python入门学习一
本文用来记录学习python过程中所遇到的不同的或者记忆不清的一些定义。
注释
注释用#
#此处是注释 n = 123 f = 456
不转义
Python中r‘ ’表示字符串默认不转义
print('\\\t\\') \ \ print(r'\\\t\\') \\\t\\
除法运算
在Python中,有两种除法,一种除法是/:计算结果是浮点数,即使是两个整数恰好整除,结果也是浮点数
>>> 10 / 3
3.333333333333333还有一种除法是//,两个整数的除法仍然是整数:
>>> 10 // 3
3
字符串和字节流
Python 3版本中,字符串是以Unicode编码的,对于单个字符的编码,Python提供了ord()函数获取字符的整数表示,chr()函数把编码转换为对应的字符
>>> ord('A') 65 >>> ord('中') 20013 >>> chr(66) 'B' >>> chr(25991) '文'
由于Python的字符串类型是str,在内存中以Unicode表示,一个字符对应若干个字节。如果要在网络上传输,或者保存到磁盘上,就需要把str变为以字节为单位的bytes。
Python对bytes类型的数据用带b前缀的单引号或双引号表示:x = b'ABC';
要注意区分'ABC'和b'ABC',前者是字符串(str),后者虽然内容显示得和前者一样,但bytes的每个字符都只占用一个字节。
以Unicode表示的str通过encode()方法可以编码为指定的bytes;
>>> '中文'.encode('utf-8') b'\xe4\xb8\xad\xe6\x96\x87'
如果我们从网络或磁盘上读取了字节流,那么读到的数据就是bytes。要把bytes变为str,就需要用decode()方法:如果bytes中包含无法解码的字节,decode()方法会报错;如果bytes中只有一小部分无效的字节,可以传入errors='ignore'忽略错误的字节:
>>> b'\xe4\xb8\xad\xff'.decode('utf-8', errors='ignore') '中'
为了避免乱码问题,应当始终坚持使用UTF-8编码对str和bytes进行转换。
格式化
格式化字符串的方式:占位符和format()
# -*- coding: utf-8 -*- s1=72 s2=85 r=s1/s2 print('小明成绩提升了%.1f \n' %(r*100)) print('小明成绩提升了{0:.1f}%'.format(r*100))
小明成绩提升了84.7%
小明成绩提升了84.7%
列表
Python内置的一种数据类型是列表:list。list是一种有序的集合,可以随时添加和删除其中的元素。(类比JavaScript中的数组)
classmates = ['Michael', 'Bob', 'Tracy']
另一种有序列表叫元组:tuple。tuple和list非常类似,但是tuple一旦初始化就不能修改(指向不能修改,类似于指针指向的那个指向):
定义只有1个元素的tuple时必须加一个逗号,来消除歧义:t=(1,) 因为括号()既可以表示tuple,又可以表示数学公式中的小括号。
最后来看一个“可变的”tuple:
>>> t = ('a', 'b', ['A', 'B']) >>> t[2][0] = 'X' >>> t[2][1] = 'Y' >>> t ('a', 'b', ['X', 'Y'])
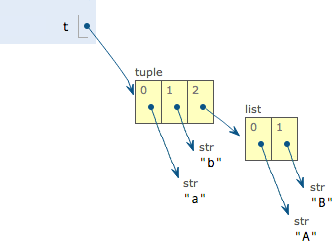
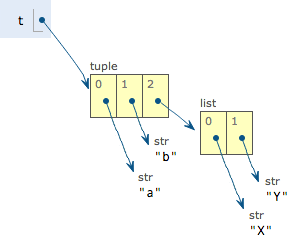
上面可以看成,tuple发生了变化,为什么呢?因为tuple所谓的“不变”是说,tuple的每个元素,指向永远不变。若想创建完全不变的,将list也转为tuple即可。
条件判断;
所有判断语句(包括循环语句里的这类判断)少了括号,判断条件后有冒号:,条件判断从上向下匹配,当满足条件时执行对应的块内语句,后续的elif和else都不再执行
if <条件判断1>: <执行1> elif <条件判断2>: <执行2> elif <条件判断3>: <执行3> else: <执行4>
if age >= 18:
print('adult')
elif age >= 6:
print('teenager')
else:
print('kid')
循环
Python的循环有两种,一种是for...in循环,依次把list或tuple中的每个元素迭代出来,第二种循环是while循环,只要条件满足,就不断循环,条件不满足时退出循环。
names = ['Michael', 'Bob', 'Tracy'] for name in names: print(name)
sum = 0 n = 99 while n > 0: sum = sum + n n = n - 2 print(sum)
使用dict和set
为什么dict查找速度这么快?因为dict的实现原理和查字典是一样的。假设字典包含了1万个汉字,我们要查某一个字,一个办法是把字典从第一页往后翻,直到找到我们想要的字为止,这种方法就是在list中查找元素的方法,list越大,查找越慢。第二种方法是先在字典的索引表里(比如部首表)查这个字对应的页码,然后直接翻到该页,找到这个字。无论找哪个字,这种查找速度都非常快,不会随着字典大小的增加而变慢。dict就是第二种实现方式,给定一个名字,比如'Michael',dict在内部就可以直接计算出Michael对应的存放成绩的“页码”,也就是95这个数字存放的内存地址,直接取出来,所以速度非常快。
dict
Python内置了字典:dict的支持,dict全称dictionary,在其他语言中也称为map,使用键-值(key-value)存储,具有极快的查找速度。dict内部存放的顺序和key放入的顺序是没有关系的。需要牢记的第一条就是dict的key必须是不可变对象,因为dict根据key来计算value的存储位置。
>>> d = {'Michael': 95, 'Bob': 75, 'Tracy': 85}
>>> d['Michael']
95
>>> d['Adam'] = 67
>>> d['Adam']
67
set
set和dict类似,也是一组key的集合,但不存储value。由于key不能重复,所以,在set中,没有重复的key。
>>> s = set([1, 1, 2, 2, 3, 3]) >>> s {1, 2, 3}

 浙公网安备 33010602011771号
浙公网安备 33010602011771号