【RL系列】马尔可夫决策过程——Jack‘s Car Rental
本篇请结合课本Reinforcement Learning: An Introduction学习
Jack's Car Rental是一个经典的应用马尔可夫决策过程的问题,翻译过来,我们就直接叫它“租车问题”吧。租车问题的描述如下:
Jack’s Car Rental Jack manages two locations for a nationwide car rental company. Each day, some number of customers arrive at each location to rent cars. If Jack has a car available, he rents it out and is credited $10 by the national company. If he is out of cars at that location, then the business is lost.
Cars become available for renting the day after they are returned. To help ensure that cars are available where they are needed, Jack can move them between the two locations overnight, at a cost of $2 per car moved.
We assume that the number of cars requested and returned at each location are Poisson random variables, where λ is the expected number.
Suppose λ is 3 and 4 for rental requests at the first and second locations and 3 and 2 for returns.
To simplify the problem slightly, we assume that there can be no more than 20 cars at each location (any additional cars are returned to the nationwide company, and thus disappear from the problem) and a maximum of five cars can be moved from one location to the other in one night. We take the discount rate to be γ = 0.9 and formulate this as a continuing finite MDP, where the time steps are days, the state is the number of cars at each location at the end of the day, and the actions are the net numbers of cars moved between the two locations overnight.
简单描述一下:
Jack有两个租车点,1号租车点和2号租车点,每个租车点最多可以停放20辆车。Jack每租车去一辆车可以获利10美金,每天租出去的车与收回的车的数量服从泊松分布。每天夜里,Jack可以在两个租车点间进行车辆调配,每晚最多调配5辆车,且每辆车花费2美金。1号租车点租车数量服从$ \lambda = 3 $的泊松分布,回收数量的$ \lambda = 3 $。二号租车点的租车数量和回收数量的$ \lambda $分别为4和2,试问使用什么样的调配策略可以使得盈利最优化(注意:这里的租车行为与回收行为是强制性的,是不可选择的)。
