[CTF_Pwn堆漏洞利用] 2.基础知识——堆相关数据结构
[CTF_Pwn堆漏洞利用] 2.基础知识——堆相关数据结构
我一直都计划开个专题,重新整理一下堆的知识点——这一部分我学的实在是太模糊了。
这篇博客的内容主要讲解堆的基础知识,依托于glibc源码进行剖析讲解。本文以glibc2.23版本作为用例,内容集中于通用的堆基础知识,诸如tcache等高版本的堆特性暂不阐述。
该系列持续更新......
chunk
#ifndef INTERNAL_SIZE_T
#define INTERNAL_SIZE_T size_t
#endif
#define SIZE_SZ (sizeof(INTERNAL_SIZE_T))
struct malloc_chunk {
INTERNAL_SIZE_T prev_size; /* Size of previous chunk (if free). */
INTERNAL_SIZE_T size; /* Size in bytes, including overhead. */
struct malloc_chunk* fd; /* double links -- used only if free. */
struct malloc_chunk* bk;
/* Only used for large blocks: pointer to next larger size. */
struct malloc_chunk* fd_nextsize; /* double links -- used only if free. */
struct malloc_chunk* bk_nextsize;
};
前两个域是堆块头
prev_size,记录物理相邻的前一个堆块的大小
size记录堆块大小,对齐2*SIZE_SZ
其中size域的最后三位作为标记位(AMP),它们从高到低分别表示
NON_MAIN_ARENA,记录当前 chunk 是否不属于主线程,1 表示不属于,0表示属于。
IS_MAPPED,记录当前 chunk 是否是由 mmap 分配的。
PREV_INUSE,记录前一个 chunk 块是否被分配。一般来说,堆中第一个被分配的内存块的 size 字段的 P 位都会被设置为 1,以便于防止访问前面的非法内存。
当一个 chunk 的 size 的 P 位为 0 时,我们能通过 prev_size 字段来获取上一个 chunk 的大小以及地址。这也方便进行空闲 chunk 之间的合并。
如果这个chunk是正在使用未被free的chunk,那么它的内部结构就到此为止了,此后便是内存块中存放的数据,当然了,分配到内存可不是如上只有6 * SIZE_SZ这么大,只是内存块的前6 * SIZE_SZ会有特殊用处罢了。
但是如果这个chunk被free了,那么后面的四个指针就会派上用场了
fd,bk,用于管理被释放的堆块,fd指向下一个,bk指向上一个,chunk通过它们和bin构成一个双向链表
-> -> -> -> -> fd
bin chunk chunk chunk chunk chunk
<- <- <- <- <- bk
bin这个东西你可以暂时理解为管理free的堆块的一个链表头
fd_nextsize和bk_nextsize用于大堆块(large bins),用来指向另一个large bin中的第一个空闲堆块(这个放在后面细说)
这里要注意chunk的后面四个指针指向另外某个malloc_chunk结构体的开头,这里是用于内部的管理,但是实际使用时malloc函数返回的指针实际指向chunk开头+2*SIZE_SZ的地方,即从fd域开始。
关于chunk有许多常见的宏,比如:
/*内存块和堆块头指针转换,这里的“mem”就是malloc返回的内存块地址*/
#define chunk2mem(p) ((void*)((char*)(p) + 2*SIZE_SZ))
#define mem2chunk(mem) ((mchunkptr)((char*)(mem) - 2*SIZE_SZ))
/*最小堆块大小,可以看到堆块至少要包含fd和bk*/
#define MIN_CHUNK_SIZE (offsetof(struct malloc_chunk, fd_nextsize))
/*这个大概是个掩码,相当于二进制的111*/
#define SIZE_BITS (PREV_INUSE | IS_MMAPPED | NON_MAIN_ARENA)
/*根据size域获取堆块大小,屏蔽了后三位*/
#define chunksize(p) ((p)->size & ~(SIZE_BITS))
(如果我某天又想起来了某些重要的宏,我一定会再回来添加...)
