第2次作业
作业地址:【https://edu.cnblogs.com/campus/nenu/2016CS/homework/2139】
一、效能分析
要求0:项目地址 https://git.coding.net/Jingr98/wfAnalysis.git
要求1:
1.以war_and_peace.txt作为测试文件,原程序连续三次运行的消耗时间如下:
(1)第一次:150.474s
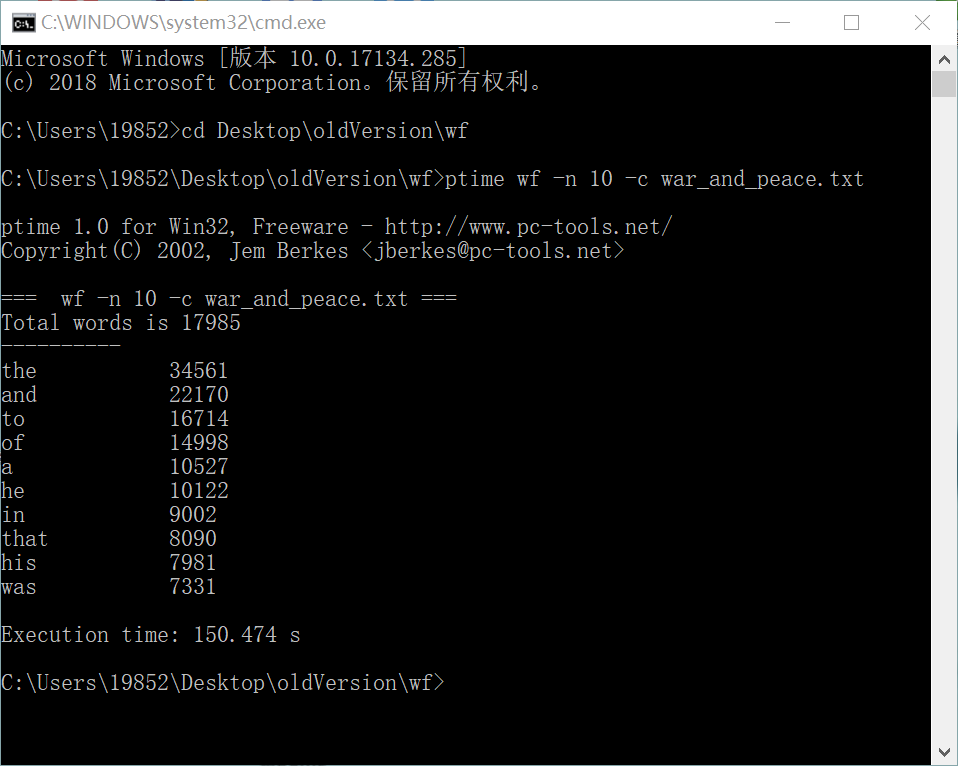
(2)第二次:151.516s
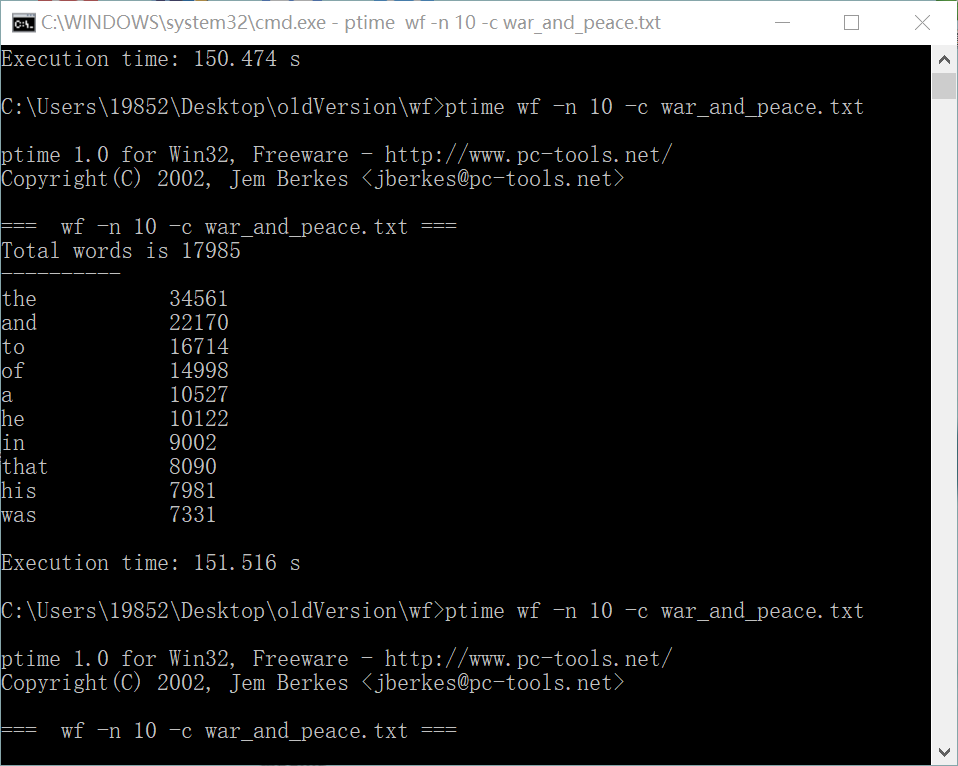
(3)第三次:164.399s
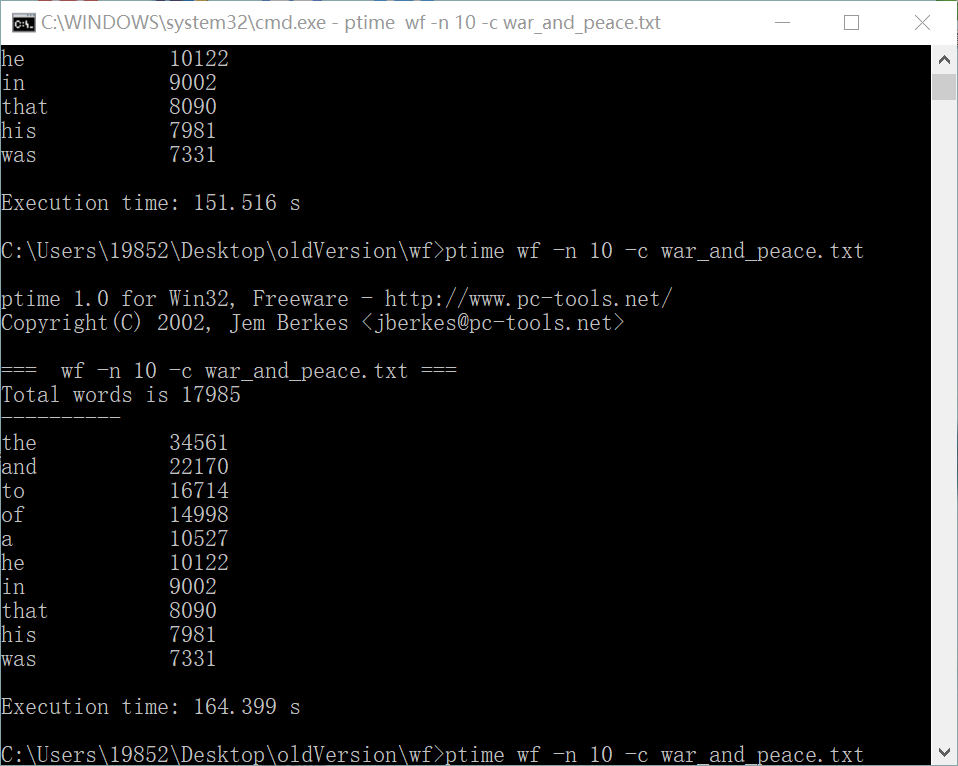
2.猜测程序瓶颈:
(1)bufferedReader.readLine()从文本文件中按行读取字符串,并依次存入字符串words中。
while((lineword=bufferedReader.readLine())!=null) {
words+=lineword+"\n";
}
猜测原因:使用BufferedReader缓存流,readLine方法读取一行文本。因为文本文件很大,程序按行读取到所有内容所耗费的时间应该较多,所以此处应该为程序的一个瓶颈。如果优化后的程序可以减少读取文件的次数,即换一种读文件的方式,那么程序运行耗时应该会减少。
(2)分割字符串words并存入数组中。
String[] word = str.split("[^a-zA-Z0-9]|\\s");
猜测原因:分割字符串并得到一个个的单词,感觉程序在这里的工作肯定不少,相对耗时也较长。但是优化后的程序在这里应该不会有什么改进,因为这是程序处理字符串必不可少的工作,没办法简化了...
