
10组-Alpha冲刺-1/6
一、基本情况
- 队名:要有格局才对
- 组长博客
- 小组人数:10
二、冲刺概况汇报
根据拟定的团队分工
- 在充分尊重大家意愿的前提下、团队分工如下(用名字唯一标识符标识):
- 前端组:萍、翁
- 后端组:石、林
- 数据组:硕、源、松、熙
- 管理组:苏、唐
- alpha_1汇总:
| 组名 | 第一阶段分工 | 第二阶段 | 第三阶段 | alpha_1阶段 | 主任务 |
|---|---|---|---|---|---|
| 前端组 | 原型设计、视频 | 接口调试 | 原型实现、UI优化 | 前端相关 | 前端相关 |
| 数据组 | 爬取可行性分析测试 | 数据收集 | 数据分析 | 数据相关 | 数据相关 |
| 后端组 | 数据库搭建 | 后端构建、接口文档说明 | 后端完善 | 后端相关 | 后端相关 |
| 管理组(含测试组) | 博客撰写、规划 | 各组协调 | 测试优化、部署 | 测试、端茶倒水 | 测试管理相关 |
姓名:苏伟煌(组长)
- 过去两天完成了哪些任务:
- 文字描述:
- 1.基本分工部署
- 2.GitHub部署
- 3.缓解组员紧张情绪
- 4.帮组测试组解决药监局爬取攻坚
- 展示GitHub当日代码/文档签入记录:
- 接下来的计划
- main:大家都有考试、成绩很重要、暂不作过多计划分工
- 继续爬取
- 前端初步
- 还剩下哪些任务
- 同上
- 说点实际的:微机接口考试、图形学考试、面向对象考试、人工智能。
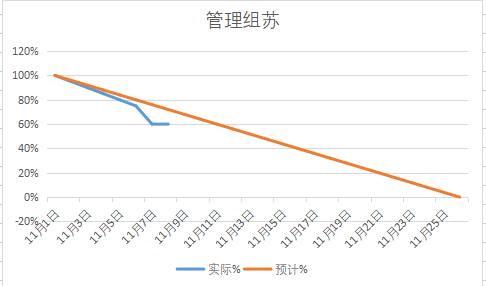
- 燃尽图
- 遇到了哪些困难
- 药监局攻坚爬取、最后用抓包手段解决
- 有哪些收获和疑问
- 收获:知道了用抓包的手段也可以在手机这种平台爬取数据、很冷门的技巧,算是作为组长为数不多的小贡献
- 疑问:药监局这种官方网站也会百疏一漏吗
| 第N轮 | 新增代码(行) | 累计代码(行) | 本轮学习耗时(小时) | 累计学习耗时(小时) | 重要成长 |
|---|---|---|---|---|---|
| 1 | 208 | 208 | 0 | 0 | 网页的基本布局以及路由跳转 |
| PSP | Personal Software Process Stages | 预估耗时(分钟 | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | 30 | 72 |
| · Estimate | · 估计这个任务需要多少时间 | 1200 | 1600 |
| Development | 开发 | 700 | 700 |
| · Analysis | · 需求分析 (包括学习新技术) | 5 | 55 |
| · Design Spec | · 生成设计文档 | 5 | 55 |
| · Design Review | · 设计复审 | 5 | 55 |
| · Coding Standard | · 代码规范 (为目前的开发制定合适的规范) | 430 | 55 |
| · Design | · 具体设计 | 120 | 120 |
| · Coding | · 具体编码 | 360 | 720 |
| · Code Review | · 代码复审 | 50 | 50 |
| · Test | · 测试(自我测试,修改代码,提交修改) | 30 | 50 |
| Reporting | 报告 | 90 | 180 |
| · Test Repor | · 测试报告 | 30 | 60 |
| · Size Measurement | · 计算工作量 | 10 | 20 |
| · Postmortem & Process Improvement Plan | · 事后总结, 并提出过程改进计划 | 10 | 100 |
| · 合计 | 1200 | 1800 |
姓名:王毅萍
- 过去两天完成了哪些任务:
- 文字描述:
- 1.基本前端分工部署
- 2.GitHub前端部署
- 3.帮组测试组解决药监局爬取攻坚
- 展示GitHub当日代码/文档签入记录:
- 接下来的计划
- main:完成前端素材积累和初步测试
- 继续UI完善
- 前端初步
- 还剩下哪些任务
- 同上
- 前端完善。
- 学习vue框架、pyecharts
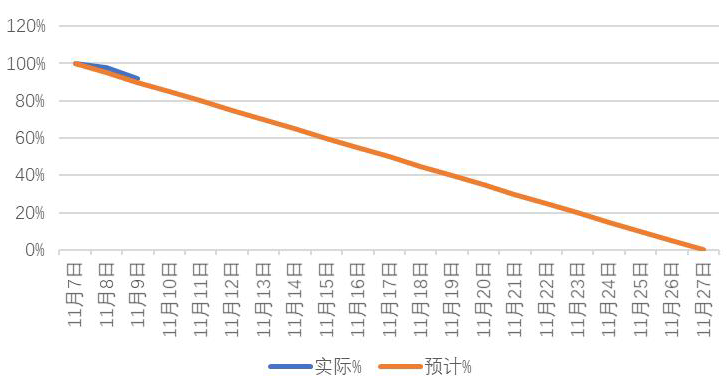
- 燃尽图
- 遇到了哪些困难
- 账号密码token连接故障
- 有哪些收获和疑问
- 收获:和后端组沟通解决了跨域问题
- 疑问:之前测试组猪尾巴的前端跨域问题和这次有些类似、但是合理的解决方法应该是后端修改
| 第N轮 | 新增代码(行) | 累计代码(行) | 本轮学习耗时(小时) | 累计学习耗时(小时) | 重要成长 |
|---|---|---|---|---|---|
