
Oracle基本函数即字段拆分
--创建用户 CREATE USER jim IDENTIFIED BY changeit; --给用户赋登陆连接权限 GRANT CONNECT TO jim; --给用户赋资源权限 GRANT RESOURCE TO jim; --回收登陆权限 REVOKE CONNECT FROM jim; --回收资源操作权限 REVOKE RESOURCE FROM jim; --锁定用户 ALTER USER jim ACCOUNT LOCK; --给用户解锁 ALTER USER jim ACCOUNT UNLOCK; --给用户修改密码 ALTER USER jim IDENTIFIED BY changeit; --创建时间维度表 CREATE TABLE DIM_DATE( Date_ID char(8) primary key , --20160704 Date_Name date, --2016/7/4 Year number, --2016 Year_Half char(6), --2016H2 Year_Month char(6), --201607 Year_Quarter char(6),-- 2016Q3 Half_Number number,--2 Half_Name char(2), --H2 Quarter_Number number,--3 Quarter_Name char(2),--Q3 Month_Number number,--7 Month_Name nvarchar2(20),--JUNL Week_Number number, --2 Week_Name nvarchar2(20),--Monday Creat_Date date, --创建时间 Update_Date date) --更新时间 ; --测试选出一段时间 select to_date('2014-01-01','YYYY-MM-DD')+(rownum-1) from dual connect by rownum<=(to_date('2015-01-01','YYYY-MM-DD')-to_date('2014-01-01','YYYY-MM-DD')); with temp_date as ( select to_date('2014-01-01','YYYY-MM-DD')+(rownum-1) from dual connect by rownum<=(to_date('2015-01-01','YYYY-MM-DD')-to_date('2014-01-01','YYYY-MM-DD')) ) select * from temp_date; --创建存储过程,导入时间 CREATE OR REPLACE PROCEDURE SP_ADD_DATE AS v_Half number; v_Quarter number; v_Month DIM_Date.Month_Name%type; v_Month_Number number; CURSOR c_date IS SELECT Date_ID,DIM_Date.Date_Name FROM DIM_DATE; c_row c_date%rowtype; BEGIN MERGE INTO DIM_DATE T1 USING( select to_date('2014-01-01','YYYY-MM-DD')+(rownum-1) date_name from dual connect by rownum<=(to_date('2018-01-01','YYYY-MM-DD')-to_date('2014-01-01','YYYY-MM-DD')) ) temp_Date on (t1.date_name=temp_Date.date_name) when matched then update set t1.date_id=to_char(temp_Date.date_name,'YYYYMMDD') when not matched then insert (Date_ID) values(to_char(temp_Date.date_name,'YYYYMMDD')); --循环游标 FOR c_row in c_date loop v_Month_Number:=to_number(to_char(c_row.Date_Name,'MM')); if v_Month_Number>6 then v_Half:=2; else v_Half:=1; end if; update DIM_DATE set DIM_DATE.DATE_NAME=to_date(c_row.Date_ID,'YYYY-MM-DD'), DIM_DATE.HALF_NAME='H'||v_Half --后面在这里补充 where DIM_DATE.DATE_ID=c_row.Date_ID; end loop; END;
/*******************华丽的分割线********************/ --创建地域维度表 CREATE TABLE DIM_Geo( M_CNTY_ID number primary key, M_CNTY nvarchar2(20), --县 M_CITY nvarchar2(20), --市 M_PRVNC nvarchar2(20)--省 ); --创建销售事实表 CREATE TABLE SALES_FACT( EMPNO NUMBER(4), DATE_ID char(8), CITY_ID NUMBER, SALES NUMBER); --基于多列的联合主键 --此处为empno,date_ID, city_ID共同为一个主键 alter table SALES_FACT add constraint PK_SALES_FACT PRIMARY KEY (EMPNO,DATE_ID,CITY_ID); --查询出事实表 WITH v1 as (select * from SALES_FACT), v2 as (select * from EMP), v3 as (select * from DIM_DATE), v9 as (select * from DIM_Geo), v6 as (select distinct sales_fact.city_id from sales_fact), v4 as(SELECT v2.ename,v1.date_id,v1.city_id,v1.sales FROM v1 right join v2 on v2.empno=v1.empno), v5 as (select v4.ename,v3.date_id,v4.city_id,v4.sales from v4 partition by (v4.ename) right join v3 on v3.date_id=v4.date_id), v7 as (select v5.ename,v5.date_id,v6.city_id,v5.sales from v5 partition by (ename,date_id) right join v6 on v6.city_id=v5.city_id), v8 as (select v7.ename,v3.Date_ID,v3.Date_Name,v3.Quarter_Name,v3.Quarter_Number,v3.Month_Number,v3.MONTH_NAME,v3.Week_Name,v7.city_id,v7.sales from v7 left join v3 on v7.date_id=v3.date_id group by v7.ename,v3.Date_ID,v3.Date_Name,v3.Quarter_Name,v3.Quarter_Number,v3.MONTH_NAME,v3.Month_Number,v3.Week_Name,v7.city_id,v7.sales order by v7.ename,v3.Quarter_Name,v3.Week_Name) select ename,month_name,v9.M_CNTY,v9.M_CITY,v9.M_PRVNC,sum(sales) from v8 left join v9 on v8.city_id=v9.M_CNTY_ID WHERE ENAME='ADAMS' GROUP BY ename,month_name,v9.M_CNTY, v9.M_CITY,v9.M_PRVNC ORDER BY MONTH_NAME,M_CNTY ;
Oracle中几个类似集合的用法
union all:将多个选择结果取并集,并且包含重复部分
unional:将
intersect:
minus:
Oracle拆分字段
如有下数据:我们需要将表格1中的数据形式转换成表格2的形式(也就是将老师这个字段拆成单行)
表1 表2
| 姓名 | 学科 | 老师 |
| Jim | 语文 | 张三 李四 王五 |
| Jim | 数学 | 牛儿 |
| Jim | 英语 | 迈克尔 梁山伯 |
| Lucy | 语文 | 老五 李四 |
| 姓名 | 学科 | 老师 |
| Jim | 语文 | 张三 |
| Jim | 语文 | 李四 |
| Jim | 语文 | 王五 |
| Jim | 数学 | 牛儿 |
| Jim | 英语 | 麦克尔 |
| Jim | 英语 | 梁山伯 |
| Lucy | 语文 | 老五 |
| Lucy | 语文 | 李四 |
此处的核心问题就是:需要将一条数据拆成多条数据
在解决这个问题之前,我们先来看看一个例子

