
第一次个人编程作业
一、github链接
二、代码原理

(在最开始的时候选择了python自带库中的文本相似度比对函数,后来由于乱序文本的输出未能达到我的预期,就换了其他方法)
1.读入文本并进行文本处理,包括去标点,jieba分词,其中jieba的内容原理是加载字典, 生成trie树,给定待分词的句子, 使用正则获取连续的 中文字符和英文字符, 切分成 短语列表, 对每个短语使用DAG(查字典)和动态规划, 得到最大概率路径, 对DAG中那些没有在字典中查到的字, 组合成一个新的片段短语, 使用HMM模型进行分词,使用python的yield 语法生成一个词语生成器, 逐词语返回。
def read_txt(txtname):
file=open(txtname,"r",encoding="utf-8")
r = '[’!"#$%&\'()*+,-./:;<=>?@[\\]^_`{|}~\n。!, ]+'
word=file.read()
word=re.sub(r,'',word)
file.close()
return word
def do_jieba(name):
jieba.analyse.set_stop_words("stopword.txt")
word=jieba.cut(name)
result=jieba.analyse.extract_tags("".join(word),topK=50)
return result
2.利用Jaccard系数进行计算

def jaccard():
word_origin = do_jieba(read_txt(parameter1)) #进行jieba分词
word_copy = do_jieba(read_txt(parameter2))
len_mixed = len(list(set(word_origin).intersection(set(word_copy))))
len_union = len(list(set(word_origin).union(set(word_copy))))
if len_union != 0:
temp = float(len_mixed) / len_union
return temp
else:
return 0
三、计算模块接口部分
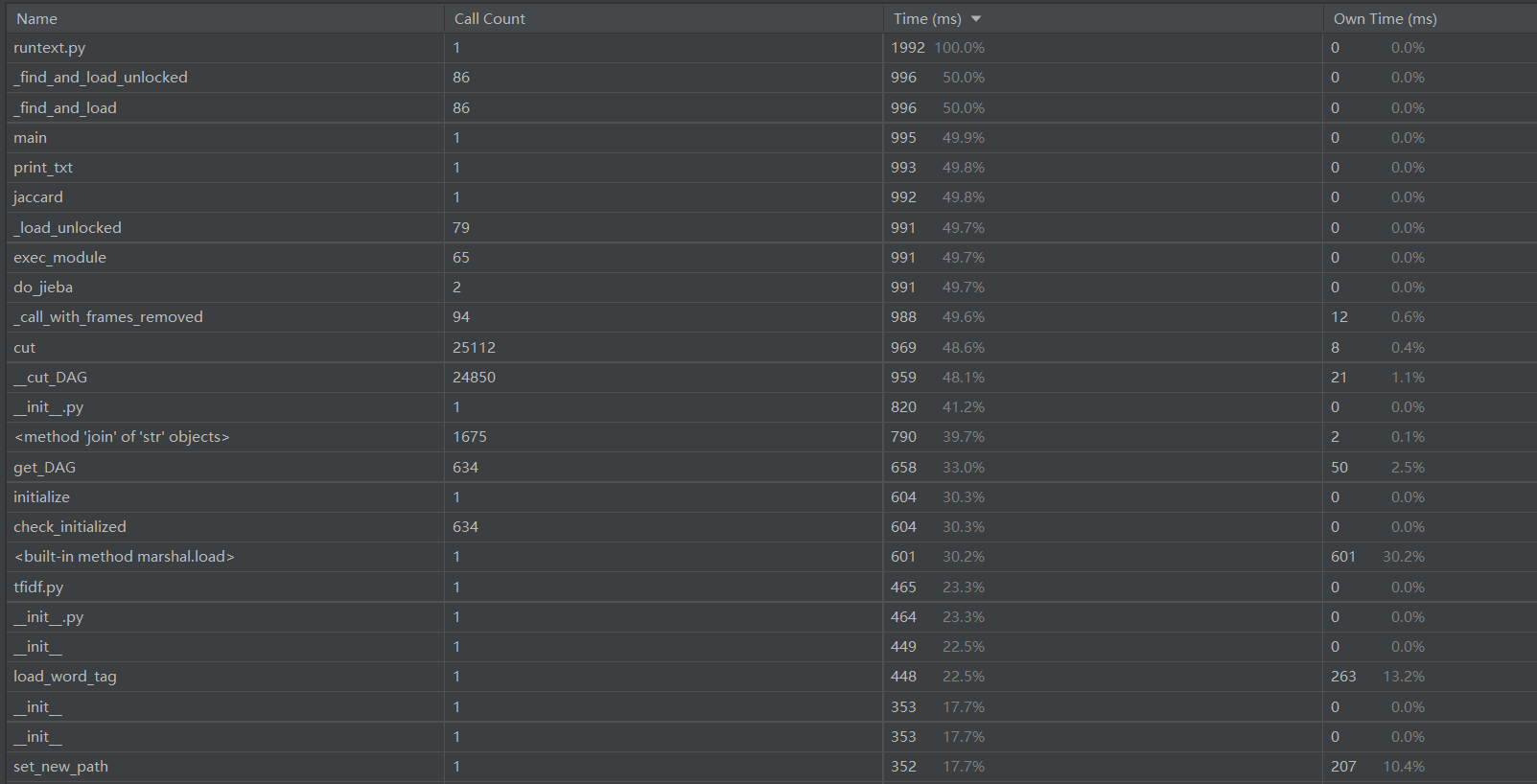
四、计算模块单元测试展示
#部分代码
import unittest
from runtest import testtxt
def test_add(self):
origin = 'orig.txt'
copyword = "orig_0.8_add.txt"
print_txt()
def test_del(self):
origin = 'orig.txt'
copyword = "orig_0.8_del.txt"
print_txt()
#..........
五、异常处理
对于这次作业的异常处理,我大概就处理了一种空白文档的情况。
def exception_hand():
if read_txt(parameter1)=="" or read_txt(parameter2)=="":
raise "存在空白文档"
六、PSP表格
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | 120 | 180 |
| Estimate | 估计这个任务需要多少时间 | 2000 | 2400 |
| Development | 开发 | 2000 | 2400 |
| Analysis | 需求分析 (包括学习新技术) | 200 | 240 |
| Design Spec | 生成设计文档 | 60 | 90 |
| Design Review | 设计复审 | 60 | 40 |
| Coding Standard | 代码规范 (为目前的开发制定合适的规范) | 100 | 150 |
| Design | 具体设计 | 200 | 240 |
| Coding | 具体编码 | 1200 | 1500 |
| Code Review | 代码复审 | 300 | 300 |
| Test | 测试(自我测试,修改代码,提交修改) | 200 | 600 |
| Reporting | 报告 | 120 | 150 |
| Test Repor | 测试报告 | 60 | 100 |
| Size Measurement | 计算工作量 | 20 | 30 |
| Postmortem & Process Improvement Plan | 事后总结, 并提出过程改进计划 | 120 | 120 |
| 合计 | 2780 | 3740 |
七、总结
其实最开始的时候是使用了python的库中的difflib,但可能是我对这个库的理解不到位,在最开始的一版本中对于乱序文本的相似度匹配一直是1,后来选择了jaccard来计算后就没有这个问题了,在这difflib和Jaccard两版本之间我其实还有一个通过计算余弦向量来比较相似度的程序,可是由于意外代码没了,所以才有了这版的诞生,实在是太难了,这次的编程作业给我的感触还是挺多的,包括代码测试异常处理这些以前没有过多接触到的东西,的确是让我学到了特别多。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号