Redis学习笔记
技术分析小组分配任务

学习视频地址
黑马这个视频对于新手入门确实讲得好,推荐大家看看。本文很多内容是直接粘贴的视频中的ppt内容,因为他已经总结得很好了。
文章目录
Redis简介
Nosql
not-Only-SQL: 泛指非关系型数据库
作用:高并发,海量用户和数据处理
常见Nosql数据库
- Redis
- memcache
- HBase
- MongeDB
Redis应用场景
- 高频
- 波段性
概念
Redis: Remote Dictionary Server ,用C语言开发的一一个开源的高性能键值对(key-value) 数据库。
特征
-
数据之间没有必然的联系
-
内部采用单线程机制
-
高性能
-
多数据类型支持
string,list,hash,set,sorted_set -
持久化支持。可以进行数据灾难性恢复
应用
-
为热点数据加速查询(主要场景),如热点商品、热点新闻、热点资讯、推广类等高访问量信息等
-
任务队列,如秒杀、抢购、购票排队等
-
即时信息查询,如各位排行榜、各类网站访问统计、公交到站信息、在线人数信息(聊天室、网站)、设备信号等
-
时效性信息控制,如验证码控制、投票控制等
-
分布式数据共享,如分布式集群架构中的 session 分离
-
消息队列
-
分布式锁
Redis 下载与安装


启动服务:

启动客户端

Redis的基本操作
信息添加
- 功能:设置 key,value 数据
- 命令:
set key value - eg:
set name jyt
信息查询
- 功能:根据 key 查询对应的 value,如果不存在,返回空(nil)
- 命令:
get key - eg:
get name
清屏
clear
退出客户端
- 命令:
quit
exit
<ESC>(有的不会)
帮助
- 功能:获取命令帮助文档,获取组中所有命令信息名称
- 命令
help 命令名称
help @组名
Redis数据类型
5种常用
- string
- hash
- list
- set
- sorted_set
redis 数据存储格式
数据类型指的是value
- redis 自身是一个 Map,其中所有的数据都是采用 key : value 的形式存储
- 数据类型指的是存储的数据的类型,也就是 value 部分的类型,key 部分永远都是字符串
![在这里插入图片描述]()

string
-
存储的数据:单个数据,最简单的数据存储类型,也是最常用的数据存储类型
-
存储数据的格式:一个存储空间保存一个数据
-
存储内容:通常使用字符串,如果字符串以整数的形式展示,可以作为数字操作使用
-
添加修改数据
set key value -
获取数据
get key
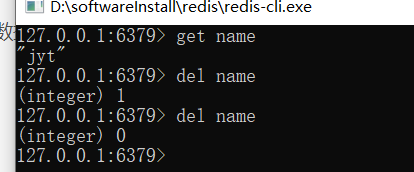
- 删除数据
del key
(integer) 1 : 操作成功
(integer) 0 :操作失败
- 添加/修改多个数据
mset key1 value1 key2 value2
eg: 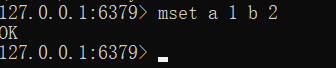
- 获取多个数据
mget kye1 key2...
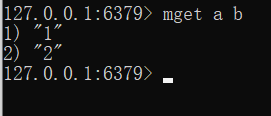
- 获取数据字符个数(字符串长度)
strlen key
- 追加信息到原始信息后部(如果原始信息存在就追加,否则新建),返回操作后的字符长度
append key value
string扩展操作
- 设置数值数据增加指定范围的值
incr key
incrby key increment
incrbyfloat key increment
- 设置数值数据减少指定范围的值
decr key
decrby key increment
- 设置数据具有指定的生命周期
setex key seconds value
psetex key milliseconds value
string 类型数据操作的注意事项
-
数据操作不成功的反馈与数据正常操作之间的差异
① 表示运行结果是否成功
(integer) 0 → false 失败
(integer) 1 → true 成功
② 表示运行结果值
(integer) 3 → 3 3个
(integer) 1 → 1 1个 -
数据未获取到
(nil)等同于null
-
数据最大存储量
512MB
-
数值计算最大范围(java中的long的最大值)
9223372036854775807
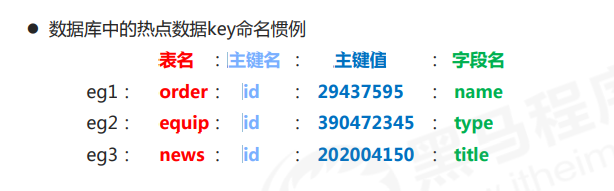
key的设置约定
- 数据库中的热点数据key命名惯例
hash类型
常见操作
- 添加/修改数据
hset key field value