(3)for语句依次处理单词数组word[ ]中的每一个元素(先调用isLegal(word[i])判断单词是否合法,若合法再判断word[i]是否已是myMap的键)。
Map<String,Integer> myMap = new TreeMap<String,Integer>();
//遍历数组将其存入Map<String,Integer>中
int wordLen = word.length;
for(int i=0;i<wordLen;i++) {
//首先判断是否为合法单词
if(isLegal(word[i])) {
if(myMap.containsKey(word[i])) {
num = myMap.get(word[i]);
myMap.put(word[i], num+1);
}
else {
myMap.put(word[i], 1);
}
}
}
猜测原因:单词很多,所以各种判断语句执行的次数也很多。并且每次执行的不是简单的判断语句,要么是调用自己定义的函数isLegal(),要么就是调用map对象下的方法containsKey(),这些应该是很耗时的。如果优化后的程序可以较少函数的调用次数或者减少判断语句的执行,应该会提高性能。
要求2:
利用Java VisualVM工具对程序进行效能分析如下:
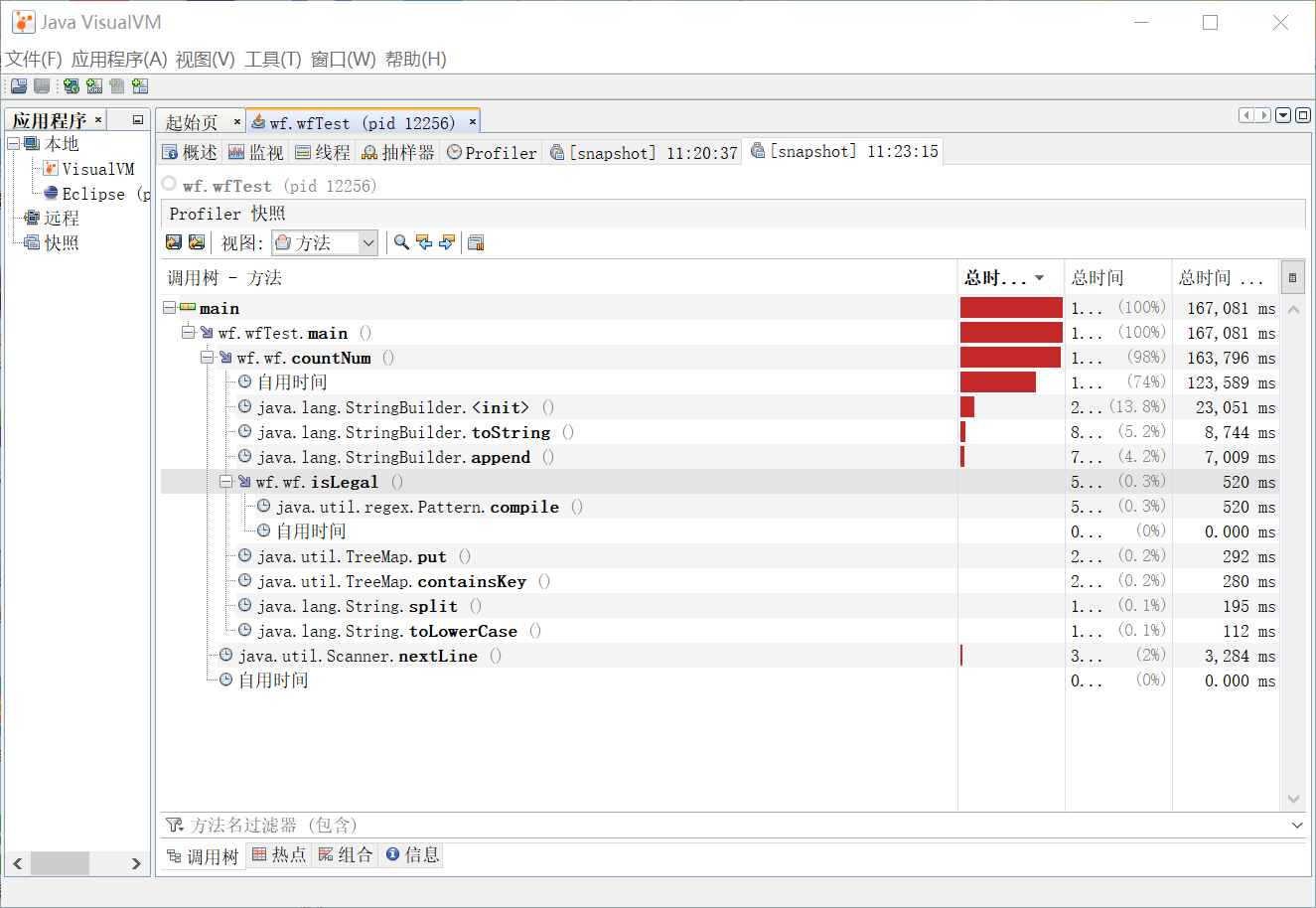
对profile的结果进行分析找出了程序运行中最花费时间的3个函数(或代码片段),如下:
1.耗时最长的部分是调用java.lang.StringBuilder

源于以下代码片段:
while((lineword=bufferedReader.readLine())!=null) {
words+=lineword+"\n";
}
(1)瓶颈分析:使用“+”号进行字符串拼接的效率非常低。我用了一个简单的小例子如下,来查看编译器是怎么处理 + 操作符的。
String str0 = "a";
String str1 = str0 + "b";
下面是该程序片段编译后的字节码指令:
public static void main(java.lang.String[]);
Code:
0: ldc #2 // String a
2: astore_1
3: new #3 // class java/lang/StringBuilder
6: dup
7: invokespecial #4 // Method java/lang/StringBuilder."<init>":()V
10: aload_1
11: invokevirtual #5 // Method java/lang/StringBuilder.append:(Ljava/lang/String;)Ljava/lang/StringBuilder;
14: ldc #6 // String b
16: invokevirtual #5 // Method java/lang/StringBuilder.append:(Ljava/lang/String;)Ljava/lang/StringBuilder;
19: invokevirtual #7 // Method java/lang/StringBuilder.toString:()Ljava/lang/String;
22: astore_2
23: return
}
通过分析这段字节码,发现“+”拼接操作实际上被编译器理解成了这个样子:
String str0 = "a";
StringBuilder sb = new StringBuilder();
sb.append(str0).append("b");
String str1 = sb.toString();
发现中间多出来了一个StringBuilder对象,即在编译的过程 "+" 被编译成了StringBuilder对象进行操作,并且拼接几次就会创建几个StringBuilder临时对象。很显然,在该while循环体中每读取一行文本“+”到字符串words后面时就会创建一个对象,使用“+”号读取完毕后创建了多个StringBuilder对象,执行完之后还要进行回收,无疑大大降低了效率。
(2)解决方法:可以在循环体外直接创建一个BufferedReader对象,然后在循环体中通过append方法拼接字符串,这样就省下了创建并回收很多个临时对象的消耗。(在需要拼接大量字符串时,还是使用StringBuilder/BufferedReader对象为好)
2.其次是isLegal()函数耗时较长

(1)瓶颈分析:处理word[ ]数组中每个元素时都调用自定义的isLegal()函数,并且每次调用时都会创建String、Pattern、Matcher变量。
