好题题集1
Intrinsic Interval
对于一排列 \(p_i\),定义“好区间”为值域连续的一段区间。
现给定一长为 \(n\) 的排列 \(p_i\),\(q\) 组询问,求包含区间 \(l...r\) 的最短好区间是哪个。
\(1 \le n,q \le 10^5\)
首先考虑求问题的弱化版:求一个排列的所有好区间。即经典题 Pudding Monsters。
对于一个排列来说,一段区间为好区间当且仅当 \(r - l = mx - mn\),其中 \(mn,mx\) 分别为区间最小值最大值。并且更重要的是,\(mx-mn \ge r - l\),于是我们只需要维护 \(mx-mn\) 的最小值,判断其是否为 \(r-l\) 即可。
具体实现类似 异或凑数那题,考虑移动右端点对所有左端点的影响。用线段树维护 \(mx-mn+l\) 的最小值及出现次数,用单调栈来维护 \(mx,m\) 即可。
回到原问题。一个比较显然的事实是:如果 \([l,r],[s,t]\) 均为好区间,且 \(l \le s \le r \le t\),那么 \([s,t]\) 也是好区间。因此包含 \(l...r\) 的最短好区间只有一个。我们只需要找到最先覆盖 \(l...r\) 的那个区间即可。
将询问挂在右端点上,扫到时取出。维护取出的询问的大根堆,以 \(l\) 为关键字。线段树上二分判断是否有解。有解下一个,无解直接退出。
复杂度:\(O(n \log n)\)
共
共价爷想构造一棵 $ N $ 个点的有根树,其中 $ 1 $ 号点是根。
显然的,对于一棵有根树,我们可以定义每个点的深度为,这个点到根的路径上点的个数(包括端点),也就是说,$ 1 $ 号点深度为 $ 1 $。
共价爷希望,深度为奇数的点的个数,刚好为 $ K $ 个。
他想知道有多少棵不同的满足条件的有根树,你只需要输出答案对 $ P $ 取模的结果。我们认为两棵树不同,当且仅当存在一对点 $ (i, j) $,满足 $ i $ 和 $ j $ 在一棵树中有边相连,而在另一棵树中没有边相连。
对于 $ 100% $ 的数据,$ 1 < K < N \(,\) N \leq 500000 $,当 $ N > 1000 $ 时,$ P $ 均为 $ 998244353 $。
看到奇偶要想一想二分图啊!!
树计数还是基尔霍夫矩阵树定理和prufer序列好使
考虑将奇数层的点分为左部图,偶数层的点分为右部图,分配完标号后,我们要解决的问题为:左部点为 \(1...n\),右部图为 \(n + 1...n + m\) 的带标号完全二分图的无根树生成树数量。即经典题 文艺计算姬
可以用基尔霍夫矩阵树定理大力推导,也可以用prufer序列得出。
prufer序列:
考虑左部图的点的总度数和为 \(n + m - 1\),右部点的总度数和也为 \(n + m - 1\),那么它们在 prufer 序列上的出现次数分别为 \(n + m - 1 - n = m - 1\) 和 \(n + m - 1 - m = n - 1\)。
注意到,当我们确定好左部图的点在 prufer 序列的相对位置,以及右部图的点在 prufer 序列的相对位置时,根据prufer转无根树以及二分图性质(边两端点一左一右)可知,唯一对应了一种无根树。于是构成了映射关系。答案为 \(n^{m-1} \times m^{n-1}\)。
所以原题的答案为 \({n - 1 \choose k - 1} \times k^{n-k-1} \times (n-k)^{k-1}\)
复杂度:\(O(n) + O(\log n)\)
价
人类智慧之神 zhangzj 最近有点胖,所以要减肥,他买了 $ N $ 种减肥药,发现每种减肥药使用了若干种药材,总共正好有 $ N $ 种不同的药材。
经过他的人脑实验,他发现如果他吃下去了 $ K(0 \leq K \leq N )$种减肥药,而这 $ K $ 种减肥药使用的药材并集大小也为 $ K $,这 $ K $ 种才会有效果,否则无效。
第 $ i $ 种减肥药在产生效果的时候会使 zhangzj 的体重增加 $ P_i $ 斤,显然 $ P_i $ 可以小于 $ 0 $。他想知道,一次吃药最好情况下体重变化量是多少,当然可以一种药也不吃,此时体重不变。
由于某些奥妙重重的情况,我们可以让这 $ N $ 种减肥药每一种对应一个其使用的药材,且 $ N $ 种减肥药对应的药材互不相同(即有完美匹配)。对于 $ 100% $ 的数据,$ 1 \leq N \leq 300, |P_i| \leq 1000000 $。
根据霍尔定理,如果二分图有完美匹配的话,左部图任选一集合,其对应的右部图集合不小于左部图的哪个集合。
考虑最大权闭合子图。但是只能保证右部图集合大于等于左部图集合。于是先跑一遍匹配求出方案,右向左连边,再跑一遍最大权闭合子图,这样就能保证左部图集合大于等于右部图集合了,此时左部图集合显然等于右部图集合。
显然得到的解均为合法解,并且可以证明合法解均可能被得到。
排序
给定一长为 \(n\) 的排列,以及 \(m\) 次操作。每次操作为将一个区间内的元素按升序或降序排序。问最后第 \(k\) 项的值。
\(1 \le n,m \le 100000\)
每次局部排序不太好维护(可能能用 ODT 维护?)
但是考虑到字符集只有 \(w\) 的序列可以通过 \(w\) 棵线段树实现单次排序 \(O(w \log n)\)。具体见A Simple Task。维护一下小于/大于当前字符的字符的个数,区间覆盖即可。
既然这道题最后只问第 \(k\) 项,我们可以二分答案 \(t\),通过最终 \(< t\) 的数的个数来判断(\(t\) 偏大时 \(<t\) 的数的个数不减)。这样,我们就只用对序列进行排序了,复杂度为 \(O(n \log n)\)
方格染色
\(n \times m\) 的网格,每个格子可以涂
R或者B。要求每个 \(2 \times 2\) 的格子中R和B的出现次数均为奇数。现已知 \(k\) 个格子的颜色,求在此前提下所有合法方案数。
\(1 \le n,m,k \le 10^5\)
其实是一类问题了。和 Appleman and Complicated Task 类似。这提示我们网格图除了想二分图,对偶图,插头DP以外,还可以想一想找规律(尤其是网格图染色计数)。
通常的规律是:确定一行/一列/一行一列/一个点以后整个网格图的方案就都确定了。当然有的题也可能是用较为可做的方法搞定 \((n-1) \times (m -1)\) 后剩下一行一列有且仅有一种方案使得整个网格图调整到合法,如 普及组
此题将 R 看作 1,将 B 看作 0 以后,限制为 \(2 \times 2\) 的格子的异或和均为1.