- 获取数据
hget key field
hgetall key

- 删除数据
hdel key filed1
hdel key field1 field2

- 添加/修改多个数据
hmset key field1 value1 field2 value2
- 获取多个数据
hmget key field1 field2
- 获取哈希表中字段的数量
hlen key
- 获取哈希表中是否存在指定的字段
hexists key field
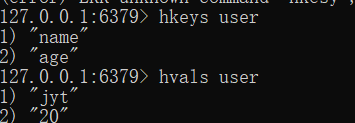
- 获取哈希表中所有的字段名或字段值
hkeys key
hvals key
- 设置指定字段的数值数据增加指定范围的值
hincrby key field increment
hincrbyfloat key field increment

hash类型应用场景
- 购物车
添加/修改不存在的值
hsetnx key field value
list
保存多个数据,底层使用双向链表存储结构实现
- 添加/修改数据
lpush key value1 [value2] ……
rpush key value1 [value2] ……
- 获取数据
lrange key start stop
lindex key index
llen key
- 获取并移除数据
lpop key
rpop key
- 规定时间内获取并移除数据
blpop key1 [key2] timeout
brpop key1 [key2] timeout
brpoplpush source destination timeout
- 移除指定数据
lrem key count value

应用场景
redis 应用于具有操作先后顺序的数据控制
set
hash的变形

- 添加数据
sadd key member1 [member2]
- 获取全部数据
smembers key
- 删除数据
srem key member1 [member2]
- 获取集合数据总量
scard key
- 判断集合中是否包含指定数据
sismember key member
- 随机获取集合中指定数量的数据
srandmember key [count]
- 随机获取集合中的某个数据并将该数据移出集合
spop key [count]
- 随机获取集合中指定数量的数据
srandmember key [count]
- 随机获取集合中的某个数据并将该数据移出集合
spop key [count]
set的扩展操作
- 求两个集合的交、并、差集
sinter key1 [key2]
sunion key1 [key2]
sdiff key1 [key2]
- 求两个集合的交、并、差集并存储到指定集合中
sinterstore destination key1 [key2]
sunionstore destination key1 [key2]
sdiffstore destination key1 [key2]
- 将指定数据从原始集合中移动到目标集合中
smove source destination member
数据操作的注意事项
- set 类型不允许数据重复,如果添加的数据在 set 中已经存在,将只保留一份
- set 虽然与hash的存储结构相同,但是无法启用hash中存储值的空间
sotred_set
简介
- 新的存储需求:数据排序有利于数据的有效展示,需要提供一种可以根据自身特征进行排序的方式
- 需要的存储结构:新的存储模型,可以保存可排序的数据
- sorted_set类型:在set的存储结构基础上添加可排序字段
![在这里插入图片描述]()

基本操作
- 添加数据
zadd key score1 member1 [score2 member2]
- 获取全部数据
zrange key start stop [WITHSCORES]
zrevrange key start stop [WITHSCORES]

- 删除数据
zrem key member [member ...]
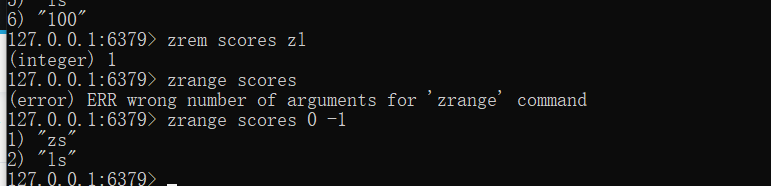
- 按照条件获取数据
zrangebyscore key min max [WITHSCORES] [LIMIT]
zrevrangebyscore key max min [WITHSCORES]

