

MyBatis结果集映射源码解析
MyBatis作为持久层框架,它最牛逼的地方就是将查询的结果集与Java对象进行映射,让我们解放双手,不用操心双方模型的关系处理,那它怎么实现的呢?
先介绍下ResultMap,ResultMapping
ResultMap&ResultMapping
ResultMap就是平常我们编写的Mapper文件中的某条SQL语句的对象,就是下面这个
<select id="getBlog" resultType="org.apache.ibatis.demo.Blog"> select * from Blog where id = #{id} </select> // 如果有自己定义的resultMap,那么ResultMap对象就优先设置resultMap标签id和type <resultMap id="blogResultMap" type="org.apache.ibatis.demo.Blog"> <result property="id" column="id" /> <result property="conText" column="con_text" /> <result property="userName" column="user_name" /> <collection property="users" select="getUsers" ofType="org.apache.ibatis.demo.User" column="id"/> </resultMap>
ResultMap所拥有的属性
public class ResultMap { private String id; private Class<?> type; // 结果映射行数 private List<ResultMapping> resultMappings; private List<ResultMapping> idResultMappings; private List<ResultMapping> constructorResultMappings; private List<ResultMapping> propertyResultMappings; private Set<String> mappedColumns; // 鉴别器(对查询的结果进行类似Switch的分支处理) private Discriminator discriminator; // 有嵌套的结果集? private boolean hasNestedResultMaps; // 有嵌套查询? private boolean hasNestedQueries; // 是否自动映射 private Boolean autoMapping; }
ResultMapping 对象是 mybatis 的 <resultMap> 节点在 ResultMap 对象中基础组成部分。
// 就是我了 <result property="id" column="id" /> <result property="conText" column="con_text" /> <result property="userName" column="user_name" /> <collection property="users" select="getUsers" ofType="org.apache.ibatis.demo.User" column="id"/>
public class ResultMapping { private Configuration configuration; // bean属性名 private String property; // 表列名 private String column; // java类型 private Class<?> javaType; // jdbc类型 private JdbcType jdbcType; // 类型处理器 private TypeHandler<?> typeHandler; // 嵌套的结果集ResultMapId private String nestedResultMapId; // 嵌套查询的mapperId private String nestedQueryId; private Set<String> notNullColumns; private String columnPrefix; private List<ResultFlag> flags; private List<ResultMapping> composites; private String resultSet; private String foreignColumn; // 是否延迟加载 private boolean lazy; }
TypeHandler类型转换器
作用:JDBC类型和JavaBean类型的转换,底层实际调用的是JDBC的API
基本的api
// 设置参数 void setParameter(PreparedStatement ps, int i, T parameter, JdbcType jdbcType) throws SQLException; // 取得结果 T getResult(ResultSet rs, String columnName) throws SQLException; // 取得结果 T getResult(ResultSet rs, int columnIndex) throws SQLException; // 取得结果,供SP用 T getResult(CallableStatement cs, int columnIndex) throws SQLException;
默认支持的JavaBean类型转换,ps:MyBatis源码真的是大量用到了模版模式啊,如果有新的需求可以继承自BaseTypeHandler自己实现一个TypeHandler
TypeHandlerRegistry类型处理注册器的构造方法,被Configration调用,也就是说Sqlsession工厂创建的时候就设置好了关系
public TypeHandlerRegistry() { // 构造函数里注册系统内置的类型处理器 register(Boolean.class, new BooleanTypeHandler()); register(boolean.class, new BooleanTypeHandler()); register(JdbcType.BOOLEAN, new BooleanTypeHandler()); register(JdbcType.BIT, new BooleanTypeHandler()); register(Byte.class, new ByteTypeHandler()); register(byte.class, new ByteTypeHandler()); register(JdbcType.TINYINT, new ByteTypeHandler()); }
