
SQL Server技术题 - 面试题
SQL Server技术题
1.SQL语句查询出每门课都大于80分的学生姓名
name kecheng fenshu
张三 语文 81
张三 数学 75
李四 语文 76
李四 数学 90
王五 语文 81
王五 数学 100
王五 英语 90
SQL1: select distinct name from table where name in (select distinct name from table where fenshu>80)
SQL2: select name from table group by name having min(fenshu)>80
2.学生表 如下:
自动编号 学号 姓名 课程编号 课程名称 分数
1 2005001 张三 0001 数学 69
2 2005002 李四 0001 数学 89
3 2005001 张三 0001 数学 69
删除除了自动编号不同,其他都相同的学生冗余信息
SQL: delete tablename where 自动编号 not in(select min(自动编号) from tablename group by 学号,姓名,课程编号,课程名称,分数)
3.请用SQL语句实现:从TestDB数据表中查询出所有月份的发生额都比101科目相应月份的发生额高的科目。请注意:TestDB中有很多科目,都有1-12月份的发生额。
AccID:科目代码,Occmonth:发生额月份,DebitOccur:发生额。
数据库名:JcyAudit,数据集:Select * from TestDB
SQL:select a.*
from TestDB a
,(select Occmonth,max(DebitOccur) Debit101ccur from TestDB where AccID='101' group by Occmonth) b
where a.Occmonth=b.Occmonth and a.DebitOccur>b.Debit101ccur
4.怎么把这样一个表
year month amount
1991 1 1.1
1991 2 1.2
1991 3 1.3
1991 4 1.4
1992 1 2.1
1992 2 2.2
1992 3 2.3
1992 4 2.4
查成这样一个结果
year m1 m2 m3 m4
1991 1.1 1.2 1.3 1.4
1992 2.1 2.2 2.3 2.4
SQL:
select year,
(select amount from aaa m where month=1 and m.year=aaa.year) as m1,
(select amount from aaa m where month=2 and m.year=aaa.year) as m2,
(select amount from aaa m where month=3 and m.year=aaa.year) as m3,
(select amount from aaa m where month=4 and m.year=aaa.year) as m4
from aaa group by year
5.复制表(只复制结构,源表名:a 新表名:b)
SQL: select * into b from a where 1<>1
6.拷贝表(拷贝数据,源表名:a 目标表名:b)
SQL: insert into b(a, b, c) select d,e,f from b;
7.显示文章、提交人和最后回复时间
SQL: select a.title,a.username,b.adddate from table a,(select max(adddate) adddate from table where table.title=a.title) b
8.外连接查询(表名1:a 表名2:b)
SQL: select a.a, a.b, a.c, b.c, b.d, b.f from a LEFT OUT JOIN b ON a.a = b.c
9.日程安排提前五分钟提醒
SQL: select * from 日程安排 where datediff('minute',f开始时间,getdate())>5
10.两张关联表,删除主表中已经在副表中没有的信息
SQL:delete from info where not exists ( select * from infobz where info.infid=infobz.infid )
11.从数据库中去一年的各单位电话费统计(电话费定额贺电化肥清单两个表来源)
SQL:
SELECT a.userper, a.tel, a.standfee, TO_CHAR(a.telfeedate, 'yyyy') AS telyear,
SUM(decode(TO_CHAR(a.telfeedate, 'mm'), '01', a.factration)) AS JAN,
SUM(decode(TO_CHAR(a.telfeedate, 'mm'), '02', a.factration)) AS FRI,
SUM(decode(TO_CHAR(a.telfeedate, 'mm'), '03', a.factration)) AS MAR,
SUM(decode(TO_CHAR(a.telfeedate, 'mm'), '04', a.factration)) AS APR,
SUM(decode(TO_CHAR(a.telfeedate, 'mm'), '05', a.factration)) AS MAY,
SUM(decode(TO_CHAR(a.telfeedate, 'mm'), '06', a.factration)) AS JUE,
SUM(decode(TO_CHAR(a.telfeedate, 'mm'), '07', a.factration)) AS JUL,
SUM(decode(TO_CHAR(a.telfeedate, 'mm'), '08', a.factration)) AS AGU,
SUM(decode(TO_CHAR(a.telfeedate, 'mm'), '09', a.factration)) AS SEP,
SUM(decode(TO_CHAR(a.telfeedate, 'mm'), '10', a.factration)) AS OCT,
SUM(decode(TO_CHAR(a.telfeedate, 'mm'), '11', a.factration)) AS NOV,
SUM(decode(TO_CHAR(a.telfeedate, 'mm'), '12', a.factration)) AS DEC
FROM (SELECT a.userper, a.tel, a.standfee, b.telfeedate, b.factration
FROM TELFEESTAND a, TELFEE b
WHERE a.tel = b.telfax) a
GROUP BY a.userper, a.tel, a.standfee, TO_CHAR(a.telfeedate, 'yyyy')
12.四表联查问题:
SQL: select * from a left inner join b on a.a=b.b right inner join c on a.a=c.c inner join d on a.a=d.d where .....