简单分析一下,每个租车点最多20辆车,那么状态数量就是21*21 = 441个。最多调配5辆车,那么动作集合A = {(-5, 5), (-4, 4),...,(0, 0), (1, -1),...,(5, -5)},动作集合A中的元素表示方法为(1号租车点出入车辆,2号租车点出入车辆),正负号分别表示“入”和“出”。
奖励期望的计算
首先来看一下动作奖励期望如何计算, 我们以动作后状态,1号租车点有10辆车为例:
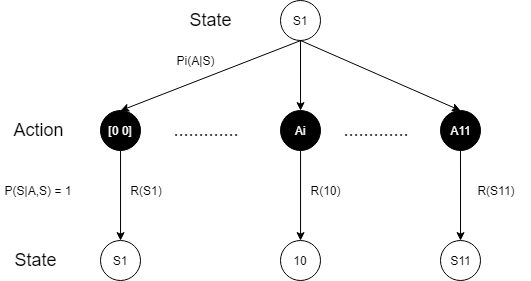
可以肯定的是当前状态S1经过Action选择后的状态是唯一的,也就说对所有的未来可能状态来说$ P(s'|a, s) = 1 $。我们先不考虑由动作影响而造成的负收益(调配车辆的花费),而是着重计算,不论任何一个动作,只要到达状态“1号租车点有10辆车”所获得的收益期望,这样再减去每个动作引起的调配车辆的费用,就是该动作的奖励期望。
考虑状态“1号租车点有10辆车”的未来可能获得收益需要分析在保有10辆车的情况下的租(Rent)与回收(Return)的行为。计算该状态收益的过程实际上是另外一个动作策略符合泊松分布的马尔可夫决策过程。我们将1天内可能发生的Rent与Return行为记录为[#Return #Rent],其中“#Return”表示一天内回收的车辆数,“#Rent”表示租出的的车辆数,设定这两个指标皆不能超过20(理论上来说,进出车辆并不发生在同一时间,这两个指标实际为流量指标,状态每刻不超过20辆即可,但这样有违该题的初衷,且在$ \lambda = 3 $的情况下并没有太大意义,所以直接这样规定了)。假设当天早上,1号租车点里有10辆车,那么在傍晚清点的时候,可能保有的车辆数为0~20辆。如果傍晚关门歇业时还剩0辆车,那么这一天的租收行为$ A_{rt, rn} $可以是:
$$ A_{rt,rn} = \left[\begin{matrix}10 & 0\\ 11 & 1\\12& 2\\...&...\\20 & 10 \end{matrix} \right] $$
可以确定的是,Rent与Return是相互独立的行为或事件且皆服从泊松分布,所以要计算某个行为出现的概率直接将$ P(A_{rt}) $与$ P_(A_{rn}) $相乘就行了,但这里要计算的是条件概率,即为$ P(A_{rt,rn}|S'' = 0) $,所以还需要再与$ P(S'' = 0) $相除,这里的$ P(S'' = 0) $指的是傍晚清点时还剩0辆车的概率。各个租收行为所获得的收益是以租出去的车辆数为准,所以当傍晚还剩0辆车时,这一天的收益期望可以写为:
$$ R(S' = 10|S'' = 0) = 10\left[\begin{matrix} \frac{P(A_{rt} = 10)P(A_{rn} = 0)}{P(S'' = 0)} \\...\\ \frac{P(A_{rt} = 20)P(A_{rn} = 10)}{P(S'' = 0)} \end{matrix} \right]^T \left[\begin{matrix} 10\\11\\...\\20 \end{matrix} \right] $$
其中$ P(S'' = 0) $可以写为:
$$ P(S'' = 0) = \sum P(A_{rt})P(A_{rn}) $$
在计算出矩阵$ R(S' = 10|S'' = {0, 1,...,20}) $后,在进行加权平均,即可得到状态“1号租车点有10辆车”的奖励期望$ R(S' = 10) $
$$ R(S' = 10) = P(S'' = {0, 1,..., 20}) R^T(S' = 10|S'' = 0)$$
两个租车点,所有的状态按上述方法计算后,即可得出两个租车点的奖励矩阵$\begin{matrix} [R_1(S') & R_2(S')] \end{matrix}$。在计算出奖励矩阵后,这个问题就变成了bandit问题的变种,bandit问题是一个动作固定对应一个未来的状态,而这里虽然也是这样,不过所对应的状态却要以当前状态为基础进行计算得出,还是有些不同,所以称为bandit问题的一个变种。
基本算法——Policy-Evaluation & Policy-Improvement