(2)解决办法:将isLegal()函数并入到countNum()函数里,即减少调用关系树。在for语句之前创建一个String变量和一个Patten变量供数组中所有元素使用,在for语句内部每次调用p.matcher(word[i]).matches()判断元素是否为合法单词。
3.对TreeMap对象的操作耗时较长
![]()
(1)瓶颈分析:TreeMap内部是按照键值对有一定的顺序,在对其操作(插入或删除)时,因为需要维护内部的平衡,所以会牺牲一些效率。
(2)解决办法:将TreeMap对象换成HashMap对象,可以实现对Map的快速操作。因为Hash Map里键值对的排序是随机的,所以这样改的话虽可以提高效率,但却失去了其顺序性,还需自己排序。
要求3:
优化后的程序效能分析如下:
(每次profile的结果都有些不同,下图仅为第一次分析结果)
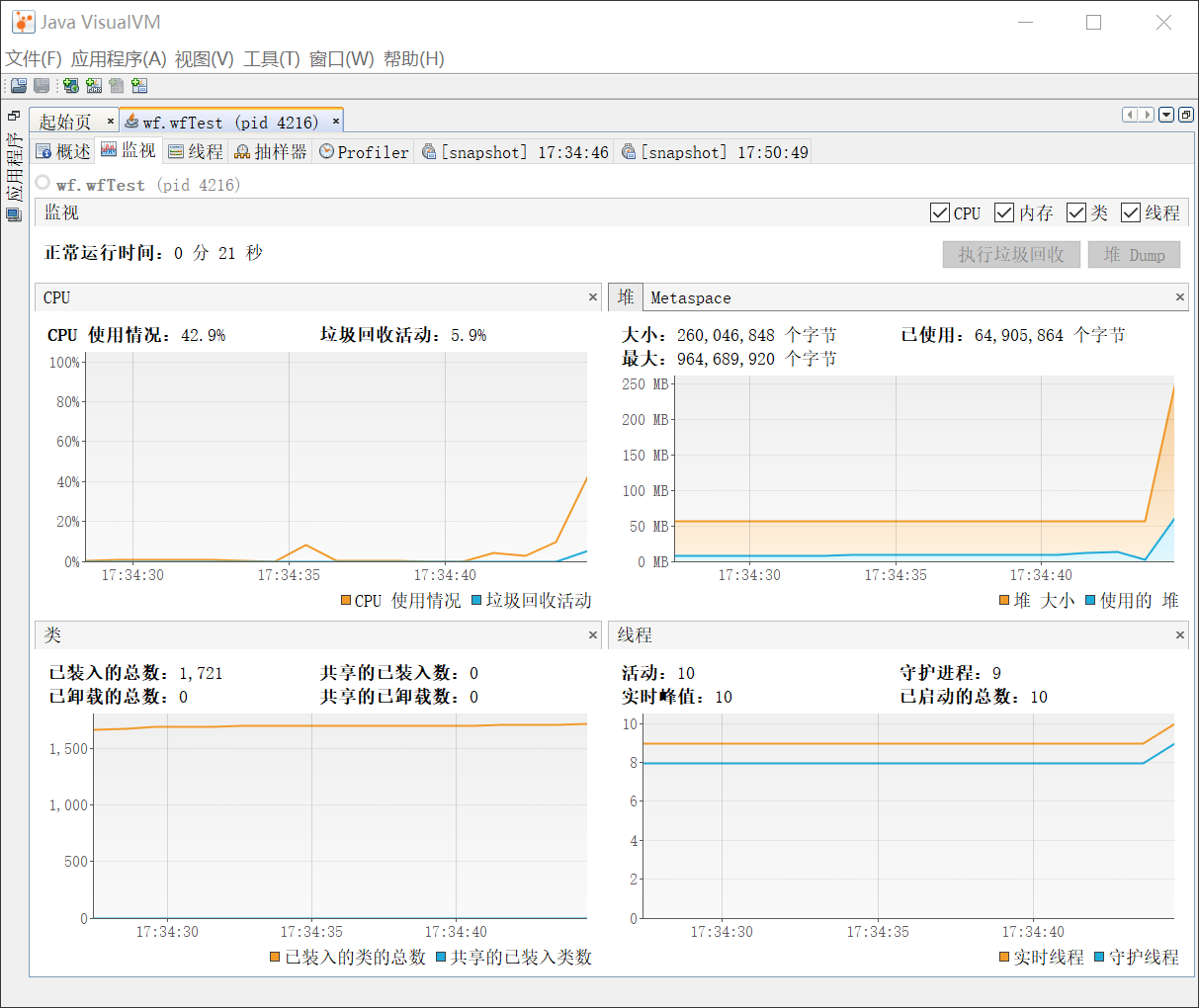
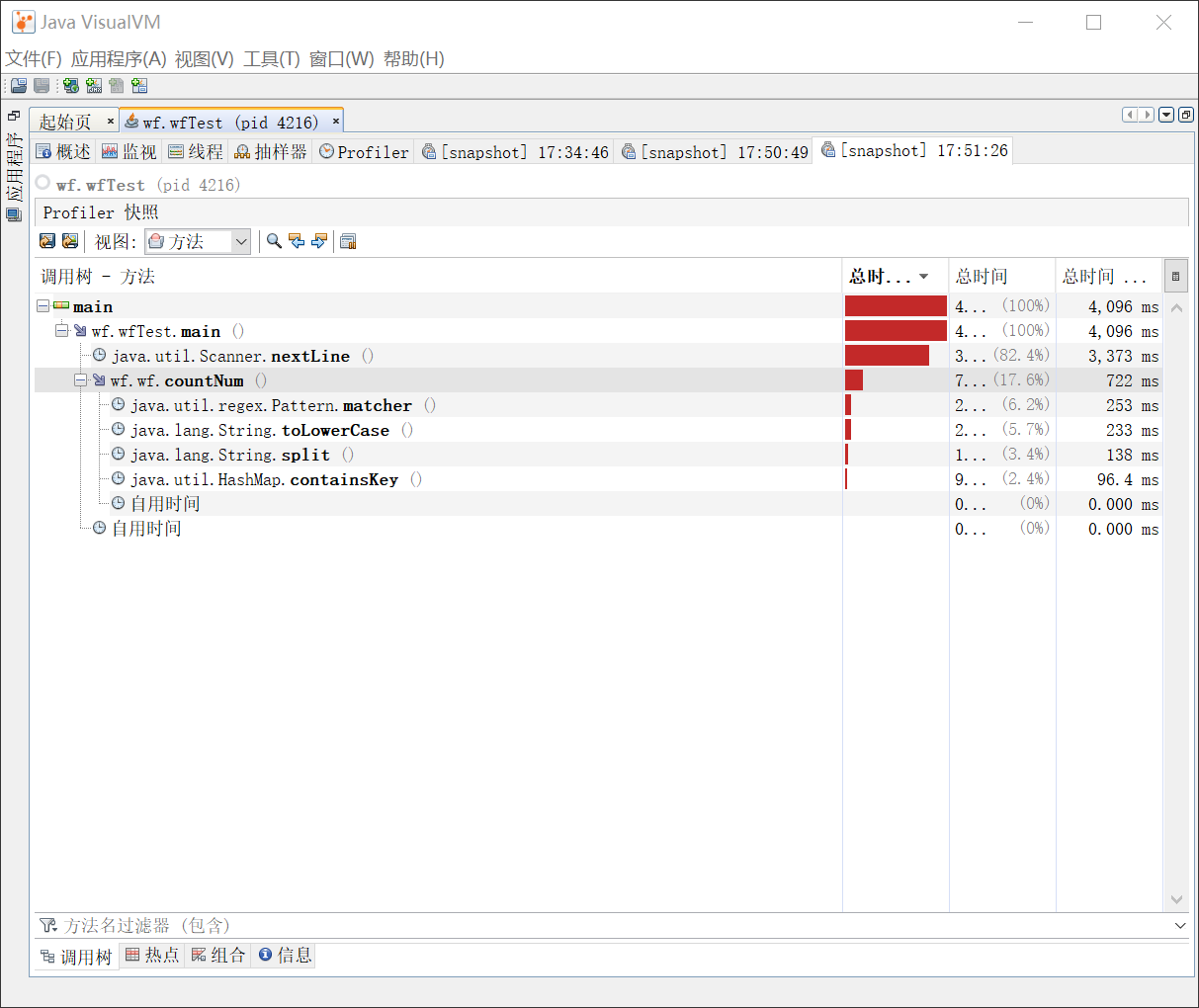
1.改进后的3个函数此时的耗时
(1)用StringBuffer拼接字符串
![]()
(2)去掉isLegal函数,在countNum函数内部添加等价代码如下
String regex="^[a-zA-Z][a-zA-Z0-9]*$";
Pattern p = Pattern.compile(regex);
for(int i=0;i<wordLen;i++) {
//首先判断是否为合法单词
if(p.matcher(word[i]).matches()) {
if(myMap.containsKey(word[i])) {
num = myMap.get(word[i]);