| 1 | 208 | 208 | 0 | 0 | 网页的基本布局以及路由跳转 |
| PSP | Personal Software Process Stages | 预估耗时(分钟 | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | 30 | 72 |
| · Estimate | · 估计这个任务需要多少时间 | 1200 | 1600 |
| Development | 开发 | 700 | 700 |
| · Analysis | · 需求分析 (包括学习新技术) | 5 | 55 |
| · Design Spec | · 生成设计文档 | 5 | 55 |
| · Design Review | · 设计复审 | 5 | 55 |
| · Coding Standard | · 代码规范 (为目前的开发制定合适的规范) | 430 | 55 |
| · Design | · 具体设计 | 120 | 120 |
| · Coding | · 具体编码 | 360 | 720 |
| · Code Review | · 代码复审 | 50 | 50 |
| · Test | · 测试(自我测试,修改代码,提交修改) | 30 | 50 |
| Reporting | 报告 | 90 | 180 |
| · Test Repor | · 测试报告 | 30 | 60 |
| · Size Measurement | · 计算工作量 | 10 | 20 |
| · Postmortem & Process Improvement Plan | · 事后总结, 并提出过程改进计划 | 10 | 100 |
| · 合计 | 1200 | 1800 |
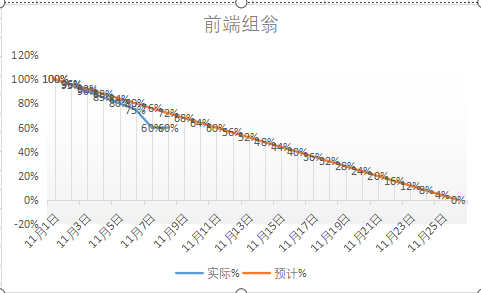
姓名:翁敏(前端组)
- 过去两天完成了哪些任务:
- 文字描述:
- 1.动手实战了用网页三件套(html,css,js)制作页面,主要收获了样式布置的相对位置和绝对位置,js语言相对容易上手,setinterval延时功能让我明白可以用js代码控制页面的更新。
- 2.学习了vue框架的大致使用,学习了一些组件(比如v-on,v-if,v-show,这些组件比传统的js代码设计页面来的省时省力
- 3.通过和同学的交谈,收获了很多优秀的第三方插件或者框架的使用方法,使自己更容易使用搜索引擎寻找网络上的资源
- 4.对本次软工课设前端页面的布局有了新的设计思路,主要布局有了大致的设计想法。
- 展示GitHub当日代码/文档签入记录:
- 接下来的计划
- 1.学习vue框架
- 2.学习一些更前言的网页设计方法
- 3.学习一些数据存储方法,特别是跨页面存储,之前用export模块存储,但是浏览器会报错,这个问题待解决。
- 还剩下哪些任务
- 1.因为我是担任前端任务,所以我对自己设定的主要任务是学习使用vue框架设计页面
- 2.学习页面如何调用后台数据库
- 燃尽图
- 遇到了哪些困难
- 1.在数据存储这块自己掌握的仍然不清晰,不知道页面的存储信息模式是怎么样的,设置成全局变量再页面更新的时候就初始化掉,export模块也会报错
- 2.对一些好用适用的框架了解太少了,vue知识也欠缺,以至于动手写代码时候相关的知识不够用,需要自己重新造轮子
- 有哪些收获和疑问
- 1.(疑问上面已经描述了,这里不早赘述)收获了一些新的页面设计思路,以前自己只会用网页三件套设计页面,但是那样太繁杂了,而且都是重复造轮子。
- 2.学习了解了一些新的框架的使用,vue真是太方便了,当然肯定还有许多更好用的框架和组件等待着我去发现。
| Alpha冲刺 | 新增代码(行) | 累计代码(行) | 本次学习耗时(小时) | 累计学习耗时(小时) | 重要成长与任务进展 |
|---|---|---|---|---|---|
| 1/6 | 462 | 462 | 11 | 11 | 对前端原型进行架构,接口调试,以及安排分工前端组同学的任务 |
| PSP | Personal Software Process Stages | 预估耗时(分钟 | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | 30 | 72 |
| · Estimate | · 估计这个任务需要多少时间 | 1200 | 1600 |
| Development | 开发 | 700 | 700 |
| · Analysis | · 需求分析 (包括学习新技术) | 5 | 55 |
| · Design Spec | · 生成设计文档 | 5 | 55 |
| · Design Review | · 设计复审 | 5 | 55 |
| · Coding Standard | · 代码规范 (为目前的开发制定合适的规范) | 430 | 55 |