然后开始找规律。发现确定好一行一列后整个网格图就确定了。并且 \((x,y)\) 的值为 \(c(1,1) \oplus c(x,1) \oplus c(1,x) \oplus ([x \bmod 2 = 0] \cdot [y \mod 2 = 0])\)。枚举好 \(c(1,1)\) 后,问题转化为:\(x = 0,x = 1,x \oplus y = 0, x \oplus y = 1\) 四种操作。其中前两种操作可以转化为 \(x \oplus c(1,1) = v\)。的操作。于是高斯消元边带权并查集搞搞就好了。
复杂度:\(O(n \log n)\)
Euclid's nightmare
给定 \(n\) 个 \(m\) 维向量,每个向量只有 \(1\) 维或 \(2\) 维为 \(1\),其余为 \(0\)。规定向量的加减法对 \(2\) 取模。
问:
- 线性基大小
- 字典序最小的那种线性基的编号集合
- 最大异或和
\(1 \le n,m \le 5 \cdot 10^5\)
考虑模拟线性基。
只有一维为 \(1\) 的情况好说,判一下这一维有没有基向量,如果没有就插入。
如果有两维为 \(1\),假设 \(a\) 和 \(b\) 为 \(1\)。那么我们找到用当前已经插入的基向量能把 \(a\) 和 \(b\) 分别异或到哪里去。此处的“异或到”表示通过异或基向量,使得由 \(x\) 为 \(1\) 转化为 \(y\) 为 \(1\),且 \(y\) 这一维没有基向量。假设 \(a\) 被异或到了 \(c\),\(b\) 被异或到了 \(d\),那么我们就插入到 \(c\),并向 \(d\) 连一条边,表示其余向量如果 \(c\) 为 \(1\) 的话,可以被异或到 \(d\) 去。但是,有可能 \(a\) 异或着就变成 \(0\) 了(遇到了只有一维为 \(1\) 的基向量),那么说明 \(a\) 这个 \(1\) 可以被线性表出,我们就不用管它了,问题简化为只有一维为 \(1\) 的情况。
如果一直暴力走边,可能会变成 \(O(nm)\)。发现可以用类似并查集路径压缩的方法来解决这个问题。复杂度变为 \(O(n \log m)\)。
线性基大小好说。字典序最小也好说,当前能插就插即可。
最大异或和也还好,因为我们可以保证基向量除掉“当前维”(指这个基向量被插到了哪一维)以外的那个“附带维”一定小于“当前维“,或者没有”附带维“,这样的话就和普通线性基完全一样了。对”当前维“排序,贪心异或即可。
复杂度:\(O(n \log m)\)
语言
给定一棵 \(n\) 个点的树。给定 \(m\) 条链 \((s_i,t_i)\)。
对于每个点,求出其仅通过一条链能到达的点的数量。
\(1 \le n,m \le 10^5\)
考虑只问一个点 \(p\) 怎么做。此时仅需考虑过 \(p\) 的链。可以发现,答案为所有过 \(p\) 的链的 \(s,t\) 组成的点集的虚树的大小,可以用寻宝游戏的方法做。即 \(\sum_u dep(u) - \sum_{u,v}[u,v为dfn上相邻的点]dep(lca(u,v))\),其中第一个和最后一个也算相邻。
考虑用线段树维护虚树大小。对 \(dfn\) 建线段树,节点存仅考虑节点内的 \(dep\) 以及相邻点 \(dep(lca)\) 的贡献的答案。pushup 的时候顺便维护一下 \(dep(lca)\),最终记得把 第一个和最后一个的 \(dep(lca)\) 也减掉。
那么这道题基本上就算做完了。至于“只考虑过 \(p\) 的链”的限制,可以通过树上差分搞定。
复杂度:\(O(n \log^2 n)\),可以做到 \(O(n \log n)\)
Triple
有 \(n\) 个集合幂级数,每个集合幂级数只有三个位置有值,第 \(i\) 个集合幂级数 \(F_i\) 中 \(F_i(a_i) = x, F_i(b_i) = y, F_i(c_i) = z\)。其中 \(x,y,z\) 为常量,所有集合幂级数的 \(x,y,z\) 都一样。
现求将这 \(n\) 个集合幂级数做异或卷积以后的每一位的值。
\(1 \le n \le 2 \cdot 10^5,0 \le a_i,b_i,c_i < 2^k,1 \le k \le 17,0 \le x,y,z \le 10^9\)
首先有一个暴力 FWT 的做法,复杂度为 \(O(nk2^k)\),还不如暴力 DP。我们考虑优化。
我们不用每次都 IFWT,直接所有的做 FWT 最后乘完一起卷回来即可。复杂度仍为 \(O(nk2^k)\)。
发现复杂度瓶颈在 FWT 上。因为一个集合幂级数只有三个位置有值,我们可以直接根据 FWT 的公式:\(\hat{f}(S) = \sum_T (-1)^{|S \cap T|}f(T)\),可以做到单次 \(O(n)\) 的 FWT。复杂度成功优化到了 \(O((n+k)2^k)\)!终于和暴力 DP 一样了
考虑实质性的优化。发现我们最后要求的主要是这个东西:
发现 \(x,y,z\) 的系数组合只有八种可能,如果我们知道了这八种组合中每个组合的出现次数,就可以直接快速幂搞定了。
然而八种还是太多了,这里有一种简化的操作:每个三元组先强制选上 \(a_i\),然后再从 \(0,a_i \oplus b_i,a_i \oplus c_i\) 三种选择中选一种,最后输出答案的时候下标异或上 \(\bigoplus_i a_i\) 即可。这样,我们就将 \(a_i,b_i,c_i\) 转化为了 \(0,a_i \oplus b_i,a_i \oplus c_i\),第一项的系数一定为 \(1\)。八种组合简化为了四种组合。设
并且我们知道 \(c_1 + c_2 + c_3 + c_4 = n\),只要再知道三个方程就可以解出来了。
接下来的操作比较神奇:
看着 \(\prod\) 感觉很不爽,因为我们想要的是 \(\sum\)。如果我们知道 \(\sum_i (-1)^{|S \cap b_i|}y\),或者哪怕是 \(\sum_i (-1)^{|S \cap b_i|}\),我们就能再搞出个方程:\(c_1+c_2-c_3-c_4 = ...\) 了。
看到 \((-1)^{|S \cap b_i|}\),不难想到 FWT,或许我们可以找到某个集合幂级数,使得其 FWT 的结果是这个东西。构造一个集合幂级数 \(g\),其中 \(g(S) = \sum_i [b_i = S]\)。考虑 \(\hat{g}(S)\) 是什么东西:
正是我们想要的。同理,对于任意的 \(f(i)\),我们设 \(g(S) = \sum_i[f(i) = S]\),都有 \(\hat{g}(S) = \sum_i (-1)^{|S \cap f(i)|}\)。那么我们就可以令 \(f(i) = c_i\),就有了 \(c_1 - c_2 + c_3 - c_4 = ...\) 了就剩最后一个了。
我们打算在 \(\sum_i (-1)^{|S \cap b_i|} \times (-1)^{|S \cap c_i|}\) 上下手。因为这个东西等于 \(\sum_i (-1)^{|S \cap (b_i \oplus c_i)|}\),于是我们令 \(f(i) = b_i \oplus c_i\) 就可以得到 \(c_1 - c_2 - c_3 + c_4 = ...\)。
总结一下:
其中 \(A,B,C,D\) 都是可以求出的东西。那么我们就可以手动解方程得到 \(c_1,c_2,c_3,c_4\) 了。快速幂后 FWT 回去即可。