private void register(Type javaType, JdbcType jdbcType, TypeHandler<?> handler) { if (javaType != null) { Map<JdbcType, TypeHandler<?>> map = TYPE_HANDLER_MAP.get(javaType); if (map == null) { map = new HashMap<JdbcType, TypeHandler<?>>(); // kehy:javaType value:map(jdbcType, TypeHandler) TYPE_HANDLER_MAP.put(javaType, map); } map.put(jdbcType, handler); } ALL_TYPE_HANDLERS_MAP.put(handler.getClass(), handler); }
要获取关系的话调用TypeHandlerRegistry的属性TYPE_HANDLER_MAP就可以了
----------------------------------------------------------------------------------------------------
Mybatis的映射规则分为两种,分别是自动映射和手动映射。
自动映射
Sql的列名和 Model 中的字段名称是一样的时候(不区分大小写),mybatis 内部会进行自动映射。
MyBatis中映射范围分为两种:
- 一种是全局配置的自动映射默认为(PARTIAL),分为三个等级:NONE(禁用),PARTIAL(默认,不支持嵌套结果集),FULL(支持嵌套结果集)
- 还有就是ResultMap的自动映射(可以不用手动声明映射,自动创建type对象)
如果有手动指定ResultMap的映射关系,那么全局范围的映射就不会生效。
不建议使用FULL等级的映射,比如:A表嵌套B表,两个有一个字段名称一样MyBatis默认会用A表的值。
手动映射
手动映射根据自己设定的ResultMap映射。如果bean模型有组合关系的话推荐用手动映射,自动映射不支持列名冲突的情况处理。
------------------------------------------------------------------------------------------------------------------------------------------------------
看下结果集映射的处理入口
public List<Object> handleResultSets(Statement stmt) throws SQLException { ErrorContext.instance().activity("handling results").object(mappedStatement.getId()); // 返回的结果集 final List<Object> multipleResults = new ArrayList<Object>(); // 行数 int resultSetCount = 0; // 获取结果集,内部获取JDBC的resultSet方法进行包装主要取出Result的信息以及设置typeHandlerRegistry ResultSetWrapper rsw = getFirstResultSet(stmt); List<ResultMap> resultMaps = mappedStatement.getResultMaps(); //一般resultMaps里只有一个元素 int resultMapCount = resultMaps.size(); validateResultMapsCount(rsw, resultMapCount); while (rsw != null && resultMapCount > resultSetCount) { ResultMap resultMap = resultMaps.get(resultSetCount); // 处理结果集 handleResultSet(rsw, resultMap, multipleResults, null); rsw = getNextResultSet(stmt); // 将已遍历的结果集上下文清理 cleanUpAfterHandlingResultSet(); resultSetCount++; } // 自定义resultSet的逻辑 String[] resultSets = mappedStatement.getResulSets(); if (resultSets != null) { while (rsw != null && resultSetCount < resultSets.length) { ResultMapping parentMapping = nextResultMaps.get(resultSets[resultSetCount]); if (parentMapping != null) { String nestedResultMapId = parentMapping.getNestedResultMapId(); ResultMap resultMap = configuration.getResultMap(nestedResultMapId); handleResultSet(rsw, resultMap, null, parentMapping); } rsw = getNextResultSet(stmt); cleanUpAfterHandlingResultSet(); resultSetCount++; } } // 压缩结果集,是单条就返回单条,是多条就返回一个集合回去 return collapseSingleResultList(multipleResults); } } finally { //关闭结果集 closeResultSet(rsw.getResultSet()); }
