字符串
字符串是不可变类型,就是说改变一个字符串的元素需要新建一个新的字符串.字符串是由 独立的字符组成的,并且这些字符可以通过切片操作顺序地访问。 双引号或者单引号中的数据,就是字符串
【1】字符串的定义
定义变量aString,存储的是字符串类型的值
aString = "pyhton" 或者 aString = 'python'
【2】字符串输出
name = 'hugo' position = 'webFont' print('--------------------------------------------------') print("姓名:%s" % name) print("职位:%s" % position) print('--------------------------------------------------') 结果如下; -------------------------------------------------- 姓名:hugo 职位:webFont --------------------------------------------------
【3】字符串输入
input获取的数据,都以字符串的方式进行保存,即使输入的是数字,那么也是以字符串方式保存
userName = input('请输入用户名:') print("用户名为:%s"%userName) password = input('请输入密码:') print("密码为:%s"%password)
根据输入的内容显示该内容
【4】下标
下面以字符串'abcd'为例子.表里面分别列出了使用正索引和负索引来定位字符的情况. 可以用长度操作符来确认该字符串的长度是 4:
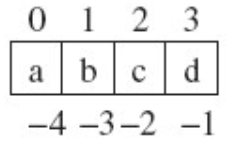
aString = 'abcde' aString[0] #a aString[1] #b aString[4] #e aString[-1] #e
【5】切片
切片是指对操作的对象截取其中一部分的操作。字符串、列表、元组都支持切片操作。
语法:
[起始:结束:步长]
注意:选取的区间属于左闭右开型,即从"起始"位开始,到"结束"位的前一位结束(不包含结束位本身)。
>>> name = 'abcdef' #取下标0~2 的字符 >>> name[0:3] 'abc' # 取下标为0~4 的字符 >>> name[0:5] 'abcde' #取下标为3、4 的字符 >>> name[3:5] 'de' #取下标为3、4 的字符 >>> name[2:] 'cdef' #取下标为1开始到最后第2个之间的字符 >>> name[1:-1] 'bcde' #取从0开始到第二个之前的字符 >>> name[:3] 'abc' #取从第一个到最后一个,步长为2 >>> name[::2] 'ace' >>> name[5:1:2] '' #取第一个到第四个之间的字符串,步长为2 >>> name[1:5:2] 'bd' #开始到结束,步长为-2 >>> name[::-2] 'fdb' #取第五个到第一个,步长为-2 >>> name[5:1:-2] 'fd'
【6】Python字符串运算符
下表实例变量 a 值为字符串 "Hello",b 变量值为 "Python":
| 操作符 | 描述 | 实例 |
|---|---|---|
| + | 字符串连接 |
>>>a + b 'HelloPython'
|
| * | 重复输出字符串 |
>>>a * 2 'HelloHello'
|
| [] | 通过索引获取字符串中字符 |
>>>a[1] 'e'
|
| [ : ] | 截取字符串中的一部分 |
>>>a[1:4] 'ell'
|
| in | 成员运算符 - 如果字符串中包含给定的字符返回 True |
>>>"H" in a True
|
| not in | 成员运算符 - 如果字符串中不包含给定的字符返回 True |
>>>"M" not in a True
|
| r/R | 原始字符串 - 原始字符串:所有的字符串都是直接按照字面的意思来使用,没有转义特殊或不能打印的字符。 原始字符串除在字符串的第一个引号前加上字母"r"(可以大小写)以外,与普通字符串有着几乎完全相同的语法。 |
>>>print r'\n' \n >>> print R'\n' \n
|
【7】python的字符串内建函数
- find() 检测 str 是否包含在 mystr中,如果是返回开始的索引值,否则返回-1
语法:str.find(str, start=0, end=len(str))
>>> str = "hello world" >>> str.find("world") 6 >>> str.find("world",0,5) -1
- index() 跟find()方法一样,只不过如果str不在 mystr中会报一个异常.
语法:
str.index(str, start=0, end=len(str))
>>>str = "hello world" >>> str.index("world",0,5) Traceback (most recent call last): File "<stdin>", line 1, in <module> ValueError: substring not found
-
count() 返回 str在start和end之间 在 mystr里面出现的次数
语法:
str.count(str, start=0, end=len(str))
str = "hello world" >>> str.count("l") 3
-
replace() 把 mystr 中的 str1 替换成 str2,如果 count 指定,则替换不超过 count 次.