事实上,可以发现这个 \(A,B,C,D\) 是对 \(c_i\) 前面符号(正为 \(0\) 负为 \(1\))的状态 FWT 后的数组。于是可以拓展为 \(t\) 个位置有值的情况,并且不用高斯消元,只用对每个 \(S\) 的这些 \(A,B,C,D\) 进行 IFWT 即可。复杂度可以做到大约 \(O((k+t)2^{k+t})\)。题目
复杂度:\(O((k + \log n)2^k)\)
双倍经验:黎明前的巧克力
节日庆典
给定一长为 \(n\) 的字符串 \(s\)。对于每个前缀 \(1...i\),求出其循环移位的最小表示的开头(多解输出最前面)。
例如
abaacaba的答案是1 1 3 3 3 6 3 8\(n \le 3 \cdot 10^6\)
首先有一些 \(O(n^2)\) 的做法,比如俩指针的线性做法,以及 Lyndon 分解,不过对正解用处不大。
还有一个 \(O(n^2)\) 的做法:每个前缀只有最小的后缀,以及带着最小后缀作为前缀的那些后缀,有可能成为答案。维护一下这些就好了。比较求解的话可能需要一个 \(O(1)\) 求后缀与整个串的 LCP 的算法,可以 exKMP 预处理。
然而,这些不一定全部有用。一种比较显然的情况是有两个候选后缀 \(s,t\),其中 \(lcp(s,t) < \min(|s|,|t|)\),这时候已经能够知道它们的大小关系了,就可以把大的那个直接扔掉了,以后也不会用到了。然而复杂度仍然是 \(O(n^2)\),一个 aaaaaaaaa 就全卡满了。
还有一个特别妙的优化:如果两个后缀 \(s,t\),满足 \(|s| < |t| < 2|s|\),那么较短的那个串 \(|s|\) 不可能成为候选后缀。证明:
如果 \(|s| < |t|< 2|s|\),那么 \(t-s\) 是一个循环节。那么 \(s=uv,t=uuv\)。\(s\) 是候选后缀,至少要求存在一个串 \(w\),使得 \(s\) 接上 \(w\) 比 \(t\) 接上 \(w\) 要小。即:\(uvw < uuvw\),即 \(vw < uvw\),即 \(vw < sw\),而 \(v\) 是一个后缀,那么至少 \(v\) 就可以代替 \(s\) 成为最小后缀了。所以 \(s\) 不可能成为候选后缀。
这样,候选后缀就只有 \(O(\log n)\) 个了。总复杂度为 \(O(n \log n)\),可以通过此题。
Mr. Kitayuta's Gift
给定一个长为 \(m\) 的小写字母串 \(s\) 和一个正整数 \(n\)。
求 \(s\) 是多少个长为 \(n\) 的回文串 \(t\) 的子序列。
\(m \le 200,n \le 10^9\)
考虑DP。设 \(f(i,l,r)\) 表示回文串已经确定好了左边 \(i\) 个和右边 \(i\) 个,且尽可能匹配 \(s\) ,使得 \(s\) 剩下 \(l...r\) 的方案数。设 \(g(i)\) 表示回文串已经确定好了左边 \(i\) 个和右边 \(i\) 个,且匹配好了 \(s\) 的方案数。
当 \(s_l = s_r\) 时:
当 \(s_l \not= s_r\) 时:
\(g\) 的转移是 \(g(i) \to 26g(i+1)\)。
当 \(r-l \le 1\) 且 \(s_l = s_r\) 时有 \(f(i,l,r) \to g(i + 1)\)。
最终答案为 \(g(\lceil \frac{n}{2}\rceil)\)。
然后就可以 \(O(m^2n)\) 地转移了。
但是 \(n\) 很大,于是考虑矩阵快速幂,复杂度为 \(O(m^6 \log n)\)。
考虑开拓新思路。不易发现,我们的转移可以看作在一个自动机上跑,\(i+1\) 相当于跑一步。自动机上共有三种点,分别时 \(s_l=s_r\) 的“绿点”,\(s_l \not= s_r\) 的“红点”,以及 \(g\)(终点),图见xht博客。每一条从起始状态到终点的恰好跑了 \(\lceil \frac{n}2 \rceil\) 步的路径唯一对应着一种合法转移方案。
不难发现我们的转移的方案数的计算至于路径上的红绿点个数有关。如果我们能对每一种 \(i\) 个红点 \(j\) 个绿点的路径都算出来方案数的话,就不难得到答案了。不难发现 \(j=\lceil \frac{m-i}{2} \rceil\),于是路径数只有 \(O(m)\) 种。至于到底有多少条 \(i\) 个红点 \(j\) 个绿点的路径,可以DP解决。设 \(f(i,l,r)\) 表示从 \(l...r\) 状态开始继续往下跑,接下来(含自己)将会有 \(i\) 个绿点的路径条数。这个可以 \(O(m^3)\) 计算。
抽出 \(O(m)\) 种链后,我们得到了一个 \(O(m^4 \log n)\) 的方法。
考虑继续优化。发现这 \(O(m)\) 种链可以长得很像,于是可以直接放在一张自动机上一次跑完。图见xht博客,每种链的方案数体现在红点指向绿点的边上。(比较特殊的是,由于可能有的方案没有经过红点,我们的初始状态为第一个红点有一种方案,第一个绿点有 \(f(0,1,m)\) 种方案)
复杂度:\(O(m^3 \log n)\)。
常数优化:矩阵张的是半个三角,怎么矩乘也是半个三角,于是只用算 \(i \le k,k \le j\) 的情况。常数可以除以 \(6\)。
机场 / Airport
飞机场有 \(a+b\) 个停机位,其中 \(a\) 个停机位有登机桥连接飞机和候机厅,乘客可以通过登机桥直接由候机厅登上飞机;另外 \(b\) 个停机位没有登机桥和候机厅相连,所以乘客登机需要先搭乘摆渡车再登机。
毫无疑问,搭乘摆渡车的体验是非常差的,所以每位搭乘摆渡车的乘客都会产生不愉快度。
现在,给定每架飞机的乘客数量,登机时间和起飞时间;飞机需要在登机时间点选择一个空闲的停机位,在这个时间点内所有乘客会完成登机,然后飞机会一直停在该停机位,直到起飞时间;
若某飞机在时刻 \(x\) 起飞,则在时刻 \(x\) 该飞机所在的停机位是空闲的。
飞机场的管理层希望能够尽量减少乘客的不愉快度,为此飞机在登机时间到起飞时间之间,可以切换停机位;切换也会产生不愉快度,如果该飞机有 \(x\) 位乘客,那么切换所产生的不愉快度为 \(\lfloor p \cdot x \rfloor\)
假设某飞机从 \(x\) 时间开始由停机位 A 切换到停机位 B,那么停机位 A 在 \(x+1\) 时间是空闲的。能进行这样的切换当且仅当停机位 B 在 \(x+1\) 时间是空闲的。
\(1 \le a,n \le 200,b=10^9,0 < p < 1\),保证有解
这是个常见的网络流模型,建议记住,可以用于应对“占用...”的问题。
将“时间点”看作边,建费用流:
将时间拉成一串,对每个时间点建一条边,边的容量为 \(a\),表示每个时间点的“登机桥”最多有 \(a\) 架飞机。
对于每个飞机,有三种选择:
- 不占用“登机桥“,花费为 \(x\)
- 一直占用”登机桥“,花费为 \(0\)
- 在 \(s\) 时刻占用”登机桥“,然后迅速切换走,花费为 \(px\)
占用”登机桥“可以体现为消耗流量,从主链上分走 \(1\) 的流量。
统一减去 \(x\) 的花费后,如下图:
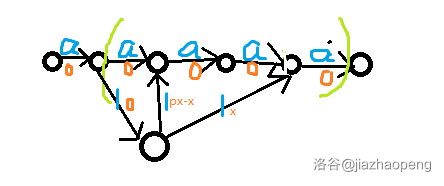
跑最小费用可行流即可。
Do you like query problems?