private void handleResultSet(ResultSetWrapper rsw, ResultMap resultMap, List<Object> multipleResults, ResultMapping parentMapping) throws SQLException { try { if (parentMapping != null) { handleRowValues(rsw, resultMap, null, RowBounds.DEFAULT, parentMapping); } else { if (resultHandler == null) { // 如果没有resultHandler // 新建个DefaultResultHandler,是个list DefaultResultHandler defaultResultHandler = new DefaultResultHandler(objectFactory); // 调用handleRowValues handleRowValues(rsw, resultMap, defaultResultHandler, rowBounds, null); // 得到记录的list multipleResults.add(defaultResultHandler.getResultList()); } else { // 如果有resultHandler,只需要处理下映射关系就好了,后面要具体返回什么类型由你自己决定 handleRowValues(rsw, resultMap, resultHandler, rowBounds, null); } } } finally { // 关闭结果集 closeResultSet(rsw.getResultSet()); } }
private void handleRowValues(ResultSetWrapper rsw, ResultMap resultMap, ResultHandler resultHandler, RowBounds rowBounds, ResultMapping parentMapping) throws SQLException { if (resultMap.hasNestedResultMaps()) { // 嵌套查询处理 ensureNoRowBounds(); checkResultHandler(); handleRowValuesForNestedResultMap(rsw, resultMap, resultHandler, rowBounds, parentMapping); } else { // 简单查询处理 handleRowValuesForSimpleResultMap(rsw, resultMap, resultHandler, rowBounds, parentMapping); } }
简单查询结果集处理
private void handleRowValuesForSimpleResultMap(ResultSetWrapper rsw, ResultMap resultMap, ResultHandler resultHandler, RowBounds rowBounds, ResultMapping parentMapping) throws SQLException { // 已遍历结果集,用来判断当前遍历的结果集是否超过分页的限制 DefaultResultContext resultContext = new DefaultResultContext(); // 分页处理 skipRows(rsw.getResultSet(), rowBounds); // 遍历多行结果,如果超出limit限制就不遍历了 while (shouldProcessMoreRows(resultContext, rowBounds) && rsw.getResultSet().next()) { // 鉴别器处理的逻辑 ResultMap discriminatedResultMap = resolveDiscriminatedResultMap(rsw.getResultSet(), resultMap, null); // 获取一行值 Object rowValue = getRowValue(rsw, discriminatedResultMap); // 设置已遍历的结果集 storeObject(resultHandler, resultContext, rowValue, parentMapping, rsw.getResultSet()); } }
核心!!!取得一行的值
private Object getRowValue(ResultSetWrapper rsw, ResultMap resultMap) throws SQLException { // 实例化ResultLoaderMap(延迟加载器) final ResultLoaderMap lazyLoader = new ResultLoaderMap(); // 创建对象 Object resultObject = createResultObject(rsw, resultMap, lazyLoader, null); if (resultObject != null && !typeHandlerRegistry.hasTypeHandler(resultMap.getType())) { // 只有简单类型才会走这里的逻辑,其他类型在createResultObject方法里就已经设置完结果集了,因为有typeHandler,直接调用typeHandler将类型匹配设置值就行了 // 将结果集进行包装成元对象,方便通过以字段名的方式获取值 final MetaObject metaObject = configuration.newMetaObject(resultObject); boolean foundValues = !resultMap.getConstructorResultMappings().isEmpty(); if (shouldApplyAutomaticMappings(resultMap, false)) { // 自动映射,具体操作是通过反射获取字段的属性类型,根据属性匹配对应类型的typeHandler,由typeHandler获取值 foundValues = applyAutomaticMappings(rsw, resultMap, metaObject, null) || foundValues; } // 手动映射设置在这里说明手动映射的级别是比自动映射高的 内部会判断是否有ResultMapping没有就不手动映射了 foundValues = applyPropertyMappings(rsw, resultMap, metaObject, lazyLoader, null) || foundValues; foundValues = lazyLoader.size() > 0 || foundValues; resultObject = foundValues ? resultObject : null; return resultObject; } return resultObject; }
第9行包装成元对象的原理可以看下我之前的文章(也是Mybatis映射的原理)https://www.cnblogs.com/JoJo1021/p/16331963.html
创建对象的方法
