
JMM(Java Memory Model)、原子性、可见性,有序性
由于并发程序比串行程序复杂得多,其中一个重要原因是在并发程序下数据访问的一致性和安全性将会受到严重的挑战。我们需要在深入了解并行机制的前提下,再定义一种规则,保证多个线程间可以有效的,正确的协同工作。JMM就是为此而生的。
JMM的关键技术点都是围绕着多线程的原子性、可见性和有序性来建立的,下面我们来了解这些概念;
JMM:JMM描述了Java程序中各种变量(线程共享变量)的访问规则,以及在JVM中将变量存储到内存和从内存中读取出变量这样的底层细节。
原子性
原子性是指一个操作是不可中断的,要么不执行,要么执行完成。即使在多线程的环境下,一旦操作开始,就不会被其他线程干扰。
注意:
Java对long和double的赋值操作在32位的虚拟机上是非原子操作!!long和double占用的字节数都是8,也就是64bits。在32位操作系统上对64位的数据的读写要分两步完成,每一步取32位数据。这样对double和long的赋值操作就会有问题:如果有两个线程同时写一个变量内存,一个进程写低32位,而另一个写高32位,这样将导致获取的64位数据是失效的数据。
下面举例说明:
1 public class MultiLong { 2 //定义全局变量 3 public static long test = 0L; 4 5 public static class ChangeT implements Runnable{ 6 private long to; 7 8 public ChangeT(long to) { 9 this.to = to; 10 } 11 @Override 12 public void run() { 13 while(true){ 14 //给全局变量test赋值 15 MultiLong.test = to; 16 Thread.yield(); 17 } 18 } 19 } 20 21 public static class ReadT implements Runnable{ 22 @Override 23 public void run() { 24 while(true){ 25 long temp = MultiLong.test; 26 if (temp != 111L && temp != -222L && temp != 333L && temp != -444L ) { 27 System.out.println(temp); 28 Thread.yield(); 29 } 30 } 31 } 32 } 33 public static void main(String[] args) { 34 new Thread(new ChangeT(111L)).start(); 35 new Thread(new ChangeT(-222L)).start(); 36 new Thread(new ChangeT(333L)).start(); 37 new Thread(new ChangeT(-444L)).start(); 38 new Thread(new ReadT()).start(); 39 } 40 }