| · Design | · 具体设计 | 120 | 120 |
| · Coding | · 具体编码 | 360 | 720 |
| · Code Review | · 代码复审 | 50 | 50 |
| · Test | · 测试(自我测试,修改代码,提交修改) | 30 | 50 |
| Reporting | 报告 | 90 | 180 |
| · Test Repor | · 测试报告 | 30 | 60 |
| · Size Measurement | · 计算工作量 | 10 | 20 |
| · Postmortem & Process Improvement Plan | · 事后总结, 并提出过程改进计划 | 10 | 100 |
| · 合计 | 1200 | 1800 |
姓名:陈本源(数据组)
- 过去两天完成了哪些任务:
- 文字描述:
- 1.爬虫爬取淘宝(几十万条数据)
- 2.爬虫爬取比价网(几十万条数据)
- 3.数据发送至后端
- 展示GitHub当日代码/文档签入记录:
- 接下来的计划
- 1.进行数据清洗
- 2.开始学习PyEcharts,对爬取到的数据,进行数据分析
- 还剩下哪些任务
- 1.对数据进行处理与分析
- 2.生成可视化图
- 燃尽图
- 遇到了哪些困难
- 1.再爬取淘宝的过程中,由于网站的反爬机制,设置了cookies,成功爬取到页面的相关信息,但是由于本次任务爬取的数据量实在太过庞大,频繁的访问淘宝的url,导致连接多次被主动中断,甚至出现ip被封,针对此问题本来打算使用selenium,通过动态模拟用户点击行为,对页面进行渲染,从而绕过反爬机制,实现爬取,但是该方法耗时长,对于本次任务需要爬取的巨大数据量显然不适合。后又发现设置time.sleep设置url访问间隔,但也同样浪费时间,最后采用python自带的fake_useragent库,通过设置随机头对url进行访问,大大降低了服务器对机器爬虫的认定概率,从而实现爬取53w条
- 2.爬取比价网的过程中,同样也是遇到了ip访问限制,使用download_delay解决。
- 有哪些收获和疑问
- 1.随机头方法在scrapy爬虫框架中,似乎起不到什么作用,导致爬取比价网的过程很煎熬,
- 2.了解了ip限制的解决方法。

| Alpha冲刺 | 新增代码(行) | 累计代码(行) | 本次学习耗时(小时) | 累计学习耗时(小时) | 重要成长与任务进展 |
|---|---|---|---|---|---|
| 1/6 | 442 | 442 | 10 | 10 | 和另一位组员一起对京东的药品信息数据进行爬取 |
| PSP | Personal Software Process Stages | 预估耗时(分钟 | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | 30 | 72 |
| · Estimate | · 估计这个任务需要多少时间 | 1200 | 1600 |
| Development | 开发 | 700 | 700 |
| · Analysis | · 需求分析 (包括学习新技术) | 5 | 55 |
| · Design Spec | · 生成设计文档 | 5 | 55 |
| · Design Review | · 设计复审 | 5 | 55 |
| · Coding Standard | · 代码规范 (为目前的开发制定合适的规范) | 430 | 55 |
| · Design | · 具体设计 | 120 | 120 |
| · Coding | · 具体编码 | 360 | 720 |
| · Code Review | · 代码复审 | 50 | 50 |
| · Test | · 测试(自我测试,修改代码,提交修改) | 30 | 50 |
| Reporting | 报告 | 90 | 180 |
| · Test Repor | · 测试报告 | 30 | 60 |
| · Size Measurement | · 计算工作量 | 10 | 20 |
| · Postmortem & Process Improvement Plan | · 事后总结, 并提出过程改进计划 | 10 | 100 |
| · 合计 | 1200 | 1800 |
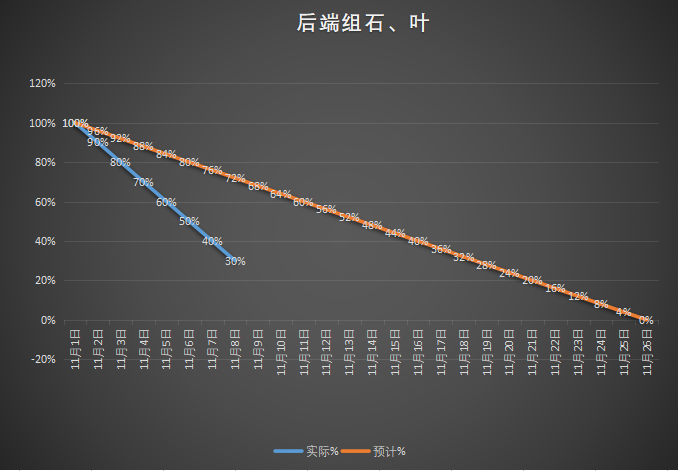
姓名:石致彬
- 过去两天完成了哪些任务:
- 文字描述:
- 1.学习数据库的相关操作
- 2.学习用jdbc连接数据库
- 3.初步设计了所需要的表
- 4.初步建立了数据库
- 展示GitHub当日代码/文档签入记录:无
- 接下来的计划
- 1.学习Web方面的知识
- 2.编写接口供数据组使用向数据库中添加数据
- 3.编写接口供数据查询使用
- 还剩下哪些任务
- 1.学习web知识
- 2.编写接口