private Object createResultObject(ResultSetWrapper rsw, ResultMap resultMap, List<Class<?>> constructorArgTypes, List<Object> constructorArgs, String columnPrefix) throws SQLException { // 得到resultType final Class<?> resultType = resultMap.getType(); final MetaClass metaType = MetaClass.forClass(resultType); final List<ResultMapping> constructorMappings = resultMap.getConstructorResultMappings(); if (typeHandlerRegistry.hasTypeHandler(resultType)) { // 基本型 return createPrimitiveResultObject(rsw, resultMap, columnPrefix); } else if (!constructorMappings.isEmpty()) { // 有参数的构造函数,需要注意一点它是按构造方法的形参顺序设置值的,如果结果集取出来的结果顺序和形参的顺序不一致那么就可能造成双方类型对不上的情况 return createParameterizedResultObject(rsw, resultType, constructorMappings, constructorArgTypes, constructorArgs, columnPrefix); } else if (resultType.isInterface() || metaType.hasDefaultConstructor()) { // 普通bean类型 return objectFactory.create(resultType); } else if (shouldApplyAutomaticMappings(resultMap, false)) { // resultMappr的自动映射 return createByConstructorSignature(rsw, resultType, constructorArgTypes, constructorArgs, columnPrefix); }
看下有参数构造函数怎么处理的吧
private Object createParameterizedResultObject(ResultSetWrapper rsw, Class<?> resultType, List<ResultMapping> constructorMappings, List<Class<?>> constructorArgTypes, List<Object> constructorArgs, String columnPrefix) throws SQLException { boolean foundValues = false; for (ResultMapping constructorMapping : constructorMappings) { final Class<?> parameterType = constructorMapping.getJavaType(); // 获取sql字段名 final String column = constructorMapping.getColumn(); final Object value; // 嵌套结果集的处理 if (constructorMapping.getNestedQueryId() != null) { value = getNestedQueryConstructorValue(rsw.getResultSet(), constructorMapping, columnPrefix); } else if (constructorMapping.getNestedResultMapId() != null) { final ResultMap resultMap = configuration.getResultMap(constructorMapping.getNestedResultMapId()); value = getRowValue(rsw, resultMap); } else { // 正常处理 final TypeHandler<?> typeHandler = constructorMapping.getTypeHandler(); value = typeHandler.getResult(rsw.getResultSet(), prependPrefix(column, columnPrefix)); } constructorArgTypes.add(parameterType); // 处理结果集,这里就简单的从集合里添加下元素 constructorArgs.add(value); foundValues = value != null || foundValues; } // 直接将结果集传过去用对象工厂创建对象,也就是说是按照构造函数形参顺序设置值的 return foundValues ? objectFactory.create(resultType, constructorArgTypes, constructorArgs) : null; }
嵌套查询结果集处理
看一下数据库查询的结果和我们想要转换的结果结构上的差异
bean对象,一个树形结构
public class Blog { // 这个博客有哪些用户 private List<User> users; private Integer id; private String userName; private String conText; } public class User { private Integer uId; // 我属于哪个博客 private Integer bId; }
数据库查询的结果是以平铺的形式
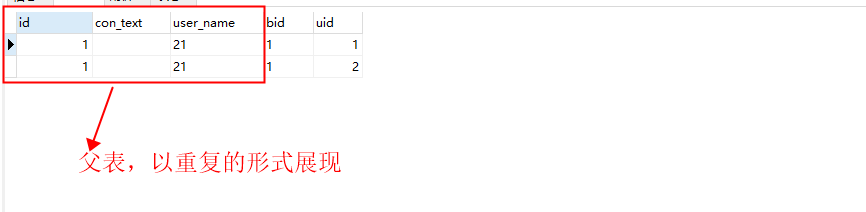
返回的resultMapper
<resultMap id="blogResultMap" type="org.apache.ibatis.demo.Blog"> <result property="id" column="id" /> <result property="conText" column="con_text" /> <result property="userName" column="user_name" /> <collection property="users" ofType="org.apache.ibatis.demo.User" > <result property="id" column="uid" /> <result property="name" column="name" /> </collection> </resultMap>
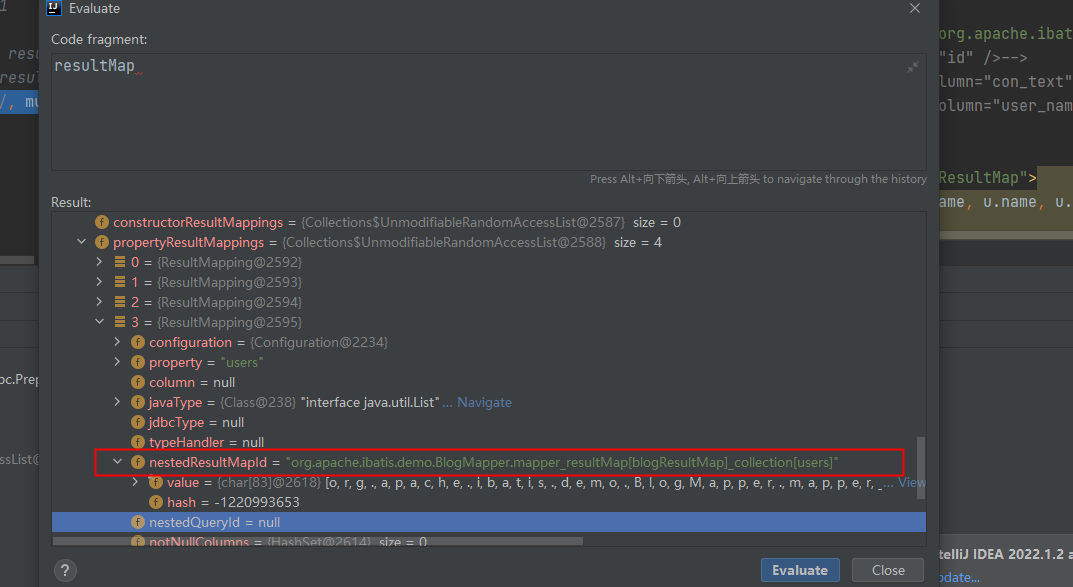
现在的需求将平铺的结果转换成具有父子级关系的树形结构你会怎么做呢??