正常情况下应该是没有输出的。在64位的虚拟机上一直没有输出结果,在32位虚拟机下运行,输出结果:
4294966852 4294966852 -4294966963 4294966852 4294966852 4294967074
这些数字是我们输入这四个数据的前32位和不同的其他数字的后32位拼接的结果,意思就是要么是写的时候写串位了,要么就是读的时候读串位了。
可见性
可见性是指当一个线程修改了某一个共享变量的值,其他线程能否立即知道这个修改。对于串行程序来说,可见性问题是不存在的。因为你在任何一个操作步骤中修改了一个变量的值,那么在后续的步骤中,读取到的这个变量的值,一定是修改后的值。
但是如果在多线程的并行程序中,如果一个线程修改了某一个全局变量,那么其他的线程未必马上知道这个改动。存在这样的情况:在CPU1和CPU2上各运行了一个线程,它们共享了一个变量t,由于硬件优化或者编译器优化的缘故,将其缓存在cache或寄存器中,这种情况下,CPU2上的线程修改了t的值,那么在CPU1上的线程可能就无法意识到这个改动,依然会读取cache中或者寄存器里的数据,这样就产生了可见性问题。
除了上述的缓存优化和硬件优化会导致可见性问题外,指令重排以及编辑器的优化,都会有可能导致一个线程的修改不会立即被其他线程察觉的问题。通过下图来说明:
注意:
❤ 所有的变量都存储到主内存中
❤ 每个线程都有自己独立的工作内存,里面保存该线程使用到的变量的副本(主内存中该变量的一份拷贝)如下图所示(借大神的图):
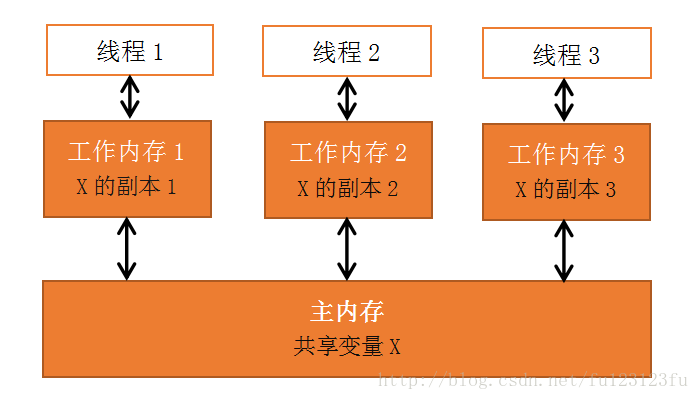
规定:
❤ 线程对共享变量的所有操作都必须在自己的工作内存中进行,不能直接从主内存中读写。
❤ 不同线程间无法直接访问其他线程线程中的工作内存变量,线程间变量值的传递需要通过主内存来完成。
例如:
线程1对共享变量的修改要想被线程2及时看到,必须要经过如下的步骤:
①把工作内存1中更新过的共享变量刷新到主内存中。
②把主内存中最新的共享变量的值更新到工作内存2中。
有序性
有序性的原因是:程序在执行时,可能会进行指令重排,重排后指令顺序与原指令的顺序未必一致。
对于一个线程执行代码而言,我们总是习惯性的认为代码的执行是从先往后,依次执行的。这么理解也不能说完全错误,因为就一个线程内来说,确实会表现成这样。但是,在并发时,程序的执行就有可能会乱序,给人的直观感觉就是:写在前面的代码,会在后面执行。
注意:
这里说的是可能存在,因为如果指令没有重排,这个问题就不存在了,但是指令是否发生重排、如何重排,我们是无法预测的。严谨的描述:线程A的指令执行顺序在线程B看来是没有保证的。就是说,有可能线程B与线程A的执行顺序是一样的。
强调:
对于同一个线程来说,它看到的指令执行顺序一定是一致的。也就是说指令重排有一个基本的前提的,就是保证串行语义的一致性,指令重排不会使串行的语义逻辑发生问题。但是:指令重排可以保证串行语义一致,但是没用义务保证多线程间的语义也一致。
为什么要指令重排?
之所以要指令重排,完全是因为性能考虑。我们知道,一条指令的执行是可以分很多步骤的,简单来说,分为以下几步:
⑴ 取指 IF
⑵ 译码和取寄存器操作数 ID
⑶ 执行或者有效地址计算 EX
⑷ 存储器访问 MEM
⑸ 写回 WB
在CPU实际的执行过程中,它是需要分很多步骤依次执行的。当然,每个步骤所涉及的硬件也可能不同。比如:取指时会用到PC寄存器和存储器,译码时会用到指令寄存器组,执行时会用到ALU,写回时会用到寄存器组。
ALU(ALU(Arithmetic And logic unit)指算数逻辑单元。它是CPU的执行单元,是CPU的核心组成部分,主要功能是进行二进制算数运算)。
由于每一个步骤都有可能用到不同的硬件,因此,聪明的工程师们就发明了流水线技术来执行指令,如下图所示:
之所以要指令重排,完全是因为性能考虑。我们知道,一条指令的执行是可以分很多步骤的,简单来说,分为以下几步:
⑴ 取指 IF
⑵ 译码和取寄存器操作数 ID
⑶ 执行或者有效地址计算 EX
⑷ 存储器访问 MEM
⑸ 写回 WB
在CPU实际的执行过程中,它是需要分很多步骤依次执行的。当然,每个步骤所涉及的硬件也可能不同。比如:取指时会用到PC寄存器和存储器,译码时会用到指令寄存器组,执行时会用到ALU,写回时会用到寄存器组。
ALU(ALU(Arithmetic And logic unit)指算数逻辑单元。它是CPU的执行单元,是CPU的核心组成部分,主要功能是进行二进制算数运算)。
由于每一个步骤都有可能用到不同的硬件,因此,聪明的工程师们就发明了流水线技术来执行指令,如下图所示:
|
指令1 |
|
IF |
ID |
EX |
MEM |
WB |
|
|
指令2 |
|
|
IF |
ID |
EX |
MEM |
WB |
可以看到,当第二条指令执行时,第一条指令其实并未执行完,确切的说第一条指令还没有开始,只是完成了取值操作而已。这样的好处十分明显,假如这里每一个步骤需要1ms,那么指令2等待指令1完全执行后再执行,则需要等待5ms,而使用流水线后,指令2只需要等待1ms就可以执行了。这样性能大大的提升了。
有了流水线这个神器,我们CPU才能才能真正的高效执行,但是,流水线很怕中断,流水线满载时,性能是最好的,但是一旦中断,所有的硬件设备都会进入一个停顿期,再次满载又需要几个周期,因此,性能损失比较大,所以,我们必须想办法尽量不让流水线中断。