- 3.学习云服务器的使用
- 4.配置云服务器的环境
- 5.部署到云服务器
- 燃尽图
- 遇到了哪些困难
- 1.时间不够考试太多
- 2.服务器太贵了
- 有哪些收获和疑问
- 1.学习了数据库的相关知识
- 2.学习了用Java操作数据库
- 3.疑问:我们真的做得完吗

| Alpha冲刺 | 新增代码(行) | 累计代码(行) | 本次学习耗时(小时) | 累计学习耗时(小时) | 重要成长与任务进展 |
|---|---|---|---|---|---|
| 1/6 | 563 | 563 | 14 | 14 | 和另一位组员合作对数据库进行搭建,以及后端的搭建 |
| PSP | Personal Software Process Stages | 预估耗时(分钟 | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | 30 | 72 |
| · Estimate | · 估计这个任务需要多少时间 | 1200 | 1600 |
| Development | 开发 | 700 | 700 |
| · Analysis | · 需求分析 (包括学习新技术) | 5 | 55 |
| · Design Spec | · 生成设计文档 | 5 | 55 |
| · Design Review | · 设计复审 | 5 | 55 |
| · Coding Standard | · 代码规范 (为目前的开发制定合适的规范) | 430 | 55 |
| · Design | · 具体设计 | 120 | 120 |
| · Coding | · 具体编码 | 360 | 720 |
| · Code Review | · 代码复审 | 50 | 50 |
| · Test | · 测试(自我测试,修改代码,提交修改) | 30 | 50 |
| Reporting | 报告 | 90 | 180 |
| · Test Repor | · 测试报告 | 30 | 60 |
| · Size Measurement | · 计算工作量 | 10 | 20 |
| · Postmortem & Process Improvement Plan | · 事后总结, 并提出过程改进计划 | 10 | 100 |
| · 合计 | 1200 | 1800 |
姓名:黄艇淞(数据组)
- 过去两天完成了哪些任务:
- 文字描述:
- 1.爬虫爬取淘宝(几十万条数据)
- 2.爬虫爬取比价网(几十万条数据)
- 3.数据发送至后端
- 展示GitHub当日代码/文档签入记录:
- 接下来的计划
- 1.进行数据清洗
- 2.开始学习PyEcharts,对爬取到的数据,进行数据分析
- 还剩下哪些任务
- 1.对数据进行处理与分析
- 2.生成可视化图
- 燃尽图
- 遇到了哪些困难
- 1.再爬取淘宝的过程中,由于网站的反爬机制,设置了cookies,成功爬取到页面的相关信息,但是由于本次任务爬取的数据量实在太过庞大,频繁的访问淘宝的url,导致连接多次被主动中断,甚至出现ip被封,针对此问题本来打算使用selenium,通过动态模拟用户点击行为,对页面进行渲染,从而绕过反爬机制,实现爬取,但是该方法耗时长,对于本次任务需要爬取的巨大数据量显然不适合。后又发现设置time.sleep设置url访问间隔,但也同样浪费时间,最后采用python自带的fake_useragent库,通过设置随机头对url进行访问,大大降低了服务器对机器爬虫的认定概率,从而实现爬取53w条
- 2.爬取比价网的过程中,同样也是遇到了ip访问限制,使用download_delay解决。
- 有哪些收获和疑问
- 1.随机头方法在scrapy爬虫框架中,似乎起不到什么作用,导致爬取比价网的过程很煎熬,
- 2.了解了ip限制的解决方法。
| Alpha冲刺 | 新增代码(行) | 累计代码(行) | 本次学习耗时(小时) | 累计学习耗时(小时) | 重要成长与任务进展 |
|---|---|---|---|---|---|
| 1/6 | 352 | 352 | 7 | 7 | 和另一位组员一起对京东的药品信息数据进行爬取 |
| PSP | Personal Software Process Stages | 预估耗时(分钟 | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | 30 | 72 |
| · Estimate | · 估计这个任务需要多少时间 | 1200 | 1600 |
| Development | 开发 | 700 | 700 |
| · Analysis | · 需求分析 (包括学习新技术) | 5 | 55 |
| · Design Spec | · 生成设计文档 | 5 | 55 |
| · Design Review | · 设计复审 | 5 | 55 |
