

数据库:如何造 10W 条数据
思路:先用代码造数据,保存到一个文档,然后将生成的数据一键复制到需要执行SQL的地方执行
一个简单的案例:
目标:向数据库 testsql 的 kemu_base 表中插入1W 条数据(这里是用 Navicat 连接的数据库)
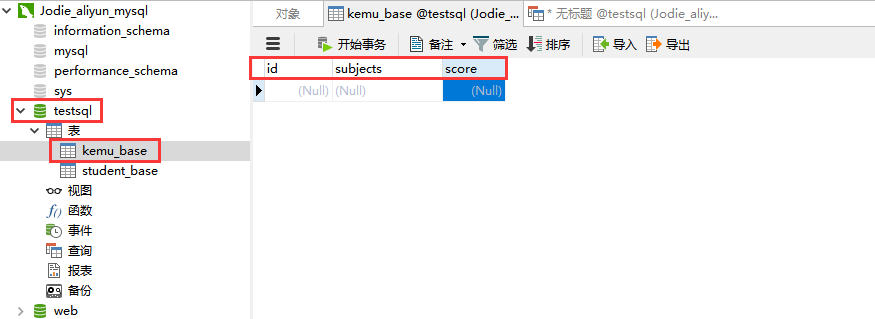
第一步:运行代码造数据,保存到 1.txt 文档(注:这里1.txt 与执行代码的 .py 文件在同一个包的同一个目录下)
# coding:utf-8 import random insert_sql = "INSERT INTO kemu_base(id, subjects, score) VALUES " with open("1.txt", "a") as fp: fp.write(insert_sql+"\n") for i in range(1, 10001): subjects = ['English', 'mathematics', 'Chinese', 'chemical', 'physical'] a = "('{0}', '{1}', '{2}'),".format(str(i), random.choice(subjects), random.randint(0, 100)) with open("1.txt", "a") as fp: fp.write(a+"\n")
1.txt 生成数据如下:

......

第二步:复制数据到编辑器中去执行
- 一键复制数据到 Navicat 中的查询编辑器中,如下:
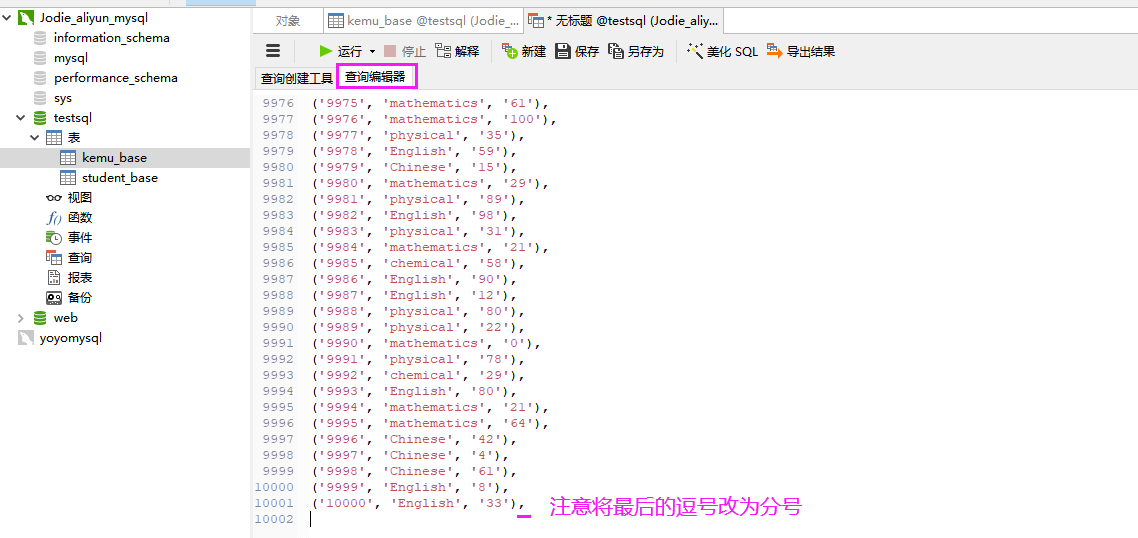