那么答案来了,之所以需要做指令重排,就是为了尽量减少流水线中断。当然,指令重排只是减少中断的一种技术,实际上,还会用更多的软硬件技术来防止中断。
下面展示A= B + C 的执行过程,写在左边的是汇编指令:LW 表示 load,其中 LW R1,B,表示把B的值加载到R1寄存器中。ADD指令就是加法,把R1和R2的值相加,并放到R3中。SW表示 store,存储,就是将R3寄存器的值保存到变量A中。
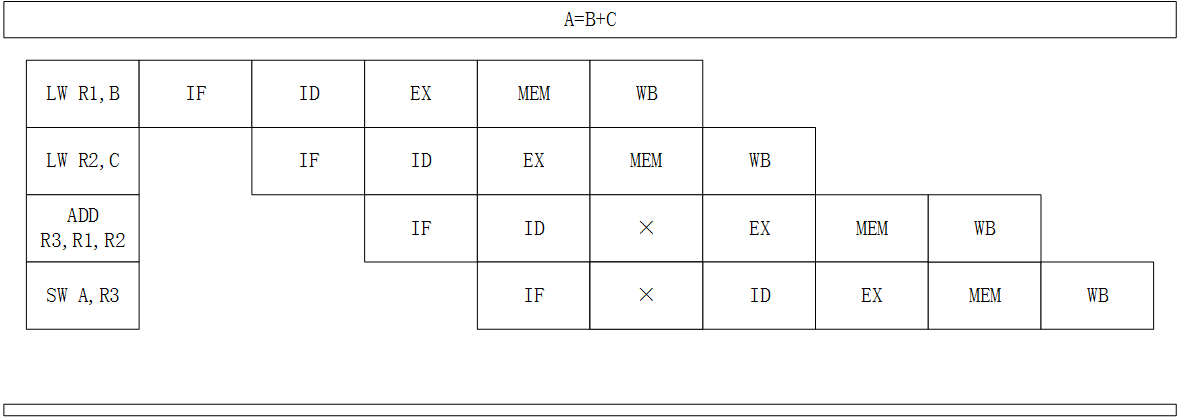
上图中ADD指令上,有一个 × ,表示一个中断。也就是说在ADD这里停顿了一下,为什么会停顿呢?原因就是:R2的数据还没有准备好。,所以ADD操作必须进行一次等待。由于ADD的延迟,导致后面的指令都要慢一个节拍。
理解了上面的A=B+C,来看一个更难的例子,更加深刻的了解指令重排。
a = b + c
d = e - f
那么执行的情况应该是下面这样的:

由于ADD和SUB都需要等待上一条指令的结果,因此有不少的停顿。是否能减少或者消除停顿来提高CPU的性能呢?是可以的,我们只需要将LW Re,e 和 LW Rf,f 移动到前面执行即可,这样先加载e和f对程序是没有影响的,既然在ADD的时候要停顿,那么在停顿的时候还不如去做点事情。
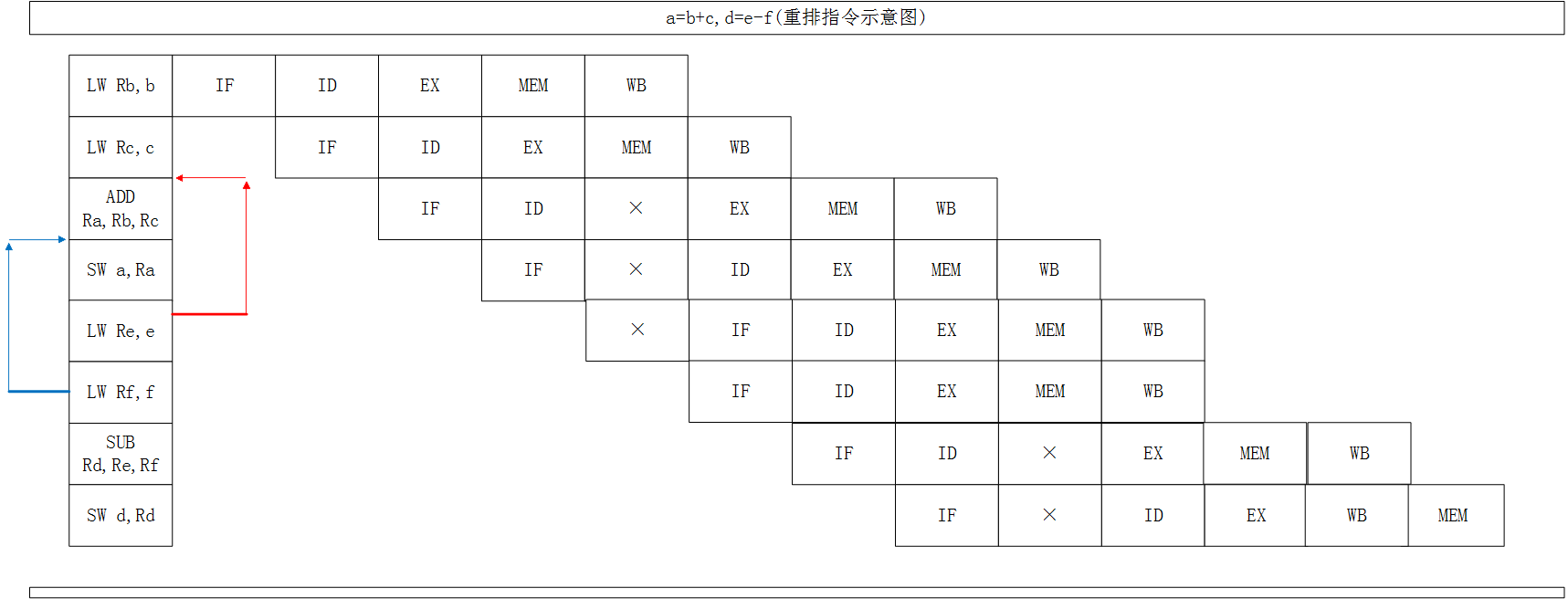
重排后,效果如下:

可以看到,所有的停顿都消失了。流水线十分顺畅的执行。由此可见,指令重排对CPU的处理性能是十分必要的,虽然带来了乱序的问题,但是这点牺牲是完全值得的。
猜想:
为什么不在加载e的时候,紧接着加载f?
LZ觉得是在保证对程序语义一致和流水线顺畅执行(不一定所有的都顺畅执行,为了串行的语义一致,流水线的停顿还是有可能的)的前提下,尽量保证执行顺序是从前往后,依次执行的。(不一定正确!)
Happen-Before 规则
虽然Java虚拟机和执行系统会对指令进行一定的重排,但是指令重排是有原则的,并非所有的指令都可以随意改变执行位置,下面这些原则是指令重排不可违背的:
❤ 程序顺序原则:一个线程内保证语义的串行性;
❤ volatile 规则:volatile 变量的写,先发生于读,这保证了volatile 变量的可见性;
❤ 锁规则:解锁(unlock)必然发生在随后的加锁(lock)前;
❤ 传递性:A先于B,B先于C,A必然先于C;
❤ 线程的start()先于它的每一个动作;
❤ 线程的所有操作先于线程的终结(Thread.join());
❤ 线程的中断(interrupt())先于被中断线程的代码;
❤ 对象的构造函数执行、结束先于finalize()方法;
参考:《Java高并发程序设计》葛一鸣,郭超 编著;


 浙公网安备 33010602011771号
浙公网安备 33010602011771号