
大话数据结构 - 算法时间复杂度
2.9.1 算法时间复杂度定义
在进行算法分析时,语句总的执行次数 T(n) 是关于问题规模 n 的函数,进而分析 T(n) 随 n 的变化情况并确定 T(n) 的数量级。
算法的时间复杂度,也就是算法的时间度量,记作:T(n) = O(f(n))。
它表示随问题规模 n 的增大,算法时间的增长率和 f(n) 的增长率相同,称作算法的渐进时间复杂度,简称为时间复杂度。
其中 f(n) 是问题规模 n 的某个函数。
这样用大写 O() 来体现算法时间复杂度的记法,我们称之为大O记法。
一般情况下,随着 n 的增大,T(n) 增长最慢的算法为最优算法。
显然,由此算法时间复杂度的定义可知,我们的三个求和算法的时间复杂度分别为 O(1) ,O(n) ,O(n²) 。
我们分别给它们取了非官方的名称,O(1) 叫常数阶,O(n) 叫线性阶,O(n²) 叫平方阶,当然,还有其他的一些阶,我们之后会介绍。
2.9.2 推导大O阶方法
那么如何分析一个算法的时间复杂度呢?即如何推导大O阶呢?我们给出了下面的推导方法。
推导大O阶:
1. 用常数1取代运行时间中的所有加法常数。
2. 在修改后的运行次数函数中,只保留最高阶项。
3. 如果最高阶项存在且不是1,则去除与这个项相乘的常数。
得到的结果就是大O阶。
哈,仿佛是得到了游戏攻略一样,我们好像已经得到了一个推导算法时间复杂度的万能公式。
可事实上,分析一个算法的时间复杂度,没有这么简单,我们还需要多看几个例子。
2.9.3 常数阶
首先顺序结构的时间复杂度。下面这个算法,也就是刚才的第二种算法,为什么时间复杂度不是 O(3),而是 O(1)。
int sum = 0,n = 100; /*执行一次*/ sum = (1+n)*n/2; /*执行一次*/ printf("%d", sum); /*执行一次*/
这个算法的运行次数函数是 f(n)=3。根据我们推导大O阶的方法,第一步就是把常数项3改为1。在保留最高阶项时发现,它根本没有最高阶项,所以这个算法的时间复杂度为O(1)。
另外,我们试想一下,如果这个算法当中的语句 sum = (1 + n) * n / 2 有10句,即:
int sum=0,n=100; /* 执行1次 */ sum = (1+n)*n/2; /* 执行第1次 */ sum = (1+n)*n/2; /* 执行第2次 */ sum = (1+n)*n/2; /* 执行第3次 */ sum = (1+n)*n/2; /* 执行第4次 */ sum = (1+n)*n/2; /* 执行第5次 */ sum = (1+n)*n/2; /* 执行第6次 */ sum = (1+n)*n/2; /* 执行第7次 */ sum = (1+n)*n/2; /* 执行第8次 */ sum = (1+n)*n/2; /* 执行第9次 */ sum = (1+n)*n/2; /* 执行第10次 */ printf("%d",sum); /* 执行1次 */
事实上无论n为多少,上面的两段代码就是3次和12次执行的差异,这种与问题的大小无关(n的多少),执行时间恒定的算法,我们称之为具有O(1)的时间复杂度,又叫常数阶。
注意,不管这个常数是多少,我们都记作O(1),而不能是O(3)、O(12)等其他任何数字。这是初学者常常犯的错误。
对于分支结构而言,无论是真,还是假,执行的次数都是恒定的,不会随着n的变大而发生变化,所以单纯的分支结构(不包含在循环结构中),其时间复杂度也是O(1)。
2.9.4 线性阶
循环结构就会复杂很多。要确定某个算法的阶次,我们常常需要确定某个特定语句或某个语句集运行的次数。因此,我们要分析算法的复杂度,关键就是要分析循环结构的运行情况。
下面这段代码,它的循环的时间复杂度为O(n)。因为循环体中的代码须要执行n次。
int i,n=100,sum=0; for( i=0; i < n; i++) { sum=sum+i; }
上面这段代码,它的循环的时间复杂度为O(n),因为循环体中的代码需要执行n次。其实,线性阶就是一个简单的for循环,条件在i<n,因而时间复杂度为O(n)。
2.9.5 对数阶
那么下面的这段代码,时间复杂度又是多少呢?
int i=1,n=100; while( i<n ) { i=i*2; }
由于每次count乘以2之后,就距离n更近了一分。也就是说,有多少个2相乘后大于n,则会退出循环。由2x=n得到x=log2n。所以这个循环的时间复杂度为O(logn)。
2.9.6 平方阶
n等于100,也就是说外层循环每执行一次, 内层循环就执行100次 那总共程序想要从这两个循环出来,需要执行100*100次, 也就是n的平方。 所以这段代码的时间复杂度为0(n^2)。那如果有三个这样的嵌套循环呢? 没错,那就是n^3。所以我们很容易总结得出,循环的时间复杂度等于循环体的复杂度乘以该循环运行的次数。
例一:下面的例子是一个循环嵌套,它的内循环刚才2.9.4中分析过,内循环时间复杂度为O(n)。
int i,j; for(i=0; i<n; i++) { for(j=0; j<n; j++) { /* 时间复杂度为O(1)的程序步骤序列 */ } }
而对于外层的循环,不过是内部这个时间复杂度为O(n)的语句,再循环n次。所以这段代码的时间复杂度为O(n²)。
例二:如果外循环的循环次数改为了m,时间复杂度则变为O(m×n)。
int i,j; for(i=0; i<m; i++) { for(j=0; j<n; j++) { /* 时间复杂度为O(1)的程序步骤序列 */ } }
例三:那么下面这个循环嵌套,它的时间复杂度是多少呢?