有 \(n\) 个数 \(a_i\),初始为 \(0\)。\(Q\) 次操作,共三种操作:
1 l r v: 对于区间 \(l...r\),\(a_i = \min(a_i,v)\)2 l r v: 对于区间 \(l...r\),\(a_i = \max(a_i,v)\)3 l r v: 对于区间 \(l...r\),将 \(a_i\) 累加到答案 \(ans\) 中。令 \(0 \le v < m\),求所有 \((\frac{n(n+1)}{2}(2m+1))^Q\) 种可能的操作的答案的和模 \(998244353\)。
\(1 \le n,m,Q \le 2 \cdot 10^5\)
考虑求所有可能的操作的答案的期望。
分拆贡献至第 \(i\) 个数第 \(j\) 次对答案的贡献。第 \(i\) 个数第 \(j\) 次有贡献,必须要第 \(j\) 次为询问且包含 \(i\)。然后考虑贡献的期望即可。即:
考虑求 \(E(a_{i,j})\)。根据套路,\(E(a_{i,j}) = \sum_{k=0}^{m-1}P(a_{i,j} > k)\)。因为只有区间取 \(\min\) 和区间取 \(\max\) 操作,\(a_{i,j}\) 的值只与前 \(j-1\) 次操作中最后一次作用到它且改变了它的操作。我们规定“改变”指 \(\min\) 操作中 \(v < a_{i}\),\(\max\) 操作中 \(v \ge a_i\)(其它的规定其实也是可以的),那么一次操作作用到它且改变它的值的概率为 \(\frac{i(n-i+1)}{\frac{n(n+1)}{2}} \cdot\frac{m}{2m+1}\),设其为 \(p\)。那么 \(P(a_{i,j} > k)\) 为在 之前曾经有过作用到它且改变它的值的操作 且最后一次这种操作的 \(v>k\)。
最后化简一下就好了。
复杂度:\(O(n \log n)\)
Simple Math 3
给定四个整数 \(A,B,C,D\),求所有满足以下条件的 \(i\) 的个数:
- \((A+B \cdot i)...(A+C \cdot i)\) 中不含 \(D\) 的倍数。
\(T \le 10^4,2 \le D \le 10^8, 0 \le B < C < D,1 \le A < D\)
不难发现,\(i\) 的上界为 \(\lfloor \frac{D-1}{C-B} \rfloor\),再大的 \(i\) 必然导致 \((A+B \cdot i) ... (A + C \cdot i)\) 中含有 \(D\) 的倍数。
注意到 \(i \le \lfloor \frac{D-1}{C-B} \rfloor\) 的时候,\((A + B \cdot i) ... (A + C \cdot i)\) 最多只包含 \(1\) 个 \(D\) 的倍数。
那么可以考虑容斥,计算 \((A + B \cdot i) ... (A + C \cdot i)\) 中含有 \(D\) 的倍数的 \(i\) 的个数,就相当于计算 \((A + B \cdot i)...(A + C \cdot i)\) 中 \(D\) 的倍数的个数。即:
扩欧计算即可。
复杂度:\(O(T\log D)\)
Stranger Trees
给定一棵 \(n\) 个点的无权无向树,对于每个 \(0 \le k < n\),求出这 \(n\) 个点的所有生成树中恰好与这棵树有 \(k\) 条边重合的方案数。
\(1 \le n \le 100\)
经典老题了。
又是生成树计数,考虑 prufer 序列或者基尔霍夫矩阵树定理。
根据套路,将这棵树上的边的边权设为 \(x\),其余设为 \(1\),然后根据基尔霍夫矩阵树定理得出的所有生成树边权积的和,其中的 \(i\) 次项为有 \(i\) 条边重合的方案数。
然而这样做非常麻烦。考虑到这个多项式只有 \(n\) 项,我们可以计算 \(n\) 个点值,然后插值得到答案多项式。
复杂度:\(O(n^4)\)
calc加强版
一个序列 \(a_i\) 是合法的,当且仅当:长度为 \(n\) ,值域为 \([1,K]\) 且互不相同。
一个合法序列的权值定义为 \(\prod_{i = 1}^n a_i\)。
给定 \(m,K\),对于所有的 \(n \le m\) 求所有合法序列的权值和。
\(1 \le m \le 5 \cdot 10^5, 1 \le K \le 10^9,tl=3s\)
对每个值单独考虑,最后拼接。因为拼接的时候需要分配位置,所以应该使用 EGF。考虑每个值的 EGF 为 \(1+kx\),那么答案应该是 \(\frac1{n!}[x^n]\prod_{k=1}^K (1+kx)\)。
但是 \(K\) 太大了,我们无法用分治 FFT 计算。
我们猜想把 \(\prod\) 换成 \(\sum\) 或许会好些,考虑使用 付公主的背包 的方法,求 \(\ln\) 后 \(\exp\)。
那么有:
然后转化 \(\prod\)
如果我们能够快速求出所有的 \(\sum_{k=1}^Kk^i\),那么就可以直接 exp 得到答案了。
这个东西其实就是要求 \(n\) 个自然数幂和,可以用高斯消元或拉格朗日插值或伯努利数或斯特林数搞定,但复杂度都很高。
考虑 \(\sum_{k=1}^K k^i\) 对 \(i\) 的生成函数。
如果使用 OGF,那么应该是 \(\sum_i \sum_{k=1}^K k^i x^i = \sum_{k=1}^K \frac{1}{1-kx}\),看起来不好搞。
如果使用 EGF,那么应该是 \(\sum_i \sum_{k=1}^K \frac{k^ix^i}{i!} = \sum_{k=1}^K e^{kx} = \dfrac{e^{(K+1)x}-1}{e^x-1}\),可以用求逆搞定。但是分母的常数项为 \(0\),没有逆元。不过分子的常数项也为 \(0\),于是分数上下两边同时除以 \(x\),值仍然不变。于是我们得到了一种 \(O(n \log n)\) 的做法。
总复杂度:\(O(n \log n)\),常数顶个 \(\log\)
Prime Flip
