表达式求导——BUAA_OO 第一单元总结
BUAA_OO 第一单元总结
一. 程序架构分析
1. 第一次作业
·需求摘要
本次作业,需要完成的任务为简单多项式导函数的求解。
·主要思路
step1: 预处理,去掉表达式中的空白字符
step2: 将相连的正负号替换成单个正负号
step3: 利用正则匹配将表达式拆分成多个项
step4: 求导,并将指数和系数分别做为HashMap的key和value
step5: 求导的同时遇到相同的指数进行系数化简,并将系数为0的项清除
step6: 输出
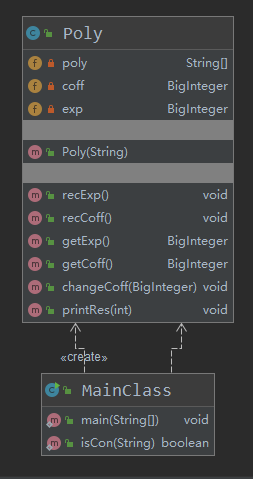
·UML类图
·Metrics

·结构分析
从Metrics图中看到有三个方法结构过于复杂、紧密程度较低,说明这次的作业面向过程的味道比较浓。类的建立也不是很合理,只建立了一个Poly类,化简部分就只能放在主函数中,导致主函数和Poly之间的耦合度较高,应该再建立一个表达式类,负责管理多个poly对象以及化简,这样可减少类之间的耦合度。
2. 第二次作业
·需求摘要
本次作业,需要完成的任务为包含简单幂函数和简单正余弦函数的导函数的求解。
·主要思路
step1: 预处理,去掉表达式中的空白字符
step2: 标准化处理,将相连的正负号替换成单个正负号、被省略的系数和指数都补充上、“ ** ”替换成" ^ "
step3: 利用正则匹配将表达式拆分成多个项
step4: 利用‘*’将项拆分成各个因子,判断每个因子的类型,并建立相应的类Item
step5: 根据各自的求导方法进行求导,将系数指数等信息存放在类Inf中
step6: 进行化简,化简规则包括同类项合并、sin(x)**2 + cos(x)**2 = 1 (包括其等价形式)等
step7: 输出
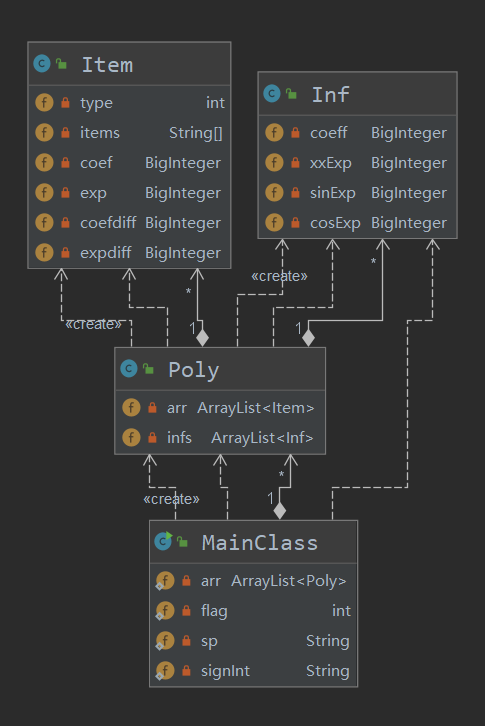
·UML类图
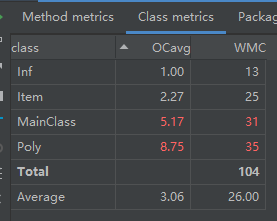
·Metrics
·结构分析
从Metrics图中我们可以看到结构复杂度、耦合程度都比较高,面向过程的味道依旧很浓;各个类的职责划分不清晰,化简等的过程应放在相应的表达式类或者项类之中,不应该继续放在主函数之中,变成了低内聚高耦合,这与我们高内聚低耦合的目标相悖;没有用到工厂模式,只是根据因子的不同类型来选择不同的求导方式,后果就是代码冗余、不好维护(在这次作业中合理的做法是根据不同的因子来分别创建相应的类,每个类有相应的求导方法,并且都继承自一个抽象类)。
3.第三次作业
·需求摘要
本次作业,需要完成的任务为包含简单幂函数和简单正余弦函数的导函数及其组合的求解。
·主要思路
step1: 判断表达式是否合法。将括号中因子或者是表达式替换成特殊符号(如@),判断替换后的表达式是否合法(此处需要改写正则表达式),并且递归判断被替换的表达式或者因子是否合法。如不合法直接进行相应的输出并退出程序
step2: 预处理,去掉多余的空白字符和正负号
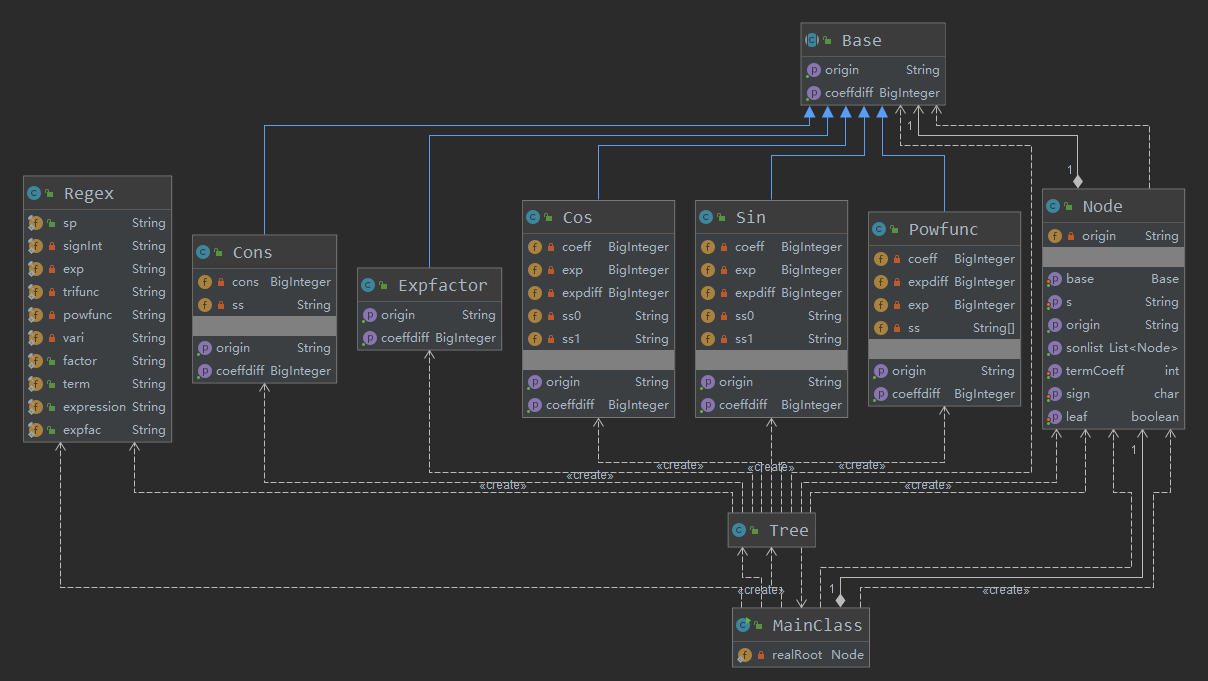
step3: 根据正则匹配将表达式递归拆分成各个项和因子,建立多叉树结构(如下图)