| · Coding Standard | · 代码规范 (为目前的开发制定合适的规范) | 430 | 55 |
| · Design | · 具体设计 | 120 | 120 |
| · Coding | · 具体编码 | 360 | 720 |
| · Code Review | · 代码复审 | 50 | 50 |
| · Test | · 测试(自我测试,修改代码,提交修改) | 30 | 50 |
| Reporting | 报告 | 90 | 180 |
| · Test Repor | · 测试报告 | 30 | 60 |
| · Size Measurement | · 计算工作量 | 10 | 20 |
| · Postmortem & Process Improvement Plan | · 事后总结, 并提出过程改进计划 | 10 | 100 |
| · 合计 | 1200 | 1800 |
姓名:唐劲霆
- 过去两天完成了哪些任务:
- 文字描述:
- 1.协同部署
- 2.各个分工小组的问题汇总商讨
- 3.博客汇总整合
- 展示GitHub当日代码/文档签入记录:
- 接下来的计划
- 同步测试
- 还剩下哪些任务
- 继续协同分工,及测试功能
- 燃尽图

- 遇到了哪些困难
- GitHub上传文件登入时密码没错但是遇一直提示密码错误,人麻了
- 有哪些收获和疑问
- 收获:跟着组长学了一些,以及GitHub的token申请
- 疑问:药监局这种官方网站也会百疏一漏吗
| 第N轮 | 新增代码(行) | 累计代码(行) | 本轮学习耗时(小时) | 累计学习耗时(小时) | 重要成长 |
|---|---|---|---|---|---|
| 1 | 208 | 208 | 0 | 0 | 网页的基本布局以及路由跳转 |
| PSP | Personal Software Process Stages | 预估耗时(分钟 | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | 30 | 72 |
| · Estimate | · 估计这个任务需要多少时间 | 1200 | 1600 |
| Development | 开发 | 700 | 700 |
| · Analysis | · 需求分析 (包括学习新技术) | 5 | 55 |
| · Design Spec | · 生成设计文档 | 5 | 55 |
| · Design Review | · 设计复审 | 5 | 55 |
| · Coding Standard | · 代码规范 (为目前的开发制定合适的规范) | 430 | 55 |
| · Design | · 具体设计 | 120 | 120 |
| · Coding | · 具体编码 | 360 | 720 |
| · Code Review | · 代码复审 | 50 | 50 |
| · Test | · 测试(自我测试,修改代码,提交修改) | 30 | 50 |
| Reporting | 报告 | 90 | 180 |
| · Test Repor | · 测试报告 | 30 | 60 |
| · Size Measurement | · 计算工作量 | 10 | 20 |
| · Postmortem & Process Improvement Plan | · 事后总结, 并提出过程改进计划 | 10 | 100 |
| · 合计 | 1200 | 1800 |
姓名:林志煌
- 过去两天完成了哪些任务:
- 文字描述:
- 1.复习了前端三要素
- 2.写了简单的登录界面
- 展示GitHub当日代码/文档签入记录:
- 接下来的计划
- 1.继续完善界面
- 2.增加其他功能
- 还剩下哪些任务
- 1.完善
- 2.增加功能
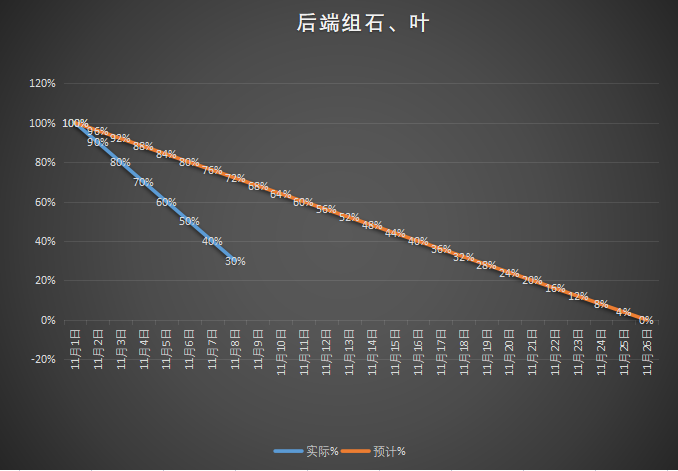
- 燃尽图
- 遇到了哪些困难
- 1.知识点大多都忘了,只能边查边做
- 2.模板几乎都是要收费的
- 有哪些收获和疑问
- 1.收获:复习了以前的知识,算是小巩固
- 2.疑问:暂时没啥疑问
| Alpha冲刺 | 新增代码(行) | 累计代码(行) | 本次学习耗时(小时) | 累计学习耗时(小时) | 重要成长与任务进展 |
|---|---|---|---|---|---|
| 1/6 | 362 | 362 | 10 | 10 | 和另一位组员合作对数据库进行搭建,以及后端的搭建 |
| PSP | Personal Software Process Stages | 预估耗时(分钟 | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | 30 | 72 |
| · Estimate | · 估计这个任务需要多少时间 | 1200 | 1600 |