regexp_substr函数的使用方法:
function REGEXP_SUBSTR(String, pattern, position, occurrence, modifier)
String :需要进行正则处理的字符串
__pattern :进行匹配的正则表达式
__position :起始位置,从第几个字符开始正则表达式匹配(默认为1)
__occurrence :标识第几个匹配组,默认为1
__modifier :模式('i'不区分大小写进行检索;'c'区分大小写进行检索。默认为'c'。)
connect by 函数
select regexp_substr('ABCD EF G','[^ ]+',1,level,'c') from dual connect by regexp_substr('ABCD EF G','[^ ]+',1,level,'c') is not null ;
这时候,我们得到的结果是:

同样的道理,我们来实现一开始的问题,先创建这么一张关系表:
CREATE TABLE t ( student nvarchar2(20), subject nvarchar2(10), teacher nvarchar2(100) ); INSERT INTO t VALUES('Jim','语文','张三 李四 王五'); INSERT INTO t VALUES('Jim','数学','牛儿'); INSERT INTO t VALUES('Jim','英语','迈克尔 梁山伯'); INSERT INTO t VALUES('Lucy','语文','老五 李四');
接下来,我们实现对teacher这个字段进行拆分,teacher中的每个值是按照空格分开的。
我们实现的代码是这样的:
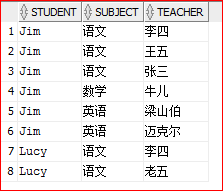
select student,subject,regexp_substr(teacher,'[^ ]+',1,level) from t group by student,subject , teacher,level connect by regexp_substr(teacher,'[^ ]+',1,level) is not null order by 1;
最终结果:

此外,我们还有另外一种方法可以来解决这个问题,前提是我们需要把所有的teacher找出来做一个临时表,
利用like方法以及左连接来拆分

select t.student ,t.subject ,teacherRecord.teacher from t left outer join teacherRecord on t.teacher like '%' || teacherRecord.teacher || '%'
最终结果:
orcle数据库表导出csv文件
废话少说,直接来代码:
set colsep , set feedback off set heading off set trimout on spool D:\DBoracle\lfc.csv select '"' || yyyymm || '","' || yyyymmdd || '","' || bu_cd || '"from jim_CALL; spool off exit

 浙公网安备 33010602011771号
浙公网安备 33010602011771号