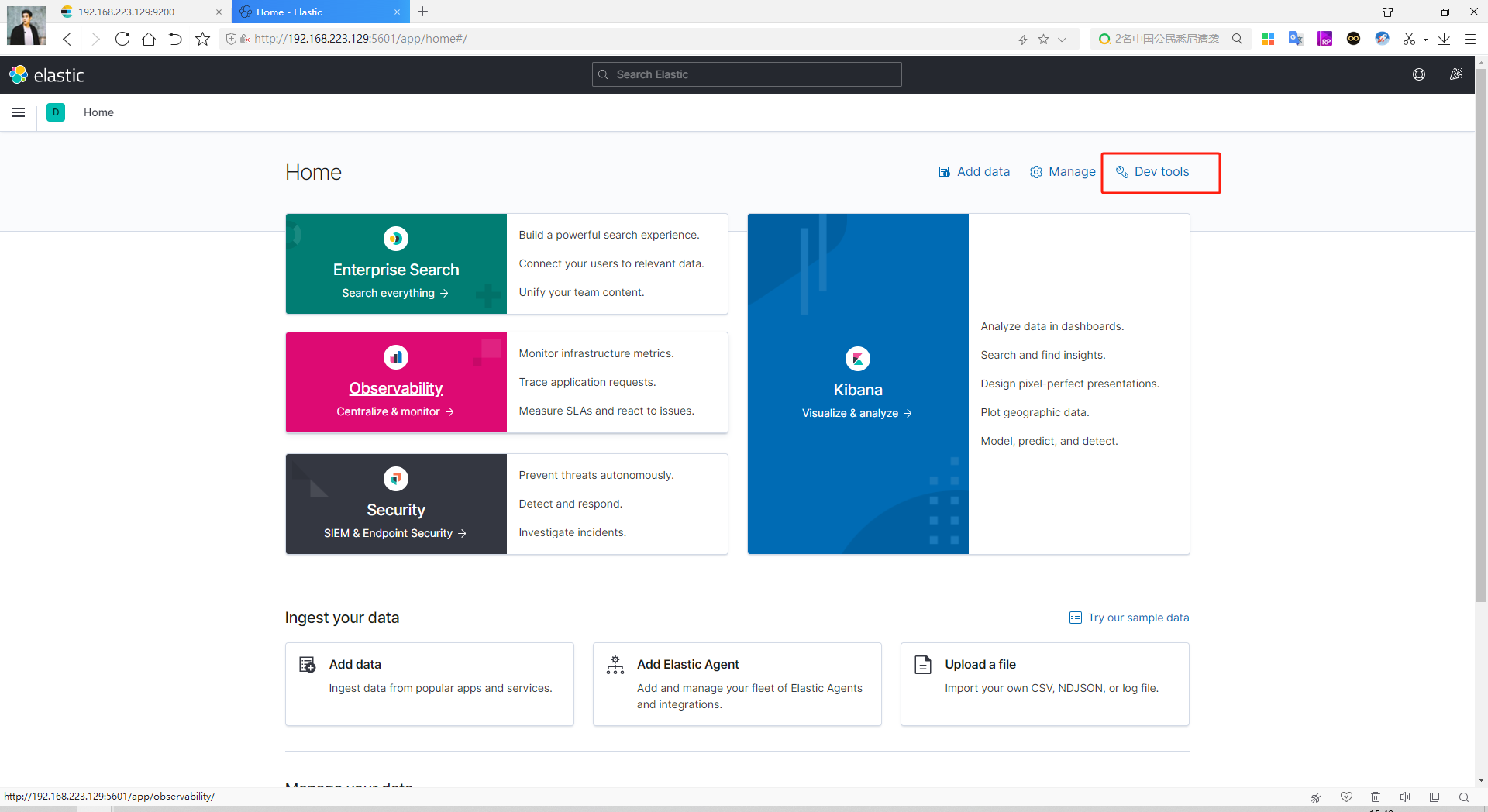
进入后我们点击 dev tools (DSL控制台,可以非常方便的发送DSL请求。)
下面含义是 查询所有数据,点击查询后就会把请求发送给ES。
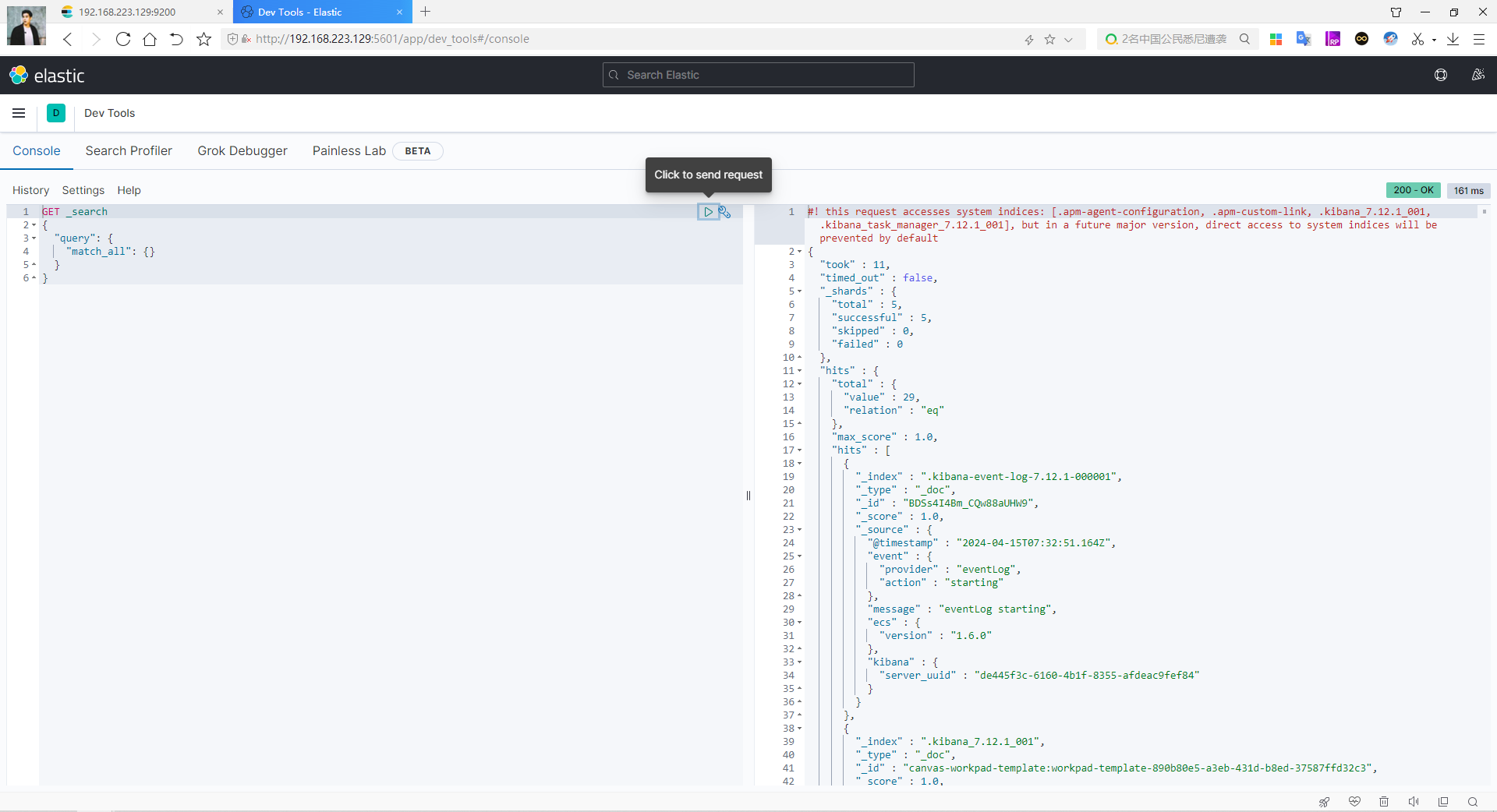
它的本质就是发送一个 restful 到ES中(调用ES提供的 restful api)如图:
分词器

POST /_analyze { "analyzer": "standard", //分组类型 "text": "黑马程序员学习java太棒了!" }
