
WordCount程序
Java版本
原文件:
package com.jim; import org.apache.hadoop.fs.Path; import org.apache.hadoop.io.IntWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; import org.apache.hadoop.mapreduce.Job; /* * MapReduce jobs are typically implemented by using a driver class. * The purpose of a driver class is to set up the configuration for the * MapReduce job and to run the job. * Typical requirements for a driver class include configuring the input * and output data formats, configuring the map and reduce classes, * and specifying intermediate data formats. * * The following is the code for the driver class: */ /** * Licensed to the Apache Software Foundation (ASF) under one * or more contributor license agreements. See the NOTICE file * distributed with this work for additional information * regarding copyright ownership. The ASF licenses this file * to you under the Apache License, Version 2.0 (the * "License"); you may not use this file except in compliance * with the License. You may obtain a copy of the License at * * http://www.apache.org/licenses/LICENSE-2.0 * * Unless required by applicable law or agreed to in writing, software * distributed under the License is distributed on an "AS IS" BASIS, * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. * See the License for the specific language governing permissions and * limitations under the License. */ import java.io.IOException; import java.util.StringTokenizer; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.Path; import org.apache.hadoop.io.IntWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Job; import org.apache.hadoop.mapreduce.Mapper; import org.apache.hadoop.mapreduce.Reducer; import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; import org.apache.hadoop.util.GenericOptionsParser; public class WordCount { public static class TokenizerMapper extends Mapper<Object, Text, Text, IntWritable>{ private final static IntWritable one = new IntWritable(1); private Text word = new Text(); public void map(Object key, Text value, Context context ) throws IOException, InterruptedException { StringTokenizer itr = new StringTokenizer(value.toString()); while (itr.hasMoreTokens()) { word.set(itr.nextToken()); context.write(word, one); } } } public static class IntSumReducer extends Reducer<Text,IntWritable,Text,IntWritable> { private IntWritable result = new IntWritable(); public void reduce(Text key, Iterable<IntWritable> values, Context context ) throws IOException, InterruptedException { int sum = 0; for (IntWritable val : values) { sum += val.get(); } result.set(sum); context.write(key, result); } } public static void main(String[] args) throws Exception { Configuration conf = new Configuration(); String[] otherArgs = new GenericOptionsParser(conf, args).getRemainingArgs(); System.out.println(otherArgs.length); if (otherArgs.length != 2) { System.err.println("Usage: wordcount <in> <out>"); System.out.println("input output"); System.exit(2); } Job job = new Job(conf, "word count"); job.setJarByClass(WordCount.class); job.setMapperClass(TokenizerMapper.class); job.setCombinerClass(IntSumReducer.class); job.setReducerClass(IntSumReducer.class); job.setOutputKeyClass(Text.class); job.setOutputValueClass(IntWritable.class); FileInputFormat.addInputPath(job, new Path(otherArgs[0])); FileOutputFormat.setOutputPath(job, new Path(otherArgs[1])); System.exit(job.waitForCompletion(true) ? 0 : 1); } }
执行程序:
hadoop jar WordCount.jar /input /output/blog
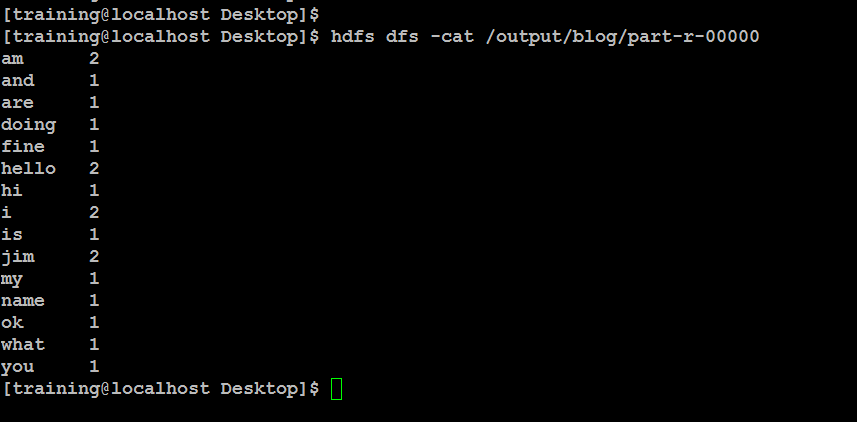
查看结果:
hdfs dfs -cat /output/blog/part-r-00000
最终结果如图:
整体shell脚本:
#!/bin/bash hdfs dfs -rm -r /output/blog hdfs dfs -rm -r /input/* hdfs dfs -put blog.csv /input hadoop jar WordCount.jar /input /output/blog hdfs dfs -ls /output/blog/part-r-00000 hdfs dfs -get /output/blog/part-r-00000 blog.result cat blog.result
Python版本
Mapper.py
#!/usr/bin/env python #coding=utf-8 import sys import os #标准输入 def readfile(): #f = open(filename) lines = sys.stdin #print type(lines) for line in lines: #line = line.strip() #print line words = line.split(",") #print type(words) for word in words: print word,",",1 readfile()
Reduce.py
#!/usr/bin/env python #coding=utf-8 import sys import os from operator import itemgetter def reduce1(): current_word = None current_count = 0 word = None lines = sys.stdin print current_word for line in lines: line = line.strip() #print line try: word,count = line.split(',',1) except: continue # print "word:%s count:%s"%(word,count) try: count = int(count) except: continue if current_word == word: current_count += count # print "current_word:%s" % (current_word) else: if current_word: #print "current_word不为空" #pass print '%s\t%s' % (current_word, current_count) current_count = count current_word = word if current_word == word: print '%s\t%s' % (current_word, current_count) reduce1()