myMap.put(word[i], num+1);
}
else {
myMap.put(word[i], 1);
}
}
}
耗时如下:
![]()
(3)换用HashMap耗时如下:
![]()
2.程序优化后连续三次运行的消耗时间如下:
(1)第一次:1.553s
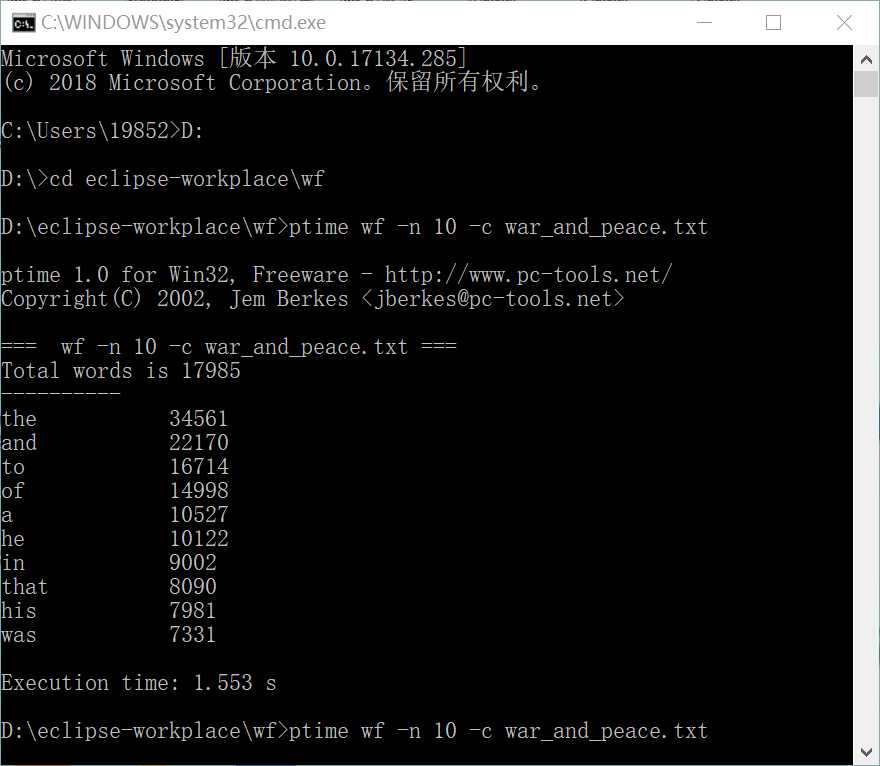
(2)第二次:1.162s
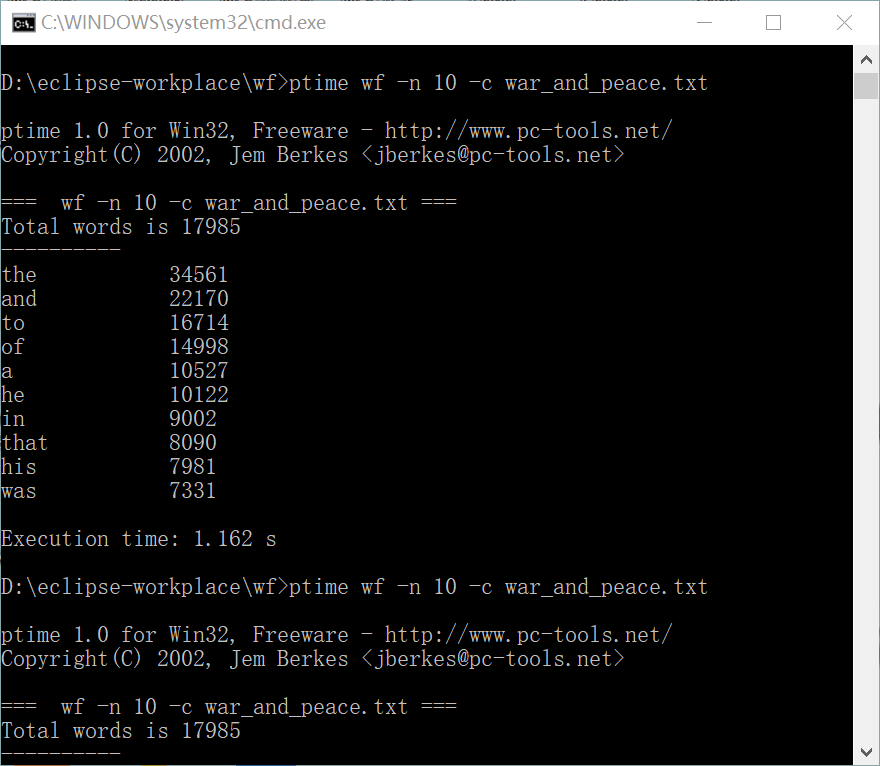
(3)第三次:1.174s

二、自我评估
作为一名计算机科学与技术专业的大三学生,目前为止,我学过计算机导论、计算机组成原理、操作系统、编译原理等计算机专业的基础课程,虽说不上自己对所学知识掌握的多好,但也算是有个大概的了解,有一定的理论知识基础。同时,我也上完了多种编程语言课程,例如C语言/C++、Java、Python、php、html等。虽然在课堂上已经接触到了这么多的编程语言,但是我感觉自己学的都很肤浅,语法掌握的不牢、只能参考别人的代码编一些小程序,有时候都不好意思说自己学过。在实战编程方面,唯一觉得自己做的不错的地方就是用HTML+CSS+Javascript写web前端了。因为在大一暑假加入了学校的卓音工作室,所以有机会可以参与学校相关网站的开发与维护工作。在这个过程中,我收获了很多,一是提升了自己的学习能力,因为前端技术更新迭代很快,可能这个项目中用node.js,下一个项目中就换成了vue.js,所以需要我去不断学习;二是具备了团队协作能力,任何项目的完成都离不开团队协作,每一次的协作经验都会指导我下次如何改进;三是拥有了良好的自我管理能力,因为要平衡好学习任务和项目任务,所以自己要提高做事效率,自我激励、开心过好每一天!