bins
glibc的堆管理系统的实际工作,其实就是管理那些被释放的内存块。这些内存块通过链表的方式串联起来,而所谓的bins正是这些链表的表头。
根据free的chunk的大小和时机,我们将堆块分为如下四类,fast bin,small bin large bin,unsorted bin。
bins数组在malloc_state结构中,至于后面这个结构是什么,我们后面会讲。
下面是一个bins数组,绝大多数bin都在这里,不过fast bin不在这里,他比较特殊。
typedef struct malloc_chunk* mchunkptr;
#define NBINS 128
mchunkptr bins[NBINS * 2 - 2];
可以看到,bins数组就是由很多个chunk*指针组成的。
不同的索引对应不同的bin类型
| 索引 | 类型 |
|---|---|
| 1 | unsorted bin2 |
| 1-63 | small bin |
| 64-127 | large bin |
有人可能会异或(疑惑),为什么这里的索引不是从0开始的呢?这里要看取某个bin的动作了,没错,这也是一个宏:
typedef struct malloc_chunk *mbinptr;
/*索引定位对应bin*/
#define bin_at(m, i) \
(mbinptr) (((char *) &((m)->bins[((i) - 1) * 2])) \
- offsetof (struct malloc_chunk, fd))
/*找后一个bin,实际上就是加上2*SIZE_SZ*/
#define next_bin(b) ((mbinptr) ((char *) (b) + (sizeof (mchunkptr) << 1)))
m应该填一个malloc_state结构,这个会在后面细说。i则是我们上面说的索引。
也许此时就会有同学发现问题了:似乎这里每个bin占据了bins数组的两个元素,而且这里返回值为mbinptr(即malloc_chunk)!,而且这里还匪夷所思地减了一个2*SIZE_SZ的偏移!这是什么情况呢?其实这里是我们通过malloc_chunk这个类型来记录索引链表,但是记录的过程中只用到了fd和bk这两个指针(统一类型也许是为了方便)。这样,尽管前一个bin的fd和bk对应后一个bin的prev_size和size,但是由于后一个bin并没有用到这两个域,所以不会发生重合,以此我们就实现了空间复用。
为什么要使用fd和bk呢,这大概是为了让bin和chunk更好地融入到一起吧(看看这几个宏)
/* 分别是找离bin最近的和最远的堆块,对应每个bin所占的bins数组的两前一个元素和后一个元素 */
#define first(b) ((b)->fd)
#define last(b) ((b)->bk)
是不是和谐多了,这下子bin本身好像也是一个chunk......
接下来我们分类讲讲这四种bin结构
fast bin
先介绍最最特殊的fast bin吧。
fast bin通过单向链表管理(仅仅使用fd指针),采用LIFO原则,每一个新的chunk会插入到链表的头部(靠近bin),且取出时也是优先从头部取出。
fast bin并不在上面说的bins数组中,而是在下面的这个fastbinsY这个结构里面,当然,这个fastbinsY也在malloc_state这个结构中。
下面是fastbinsY的定义和一些相关宏,之前上面讲bins时的一些宏在这里可能不太管用——它们适用于后面三个。
typedef struct malloc_chunk *mfastbinptr;
#define fastbin(ar_ptr, idx) ((ar_ptr)->fastbinsY[idx])
/*根据大小查索引*/
#define fastbin_index(sz) \
((((unsigned int) (sz)) >> (SIZE_SZ == 8 ? 4 : 3)) - 2)
/*最大fast bin*/
#define MAX_FAST_SIZE (80 * SIZE_SZ / 4)
#define NFASTBINS (fastbin_index (request2size (MAX_FAST_SIZE)) + 1)
#define set_max_fast(s) \
global_max_fast = (((s) == 0) \
? SMALLBIN_WIDTH : ((s + SIZE_SZ) & ~MALLOC_ALIGN_MASK))
#define get_max_fast() global_max_fast
#define DEFAULT_MXFAST (64 * SIZE_SZ / 4)
mfastbinptr fastbinsY[NFASTBINS];
fast bin,bin如其名,特点就是快,这个范围的chunk被释放时不会发生合并,物理相邻的后一个堆块的P为始终为1,后一个堆块的prev_size也不会启用,这就大大减少了维护损耗。
fastbin中的每个堆块大小都是一样的,这里可以看到,堆块大小和索引的关系大致为 size == i * ( 2 * SIZE_SZ )。64位下,就是0x20为0开始,每0x10递增。fastbin最大可以是MAX_FAST_SIZE,但是这只是一个理论的上界限,实际我们可以通过set_max_fast进行一个预设。通常,global_max_fast,会被预设为DEFAULT_MXFAST,在64位下,这个值是0x80。