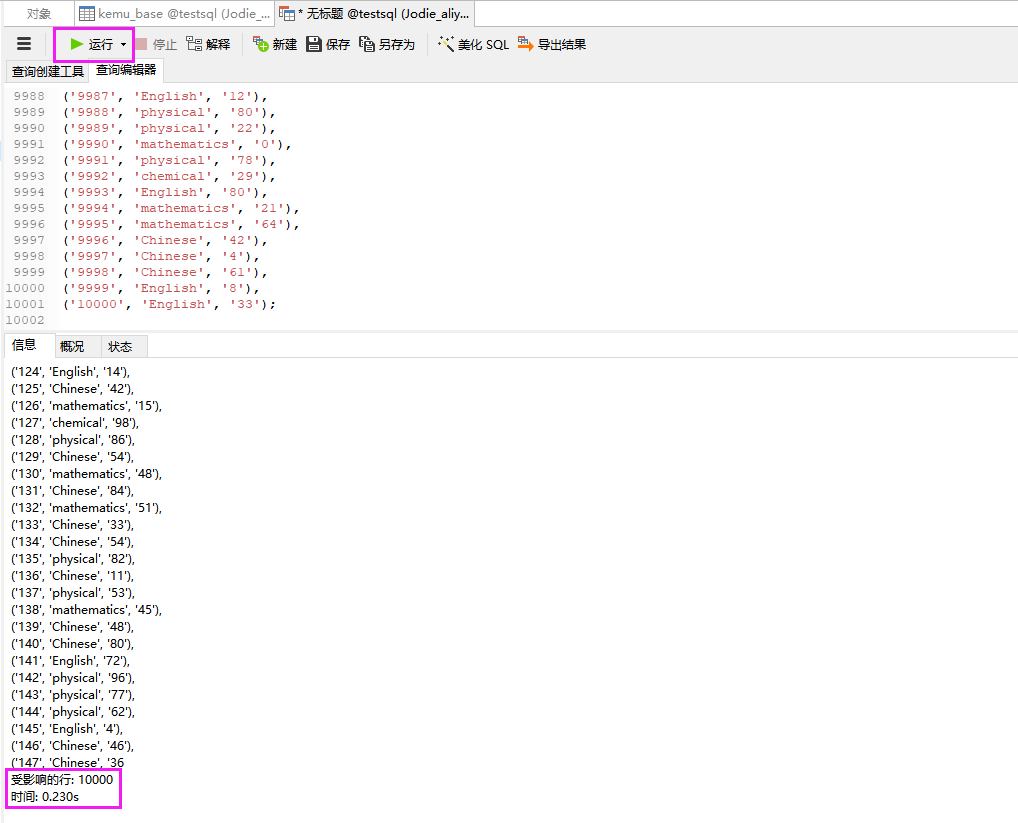
- 点击运行,查看到执行成功,且用时很短
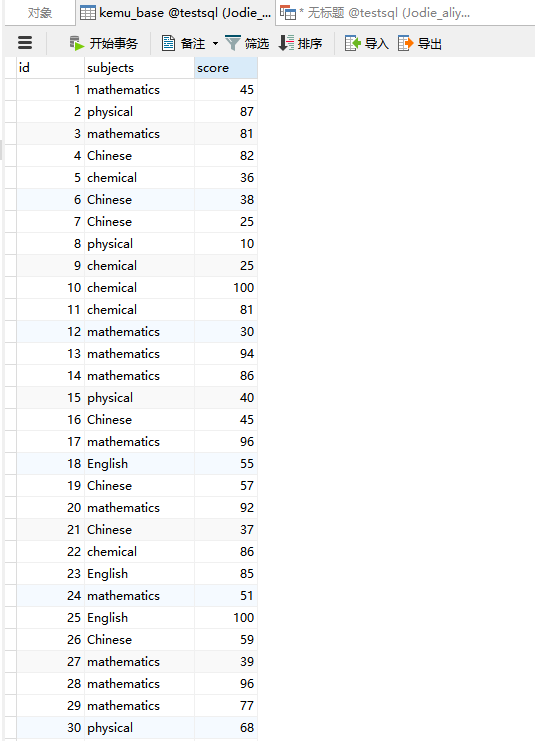
第三步:查看表,已成功生成数据
......
这样生成1W条数据就完成了。
不论要添加多少条,同理,改改 range 的范围即可,
不论有多少个字段,改改 str.format() 即可,format 函数可以接受不限个参数。
知识点:
import random print(random.randint(0, 100)) # 产生 0 到 100 的一个整数型随机数 print(random.choice(subjects)) # 从序列中随机选取一个元素 print(random.random()) # 产生 0 到 1 之间的随机浮点数 print(random.uniform(1.7, 9.3)) # 产生 1.7 到 5.3 之间的随机浮点数,区间可以不是整数 print(random.randrange(1, 100, 2) ) # 生成从 1 到 100 的间隔为 2 的随机整数 s = [1, 2, 3, 4, 5, 6, 7, 8, 9] # 将序列a中的元素顺序打乱 random.shuffle(s) print(s)
格式化字符串的函数 str.format(),它增强了字符串格式化的功能;基本语法是通过 {} 和 : 来代替以前的 % 。
format 函数可以接受不限个参数,位置可以不按顺序;实例如下:
>>>"{} {}".format("hello", "world") # 不设置指定位置,按默认顺序
'hello world'
>>> "{0} {1}".format("hello", "world") # 设置指定位置
'hello world'
>>> "{1} {0} {1}".format("hello", "world") # 设置指定位置
'world hello world'