语法:
str.replace(str1, str2, str.count(str1))
>>> str = "hello world hw hw" >>> str.replace("hw","HW") 'hello world HW HW' >>> str.replace("hw","HW",1) 'hello world HW hw' >>>
-
split() 切片
>>> str='hello world hw hw' >>> str.split(" ") ['hello', 'world', 'hw', 'hw'] >>> str.split(" ",2) ['hello', 'world', 'hw hw']
- capitalize() 把字符串的第一个字符大写
>>>str = "hello" >>>str.capitalize() Hello
- title() 把字符串的每个单词首字母大写
>>> a = "hello world" >>> a.title() 'Hello World'
- startswith() 检查字符串是否是以 obj 开头, 是则返回 True,否则返回 False
>>>str = "hello world" >>>str.startswith("hello") True >>>str.startswith("Hello") False
-
endswith() 检查字符串是否以obj结束,如果是返回True,否则返回 False.
>>>str = "hello world" >>>str.endswith("world") True >>>str.endswith("World") False
-
lower() 将字符串中所有大写字符为小写
>>>str = "HeLLo World" >>>str.lower() hello world
-
upper() 将字符串中所有小写字符为大写
>>>str = "hello World" >>>str.upper() HELLO WORLD
-
ljust() 返回一个原字符串左对齐,并使用空格填充至长度width
>>>str = "hello World" >>>str.upper() HELLO WORLD
-
rjust() 返回一个原字符串右对齐,并使用空格填充至长度width
>>> str = "hello" >>> str.rjust(10) ' hello'
-
center() 返回一个原字符串居中,并使用空格填充至长度 width 的新字符串
>>> str = "hello" >>> str.center(30) ' hello '
- lstrip() 删除字符串左边的空白字符
>>> str = " hello " >>> str.lstrip() 'hello '
-
rstrip() 删除字符串右边的空白字符
>>> str = " hello " >>> str.rstrip() ' hello'
-
strip() 删除mystr字符串两端的空白字符
>>> str = " hello " >>> str.strip() 'hello'
- rfind() 类似于 find()函数,不过是从右边开始查找.
语法:
str.rfind(str, start=0,end=len(str) )
>>> str = " hello " >>> str.strip() 'hello'
-
rindex() 类似于 index(),不过是从右边开始. -
partition()把mystr以str分割成三部分,str前,str和str后
>>> str = "hello world hello world" >>> str.partition("world") ('hello ', 'world', ' hello world')
- rpartition() 类似于 partition()函数,不过是从右边开始.
>>> str = "hello world hello world" >>> str.partition("world") ('hello ', 'world', ' hello world')
- splitlines() 按照行分隔,返回一个包含各行作为元素的列表
>>> str = "hello world hello world" >>> str.partition("world") ('hello ', 'world', ' hello world')
-
isalpha() 如果字符串所有字符都是字母 则返回 True,否则返回 False
>>> str.splitlines() ['hello', 'world'] >>> str = 'python' >>> str.isalpha() True >>> str2 = '12abc' >>> str2.isalpha() False
- isdigit() 如果字符串所有字符都是数字 则返回 True,否则返回 False
>>> str = "123" >>> str.isdigit() True >>> str2 = "123abc" >>> str2.isdigit() False
- isalnum() 如果字符串所有字符都是字母或数字则返回 True,否则返回 False
>>> str = "123" >>> str.isalnum() True >>> str2 = "abc" >>> str2.isalnum() True >>> str3 = "123abc" >>> str3.isalnum() True >>> str4 ="abc 123" >>> str4.isalnum() False
-
isspace() 如果字符串中只包含空格,则返回 True,否则返回 False.
>>> str = "" >>> str.isspace() False >>> str2 =" " >>> str2.isspace() True >>> str3 = " " >>> str3.isspace() True >>> str4 = "abc 123" >>> str4.isspace() False
-
join() 字符串 中每个字符后面插入字符串 ,构造出一个新的字符串
>>> str = "" >>> str.isspace() False >>> str2 =" " >>> str2.isspace() True >>> str3 = " " >>> str3.isspace() True >>> str4 = "abc 123" >>> str4.isspace() False
其他:
字符串反转
>>> str = "hello world" >>> str[::-1] 'dlrow olleh'
分割字符串:
>>> str = "hello world \t heihei \t this is a test \t ni hao \npython" >>> str.split() ['hello', 'world', 'heihei', 'this', 'is', 'a', 'test', 'ni', 'hao', 'python']

 浙公网安备 33010602011771号
浙公网安备 33010602011771号