step4: 递归求导,进行简单的化简
step5: 输出

·UML类图
·Metrics
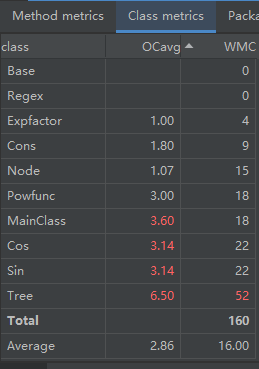
·结构分析
此次的类比较多,所以采用的继承的方式在一定程度上避免了代码冗余,三角函数类、常数类、幂函数类、表达式因子类都继承自Base抽象类;这次的Metrics数据飘红原因和前两次不同,前两次主要是各个类的职责不清导致耦合度过高,这次主要是递归建树、求导、输出过程复杂,且短时间内较难优化,但相较于前两次作业这次的OO味道浓了一些;此次作业为了强调正确性,没有进行大范围的优化,只是在项内进行简单的化简。
二. Bug分析
在三次的强测中,第二未次能全部通过所有测试点,出现bug的原因是在化简过程条件判断错误,导致输出结果错误,
在强测和互测中均被hack。
在第一次和第三次的强测中群全部通过所有测试点,但是在互测阶段均被hack,第一次作业出现了在输入“0*x**0”(我最初以为这个数据不合法)时无输出的bug,第三次作业出现了当项的系数为-1时,-1和后面的括号相对位置错误的bug。
三. 寻找bug策略
·构建数据集
构建数据集主要有两种方式:
·通过程序自动生成大量数据集,强调广泛性
·自己手动构建数据集,具有一定的针对性(由程序自动生成的概率较小)
·阅读代码
·阅读自己的代码,形式化验证有无bug,此过程可以发现大部分的bug
·阅读他人的代码,主要针对易错点,包括输出部分是否合法、数据是否溢出等,但随着代码行数的增加,
这种方法的可行性会越来越差
·自动评测
为了达到程序的正确性,在第三次作业中我自己写了一个“似评测机”,由于时间较为紧张且技术不成熟导致“似评测机”本身就具有较大的问题,第三次作业中的bug并没有被检测出来,所以在下个作业发布之前要完成对评测机的构建,“功在当代,利在千秋”。
在三次的互测中,通过以上的方法均发现了其他人的bug,包括常函数求导错误、输出格式错误、符号错误等
四. 设计模式
第一单元的设计模式主要是工厂模式
第一次作业较为简单(就一个幂函数类),没必要运用工厂模式
第二次作业有了工厂模式的雏形,主要是根据类型使用不同的求导方法,没有使用继承等思想
第三次作业中运用了工厂模式,建立了抽象类Base,Sin、Cos、Cons、Expfactor、Powfunc五个类都继承Base,
结合多叉树构建工厂
五. 反思和总结
·关于测试
·在这三次作业中均出现了bug,值得深思。测试的完整性、数据的特殊性、指导书的理解透彻性都必须进一步提升
·进一步完善评测机,毕竟“工欲善其事必先利其器”
·关于总体设计
·工厂模式的应用可有效提升代码的可维护性、降低代码的冗余性
·构建类时要梳理清各个类的相关关系,如果两个类的区分度不是很大,要么规划成一个类,要么采用继承的模式,做到面向对象
·“自己的事情自己做”,类内部的方法只处理自己的数据和得到的数据,不处理其他类内部数据,
尽量降低类之间的联系,做到高内聚低耦合
·关于可扩展性
·正确并熟练运用继承、接口等OO思想
·关注Metrics分析,可扩展性不强的代码就在于Metrics中标红的部分,及时关注,及时修改