fastbin中的chunk会被malloc_consolidate函数清空,不过这个是后话了,我们以后再聊。
small bin
small bin,被维护在bins数组当中的索引2-63号。和fast bin一样,链表中每一个堆块大小都是一样的,不过它是采用双向链表进行管理,并且采用FIFO机制,表头插入,表尾取出。
/*对齐方式*/
#define MALLOC_ALIGNMENT (2 *SIZE_SZ < __alignof__ (long double) \
? __alignof__ (long double) : 2 *SIZE_SZ)
/*似乎也是对齐方式*/
#define SMALLBIN_WIDTH MALLOC_ALIGNMENT
#define SMALLBIN_CORRECTION (MALLOC_ALIGNMENT > 2 * SIZE_SZ)
#define NSMALLBINS 64
#define MIN_LARGE_SIZE ((NSMALLBINS - SMALLBIN_CORRECTION) * SMALLBIN_WIDTH)
#define in_smallbin_range(sz) \
((unsigned long) (sz) < (unsigned long) MIN_LARGE_SIZE)
#define smallbin_index(sz) \
((SMALLBIN_WIDTH == 16 ? (((unsigned) (sz)) >> 4) : (((unsigned) (sz)) >> 3))\
+ SMALLBIN_CORRECTION)
仔细算一下就能知道MIN_LARGE_SIZE是63*SIZE_SZ,在64位下是1008,从1024开始,就是large bin了
small bin也是从2,也就是2(2SIZE_T)开始的,也许你已经发现了一个问题:这不是和fast bin范围重合了吗?的确如此,但是small bin并不具有fast bin不切割不合并不标记的特点,两者仍有差别,而fast bin中的堆块也可以进到small bin当中。这在后来我们剖析函数源码时会有进一步讲解。
large bin
感觉比较吃力的同学可以先跳过这一节,large bin在堆攻击学习的前期不太会涉及,当然,欠的债迟早要补——和我一样。
从small bin后面(索引64以后)就全是large bin的天下了(63个),这要注意里large bin中的chunk大小并不是完全一致的,但也不是杂乱无章,每一个bin中chunk大小一定是在一定的区间范围内。
这63个bin被分为了6组,每组内的相邻的bin之间范围的范围构成一个等差数列。
| 组 | 数量 | 公差 |
|---|---|---|
| 1 | 32 | 64B |
| 2 | 16 | 512B |
| 3 | 8 | 4096B |
| 4 | 4 | 32768B |
| 5 | 2 | 262144B |
| 6 | 1 | 不限制 |
#define largebin_index_32(sz) \
(((((unsigned long) (sz)) >> 6) <= 38) ? 56 + (((unsigned long) (sz)) >> 6) :\
((((unsigned long) (sz)) >> 9) <= 20) ? 91 + (((unsigned long) (sz)) >> 9) :\
((((unsigned long) (sz)) >> 12) <= 10) ? 110 + (((unsigned long) (sz)) >> 12) :\
((((unsigned long) (sz)) >> 15) <= 4) ? 119 + (((unsigned long) (sz)) >> 15) :\
((((unsigned long) (sz)) >> 18) <= 2) ? 124 + (((unsigned long) (sz)) >> 18) :\
126)
#define largebin_index_32_big(sz) \
(((((unsigned long) (sz)) >> 6) <= 45) ? 49 + (((unsigned long) (sz)) >> 6) :\
((((unsigned long) (sz)) >> 9) <= 20) ? 91 + (((unsigned long) (sz)) >> 9) :\
((((unsigned long) (sz)) >> 12) <= 10) ? 110 + (((unsigned long) (sz)) >> 12) :\
((((unsigned long) (sz)) >> 15) <= 4) ? 119 + (((unsigned long) (sz)) >> 15) :\
((((unsigned long) (sz)) >> 18) <= 2) ? 124 + (((unsigned long) (sz)) >> 18) :\
126)
// XXX It remains to be seen whether it is good to keep the widths of
// XXX the buckets the same or whether it should be scaled by a factor
// XXX of two as well.