执行程序:
#!/bin/bash alias dt='date +%Y%m%d" "%H:%M:%S' shopt -s expand_aliases function init() { hdfs dfs -rmr /input/* hdfs dfs -put ./blogdata/blog_20170414.csv /input/ hdfs dfs -ls /input/ hdfs dfs -rmr /output/emp } function mapreduce() { hadoop jar /usr/lib/hadoop-mapreduce/hadoop-streaming-2.0.0-cdh4.1.1.jar -mapper "python mapper.py" -reducer "python reducer.py" -input /input/* -output /output/emp -file "/etl/etldata/script/python/mapper.py" -file "/etl/etldata/script/python/reducer.py" -jobconf mapred.map.tasks=10 -jobconf mapred.reduce.tasks=10 } echo "`dt`:1.start init..." > ./wordcount.log init echo "`dt`:2.end init.." >> ./wordcount.log echo "`dt`:3.start MapReduce......" >> ./wordcount.log mapreduce echo "`dt`:4.end MapReduce....." >> ./wordcount.log
Java操作HDFS
创建目录:
package com.jim; import java.io.IOException; import java.net.URI; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.FileSystem; import org.apache.hadoop.fs.Path; public class Hdfs1 { /** * @param args * @throws IOException */ public static void main(String[] args) { // TODO Auto-generated method stub System.out.println("Start....."); //String uri = args[0]; String uri = "/input/jjm"; Configuration conf = new Configuration(); FileSystem fs = null; try { fs = FileSystem.get(URI.create(uri),conf); } catch (IOException e) { // TODO Auto-generated catch block e.printStackTrace(); } Path dfs = new Path(uri); try { fs.mkdirs(dfs); } catch (IOException e) { // TODO Auto-generated catch block e.printStackTrace(); } System.out.println("OK"); } }
上传文件、创建和删除目录
package com.jim; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.FileSystem; import java.io.BufferedInputStream; import java.io.IOException; import java.io.InputStream; import java.net.URI; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.FileSystem; import org.apache.hadoop.fs.Path; import java.io.BufferedInputStream; import java.io.FileInputStream; import java.io.FileNotFoundException; import java.io.InputStream; import java.io.OutputStream; import org.apache.hadoop.io.IOUtils; public class Hdfs { /** * @param args */ public static void main(String[] args) { // TODO Auto-generated method stub System.out.println("Start...."); dfs.mkdir("/input/jim"); dfs.deletedir("/input/jim/jack"); System.out.println("OK"); String srcfile="/etl/etldata/script/python/emp.csv"; String trgfile="/input/jim/jim.csv"; try { dfs.putfile(srcfile, trgfile); } catch (Exception e) { // TODO Auto-generated catch block e.printStackTrace(); } } public static class dfs { public static Configuration conf = new Configuration(); //create directory public static void mkdir(String string) { String uri=string; try { FileSystem fs =FileSystem.get(URI.create(uri),conf); Path dfs = new Path(uri); fs.mkdirs(dfs); } catch (IOException e) { // TODO Auto-generated catch block e.printStackTrace();} } //delete dir public static void deletedir(String string){ String uri=string; try { FileSystem fs =FileSystem.get(URI.create(uri),conf); Path dfs = new Path(uri); fs.delete(dfs, true); } catch (IOException e) { // TODO Auto-generated catch block e.printStackTrace(); } } // put file to hdfs public static void putfile(String srcfile ,String trgfile) throws Exception{ InputStream in = new BufferedInputStream(new FileInputStream(srcfile)); Configuration conf = new Configuration(); FileSystem fs = FileSystem.get(URI.create(trgfile),conf); OutputStream out = fs.create(new Path(trgfile)); IOUtils.copyBytes(in, out, 4096, true); } } }
Python提取文章关键字
#coding:utf-8 import sys sys.path.append('/home/shutong/crawl/tools') from tools import * import jieba import jieba.posseg #需要另外加载一个词性标注模块 from jieba import analyse # 引入TextRank关键词抽取接口 #设置utf-8模式 reload(sys) sys.setdefaultencoding( "utf-8" ) print getTime() textrank = analyse.textrank def get_key_words(line): words = '' keywords = textrank(line) # 输出抽取出的关键词 for keyword in keywords: #print keyword words = words + keyword + ',' return words # 原始文本 text = "经常有初学者在博客和QQ问我,自己想往大数据方向发展,该学哪些技术,学习路线是什么样的,觉得大数据很火,就业很好,薪资很高。如果自己很迷茫,为了这些原因想往大数据方向发展,也可以,那么我就想问一下,你的专业是什么,对于计算机/软件,你的兴趣是什么?是计算机专业,对操作系统、硬件、网络、服务器感兴趣?是软件专业,对软件开发、编程、写代码感兴趣?还是数学、统计学专业,对数据和数字特别感兴趣" #print get_key_words(text) #inputfilename = '/home/shutong/mapreduce/context.txt' #outputfile = '/home/shutong/mapreduce/mapcontext.txt' inputfilename = sys.argv[1] outputfile = sys.argv[2] keywords = '' for line in getLines(inputfilename): line = line.strip() keywords = keywords + get_key_words(line) #print keywords deleteFile(outputfile) saveFile(outputfile,',',keywords) #print "\nkeywords by textrank:" # 基于TextRank算法进行关键词抽取 #keywords = textrank(text) # 输出抽取出的关键词 #for keyword in keywords: # print keyword

 浙公网安备 33010602011771号
浙公网安备 33010602011771号