int i,j; for(i=0; i<n; i++) { for(j=i; j<n; j++) /* 注意j=i而不是0 */ { /* 时间复杂度为O(1)的程序步骤序列 */ } }
由于
当i=0时,内循环执行了n次,
当i=1时,执行了n-1次,
…………
当i=n-1时,执行了1次。
n + (n-1) + (n-2) + …… +1 = n(n+1)/2 = n²/2 + n/2
用我们推导大O阶的方法:
第一条,没有加法常数,不考虑;
第二条,只保留最高阶项,因此保留n²/2;
第三条,去除这个项相乘的常数,也就是去除1/2,
最终这段代码的时间复杂度为O(n²)。
例四:对于方法调用的时间复杂度又如何分析?
int i,j; for(i=0; i<n; i++) { function(i); } void function(int count) { printf( count );
}
函数体是打印这个参数。其实这很好理解,function函数的时间复杂度是O(1)。所以整体的时间复杂度是O(n)。
例五:假如 function 是下面这样的:
int i,j; for(i=0; i<n; i++) { function(i); } void function(int count) { int j; for(j=count; j<n; j++) { /* 时间复杂度为O(1)的程序步骤序列 */ } }
其实这和刚刚的例子是一样的,只是把嵌套内循环放到了函数中,所以最终的时间复杂度还是为O(n²)。
例六:下面这段相对复杂的语句:
n++; /* 执行次数为1 */ function(n); /* 执行次数为n */ int i,j; for(i=0; i<n; i++) /* 执行次数为n² */ { function(i); } for(i=0; i<n; i++) /* 执行次数为n(n+1)/2 */ { for(j=i; j<n; j++) { /* 时间复杂度为O(1)的程序步骤序列 */ } }
它的执行次数 f(n) = 1 + n + n² + n(n+1)/2 = 3n²/2 + 3n/2 + 1
根据推导大0阶的方法,最终这段代码的时间复杂度也是0(n²)。
2.10 常见的时间复杂度
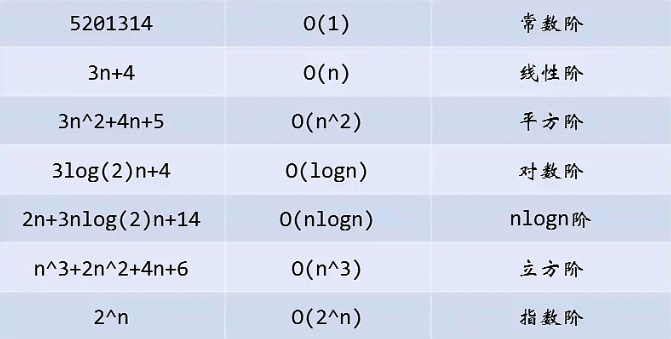
常用时间复杂度所耗费时间从小到大依次为:
O(1) < O(logn) < O(n) < O(nlogn) < O(n²) < O(n³) < O(2n) < O(n!) < O(nn)
我们前面谈到了 O(1) 常数阶、O(logn)对数阶、O(n)线性阶、O(n²)平方阶等,至于 O(nlogn) 我们将会在今后的课程中介绍,而像 O(n³),过大的n都会使得结果变得不现实。同样指数阶 O(2^n) 和阶乘阶 O(n!) 等除非是很小的n值,否则哪怕n只是100,都是噩梦般的运行时间。所以这种不切实际的算法时间复杂度,一般我们都不去讨论它。
2.11 最坏情况和平均情况
我们查找一个有 n 个随机数字数组中的某个数字,最好的情况是第一个数字就是,那么算法的时间复杂度为 O(1),但也有可能这个数字就在最后一个位置上待着,那么时间的复杂的就是 O(n),这是最坏的一种情况了。
最坏情况运行时间是一种保证,那就是运行时间将不会再坏了。在应用中,这是一种最重要的需求,通常,除非特别指定,我们提到的运行时间都是最坏情况的运行时间。
平均运行时间是所以情况中最有意义的,因为它是期望的运行时间。也就是说,我们运行一段代码的时,是希望看到评价运行时间的。可现实中,平均运行时间很难通过分析得到,一般都是通过运行一定数量的实验数据后估算出来的。
对算法的分析,一种方法是计算所有情况的平均值,这种时间复杂度的计算方法称为平均时间复杂度。另一种方法是计算最坏情况下的时间复杂度,这种方法称为最坏时间复杂度。一般在没有特殊说明的情况下,都是指最坏时间复杂度。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号