#define largebin_index_64(sz) \
(((((unsigned long) (sz)) >> 6) <= 48) ? 48 + (((unsigned long) (sz)) >> 6) :\
((((unsigned long) (sz)) >> 9) <= 20) ? 91 + (((unsigned long) (sz)) >> 9) :\
((((unsigned long) (sz)) >> 12) <= 10) ? 110 + (((unsigned long) (sz)) >> 12) :\
((((unsigned long) (sz)) >> 15) <= 4) ? 119 + (((unsigned long) (sz)) >> 15) :\
((((unsigned long) (sz)) >> 18) <= 2) ? 124 + (((unsigned long) (sz)) >> 18) :\
126)
#define largebin_index(sz) \
(SIZE_SZ == 8 ? largebin_index_64 (sz) \
: MALLOC_ALIGNMENT == 16 ? largebin_index_32_big (sz) \
: largebin_index_32 (sz))
比较复杂对吧。
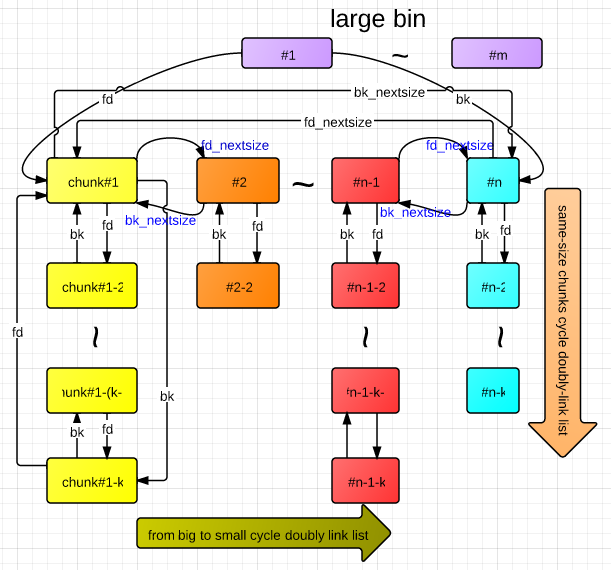
fd和bk指针,在large bin中仍然启用,并且和small bin一样用来你链接大小相同的chunk,但是我们上面讲了,large bin中的堆块大小是不相同的,为了便于管理,large bin启用了fd_nextsize和bk_nextsize这两个域,在相同大小的chunk各自通过fd和bk串联成双向链表后,这些链表头部的chunk也会依次通过fd_nextsize和bk_nextsize串联起来。而bin的fd和bk则会分别指向最大的链表和最小的链表。
具体的串联方式见下图(转自博客ptmalloc代码浅析2(small bin/large bin结构图)),这里不详细介绍了,后面会单独分析large bin的管理机制,到时候我们再细说
unsorted bin
这个在bins最开头的一项,索引为1。就像它的名字一样,里面的chunk的未整理的,大小不一致。
这个bin你可以理解为是一个缓冲区,任何要放入small bin或者large bin的chunk都要先放进unsorted bin里面,再经过后续的一些整理进入unsorted bin。
unsorted bin和small bin很相似,除了里面储存的chunk大小范围不一样之外,其余的特点大致都相同(FIFO,双向链表管理等等)
这里要介绍一个宏unlink,用来把chunk(P)从它所处的双向链表中取出,在unsorted bin中比较常见,而且针对于unsorted bin chunk也有一个unlink的混淆攻击手段。
#define unlink(AV, P, BK, FD) \
最后再介绍一个通用的宏,用来查找某个大小对应的bin索引
#define bin_index(sz) \
((in_smallbin_range (sz)) ? smallbin_index (sz) : largebin_index (sz))
微观结构——杂项
top chunk
堆段内存分配,其实就相当于切蛋糕,分配出去的是小蛋糕,切的就是top chunk。
top chunk在main arena中可以通过sbrk扩展,在thread heap中通过mmap映射。
top chunk的P位永远是1,否则之前分配的chunk就应该被合并进来。
last reminder
有的时候我们在malloc时会从一个已经free掉的堆块中切一个合适堆块出来,剩下的东西就是last reminder
被切出来的last reminder会被扔进unsorted bin
宏观结构
arena
这一块我也说不明白,其实不懂的话基础的堆题不受影响。
arena在线程第一次申请内存时创建,不是每个线程都有对应的arena
需要注意的一点,main_arena(主线程的arena)保存在libc段中。
malloc_state
记录了arena申请的内存信息
struct malloc_state
{
/* Serialize access. */
mutex_t mutex;
/* Flags (formerly in max_fast). */
int flags;
/* Fastbins */
mfastbinptr fastbinsY[NFASTBINS];
/* Base of the topmost chunk -- not otherwise kept in a bin */
mchunkptr top;
/* The remainder from the most recent split of a small request */
mchunkptr last_remainder;
/* Normal bins packed as described above */
mchunkptr bins[NBINS * 2 - 2];
/* Bitmap of bins */
unsigned int binmap[BINMAPSIZE];
/* Linked list */
struct malloc_state *next;
/* Linked list for free arenas. Access to this field is serialized
by free_list_lock in arena.c. */
struct malloc_state *next_free;
/* Number of threads attached to this arena. 0 if the arena is on
the free list. Access to this field is serialized by
free_list_lock in arena.c. */
INTERNAL_SIZE_T attached_threads;
/* Memory allocated from the system in this arena. */
INTERNAL_SIZE_T system_mem;
INTERNAL_SIZE_T max_system_mem;
};
里面有很多我们之前提到的结构(bins等)
宏观结构可能在前期不是很重要,对于其结构稍作了解即可,前期学习的重点要放在malloc和free的那一堆繁琐却不严密的检查机制上。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号