当analyzer为 english 或 standard 的时候,会发现他是按照一个字符一个字符来分,英文分的特别好,但对中文很不友好,如图:

如果想分词中文,使用专门的中文分词器 - IK 。安装方法详见上面安装资料中的安装教程。
IK分词器官网地址:https://github.com/infinilabs/analysis-ik
安装完成后重启ES,重新在kibana中运行。
-
ik_smart:最少切分 (内存占用小,可以缓存更多的数据,效率高。) -
ik_max_word:最细切分 (内存占用大,更精确)
GET /_analyze
{
"analyzer": "ik_smart",
"text": "黑马程序员学习java太棒了"
}
效果:

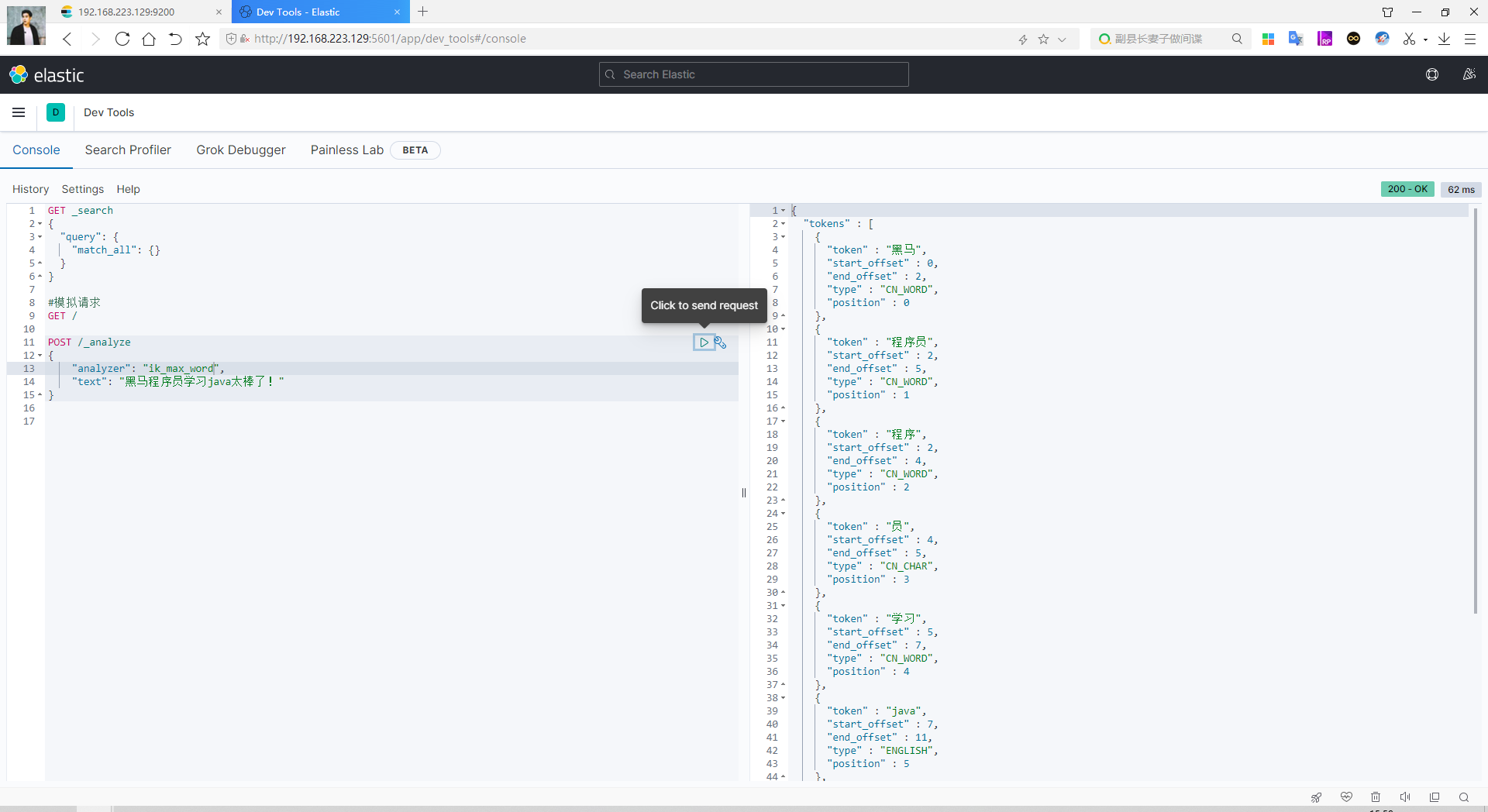
GET /_analyze { "analyzer": "ik_max_word", "text": "黑马程序员学习java太棒了" }
效果: 拆分的特别细
IK分词器的拓展和停用词典
IK分词器可能也不会分词很理想,如一些流行用语,如:白嫖、奥利给等等。
还有一些无用的分词想禁掉,如:的、了、哦、嗯、啊 或者一些禁词等等。
1、打开IK分词器config目录
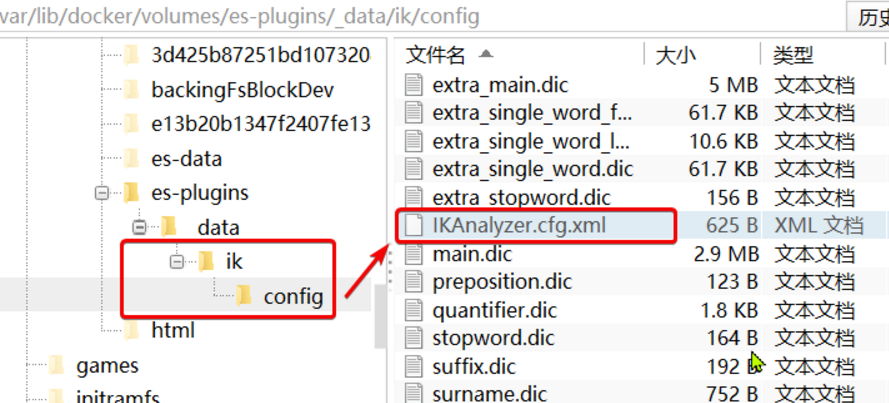