| Development | 开发 | 700 | 700 |
| · Analysis | · 需求分析 (包括学习新技术) | 5 | 55 |
| · Design Spec | · 生成设计文档 | 5 | 55 |
| · Design Review | · 设计复审 | 5 | 55 |
| · Coding Standard | · 代码规范 (为目前的开发制定合适的规范) | 430 | 55 |
| · Design | · 具体设计 | 120 | 120 |
| · Coding | · 具体编码 | 360 | 720 |
| · Code Review | · 代码复审 | 50 | 50 |
| · Test | · 测试(自我测试,修改代码,提交修改) | 30 | 50 |
| Reporting | 报告 | 90 | 180 |
| · Test Repor | · 测试报告 | 30 | 60 |
| · Size Measurement | · 计算工作量 | 10 | 20 |
| · Postmortem & Process Improvement Plan | · 事后总结, 并提出过程改进计划 | 10 | 100 |
| · 合计 | 1200 | 1800 |
姓名:陈硕
- 过去两天完成了哪些任务:
- 文字描述:
- 1.爬虫爬取淘宝(几十万条数据)
- 2.爬虫爬取药房网
- 3.数据发送至后端
- 展示GitHub当日代码/文档签入记录:
- 接下来的计划
- 1.进行数据清洗
- 2.开始学习PyEcharts,对爬取到的数据,进行数据分析
- 还剩下哪些任务
- 1.对数据进行处理与分析
- 2.生成可视化图
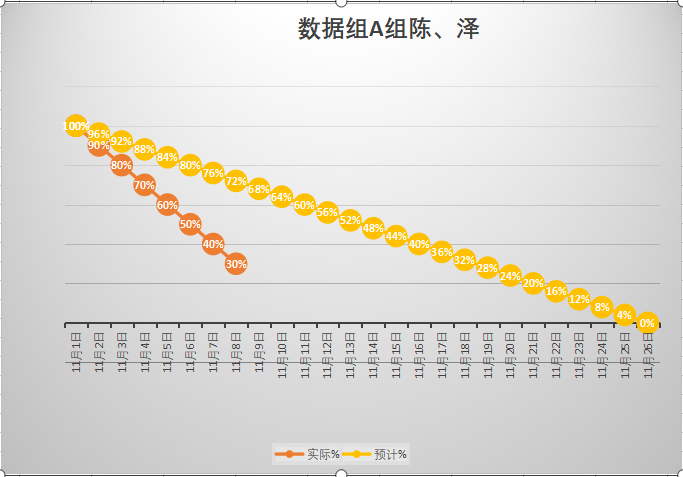
- 燃尽图
- 遇到了哪些困难
- 1.爬虫团队在爬取淘宝的过程中,由于网站的反爬机制,设置了cookies,成功爬取到页面的相关信息,但是由于本次任务爬取的数据量实在太过庞大,频繁的访问淘宝的url,导致连接多次被主动中断,甚至出现ip被封,针对此问题本来打算使用selenium,通过动态模拟用户点击行为,对页面进行渲染,从而绕过反爬机制,实现爬取,但是该方法耗时长,对于本次任务需要爬取的巨大数据量显然不适合。后又发现设置time.sleep设置url访问间隔,但也同样浪费时间,最后采用python自带的fake_useragent库,通过设置随机头对url进行访问,大大降低了服务器对机器爬虫的认定概率,从而实现爬取53w条
- 2.爬取比价网的过程中,同样也是遇到了ip访问限制,使用download_delay解决。
- 有哪些收获和疑问
- 1.随机头方法在scrapy爬虫框架中,似乎起不到什么作用,导致爬取比价网的过程很煎熬,
- 2.了解了ip限制的解决方法。
| Alpha冲刺 | 新增代码(行) | 累计代码(行) | 本次学习耗时(小时) | 累计学习耗时(小时) | 重要成长与任务进展 |
|---|---|---|---|---|---|
| 1/6 | 410 | 410 | 9 | 9 | 和另一位组员一起对淘宝的药品信息数据进行爬取 |
| PSP | Personal Software Process Stages | 预估耗时(分钟 | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | 30 | 72 |
| · Estimate | · 估计这个任务需要多少时间 | 1200 | 1600 |
| Development | 开发 | 700 | 700 |
| · Analysis | · 需求分析 (包括学习新技术) | 5 | 55 |
| · Design Spec | · 生成设计文档 | 5 | 55 |
| · Design Review | · 设计复审 | 5 | 55 |
| · Coding Standard | · 代码规范 (为目前的开发制定合适的规范) | 430 | 55 |
| · Design | · 具体设计 | 120 | 120 |
| · Coding | · 具体编码 | 360 | 720 |
| · Code Review | · 代码复审 | 50 | 50 |
| · Test | · 测试(自我测试,修改代码,提交修改) | 30 | 50 |
| Reporting | 报告 | 90 | 180 |
| · Test Repor | · 测试报告 | 30 | 60 |
| · Size Measurement | · 计算工作量 | 10 | 20 |
| · Postmortem & Process Improvement Plan | · 事后总结, 并提出过程改进计划 | 10 | 100 |
| · 合计 | 1200 | 1800 |
姓名:林泽熙