min与max用于限定搜索查询的条件
start与stop用于限定查询范围,作用于索引,表示开始和结束索引
offset与count(limit后面跟的)用于限定查询范围,作用于查询结果,表示开始位置和数据总量
- 条件删除数据
zremrangebyrank key start stop
zremrangebyscore key min max
- 获取集合数据总量
zcard key
- 集合交,并操作
zinterstore destination numkeys key [key ...]
zunionstore destination numkeys key [key ...]
扩展操作
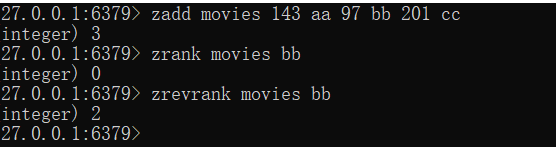
- 获取数据对应的排名
zrank key member
zrevrank key member
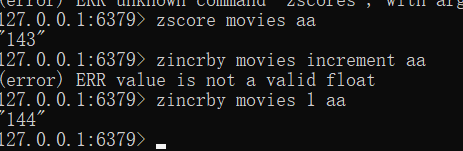
- score值获取与修改
zscore key member
zincrby key increment member
注意事项
- score保存的数据存储空间是64位,如果是整数范围是-9007199254740992~9007199254740992
- score保存的数据也可以是一个双精度的double值,基于双精度浮点数的特征,可能会丢失精度,使用时
候要慎重 - sorted_set 底层存储还是基于set结构的,因此数据不能重复,如果重复添加相同的数据,score值将被反复覆盖,保留最后一次修改的结果
redis 通用命令
key基本操作
- 删除操作
del key
- 获取key是否存在
exists key
- 获取key的类型
type key
key扩展操作(时效性控制)
- 为指定key设置有效期
expire key seconds
pexpire key milliseconds
expireat key timestamp
pexpireat key milliseconds-timestamp
- 获取key的有效时间
ttl key
pttl key
- 切换key从时效性转换为永久性
persist key
key扩展操作(查询模式)
keys * 查询所有
keys it* 查询所有以it开头
keys *heima 查询所有以heima结尾
keys ??heima 查询所有前面两个字符任意,后面以heima结尾
keys user:? 查询所有以user:开头,最后一个字符任意
keys u[st]er:1 查询所有以u开头,以er:1结尾,中间包含一个字母,s或t
key其他通用操作
- 为key改名
rename key newkey // 如果newkey已经存在那么会被覆盖
renamenx key newkey
- 对所有key排序
sort key//有值才能排
- 其他key通用操作
help @generic
数据库通用操作
- 切换数据库
select index//我们默认在0区
- 其它
quit
ping
echo message
- 数据移动
move key db//要在当前的库移动到其他库,相当于是剪切,如果另外一个库已经存在那么则移动失败
- 数据清楚
dbsize//看当前数据库有多少个key
flushdb//删除当前数据库数据
flushall//删除所有数据库数据
Jedis简介
-
java连接redis服务
jedis; SpringData Redis; Lettuce; -
其他许多语言也可以连接redis
客户端连接redis
打开idea,建立maven项目,导入maven依赖
<dependency>
<groupId>redis.clients</groupId>
<artifactId>jedis</artifactId>
<version>3.6.3</version>
</dependency>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.12</version>
<scope>test</scope>
</dependency>
- 连接redis
Jedis jedis = new Jedis("127.0.0.1", 6379);
- 操作redis(和redis里面一样)
jedis.set("name","jyt");
String name=jedis.get("name");
System.out.println(name);
- 关闭redis
jedis.close();
Jedis简易工具类开发
- JedisPoll: jedis提供的连接池技术
//poolConfig:连接池配置对象
//host:redis服务地址
//port:redis服务端口号
public JedisPool(GenericObjectPoolConfig poolConfig, String host, int port) {
this(poolConfig, host, port, 2000, (String)null, 0, (String)null);
}
封装连接参数
在resources下建立 redis.properties
redis.host = 127.0.0.1
redis.port = 6379
redis.maxTotal = 30
redis.maxIdle = 10
加载配置类信息
- 静态代码初始化资源
static {
ResourceBundle rb = ResourceBundle.getBundle("redis");
JedisPoolConfig jedisPoolConfig = new JedisPoolConfig();
//最大连接数
MaxTotal = Integer.parseInt(rb.getString("redis.maxTotal"));
jedisPoolConfig.setMaxTotal(MaxTotal);
//最大活动数
MaxIdle = Integer.parseInt(rb.getString("redis.maxIdle"));
jedisPoolConfig.setMaxIdle(MaxIdle);
host = rb.getString("redis.host");
port = Integer.parseInt(rb.getString("redis.port"));
jedisPool = new JedisPool(jedisPoolConfig,host,port);
}
获取连接
- 对外访问接口,提供jedis连接对象,连接从连接池获取
public static Jedis getJedis(){
return jedisPool.getResource();
}
可视化客户端
Redis Desktop Manager
Linux环境安装redis
基于Center OS7安装Redis
我是买了一个阿里云服务器,用的center OS
- 下载安装包
wget http://download.redis.io/releases/redis-?.?.?.tar.gz//?.?.?代表版本号
- 解压
tar –xvf 文件名.tar.gz
- 编译
make
- 安装
make install [destdir=/目录]
Redis 服务启动
- 默认配置启动
redis-server
redis-server –-port 6379
redis-server –-port 6380
- 指定配置文件启动
redis-server redis.conf
redis-server redis-6379.conf
redis-server redis-6380.conf ……
redis-server conf/redis-6379.conf
redis-server config/redis-6380.conf
Redis客户端连接
- 默认连接
redis-cli
- 连接指定服务器
redis-cli -h 127.0.0.1
redis-cli –port 6379
redis-cli -h 127.0.0.1 –port 6379
- linux查看进程
ps -ef|grep redis