2、在IKAnalyzer.cfg.xml配置文件内容添加:
<?xml version="1.0" encoding="UTF-8"?> <!DOCTYPE properties SYSTEM "http://java.sun.com/dtd/properties.dtd"> <properties> <comment>IK Analyzer 扩展配置</comment> <!--用户可以在这里配置自己的扩展字典 ext.dic 添加扩展词典--> <entry key="ext_dict">ext.dic</entry> <!--用户可以在这里配置自己的扩展停止词字典 stopword.dic 添加停用词词典--> <entry key="ext_stopwords">stopword.dic</entry> </properties>
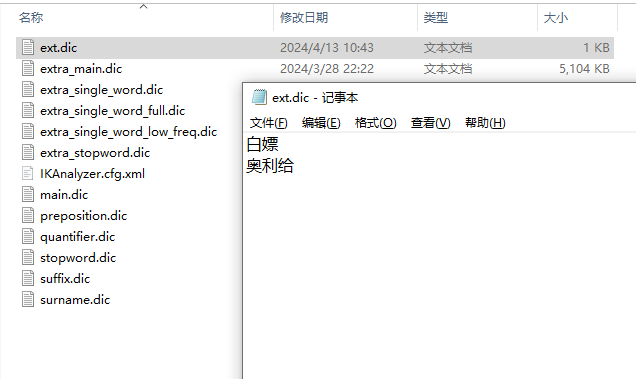
3、在当前配置文件目录下(config文件夹下)新建 扩展词典ext.dic
打开 扩展词典ext.dic 添加我们想要分词的词语
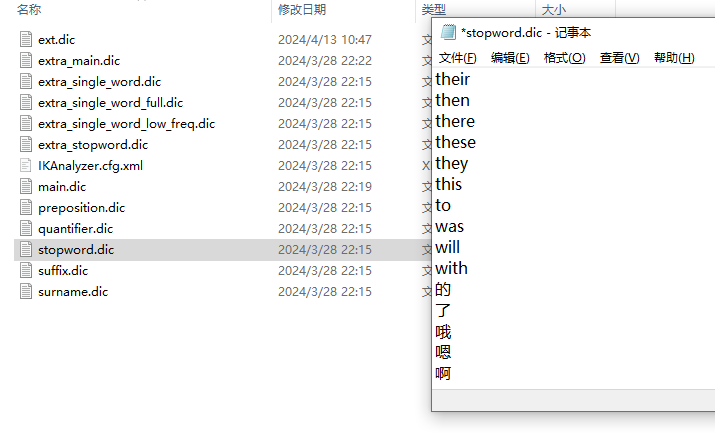
打开 停用词词典 stopword.dic 停掉我们想停用的词语(默认会有一些英文)
4、重启es --- docker restart es