这里所用到的主要解决方法为动态编程(DP)里的Policy-Evaluation和Policy-Improvement,我会先用Policy-Evaluation + Softmax求解一次,再用Policy-Evaluation + Policy-Improvement求解一次。这里先给出Policy-Evaluation + Softmax的算法流程:
- 计算奖励矩阵,初始化Q矩阵和V矩阵
- 进入迭代循环
- 将当前状态转变为1号与2号租车点的保有车辆数[#Car1 #Car2]
- 带入动作集合计算找出可能的未来状态S’与可执行的动作PossibleAction
- 用式子$ Q(S, \mathrm{Possible\ Action}) = R_1(S') + R_2(S') - 2\mathrm{Cost}(Possible\ Action) + \gamma V(S')$计算Q矩阵
- 用式子$ V(S) = \pi(S, A)Q^T(S) $更新V矩阵
- Softmax优化$ \pi(S, A) $: $$ \pi(S) = \frac{\exp{Q(S)}}{\sum \exp(Q(S, A))} $$
- 计算收敛程度,如果已收敛,退出循环;未收敛,继续迭代循环
Policy-Evaluation + Softmax的特点是将Softmax优化动作选择策略嵌入到迭代过程中去,这样好处是可以迅速的计算出较优的动作选择策略(在V值收敛之前),但不能保证是最优的。这中方法实际上叫Value-Iteration,是一种有策略的自更新policy的算法,大的框架还是policy-evaluation的,这一点并没有太大改变。
Policy-Improvement是将已有的动作选择策略$\pi(S, A)$和V矩阵带入与最优值进行比较,从而将$\pi(S, A)$跟新为最优。下面我们来看Policy-Improvement的算法流程,再将其与Policy-Evaluation结合起来:
- 初始化Q矩阵,将计算好的V矩阵与策略$ \pi(S, A) $带入状态循环中(每一个状态计算一遍)
- 将当前状态转变为1号与2号租车点的保有车辆数[#Car1 #Car2]
- 带入动作集合计算找出可能的未来状态S’与可执行的动作PossibleAction
- 用式子$ Q(S, \mathrm{Possible\ Action}) = R_1(S') + R_2(S') - 2\mathrm{Cost}(Possible\ Action) + \gamma V(S')$计算Q矩阵
- 用策略$\pi(S, A)$与$ Q_{max} $所在的动作进行比较,若是不符则令一个flag:Policy_Stable = False
Policy-Evaluation + Policy-Improvement算法:
- 计算奖励矩阵,初始化Q矩阵与V矩阵
- 判断Policy_Stable是否为False,如为True则输出结果$\pi(S,A)$,如为False则进入迭代循环过程。
- 令Policy_Stable = True
- 执行Policy-Evaluation算法
- 执行Policy-Improvement算法,得到Policy_Stable的结果,返回第2步
结果与评价
下面这幅图表示出了Policy-Improvement策略进化的过程,直到第5次迭代,动作策略最终稳定为最优策略。在这幅图中,横轴表示2号租车点的车辆保有量,纵轴表示1号租车点的车辆保有量,图上的颜色由蓝到绿到黄表示了车辆调配的策略,正负号分别表示从1号调出车辆到2号,从2号调出车辆到1号。
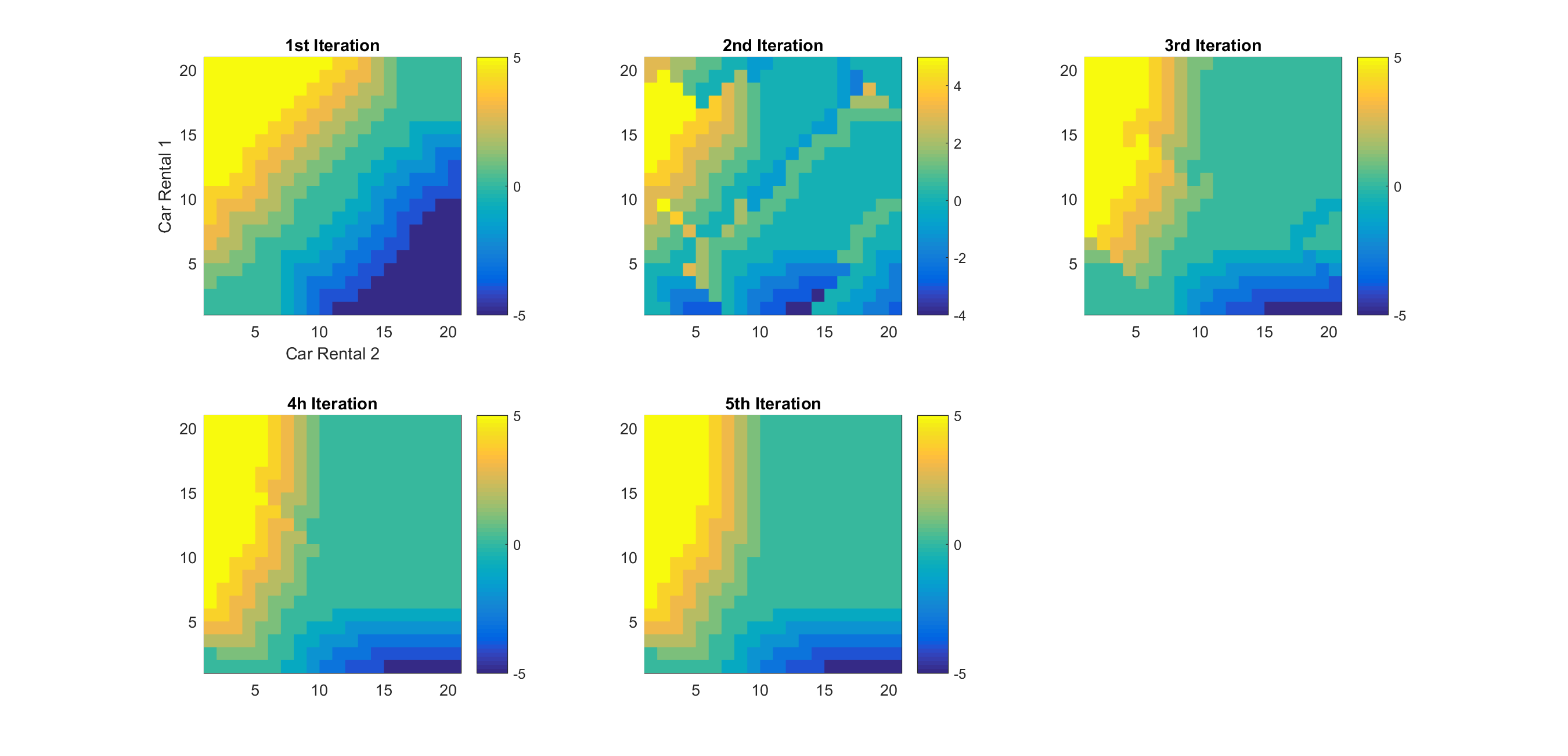
从第1次迭代的策略到第5次迭代的策略分别去测试Jack平均每日的实际收益,测试以10000日为基准(我并不是很清楚这里的第三次迭代的结果为何比第四次还要好,但最终的稳定后的策略是最优的):
| 迭代次数 | 实际每日收益 |
| 0(无策略) | $38 |
| 1 | $42.5 |
| 2 | $43.7 |
| 3 | $44.9 |
| 4 | $44.3 |
| 5 | $45.2 |

 浙公网安备 33010602011771号
浙公网安备 33010602011771号