先介绍下比较重要的属性
- nestedResultObjects:父查询Map集合,存在的理由就是为了将重复父结果集进行过滤。
- ancestorObjects:复合结果查询Map集合,存在的理由是将重复的复合结果集进行过滤。
- absoluteKey(单体key):没有任何关联的key
- combinedKey(复合查询key):父查询和嵌套查询的集合体
private void handleRowValuesForNestedResultMap(ResultSetWrapper rsw, ResultMap resultMap, ResultHandler resultHandler, RowBounds rowBounds, ResultMapping parentMapping) throws SQLException { final DefaultResultContext resultContext = new DefaultResultContext(); skipRows(rsw.getResultSet(), rowBounds); Object rowValue = null; // 每行的循环,如果超过分页限制或结果集遍历完了就结束 while (shouldProcessMoreRows(resultContext, rowBounds) && rsw.getResultSet().next()) { // 鉴别器处理的逻辑 final ResultMap discriminatedResultMap = resolveDiscriminatedResultMap(rsw.getResultSet(), resultMap, null); // key组成部分为property名和结果 final CacheKey rowKey = createRowKey(discriminatedResultMap, rsw, null); // 获取父查询的结果 Object partialObject = nestedResultObjects.get(rowKey); // 是否有排序 if (mappedStatement.isResultOrdered()) { if (partialObject == null && rowValue != null) { // 将之前缓存的父查询结果给清除 nestedResultObjects.clear(); storeObject(resultHandler, resultContext, rowValue, parentMapping, rsw.getResultSet()); } rowValue = getRowValue(rsw, discriminatedResultMap, rowKey, rowKey, null, partialObject); } else { // 获取一条值,跟简单查询不一样,注意一下这里传了两个key是一样的 rowValue = getRowValue(rsw, discriminatedResultMap, rowKey, rowKey, null, partialObject); if (partialObject == null) { storeObject(resultHandler, resultContext, rowValue, parentMapping, rsw.getResultSet()); } } } if (rowValue != null && mappedStatement.isResultOrdered() && shouldProcessMoreRows(resultContext, rowBounds)) { storeObject(resultHandler, resultContext, rowValue, parentMapping, rsw.getResultSet()); } }
看下查询一条怎么处理的
private Object getRowValue(ResultSetWrapper rsw, ResultMap resultMap, CacheKey combinedKey/*复合key*/, CacheKey absoluteKey/*当前key*/, String columnPrefix, Object partialObject) throws SQLException { final String resultMapId = resultMap.getId(); Object resultObject = partialObject; // 如果父查询结果之前缓存过的情况下 if (resultObject != null) { // 父查询就没必要再映射创建对象了,直接处理嵌套查询 final MetaObject metaObject = configuration.newMetaObject(resultObject); // 设置一下ancestorObjects,设置ancestorObjects都带上了父查询的结果说明了什么?说明了子查询的重复条件是必须关联父查询的 putAncestor(absoluteKey, resultObject, resultMapId, columnPrefix); // 嵌套结果集处理 applyNestedResultMappings(rsw, resultMap, metaObject, columnPrefix, combinedKey, false); // 删除嵌套查询缓存,生命周期只在父查询还存在的情况下 ancestorObjects.remove(absoluteKey); } else { final ResultLoaderMap lazyLoader = new ResultLoaderMap(); resultObject = createResultObject(rsw, resultMap, lazyLoader, columnPrefix); if (resultObject != null && !typeHandlerRegistry.hasTypeHandler(resultMap.getType())) { final MetaObject metaObject = configuration.newMetaObject(resultObject); boolean foundValues = !resultMap.getConstructorResultMappings().isEmpty(); if (shouldApplyAutomaticMappings(resultMap, true)) { // 自动映射 foundValues = applyAutomaticMappings(rsw, resultMap, metaObject, columnPrefix) || foundValues; } // 手动映射 foundValues = applyPropertyMappings(rsw, resultMap, metaObject, lazyLoader, columnPrefix) || foundValues; // 设置一下ancestorObjects putAncestor(absoluteKey, resultObject, resultMapId, columnPrefix); // 嵌套结果集处理,父查询没有重复但是可能嵌套结果跟父查询重复了(也就是双方同属一个对象的情况),需要给父查询映射,所以传个true foundValues = applyNestedResultMappings(rsw, resultMap, metaObject, columnPrefix, combinedKey, true) || foundValues; ancestorObjects.remove(absoluteKey); foundValues = lazyLoader.size() > 0 || foundValues; // foundValues如果为false说明结果之前缓存过了,返回个null就行了 resultObject = foundValues ? resultObject : null; } if (combinedKey != CacheKey.NULL_CACHE_KEY) { // 保存结果,因为递归调用的原因,通常保存两种一种是嵌套结果,一种是父查询+嵌套结果(复合结果) nestedResultObjects.put(combinedKey, resultObject); } } return resultObject; }