有 \(10^{100}\) 枚硬币,其中 \(n\) 枚硬币正面朝上,分别在 \(x_1,x_2,...,x_n\),其余反面朝上。
每次可以选择一个区间 \([l,r]\),将区间内所有硬币翻转,要求 \(r-l+1\) 为奇素数。
求最少需要多少次才能使得所有硬币反面朝上。
\(1 \le n \le 100,1 \le x_i \le 10^7\)
区间异或可以通过经典套路差分转化为两点异或。(注意不是前缀和,区间加在前缀和数组上的表现为加等差数列)而差分后为 \(1\) 的位置不超过 \(2n\)。
不难发现我们的所有决策都可以看作两个两个地消掉。那么我们可以预处理出来两两之间消掉的最小代价,那么跑一遍一般图最大权匹配即为答案(但是我不会)。
通过手玩不易发现,对于两个相距 \(d\) 的点,如果 \(d\) 为奇素数,那么代价为 \(1\);如果 \(d\) 为偶数,那么当 \(d > 4\) 的时候,根据哥德巴赫猜想(一个 \(>4\) 的偶数一定能拆成两个奇素数的和)在 \(10^7\) 内被验证为正确,可得代价为 \(2\),而 \(d \le 4\) 的偶数也不难得到代价为 \(2\);如果 \(d\) 为奇合数,那么代价为 \(3\)(至少可以先加 \(3\) 变为偶数,然后偶数代价为 \(2\))
注意到奇数的情况两点一定一奇一偶,偶数一定同奇偶。于是贪心:尽可能的用奇素数,然后用偶数,最后用奇合数(这个最多只会用一次)。这个不难证明。
而奇素数的情况因为一奇一偶,可以通过二分图匹配来得到。剩下的就好说了。
地震后的幻想乡
给定一张 \(n\) 个点 \(m\) 条边的无向图,每条边的边权在 \([0,1]\) 内均匀随机分布。求最小生成树的最大边权。
\(1 \le n \le 10,1 \le m \le \frac{n(n-1)}{2}\)
为什么一到状压我就不会啊/kk 不过这道题是卡在了概率期望那里了。
首先有一个结论:\(n\) 个 \([0,1]\) 均匀随机变量的第 \(k\) 大的期望为 \(\frac{k}{n+1}\),证明见这里或者这里。最好当常识背过。
那么答案就是:
那么考虑如何求 \(\sum_{边的相对大小}P(选前i小的边后恰好连通)\)。首先“恰好”不好处理,一步差分后转化为 \(P(选前i-1小没连通)-P(选前i小还是没连通)\)。考虑求 \(P(选前i小没连通)\)。考虑从小到大加边,由于所有(边集)从空集到大小为 \(i\) 的方案数都是等概率的(虽然可能克鲁斯卡尔的时候我们可能加了一半停下来了,但是如果从”从小到大加边“的角度看确实是这样的),且总方案数为 \({m \choose i}\),那么我们只需要求出从 \(m\) 条边中选 \(i\) 条边,且这 \(i\) 条边连通的方案数。这个相比之前的过程来说要简单得多。
类似有标号无向连通图计数的方法,我们设 \(f(S,i)\) 表示选了 \(i\) 条 \(S\) 内的边,让 \(S\) 连通的方案数。其中 \(S\) 为点集。类似地,设\(g(S,i)\) 表示选了 \(i\) 条 \(S\) 内的边,让 \(S\) 不连通的方案数。那么有 \(f(S,i) + g(S,i) = {c(S) \choose i}\),其中 \(c(S)\) 为 \(S\) 内的边数。现在我们只需要挑一个好算的来计算即可。
注意到 \(g(S,i)\) 好递归计算。枚举 \(S\) 中编号最小的那个点所在连通块及其内部的边数。那么有转移:
然后答案即为:
其中 \(U\) 为全集。
复杂度:\(O(m^23^n)\),不过有个小常数。
加特林轮盘赌
\(n\) 个人轮流做游戏,从 \(1\) 开始,每个人有 \(p\) 的概率死亡出局,有 \(1-q\) 的概率存活。一直到只剩下一个人。
给定 \(n,p,k\),求最终第 \(k\) 个人存活的概率。
\(1 \le n \le k \le 10000,0 < p < 1\)
难点在于前缀和优化。
设 \(f(n,i)\) 表示 \(n\) 个人的游戏中第 \(i\) 个人最终存活的概率,\(g(n,i)\) 为 \(n\) 个人的游戏中 \(i\) 为第一个死亡的人的概率。
那么有:
由此得到一个 \(O(n^3)\) 的做法。
考虑前缀和优化。一般情况下转移中含有类似 \(f(i-j)\) 的东西是不好前缀和优化的。但是发现 \(g(n,j) \cdot (1-p) = g(n,j+1)\),即可以通过乘 \(1-p\) 让 \(g\) 的下标统一加 \(1\)。那么就可以快速求 \(i\) 增加 \(1\) 的结果了。
game
有 \(n\) 个点,一部分为黑点,剩余为白点。有 \(m\) 条无向边,每条边连接着一个黑点和一个白点(即图有二分图性质)。两人博弈。
随机钦定某个点为起点,先后手轮流操作,每次沿着一条无向边走到一个之前没有到过的点。没法走的人输。
对于每个点,询问以这个点为起点,是否先手必胜。
\(1 \le n,m \le 20000\)
不难推测每个点是否先手必胜和二分图有关。
有一个结论:如果一个点是二分图的必须点,即每一种最大匹配方案中这个点都被匹配了,那么这个点先手必胜,否则先手必败。
证明必须点先手必胜:先手从这个点 \(x\) 向匹配边走到另一个点 \(y\),如果 \(y\) 没有其余边,则先手胜;否则后手从 \(y\) 走向 \(z\),那么先手可以从 \(z\) 走向 \(z\) 的匹配边。不难证明 \(z\) 一定有匹配边,否则 \(x -y\) 可以被替换为 \(y-z\),\(x\) 不是必须点。
证明非必须点先手必败:先讲最大匹配的图调整为 \(x\) 没有匹配的情况。如果 \(x\) 没有出边,则先手必败;否则,假设 \(x\) 有一条出边为 \(y\),那么后手可以走 \(y\) 的匹配边。不难证明,\(y\) 一定有匹配边,否则存在 \(x - y\),当前匹配不是最大匹配。
于是问题转化为找出二分图的所有必须点和非必须点。
用网络流随意找一组最大匹配。因为非必须点要么是没匹配的点,要么是可以被其余点替换的点。于是从 \(s\) 出发尝试增广(肯定会失败,但是可以知道哪些点可以被增广),经过的左部点为非必须点;从 \(t\) 出发尝试反向增广,经过的右部点为非必须点。