- 进入文件夹
cd xx
- 进入文件
cat xx
Redis 服务端配置
- 基本配置
daemonize yes
以守护进程方式启动,使用本启动方式,redis将以服务的形式存在,日志将不再打印到命令窗口中
port 6***
设定当前服务启动端口号
dir “/自定义目录/redis/data“
设定当前服务文件保存位置,包含日志文件、持久化文件(后面详细讲解)等
logfile "6***.log“
设定日志文件名,便于查阅


Redis 持久化
持久化简介
-
什么是持久化?
利用永久性存储介质将数据进行保存,比如硬盘。在特定的时间将保存的数据进行恢复。 -
为什么要进行持久化?
防止数据意外丢失,比如软件崩溃,断电,确保数据安全性。 -
持久化保存什么?
-
RDB 数据快照,将当前数据状态进行保存,快照形式,存储数据结果,存储格式简单,关注点在数据
![在这里插入图片描述]()
-
AOF 过程(日志):将数据的操作过程进行保存,日志形式,存储操作过程,存储格式复杂,关注点在数据的操作过程
![在这里插入图片描述]()
-


RDB
谁?什么时间,干什么事情
命令执行
- 谁:redis操作者
- 什么时间:随时进行
- 干什么事情:保存数据
save 指令
- 命令
save
- 作用
手动执行一次保存操作,保存在data目录下的dum.rdb文件内


save指令相关配置
- dbfilename dump.rdb
说明:设置本地数据库文件名,默认值为 dump.rdb
经验:通常设置为dump-端口号.rdb - dir
说明:设置存储.rdb文件的路径
经验:通常设置成存储空间较大的目录中,目录名称data - rdbcompression yes
说明:设置存储至本地数据库时是否压缩数据,默认为 yes,采用 LZF 压缩
经验:通常默认为开启状态,如果设置为no,可以节省 CPU 运行时间,但会使存储的文件变大(巨大) - rdbchecksum yes
说明:设置是否进行RDB文件格式校验,该校验过程在写文件和读文件过程均进行
经验:通常默认为开启状态,如果设置为no,可以节约读写性过程约10%时间消耗,但是存储一定的数据损坏风险
save指令工作原理
- save指令的执行会阻塞当前Redis服务器,直到当前RDB过程完成为止,有可能会造成长时间阻塞,线上环境不建议使用。
bgsave指令
- 命令
bgsave - 作用
手动启动后台保存操作,但不是立即执行
bgsave 指令工作原理