- 过去两天完成了哪些任务:
- 文字描述:
- 1.爬虫爬取淘宝(几十万条数据)
- 2.数据发送至后端
- 展示GitHub当日代码/文档签入记录:
- 接下来的计划
- 1.进行数据清洗
- 2.开始学习Pyecharts
- 还剩下哪些任务
- 1.数据处理与分析
- 2.数据可视化
- 燃尽图
- 遇到了哪些困难
- 1.爬虫团队在爬取淘宝的过程中,由于网站的反爬机制,设置了cookies,成功爬取到页面的相关信息,但是由于本次任务爬取的数据量实在太过庞大,频繁的访问淘宝的url,导致连接多次被主动中断,甚至出现ip被封,针对此问题本来打算使用selenium,通过动态模拟用户点击行为,对页面进行渲染,从而绕过反爬机制,实现爬取,但是该方法耗时长,对于本次任务需要爬取的巨大数据量显然不适合。后又发现设置time.sleep设置url访问间隔,但也同样浪费时间,最后采用python自带的fake_useragent库,通过设置随机头对url进行访问,大大降低了服务器对机器爬虫的认定概率,从而实现爬取53w条
- 2.github使用不熟悉
- 3.复现了组长的抓包爬取药监局手段,完善了json字段
- 有哪些收获和疑问
- 1.了解了ip限制的解决方法。
- 2.python第三方库功能强大,需要自己多多了解和使用
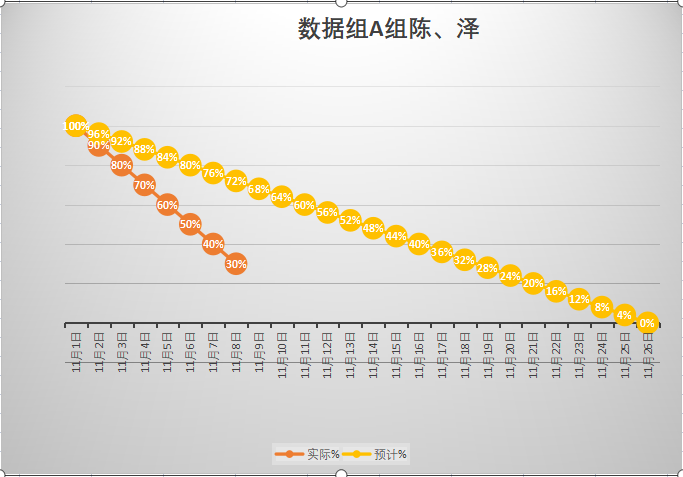
| Alpha冲刺 | 新增代码(行) | 累计代码(行) | 本次学习耗时(小时) | 累计学习耗时(小时) | 重要成长与任务进展 |
|---|---|---|---|---|---|
| 1/6 | 411 | 411 | 10 | 10 | 和另一位组员一起对淘宝的药品信息数据进行爬取 |
| PSP | Personal Software Process Stages | 预估耗时(分钟 | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | 30 | 72 |
| · Estimate | · 估计这个任务需要多少时间 | 1200 | 1600 |
| Development | 开发 | 700 | 700 |
| · Analysis | · 需求分析 (包括学习新技术) | 5 | 55 |
| · Design Spec | · 生成设计文档 | 5 | 55 |
| · Design Review | · 设计复审 | 5 | 55 |
| · Coding Standard | · 代码规范 (为目前的开发制定合适的规范) | 430 | 55 |
| · Design | · 具体设计 | 120 | 120 |
| · Coding | · 具体编码 | 360 | 720 |
| · Code Review | · 代码复审 | 50 | 50 |
| · Test | · 测试(自我测试,修改代码,提交修改) | 30 | 50 |
| Reporting | 报告 | 90 | 180 |
| · Test Repor | · 测试报告 | 30 | 60 |
| · Size Measurement | · 计算工作量 | 10 | 20 |
| · Postmortem & Process Improvement Plan | · 事后总结, 并提出过程改进计划 | 10 | 100 |
| · 合计 | 1200 | 1800 |
三、冲刺成果展示
PSP & 学习进度条(学习进度条每周追加)
PSP(全队)
| PSP | Personal Software Process Stages | 预估耗时(分钟 | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | 300 | 720 |
| · Estimate | · 估计这个任务需要多少时间 | 12000 | 16000 |
| Development | 开发 | 7000 | 7000 |
| · Analysis | · 需求分析 (包括学习新技术) | 50 | 550 |
| · Design Spec | · 生成设计文档 | 50 | 550 |
| · Design Review | · 设计复审 | 50 | 550 |
| · Coding Standard | · 代码规范 (为目前的开发制定合适的规范) | 4300 | 550 |
| · Design | · 具体设计 | 1200 | 1200 |
| · Coding | · 具体编码 | 3600 | 7200 |
| · Code Review | · 代码复审 | 500 | 500 |
| · Test | · 测试(自我测试,修改代码,提交修改) | 300 | 500 |
| Reporting | 报告 | 900 | 1800 |
