Python-Jsonpath
python解析json时使用jsonpath包
| Xpath | JSONPath | 描述 |
|---|---|---|
| / | $ | 跟节点 |
| . | @ | 现行节点 |
| / | . or [] | 取子节点 |
| .. | n/a | 就是不管位置,选择所有符合条件的条件 |
| * | * | 匹配所有元素节点 |
| [] | [] | 迭代器标示(可以在里面做简单的迭代操作,如数组下标,根据内容选值等) |
| | | [,] | 支持迭代器中做多选 |
| [] | ?() | 支持过滤操作 |
| n/a | () | 支持表达式计算 |
| () | n/a | 分组,JsonPath不支持 |
导入包
pip install jsonpath
使用json例子
shop={ "store": { "book": [ { "category": "reference", "author": "Nigel Rees", "title": "Sayings of the Century", "price": 8.95 }, { "category": "fiction", "author": "Evelyn Waugh", "title": "Sword of Honour", "price": 12.99 }, { "category": "fiction", "author": "Herman Melville", "title": "Moby Dick", "isbn": "0-553-21311-3", "price": 8.99 }, { "category": "fiction", "author": "J. R. R. Tolkien", "title": "The Lord of the Rings", "isbn": "0-395-19395-8", "price": 22.99 } ], "bicycle": { "color": "red", "price": 19.95 } }, "expensive": 10 }
loads方法是把json字符串转化为python对象,dumps方法是把pyhon对象转化为json字符串
如果是从文件中读入的字符串则要先转为python对象使用loads方法,
import json import jsonpath as jp f='' for line in open('D:\VSpython\json\j1.txt', 'r'): #打开文件 rs = line.rstrip('\n') # 移除行尾换行符 f=f+rs str=json.loads(f)
现在对str使用jsonpath()方法解析数据,方法2个参数:一个是被解析的对象shop,一个是解析的路径re
re='$..book[0].*' rst=jp.jsonpath(shop,re)
json结构表示:K:V
re解读:
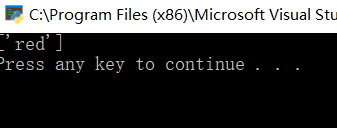
re='$.store.bicycle.color'
表示根下 store :V里面的bicyce bicyce:V的color
re='$..book'
表示根以下的K=book的键值对,返回来book的V即book:后面所有的字符,注意还包含[]数组的符号

re='$..book.*'
返回了book数组的所有的值,注意这次少了[]

re='$..book[0]'
因为book的V是个数组,所以book[0]表示该数组的一个值。

re='$..book[0].*'
表示数组第一个值里的所有V

re='$..book[0].price'
数组第一个值的price的V即

综上:jsonpath()函数返回构建的re(构建的re为一个K)的V。
当没有匹配的值是返回false。
完整示例
import json import jsonpath as jp data1 = {'foo': [{'baz': 'news'}, {'baz': 'music'}]} shop={ "store": { "book": [ { "category": "reference", "author": "Nigel Rees", "title": "Sayings of the Century", "price": 8.95 }, { "category": "fiction", "author": "Evelyn Waugh", "title": "Sword of Honour", "price": 12.99 }, { "category": "fiction", "author": "Herman Melville", "title": "Moby Dick", "isbn": "0-553-21311-3", "price": 8.99 }, { "category": "fiction", "author": "J. R. R. Tolkien", "title": "The Lord of the Rings", "isbn": "0-395-19395-8", "price": 22.99 } ], "bicycle": { "color": "red", "price": 19.95 } }, "expensive": 10 } #ss=json.loads(shop) rows=len(shop["store"]["book"]) #用字典取 for i in range(0,rows): re='$..book['+str(i)+'].' rst=jp.jsonpath(shop,re) cc=rst[0] print(cc["title"]) #数组一个一个取得 #for i in range(0,rows): # re='$..book['+str(i)+'].*' # rst=jp.jsonpath(shop,re) # for j in range(0,len(rst)): # print(rst[j])