- bgsave命令是针对save阻塞问题做的优化。Redis内部所有涉及到RDB操作都采用bgsave的方式,save命令可以放弃使用
bgsave 指令相关配置

save配置
- 配置
save second changes - 作用
满足限定时间范围内key的变化数量达到指定数量即进行持久化 - 参数
second:监控时间范围
changes:监控key的变化量 - 位置
在conf文件中进行配置 - 范例
save 900 1
save 300 10
save 60 10000
rdb 特殊启动形式
- 服务器运行过程中重启
debug reload
- 关闭服务器时指定保存数据
shutdown save//加了save就保存,不加就不保存
AOF
AOF概念
- AOF(append only file)持久化:以独立日志的方式记录每次写命令,重启时再重新执行AOF文件中命令达到恢复数据的目的。与RDB相比可以简单描述为改记录数据为记录数据产生的过程
- AOF的主要作用是解决了数据持久化的实时性,目前已经是Redis持久化的主流方式
AOF 写数据三种策略
-
always
每次写入操作均同步到AOF文件中,数据零误差,性能较低 -
everysec
每秒将缓冲区中的指令同步到AOF文件中,数据准确性较高,性能较高
在系统突然宕机的情况下丢失1秒内的数据,是默认配置 -
no
由操作系统控制每次同步到AOF文件的周期,整体过程不可控
AOF功能开启
- 配置
appendonly yes|no//是否开启AOF持久化功能,默认为不开启状态
- 配置
appendfsync always|everysec|no//AOF写数据策略
AOF相关配置
- 指定文件名
AOF持久化文件名,默认文件名未appendonly.aof,建议配置为appendonly-端口号.aof
appendfilename filename
- 指定文件保存路径
AOF持久化文件保存路径,与RDB持久化文件保持一致即可
dir
AOF自动重写方式
- 自动重写触发条件设置
auto-aof-rewrite-min-size size
auto-aof-rewrite-percentage percent
- 自动重写触发比对参数( 运行指令info Persistence获取具体信息 )
aof_current_size
aof_base_size
- 自动重写触发条件
![在这里插入图片描述]()

RDB与AOF区别

Redis 事务
-
什么是事务?
redis事务就是一个命令执行的队列,将一系列预定义命令包装成一个整体 (一个队列)。当执行时,一次性按照添加顺序依次执行,中间不会被打断或者干扰。
事务的基本操作
- 开启事务
multi
- 执行事务
exec//设定事务的结束位置,同时执行事务。与multi成对出现,成对使用
//加入事务的命令暂时进入到任务队列中,并没有立即执行,只有执行exec命令才开始执行
- 取消事务
discard
锁
- 对 key 添加监视锁,在执行exec前如果key发生了变化,终止事务执行
watch key1 [key2……]
- 取消对所有key的监视
unwatch
分布式锁改良
- 使用 expire 为锁key添加时间限定,到时不释放,放弃锁
expire lock-key second
pexpire lock-key milliseconds
删除策略
-
数据删除策略:
- 定时删除
- 惰性删除
- 定期删除
-
数据逐出策略
- 8种策略
数据删除策略
定时删除策略
- 创建一个定时器,当key设置有过期时间,且过期时间到达时,由定时器任务立即执行对键的删除操作
- 优点:节约内存,到时就删除,快速释放掉不必要的内存占用
- 缺点:CPU压力很大,无论CPU此时负载量多高,均占用CPU,会影响redis服务器响应时间和指令吞吐量
- 总结:用处理器性能换取存储空间(拿时间换空间)
惰性删除
- 数据到达过期时间,不做处理。等下次访问该数据时,如果未过期,返回数据,发现已过期,删除,返回不存在
- 优点:节约CPU性能,发现必须删除的时候才删除
- 缺点:内存压力很大,出现长期占用内存的数据
- 总结:用存储空间换取处理器性能 expireIfNeeded() (拿空间换时间)
定期删除
- 周期性轮询redis库中的时效性数据,采用随机抽取的策略,利用过期数据占比的方式控制删除频度
- 特点1:CPU性能占用设置有峰值,检测频度可自定义设置
- 特点2:内存压力不是很大,长期占用内存的冷数据会被持续清理
- 总结:周期性抽查存储空间(随机抽查,重点抽查)
逐出算法
- Redis使用内存存储数据,在执行每一个命令前,会调用freeMemoryIfNeeded()检测内存是否充足。如果内存不满足新加入数据的最低存储要求,redis要临时删除一些数据为当前指令清理存储空间。清理数据
的策略称为逐出算法
影响数据逐出的相关配置
- 最大可使用内存
maxmemory
- 每次选取待删除数据的个数
maxmemory-samples//选取数据时并不会全库扫描,导致严重的性能消耗,降低读写性能。因此采用随机获取数据的方式作为待检测删除数据
- 逐出策略
maxmemory-policy //达到最大内存后的,对被挑选出来的数据进行删除的策略
-
检查易失数据,可能会过期的数据集server.db[i].expires
- volatile-lru : :挑选最近最少使用的数据淘汰
- volatile-lfu:挑选最近使用次数最少的数据淘汰
- volatile-ttl:挑选将要过期的数据淘汰
- volatile-random:任意选择数据淘汰
//
-
检测全库数据(所有数据集server.db[i].dict )
- allkeys-lru:挑选最近最少使用的数据淘汰
- allkeys-lfu:挑选最近使用次数最少的数据淘汰
- allkeys-random:任意选择数据淘汰
//
-
放弃数据驱逐
- no-enviction(驱逐):禁止驱逐数据(redis4.0中默认策略),会引发错误OOM(Out Of Memory)
服务器基础配置
服务器端设定
- 设置服务器以守护进程的方式运行
daemonize yes|no
- 绑定主机地址
bind 127.0.0.1
- 设置服务器端口号
port 6379
- 设置数据库数量
databases 16
高级数据类型
bitmaps
- 获取指定key对应偏移量上的bit值
getbit key offset
- 设置指定key对应偏移量上的bit值,value只能是1或0
setbit key offset value
HperLogLog
统计去重后的元素
GEO
主从复制
主从简介