| · Test Repor | · 测试报告 | 30 0 | 600 |
| · Size Measurement | · 计算工作量 | 100 | 200 |
| · Postmortem & Process Improvement Plan | · 事后总结, 并提出过程改进计划 | 10 | 100 |
| · 合计 | 1200 | 18000 |
学习进度条
- 苏伟煌:
| Alpha冲刺 | 新增代码(行) | 累计代码(行) | 本次学习耗时(小时) | 累计学习耗时(小时) | 重要成长与任务进展 |
|---|---|---|---|---|---|
| 1/6 | 506 | 506 | 15 | 15 | 各部分工作任务监督,对后端初步进行测试以及参与前端原型架构 |
- 陈硕:
| Alpha冲刺 | 新增代码(行) | 累计代码(行) | 本次学习耗时(小时) | 累计学习耗时(小时) | 重要成长与任务进展 |
|---|---|---|---|---|---|
| 1/6 | 410 | 410 | 9 | 9 | 和另一位组员一起对淘宝的药品信息数据进行爬取 |
- 陈本源:
| Alpha冲刺 | 新增代码(行) | 累计代码(行) | 本次学习耗时(小时) | 累计学习耗时(小时) | 重要成长与任务进展 |
|---|---|---|---|---|---|
| 1/6 | 442 | 442 | 10 | 10 | 和另一位组员一起对京东的药品信息数据进行爬取 |
- 黄艇淞:
| Alpha冲刺 | 新增代码(行) | 累计代码(行) | 本次学习耗时(小时) | 累计学习耗时(小时) | 重要成长与任务进展 |
|---|---|---|---|---|---|
| 1/6 | 352 | 352 | 7 | 7 | 和另一位组员一起对京东的药品信息数据进行爬取 |
- 林泽熙:
| Alpha冲刺 | 新增代码(行) | 累计代码(行) | 本次学习耗时(小时) | 累计学习耗时(小时) | 重要成长与任务进展 |
|---|---|---|---|---|---|
| 1/6 | 411 | 411 | 10 | 10 | 和另一位组员一起对淘宝的药品信息数据进行爬取 |
- 翁敏:
| Alpha冲刺 | 新增代码(行) | 累计代码(行) | 本次学习耗时(小时) | 累计学习耗时(小时) | 重要成长与任务进展 |
|---|---|---|---|---|---|
| 1/6 | 462 | 462 | 11 | 11 | 对前端原型进行架构,接口调试,以及安排分工前端组同学的任务 |
- 林志煌:
| Alpha冲刺 | 新增代码(行) | 累计代码(行) | 本次学习耗时(小时) | 累计学习耗时(小时) | 重要成长与任务进展 |
|---|---|---|---|---|---|
| 1/6 | 362 | 362 | 10 | 10 | 和另一位组员合作对数据库进行搭建,以及后端的搭建 |
- 石致彬:
| Alpha冲刺 | 新增代码(行) | 累计代码(行) | 本次学习耗时(小时) | 累计学习耗时(小时) | 重要成长与任务进展 |
|---|---|---|---|---|---|
| 1/6 | 563 | 563 | 14 | 14 | 和另一位组员合作对数据库进行搭建,以及后端的搭建 |
- 唐劲霆:
| Alpha冲刺 | 新增代码(行) | 累计代码(行) | 本次学习耗时(小时) | 累计学习耗时(小时) | 重要成长与任务进展 |
|---|---|---|---|---|---|
| 1/6 | 369 | 369 | 10 | 10 | 各分工组反馈的问题商讨解决,后端初步测试,博客整合 |
- 王毅萍:
| Alpha冲刺 | 新增代码(行) | 累计代码(行) | 本次学习耗时(小时) | 累计学习耗时(小时) | 重要成长与任务进展 |
|---|---|---|---|---|---|
| 1/6 | 388 | 388 | 8 | 8 | 对前端原型进行架构,接口调试 |
-
组内最新成果展示
- 以二甲双胍为例的成本价指导价散点图:
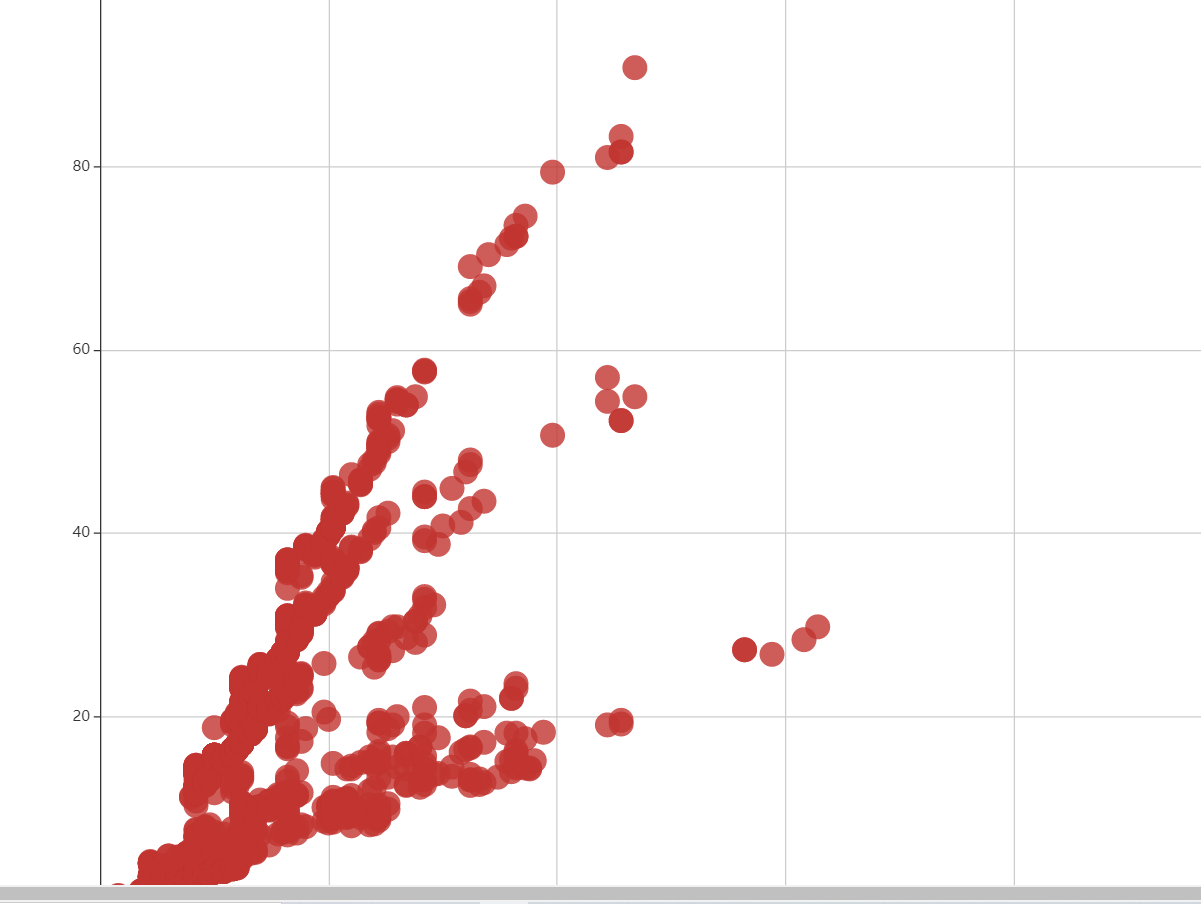
解析了图中潜在的三个斜率的含义,有95.5以上的概率可以认为药品的剂型与药品价格相关(by数据组) - 前端组协助下,利用抓包工具爬取了药监局的药品名单:部分展示如下:


将近1.8万条
- 以二甲双胍为例的成本价指导价散点图:
-
站立会议合照

-
会议耗时记录(每次追加记录)
| 第N次alpha会议 | 耗时(分钟) |
|---|---|
| 1/6 | 8 |
| 2/6 | |
| 3/6 | |
| 4/6 | |
| 5/6 | |
| 6/6 |

 浙公网安备 33010602011771号
浙公网安备 33010602011771号