Nezzar and Hidden Permutations
要求构造两个长度为 \(n\) 的排列 \(a_i,b_i\)。给定 \(m\) 条限制 \((p_i,q_i)\),要求在这两个排列中 \((p_i,q_i)\) 的大小关系相同。要求最大化 \(a_i \not= b_i\) 的 \(i\) 的数量。
\(1 \le n,m \le 5 \cdot 10^5, tl = 5s\)
首先可以把问题抽象成图论模型。排列的每个位置对应一个点,每条限制对应一条无向边。我们要给每个点赋 \(a_i,b_i\) 两个值,要求 \(a_i,b_i\) 各自构成排列且 \(a_i = b_i\) 的点尽可能小。
不难发现,如果一个点满度了,它和其它的所有点都有连边,那么这个点一定只能 \(a_i = b_i\)。
现在我们只需考虑不存在满度点的情况了。可以证明,一定存在一种方案使得这些点 \(a_i \not= b_i\)。
Solution1(jzp)
考虑到如果 \(u,v\) 没有连边,那么我们可以将 \(u\) 设为 \(1\),将 \(v\) 设为 \(2\),并且在第二个排列中交换这两个数,然后删除这两个点。然后就可以递归到一个点数为 \(n-2\) 的情况了。(注意,这里的 \(1\) 指的是最小的值)
然而发现这样会出错,有可能删去这两个点以后,其它点中存在一些点就变成了”满度“点。那么考虑优先删除点度数较大的点。
找到当前点度数最大的那个点 \(u\)。如果点度数为 \(n-2\),那么一定只含有一个没有和它连边的点 \(v\)。如果我们按照上面的方法做的话,可能存在其它点 \(p\),原来度数为 \(n-2\),没有和 \(v\) 连边,删除 \(u,v\) 之后 \(p\) 就成满度点了。那么我们找出所有的这样的 \(p\),将 \(u,p_1,p_2,..,p_k,v\) 设为 \((1,2,3,...,k+1,k+2)\) 和 \((2,3,4,...,k+2,1)\),然后删除掉这些点。可以证明这样做一定合法,且不会再有其余的点的度数变为 \(n-2\)。
如果点 \(u\) 度数为 \(n-3\),那么会有两个没有和它连边的点 \(v,w\)。这时我们尝试按照开头的方法做,删去 \(u,v\) 的话,可能会有 \(w\) 的度数为 \(n-3\),且 \(v,w\) 之间没有连边,删去 \(u,v\) 后 \(w\) 成为满度点。这时我们假装连上 \(u,v\),问题变为 \(u\) 的度数为 \(n-2\) 的情况了。
如果点 \(u\) 度数小于 \(n-3\),那么剩余点的度数至多为 \(n-4\)。找到任意一个没有与 \(u\) 连边的点 \(v\),按照开头的做法删去 \(u,v\) 即可。不难证明不存在剩余点的度数变为 \(n-1\) 的情况。
复杂度:\(O((n+m) \log n)\),代码量和常数巨大
Solution2(std)
找到任意一个补图的生成森林。不难发现每个连通块大小至少为 \(2\)。
对于一个菊花(star),那么找到其中心 \(u\),其余点 \(p_1,p_2,...,p_k\),可以设 \(u,p_1,p_2,...,k\) 为 \((1,2,3,...,k+1)\) 和 \((k+1,1,2,...,k)\)。然后可以把这个菊花删掉递归子问题。
如果我们能够将每一棵树划分为若干大小至少为 \(2\) 的菊花,那么就可以依次删除了。
具体来说,找到一个没有被划分过的点 \(p\),如果 \(p\) 的邻居中存在没有被划分过的点,那么可以将 \(p\) 和 \(p\) 的所有没有被划分过的点都划分为一个菊花;否则,\(p\) 的邻居都为划分过的点,且都不是菊花的中心。找到任意一个邻居 \(q\),如果 \(q\) 所在菊花大小为 \(2\),那么将 \(q\) 设为菊花的中心,将 \(p\) 划进去;否则将 \(q\) 从 \(q\) 所在菊花中删除,\(p,q\) 组成一个菊花。
复杂度:\(O((n+m) \log n)\),瓶颈在于找到补图的生成森林。
附上std的找补图生成森林的代码:
set<int> rv; // remained vertices
set<int> g[maxn]; // original graph
set<int> t[maxn]; // dfs tree
void dfs(int u){
rv.erase(u);
int crt=0;
while (1){
auto iter=rv.upper_bound(crt);
if (iter==rv.end()) break;
int v=*iter;
crt=v;
if (g[u].find(v)!=g[u].end()) continue;
t[u].insert(v), t[v].insert(u);
dfs(v);
}
}
...
for (i = 1 -> n) rv.insert(i);
while(rv.size() > 0) dfs(*(rv.begin()));
寿司晚宴
有 \(n\) 个点,要取 \(m\) 次,第 \(i\) 次取可以选择一个位置 \(p\)(可以为空),向左或向右取第一个点,取完后那个位置就为空了。要求每次都必须取到点。给定 \(n,m\),问合法方案数。
\(1 \le m \le n \le 10^5\)
接链成环。我们在序列后面新加一个虚拟节点,然后把第一个点和最后那个虚拟节点连起来成一个大小为 \(n+1\) 的环。每次我们可以选择一个位置顺时针或者逆时针选一个位置,取点,这样的话每次都能取到一个点。但是我们要求不能取到虚拟节点,于是我们可以这样看:一开始暂时不确定环的编号起点,随便编一个;然后开始取,最终从剩下的 \(n-m+1\) 个点中钦定一个作为虚拟节点。这样的话方案数为 \(2^m(n+1)^m(n-m+1)\),但是发现每一个起点都会把答案算一遍,于是最终除一个 \(n+1\),即答案为 \(2^m(n+1)^{m-1}(n-m+1)\)。
复杂度:\(O(\log m)\)。理解的还不是很透。
情侣?给我烧了!