-
主从复制就是将master中的数据即时、有效的复制到slave中
-
特征:一个master可以拥有多个slave,一个slave只对应一个master
-
职责:
master: 写数据,讲出现变化的数据自动同步到slave,读数据
slave: 读数据
主从复制作用
- 读写分离:master写、slave读,提高服务器的读写负载能力
- 负载均衡:基于主从结构,配合读写分离,由slave分担master负载,并根据需求的变化,改变slave的数量,通过多个从节点分担数据读取负载,大大提高Redis服务器并发量与数据吞吐量。
- 故障恢复:当master出现问题时,由slave提供服务,实现快速的故障恢复
- 数据冗余:实现数据热备份,是持久化之外的一种数据冗余方式
- 高可用基石:基于主从复制,构建哨兵模式与集群,实现Redis的高可用方案
建立连接阶段
数据同步阶段
命令传播阶段
常见问题
哨兵
哨兵也是一台redsi服务器,只是不提供数据服务。通常哨兵配置数量为单数
集群
sed "s/6380/6381/g" redis-6380.conf > redis-6381.conf
./redis-cli --cluster create 120.27.248.196:6380 120.27.248.196:6381 120.27.248.196:6382 120.27.248.196:6383 120.27.248.196:6384 120.27.248.196:6385 --cluster-replicas 1 -a abc123456abc
企业级解决方案
缓存预热
问题出现
服务器启动后迅速宕机
原因
- 请求数量较高
- 主从之间数据吞吐量较大,数据同步操作频度较高
总结
缓存预热就是系统启动前,提前将相关的缓存数据直接加载到缓存系统。避免在用户请求的时候,先查询数据库,然后再将数据缓
存的问题!用户直接查询事先被预热的缓存数据!
缓存雪崩
总结
缓存雪崩就是瞬间过期数据量太大,导致对数据库服务器造成压力。如能够有效避免过期时间集中,可以有效解决雪崩现象的出现
(约40%),配合其他策略一起使用,并监控服务器的运行数据,根据运行记录做快速调整。
缓存击穿
总结
缓存击穿就是单个高热数据过期的瞬间,数据访问量较大,未命中redis后,发起了大量对同一数据的数据库访问,导致对数据库服
务器造成压力。应对策略应该在业务数据分析与预防方面进行,配合运行监控测试与即时调整策略,毕竟单个key的过期监控难度
较高,配合雪崩处理策略即可。
缓存穿透
总结
缓存击穿访问了不存在的数据,跳过了合法数据的redis数据缓存阶段,每次访问数据库,导致对数据库服务器造成压力。通常此类数据的出现量是一个较低的值,当出现此类情况以毒攻毒,并及时报警。应对策略应该在临时预案防范方面多做文章。无论是黑名单还是白名单,都是对整体系统的压力,警报解除后尽快移除。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号