
mysql执行拉链表操作
拉链表需求:
1.数据量比较大
2.变化的比例和频率比较小,例如客户的住址信息,联系方式等,比如有1千万的用户数据,每天全量存储会存储很多不变的信息,对存储也是浪费,因此可以使用拉链表的算法来节省存储空间
3.拉链历史表,既能反映每个客户不同时间的不同状态,也可查看某个时间点的全量快照信息
拉链表设计
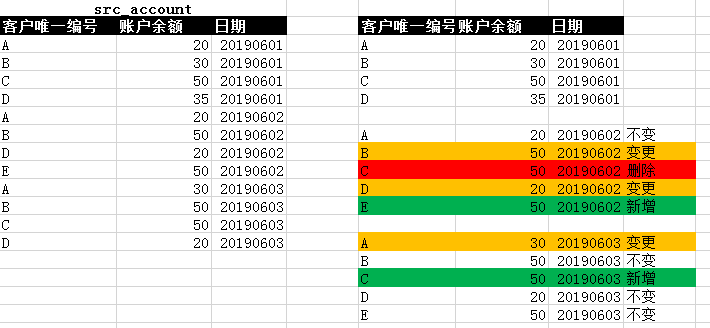
设计的拉链历史表:
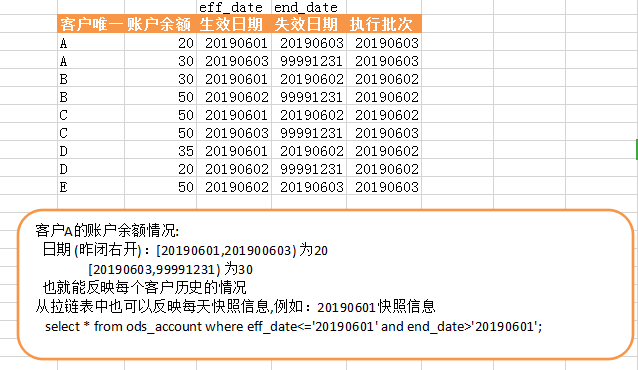
反映A客户的状态信息
select * from ods_account where cst_id='A';

反映20190601历史数据:
select * from ods_account where eff_date<='20190601' and end_date>'20190601';
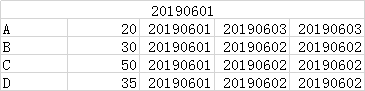
反映20190602历史全量数据:
select * from ods_account where eff_date<='20190602' and end_date>'20190602';

建表:
use edw; drop table if exists src_account; create table if not exists src_account( cst_id varchar(64) comment '客户唯一编号', bal float comment '余额', date_id varchar(16) comment '日期' )ENGINE=InnoDB DEFAULT CHARSET=utf8; alter table src_account add primary key(cst_id,date_id); drop table if exists delta_account; create table if not exists delta_account( cst_id varchar(64) comment '客户唯一编号', bal float comment '余额', etl_flag varchar(16) comment 'ETL标记' )ENGINE=InnoDB DEFAULT CHARSET=utf8; alter table delta_account add primary key(cst_id,etl_flag); drop table if exists odshis_account; create table if not exists odshis_account( cst_id varchar(64) comment '客户唯一编号', bal float comment '余额', eff_date varchar(16) comment '生效日期', end_date varchar(16) comment '失效日期', job_seq_id varchar(16) comment '批次号', new_job_seq_id varchar(16) comment '最新批次号' )ENGINE=InnoDB DEFAULT CHARSET=utf8; alter table odshis_account add primary key(cst_id,new_job_seq_id); drop table if exists ods_account; create table if not exists ods_account( cst_id varchar(64) comment '客户唯一编号', bal float comment '余额', eff_date varchar(16) comment '生效日期', end_date varchar(16) comment '失效日期', job_seq_id varchar(16) comment '批次号' )ENGINE=InnoDB DEFAULT CHARSET=utf8; alter table ods_account add primary key(cst_id,eff_date,end_date);
加载原始数据:
delete from src_account; insert into src_account values('A','20','20190601'); insert into src_account values('B','30','20190601'); insert into src_account values('C','50','20190601'); insert into src_account values('D','35','20190601'); insert into src_account values('A','20','20190602'); insert into src_account values('B','50','20190602'); insert into src_account values('D','20','20190602'); insert into src_account values('E','50','20190602'); insert into src_account values('A','30','20190603'); insert into src_account values('B','50','20190603'); insert into src_account values('C','50','20190603'); insert into src_account values('D','20','20190603'); insert into src_account values('A','30','20190604'); insert into src_account values('B','40','20190604'); insert into src_account values('C','30','20190604'); insert into src_account values('D','20','20190604'); insert into src_account values('E','20','20190604'); insert into src_account values('F','20','20190604'); insert into src_account values('G','20','20190604');