有 \(n\) 对情侣和 \(2n\) 个座位,相邻两个座位为一对。每个人随意挑一个座位坐下,问这 \((2n)!\) 种方案种恰有 \(k\) 对情侣成功配对的方案数。\(T\) 组询问。
\(1 \le T \le 2 \cdot 10^5,1 \le n \le 5 \cdot 10^6\)
不难发现问题实质上是问 \(n\) 对情侣的问题中全部都没有配对的方案数。
这是一个类似错排数的模型。我们可以枚举第一个座位上的人,然后再枚举其旁边的人,要求这两个人不能是一对。这个的方案数为 \(2n \cdot (2n-2)\)。但是还不能直接递归,因为两个人的配偶还没有安排妥当。两个人的配偶共有两种方案,即配对或不配对。如果配对,那么我们需要给这俩人安排座位,方案数为 \(2 \cdot (n-1)\);否则,我们要求这两个人不能配对,这个要求相当于对情侣的要求,于是直接把这两个人看作一对情侣,递归为 \(n-2\) 的子问题。
复杂度为 \(O(n+T)\)
猜数游戏
对于一个 \(n\) 个数的集合 \(S\),每次你可以选择一个数 \(a_i\),将这 \(n\) 个数中可以被表示成 \(a_i^k \bmod P\) 的数删去。将这个集合删空的最小次数即为 \(f(S)\)。
给定 \(n\) 个互不相同的数 \(a_i\),求其所有 \(2^{n}-1\) 个非空子集的 \(f\) 值的和。
\(1 \le n \le 5000,P \le 10^8,1 \le a_i < P\),且 \(P\) 可以为素数或 \(P=q^k\),其中 \(q\) 为奇素数。
\(tl=2s\)
先考虑素数的情况。每个数都可以被表示为 \(g^t\),其中 \(g\) 为原根。那么选一个 \(g^t\),所有 \(g^{kt}\) 都将被删掉。准确地说,是所有 \(g^{k \cdot \gcd(t,\varphi(P))}\) 都将被删掉。那么我们的贪心策略即为根据 \(\gcd(t,\varphi(P))\) 从小到大排序,如果不能被表示出来,就选它,花费 \(1\) 的代价。
考虑贡献。枚举 \(g^t\),那么如果 \(g^t\) 想要有贡献, \(g^{d},d|t\) 都不能选,其余任意。总复杂度:\(O(n\sqrt P + n^2)\)
考虑 \(q^k\) 的情况。这时候可能会存在有些数不能被表示为 \(g^t\) 的情况。这些数肯定是 \(qp^t\) 的形式,不难发现这些数和 \(g^t\) 的那些数互相独立。并且这些数乘方多次很容易为 \(0\)(大概是 $\log $ 次)。于是仍然考虑贡献,要求不能选能乘方成这个数的数即可。
复杂度:\(O(n \sqrt P + n^2 \log n)\)。由于各OJ跑得很快,于是可以水过(顺便拿到了UOJ最慢)
Broot
已知 \(x^k = b \pmod P\)。给定 \(k,b,P\),求所有可能的 \(x\)。
\(0 \le k,b,P \le 10^{12}\),\(P\) 为素数,且可能的 \(x\) 不超过 \(10^6\)。(原题面的范围更大,但是实测只有这点)
如果学过 N次剩余,那这题肯定不难。但是如果没有学过,这题也并不是不可做。
注意到 \(x^k \equiv b\) 不好解决,但是既然 \(P\) 为素数,我们可以求出原根,然后转化为形如 \(xk \equiv b\) 的问题。这个问题是可以用 exgcd 轻松解决的。
于是可以先求原根 \(g\),然后 BSGS 求出 \(b=g^t\) 中的 \(t\),假设 \(x=g^d\),那么 \(dk \equiv t \pmod {\varphi(P)}\),套用 exgcd 解决即可。
复杂度 \(O(\sqrt P \log P)\)(需要龟速乘)
表达式求值
定义二元操作符
<:对于两个长度都为 \(n\) 的数组 \(A, B\)(下标从 \(1\) 到 \(n\)),\(A\)<\(B\) 的结果也是一个长度为 \(n\) 的数组,记为 \(C\)。则有 \(C[i] = \min(A[i], B[i])\)(\(1 \le i \le n\))。定义二元操作符
>:对于两个长度都为 \(n\) 的数组 \(A, B\)(下标从 \(1\) 到 \(n\)),\(A\)>\(B\) 的结果也是一个长度为 \(n\) 的数组,记为 \(C\)。则有 \(C[i] = \max(A[i], B[i])\)(\(1 \le i \le n\))。现在有 \(m\)(\(1 \le m \le 10\))个长度均为 \(n\) 的整数数组 \(A_0, A_1, \ldots , A_{m-1}\)。给定一个待计算的表达式 \(E\),其满足 \(E\) 中出现的每个操作数都是 \(A_0, A_1, \ldots , A_{m-1}\) 其中之一,且 \(E\) 中只包含
<和>两种操作符(<和>的运算优先级相同),因此该表达式的结果值也将是一个长度为 \(n\) 的数组。特殊地,表达式 \(E\) 中还可能出现操作符
?,它表示该运算符可能是<也可能是>。因此若表达式中有 \(t\) 个?,则该表达式可生成 \(2^t\) 个可求确定值的表达式,从而可以得到 \(2^t\) 个结果值,你的任务就是求出这 \(2^t\) 个结果值(每个结果都是一个数组)中所有的元素的和。你只需要给出所有元素之和对 \({10}^9 + 7\) 取模后的值。\(1 \le n \le 5 \times {10}^4\),\(1 \le m \le 10\),\(|S| \le 5 \times {10}^4\),\(1 \le A_i[j] \le {10}^9\)。
(果然还是没想到状压)
首先不难做到 \(O(n)\) 建表达式树,并且 \(n\) 个下标互不影响,于是可以 \(O(nm^2|S|)\) 地DP(设 \(f(x,i)\) 表示 \(x\) 子树的结果是 \(A_i\) 的方案数),然而无法通过此题。
观察到 \(m\) 太小,不难想到对 \(m\) 进行状压,毕竟 \(O(2^m|S|)\) 或者 \(O(2^mn)\) 是可以接受的。考虑类似排序那题的模型,对 \(1 \le A_i[j] \le 10^9\) 不好做,但是对 \(0 \le A_i[j] \le 1\) 还是比较好做的。于是对于某一个位置(下标),我们可以求出答案大于等于 \(A_i[j]\) 的方案数,即将 \(A_i[j]\) 转化为 \(0/1\),最后答案为 \(1\) 即为答案大于等于 \(A_i[j]\),这样我们的DP状态的第二维就只有常数了(\(f(x,0/1)\) 表示 \(x\) 子树的结果是 \(0/1\) 的方案数),最关键的是DP状态不需要关心 \(A_i[j]\) 的具体值。这样的话我们就可以 \(O(n|S| \cdot m)\) 了。
然而还是过不去,但是考虑 \(A_i[j]\) 变成的 \(0/1\) 总共只有 \(O(2^m)\) 种,于是可以直接对于每种 \(A_i[j]\) 的 \(0/1\) 情况都预处理一遍。复杂度:\(O(2^m|S| + nm)\)
括号路径
给定一张 \(n\) 个点 \(2 m\) 条边的有向图,图中的每条边上都有一个标记,代表一个左括号或者右括号。共有 \(k\) 种不同的括号类型,即图中可能有 \(2 k\) 种不同的标记。点、边、括号种类均从 \(1\) 开始编号。
图中的每条边都会和另一条边成对出现。更具体地,若图中存在一条标有第 \(w\) 种括号的左括号的边 \((u, v)\),则图中一定存在一条标有第 \(w\) 种括号的右括号的边 \((v, u)\)。同样地,图中每条标有右括号的边将对应着一条反方向的标有同类型左括号的边。
现在请你求出,图中共有多少个点对 \((x, y)\)(\(1 \le x < y \le n\))满足:图中存在一条从 \(x\) 出发到达 \(y\) 的路径,且按经过顺序将路径各条边上的标记拼接得到的字符串是一个合法的括号序列。
\(1 \le n \le 3 \times {10}^5\),\(1 \le m \le 6 \times {10}^5\),\(1 \le k, u, v \le n\),\(1 \le w \le k\)。