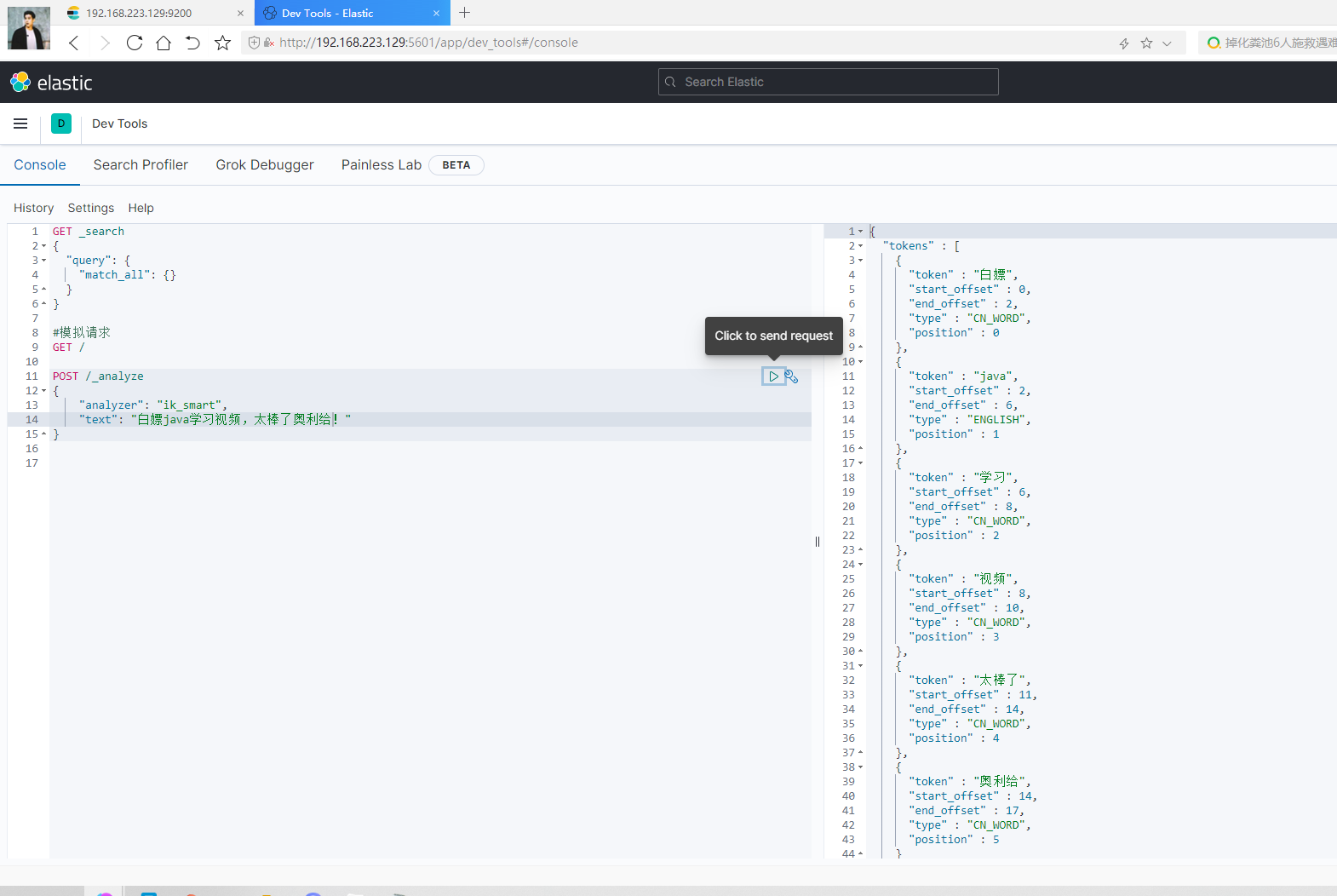
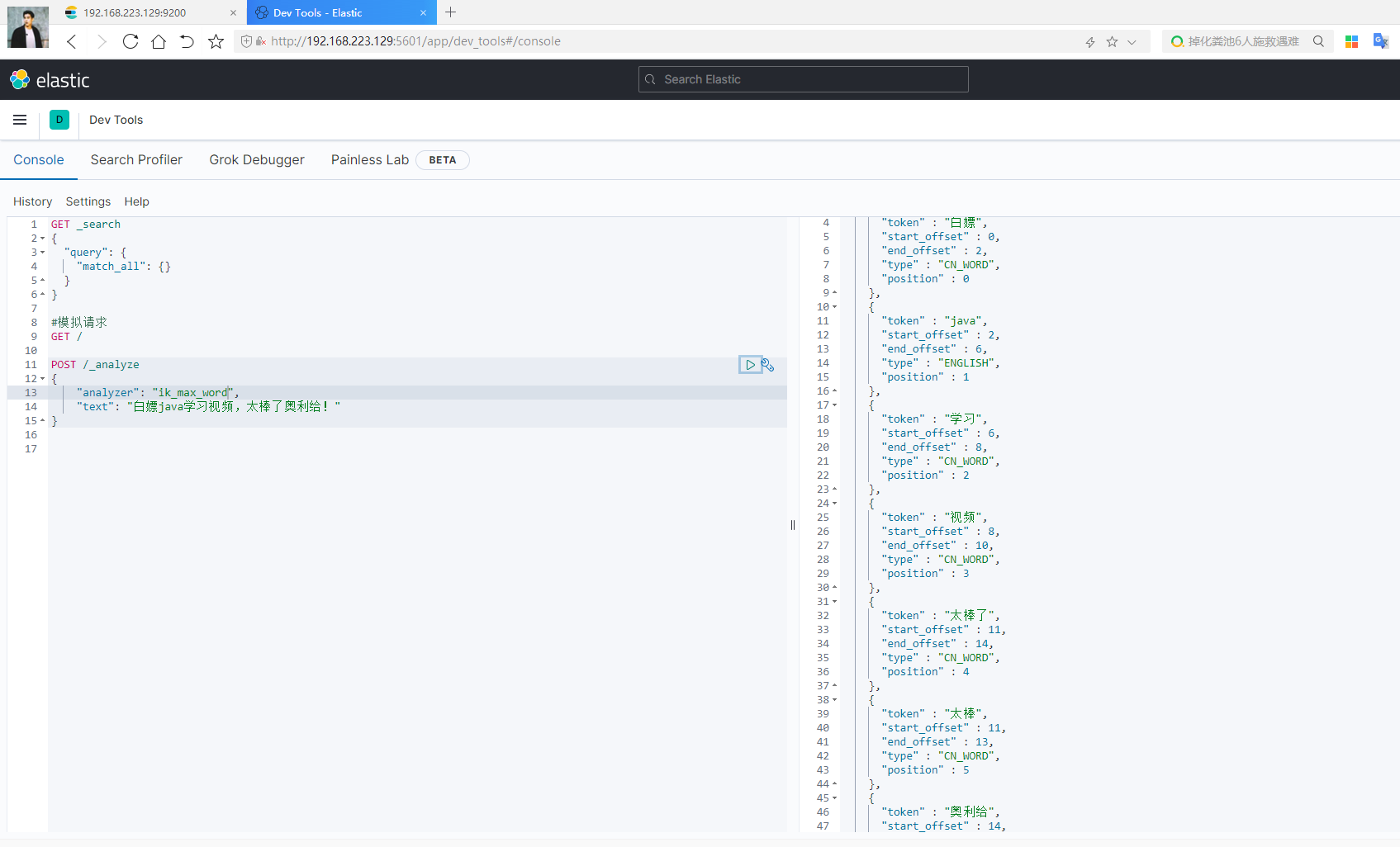
效果展示:
POST /_analyze { "analyzer": "ik_smart", "text": "白嫖java学习视频,太棒了奥利给!" }
POST /_analyze { "analyzer": "ik_max_word", "text": "白嫖java学习视频,太棒了奥利给!" }

 浙公网安备 33010602011771号
浙公网安备 33010602011771号