开始拉链过程:
#清空增量数据 truncate delta_account; #加载增量数据(新增) insert into delta_account select t1.cst_id,t1.bal,'I' as etl_flag from (select * from src_account where date_id = '${job_date_id}') t1 left join (select * from src_account where date_id = '${before_job_date_id}') t2 on t1.cst_id = t2.cst_id where t2.cst_id is null; #加载增量数据(删除) insert into delta_account select t1.cst_id,t1.bal,'D' as etl_flag from (select * from src_account where date_id = '${before_job_date_id}') t1 left join (select * from src_account where date_id = '${job_date_id}') t2 on t1.cst_id = t2.cst_id where t2.cst_id is null; #加载增量数据(变更前) insert into delta_account select t1.cst_id,t1.bal,'A' as etl_flag from (select * from src_account where date_id = '${job_date_id}') t1 left join (select * from src_account where date_id = '${before_job_date_id}') t2 on t1.cst_id = t2.cst_id where t2.cst_id is not null and t1.bal <> t2.bal; #加载增量数据(变更后) insert into delta_account select t1.cst_id,t2.bal,'B' as etl_flag from (select * from src_account where date_id = '${job_date_id}') t1 left join (select * from src_account where date_id = '${before_job_date_id}') t2 on t1.cst_id = t2.cst_id where t2.cst_id is not null and t1.bal <> t2.bal; #1.重跑:删除已跑入数据 delete from ods_account where job_seq_id = '${job_date_id}'; #2.重跑:从历史表恢复数据 insert into ods_account(cst_id,bal,eff_date,end_date,job_seq_id) select cst_id,bal,eff_date,end_date,job_seq_id from odshis_account where new_job_seq_id = '${job_date_id}'; #3.重跑:删除已跑入历史数据 delete from odshis_account where new_job_seq_id = '${job_date_id}'; #4.备份数据到历史表 insert into odshis_account(cst_id,bal,eff_date,end_date,job_seq_id,new_job_seq_id) select cst_id,bal,eff_date,end_date,job_seq_id,'${job_date_id}' from ods_account t where t.end_date='99991231' and exists ( select 1 from delta_account s where t.cst_id=s.cst_id ); #5.断链 update ods_account t set end_date='${job_date_id}',job_seq_id = '${job_date_id}' where t.end_date='99991231' and exists ( select 1 from delta_account s where etl_flag in ('I','D','A') and t.cst_id=s.cst_id ); #6.加链 insert into ods_account(cst_id,bal,eff_date,end_date,job_seq_id) select cst_id,bal,'${job_date_id}' as eff_date,'99991231' as end_date,'${job_date_id}' as job_seq_id from delta_account where etl_flag in ('A','I'); #7.保持数据完整性 insert into ods_account (cst_id,bal,eff_date,end_date,job_seq_id) select t.cst_id,t.bal,'${job_date_id}','${job_date_id}' as end_date,'${job_date_id}' as job_seq_id from delta_account t where etl_flag = 'D' and not exists (select 1 from ods_account s where t.cst_id=s.cst_id)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号