嵌套结果集处理
private boolean applyNestedResultMappings(ResultSetWrapper rsw, ResultMap resultMap, MetaObject metaObject, String parentPrefix, CacheKey parentRowKey, boolean newObject) { boolean foundValues = false; // 遍历ResultMapping for (ResultMapping resultMapping : resultMap.getPropertyResultMappings()) { final String nestedResultMapId = resultMapping.getNestedResultMapId(); // 如果有嵌套结果集 if (nestedResultMapId != null && resultMapping.getResultSet() == null) { try { final String columnPrefix = getColumnPrefix(parentPrefix, resultMapping); final ResultMap nestedResultMap = getNestedResultMap(rsw.getResultSet(), nestedResultMapId, columnPrefix); CacheKey rowKey = null; Object ancestorObject = null; // 嵌套结果的id有缓存的情况下 if (ancestorColumnPrefix.containsKey(nestedResultMapId)) { rowKey = createRowKey(nestedResultMap, rsw, ancestorColumnPrefix.get(nestedResultMapId)); // 获取缓存 ancestorObject = ancestorObjects.get(rowKey); } if (ancestorObject != null) { // 是否新建映射 if (newObject) { // 父结果集和嵌套结果集是同一个对象的情况下....需要重新映射,解决循环查询的问题 metaObject.setValue(resultMapping.getProperty(), ancestorObject); } } else { // 创建嵌套结果集的key rowKey = createRowKey(nestedResultMap, rsw, columnPrefix); // 父key和子key进行合并 final CacheKey combinedKey = combineKeys(rowKey, parentRowKey); // 通过复合key查询,能查询到这说明一整条结果集是重复了就返回false,后面就不用处理了 Object rowValue = nestedResultObjects.get(combinedKey); boolean knownValue = (rowValue != null); // 通过MetaObject初始化父对象的属性,创建一个集合 final Object collectionProperty = instantiateCollectionPropertyIfAppropriate(resultMapping, metaObject); if (anyNotNullColumnHasValue(resultMapping, columnPrefix, rsw.getResultSet())) { // 递归调用,映射嵌套的值,又回到了getRowValue rowValue = getRowValue(rsw, nestedResultMap, combinedKey /*复合key*/, rowKey/*当前key*/, columnPrefix, rowValue); if (rowValue != null && !knownValue) { if (collectionProperty != null) { final MetaObject targetMetaObject = configuration.newMetaObject(collectionProperty); // 父对象赋值翻译成代码就是:blog.users.add(new User()) targetMetaObject.add(rowValue); } else { metaObject.setValue(resultMapping.getProperty(), rowValue); } foundValues = true; } } } } catch (SQLException e) { throw new ExecutorException("Error getting nested result map values for '" + resultMapping.getProperty() + "'. Cause: " + e, e); } } } return foundValues; }
流程到这里就结束了,其实只要搞懂那四个属性的作用基本就能搞懂这里的逻辑了,有时间画个流程图吧,简单来说就是去重,其实整体思想跟MetaObject还是有点像的。
总结:
- ResultMapping的nestedResultMapId来区分谁是父谁是子,父结果集通过简单映射来处理,映射完以后进行缓存,如果下一条父结果集重复了那么就不用再映射了只需要再原基础上进行处理子查询结果集就行了,子查询也一样通过简单映射来赋值去重,它分三种情况,一是复合结果(子查询+父查询)重复了那么返回null就行了,二是子查询和父查询两个是一个对象,那么需要重新映射下父查询的对象属性(因为是新的父查询结果集),三是不重复,在父对象的集合属性里add下就行了。这样就完成了将一对一的平铺结构转换成具有父子关系的树形结构的JavaBean对象了。


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 阿里最新开源QwQ-32B,效果媲美deepseek-r1满血版,部署成本又又又降低了!
· AI编程工具终极对决:字节Trae VS Cursor,谁才是开发者新宠?
· 开源Multi-agent AI智能体框架aevatar.ai,欢迎大家贡献代码
· Manus重磅发布:全球首款通用AI代理技术深度解析与实战指南
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!