发现 \(u \to v\) 和 \(w \to v\) 同色的话,可以把 \(u,w\) 合并。不难证明合并 \(u,w\) 后如果有 \(u \to x\) 是合法路径,那么 \(v \to x\) 也是合法路径。于是合并后的节点内的所有点都是互相可达的。最终答案为合并后所有点的 \({siz \choose 2}\)。
实现大概为并查集+队列+启发式合并或线段树合并。
这题和儒略日一样,想好了写一百行不到,想不好就一百多行并且常数巨大狂T不止。
复杂度:\(O(n \log n)\) 或者 \(O(n \log^2 n)\)
Duff as a Queen
给定一长为 \(n\) 的序列 \(a_i\),\(q\) 次操作:
1 l r k:将区间 \([l,r]\) 异或上 \(k\)
2 l r:询问区间 \([l,r]\) 的线性基大小。\(1 \le n \le 2 \cdot 10^5,1 \le q \le 4 \cdot 10^4, 1 \le a_i \le 10^9, tl = 7s\)
其实是区间加,区间 \(\gcd\) 的拓展。
注意到 \(a_1,a_2,a_3\) 的线性基和 \(a_1, a_1 \oplus a_2,a_2 \oplus a_3\) 的线性基是一样的,而后面的部分 \(a_1 \oplus a_2,a_2 \oplus a_3\) 是 \(a_i\) 的差分数组。于是直接在差分数组上维护即可。复杂度:\(O(n \log^2 n + q \log^3 n)\)
值得注意的是,直接线段树打异或 tag,把线性基中的数都取出来异或后再加进去的算法是错误的。举个简单的例子,可能原来 \(a_1 \oplus a_2 = a_3\),于是我们扔掉了 \(a_3\);但是现在 \(a_1 \oplus k \oplus a_2 \oplus k \not= a_3 \oplus k\),于是现在 \(a_3\) 又可以加进来了。可见上述做法为错误的。
Intergalaxy Trips
\(n\) 个点的有向图,任意 \(i,j\) 均有连边。其中 \(i \to j\) 每天出现的概率为 \(p_{i,j}\),保证 \(p_{i,i}=1\)。每天需要选择一条边走出去。问最优策略下从 \(1\) 走到 \(n\),平均最少要花几天。
\(1 \le n \le 1000\)
这种题看起来无从下手,纵使我们能够写出一个DP式子,也不知道怎么转移。
设 \(f(x)\) 表示从 \(x\) 走到 \(n\) 的最优策略期望时间。那么如果一天中与 \(x\) 相连的边集 \(S\) 出现了,我们应该走 \(S\) 中期望时间最小的那个,即 \(f(x) = \sum_S P(S) \cdot minf(S)\)。然而时间复杂度绝对过不去,并且 \(f\) 大部分都不知道,没办法转移。
注意到 \(f(n) = 0\),我们可以从这里着手,贪心地去决策其余点。假设 \(p_{x,n}\) 为连向 \(n\) 的边中最大的那个概率,那么 \(x\) 要么会向 \(n\) 走,要么原地不懂。于是可以算出 \(f(x) = \frac1{p_{x,n}}\)。对于一个点 \(x\),假设其有 \(p\) 的概率到点 \(y\),有 \(q\) 的概率到点 \(z\),且 \(f(z) < f(y)\),\(x\) 仅有这两条出边,那么 \(f(x) = 1 + pf(z) + (1-p)(qf(y) + (1-q)f(x))\)。我们可以维护类似这样的东西,每次取期望最小的那个点,去更新别的点。发现和 Dijkstra 算法类似。
复杂度:\(O(n^2 \log n)\),去掉堆优化,每次暴力找最小点,复杂度为 \(O(n^2)\)。
Square Constraints
给定正整数 \(n\),求满足
\[n^2 \le i^2 + P_i^2 \le (2n)^2 \]的排列数。
下标、数值从 \(0\) 开始。
\(1 \le n \le 250\)
不难发现,每个位置对应一个上界 \(R_i\) 和一个下界 \(L_i\)。没有下界还是很好做的,我们按 \(R_i\) 从小到大排序,依次决定,那么第 \(i\) 个的方案数为 \(R_i - i\)(因为 \(0...i-1\) 各占用一个位置)。
二项式反演/子集反演,设 \(g_i\) 表示钦定 \(i\) 个位置小于 \(L_i\),那么答案为 \(\sum_k (-1)^k g_k\)。
考虑DP求解 \(g_k\)。设 \(f(i,j)\) 表示准备考虑第 \(i\) 个,\(0...i-1\) 中有 \(j\) 个小于 \(L_i\) 的方案数。然而仍然不好转移。
注意到 \(L_i,R_i\) 均递减,\(n...2n-1\) 中 \(L_i = 0\),且 \(R_{n-1} \ge L_0\),即左半边的 \(R\) 永远比 \(L\) 大。
我们可以对于 \(0...n-1\),按照 \(L_i - 1\) 排序,\(n...2n-1\),按照 \(R_i\) 排序后DP。然后考虑计算方案时先决定 \(0...n-1\) 中选 \(L_i\) 的和 \(n...2n-1\),再决定 \(0...n-1\) 中选 \(R_i\) 的,但是DP时按照排序后的数组DP。
假设之前 \(0...i-1\) 中有 \(c_l\) 个前半部分,\(c_r\) 个后半部分。如果当前为 \(n...2n-1\),那么所有之前选的(上界为 \(L_i\) 的前半部分 + 后半部分)都会妨碍到它,方案数为 \(R_i + 1 - j - c_r\);如果当前为 \(0...n-1\),选上界为 \(L_i - 1\) 的方案同理,为 \(L_i - c_l - j\),选上界为 \(R_i\) 的方案为所有的 \(k\) 个选 \(L_i\) 的,和所有的右半部分,和之前选 \(R_i\) 的部分,方案数为 \(R_i + 1 - k - n - (c_l - j)\)。
最终答案为 \(f(2n,k)\),复杂度 \(O(n^3)\)。
划艇
长为 \(n\) 的序列,每个位置有一个上界 \(R_i\) 和下界 \(L_i\)。
问有多少种方案,使得每个位置要么不选,要么在 \(L_i\) 和 \(R_i\) 之间,且选择的部分严格递增。
\(1 \le n \le 500,1 \le L_i \le R_i \le 10^9\)
有一个显然的 \(O(n^2R_i)\) 的DP:设 \(f(i,j)\) 表示决策了前 \(i\) 个位置,第 \(i\) 个位置强制选且值为 \(j\) 的方案数,转移为枚举前面第一个选的位置 \(k\) 并枚举 \(a_k\),采用前缀和优化的技巧。
值域太大了,考虑离散化,将值域分为若干区间。那么DP状态为 \(f(i,j)\) 表示决定了前 \(i\) 个位置,且第 \(i\) 个位置强制选且位于第 \(j\) 个区间,的方案数。转移就枚举前面第一个不选第 \(j\) 个区间的位置 \(k\),这样我们可以求得 \(k+1...i\) 中可以选第 \(j\) 个区间的位置数量,假设叫 \(c\)。给这 \(c\) 个位置决定值的方案数假设为 \(g(len_j,c)\),那么 \(f\) 的递推式为 \(f(i,j) = \sum_{k < i} (\sum_{t < j}f(k,t)) \cdot g(len_j,c)\),最终答案为 \(\sum_{i,j} f(i,j)\)。这部分的复杂度为 \(O(n^3)\)
考虑求 \(g(n,m)\),即在值域大小为 \(n\) 的值域区间中决定 \(m\) 个递增的数,其中除了最后一个以外其余的可以不选,的方案数。计算的话可以枚举有 \(k\) 个选的,这 \(k\) 个的方案数为 \({n \choose k}\)。所以:
\(g(len_j, c)\) 可以递推,这部分的复杂度为 \(O(n^2)\)。总复杂度: \(O(n^3)\)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号