离成为一个合格的 IT专业毕业生,真的还差好多。首先我需要掌握一种编程语言(C语言或者Java),可以熟练编写程序解决问题;其次我需要锻炼自己的逻辑思维能力,因为IT行业很多是工程思想,需要从业者具有较高的逻辑思维能力,尤其是研发人员,自己在这方面是很欠缺的;然后如果自己以后想要成为一名前端工程师,不仅需要去了解前端工程化、后台技术方面、网络技术等相关知识,还要掌握一门后端语言,这样才能更好的写好web前端代码,毕竟web网页最终还是要与后端语言进行结合形成一个真正的动态网站。

| Skills/技能 | 课前评估(0-9) | 课后评估(0-9) |
| Programming Overall/对编程整体的理解 | 3 | 5 |
| programming:Comprehension (程序理解)(如何理解已有的程序,通过阅读、分析、debug) |
3 | 6 |
| Programming:Implementation(模块实现,逐步细化) | 1 | 4 |
| Programming:Code Review/Code Quality(代码复审/规范/质量) | 3 | 5 |
| Programming:BigData(处理大数据) | 0 | 3 |
| Programming Language(C) | 3 | 6 |
| Ability to Learn:自主学习的能力 | 3 | 6 |

 浙公网安备 33010602011771号
浙公网安备 33010602011771号