13.得到表中最小的未使用的ID号
SQL:
SELECT (CASE WHEN EXISTS(SELECT * FROM Handle b WHERE b.HandleID = 1) THEN MIN(HandleID) + 1 ELSE 1 END) as HandleID
FROM Handle
WHERE NOT HandleID IN (SELECT a.HandleID - 1 FROM Handle a)
14.表数据如下
ID stuid status
1 100 1
3 200 1
4 2343 1
5 52 3
6 42 5
7 333 1
想得到下面结果
stuid 总数
100,200,2343,333 4
SQL:
SELECT stuff(Select ',' +convert(nvarchar(100),stuid) from tablea where status=1 order by stuid FOR XML PATH('')),1,1,'')
AS stuid,count(*) as 总数 from tablea as a where status=1
15.原表:
courseid coursename score
-------------------------------------
1 java 70
2 oracle 90
3 xml 40
4 jsp 30
5 servlet 80
-------------------------------------
为了便于阅读,查询此表后的结果显式如下(及格分数为60):
courseid coursename score mark
---------------------------------------------------
1 java 70 pass
2 oracle 90 pass
3 xml 40 fail
4 jsp 30 fail
5 servlet 80 pass
---------------------------------------------------
写出此查询语句。
SQL:
select courseid,coursename,score,
'mark'= CASE
WHEN score >=60 THEN 'pass'
WHEN score < 60 THEN 'fail'
END from tablea
16.原表:
id proid proname
1 1 M
1 2 F
2 1 N
2 2 G
3 1 B
3 2 A
查询后的表:
id pro1 pro2
1 M F
2 N G
3 B A
SQL:
select distinct id ,
(select proname from tablea a where proid = 1 and a.id=tablea.id) as pro1,
(select proname from tablea a where proid = 2 and a.id=tablea.id) as pro2
from tablea
17.原表a:
a1 a2
1 a
1 b
2 x
2 y
2 z
查询后的表:
id a3
1 ab
2 xyz
SQL 用FOR XML PATH()实现
SQL:
select distinct
(select ''+a2 from a where a1=1 FOR XML PATH('')) as '1',
(select ''+a2 from a where a1=2 FOR XML PATH('')) as '2'
from a
18.行转列
姓名 课程 分数
---------- ---------- -----------
张三 语文 74
张三 数学 83
张三 物理 93
李四 语文 74
李四 数学 84
李四 物理 94
变成
姓名 语文 数学 物理
---------- ----------- ----------- -----------
李四 74 84 94
张三 74 83 93
SQL 1:
select姓名,
max(case 课程 when '语文' then分数 else 0 end)语文,
max(case 课程 when '数学' then 分数 else 0 end)数学,
max(case 课程 when '物理' then 分数 else 0 end)物理
from tb
group by 姓名
SQL 2:select * from tb pivot(max(分数) for 课程 in(语文,数学,物理))a
19.行转列结果加上总分、平均分
姓名 语文 数学 物理 总分 平均分
---------- ----------- ----------- ----------- -----------
李四 74 84 94 252 84.00
张三 74 83 93 250 83.33
SQL:
select 姓名,
max(case 课程 when '语文' then 分数 else 0 end)语文,
max(case 课程 when '数学' then 分数 else 0 end)数学,
max(case 课程 when '物理' then 分数 else 0 end)物理,
sum(分数)总分,
cast(avg(分数*1.0)asdecimal(18,2))平均分
from tb
group by 姓名
20.列转行
姓名 语文 数学 物理
---------- ----------- ----------- -----------
张三 74 83 93
李四 74 84 94
变成
姓名 课程 分数
---------- ---- -----------
李四 语文 74
李四 数学 84
李四 物理 94
张三 语文 74
张三 数学 83
张三 物理 93
SQL:
select * from
(
select 姓名,课程='语文',分数=语文from tb
union all
select 姓名,课程='数学',分数=数学from tb
union all
select 姓名,课程='物理',分数=物理from tb
) t
order by 姓名,case 课程 when '语文' then 1 when '数学' then 2 when '物理' then 3 end
21.获取不同name的最小的year和最小的month的其中的id字段
year month id name
2014 10 1 a
2014 9 2 a
2013 12 3 a
2013 1 4 a
2013 2 5 a
2014 10 6 b
2015 9 7 b
2012 12 8 b
2012 1 9 b
2012 2 10 b
2014 10 11 b
2015 11 12 b
2013 12 13 c
2013 1 14 c
2013 2 15 c
结果:
year month id name
2013 1 4 a
2012 1 9 b
2013 1 14 c
SQL:
select * from
(select *,row_number()over(partition by name order by years ) as n from tablesa) t
where t.n=1
22.如图,如何将表A和表B合并成表C。记得sql有一个关键字可以实现,可怎么就是想不起来了。
(不使用ISNULL()来设定固定值)
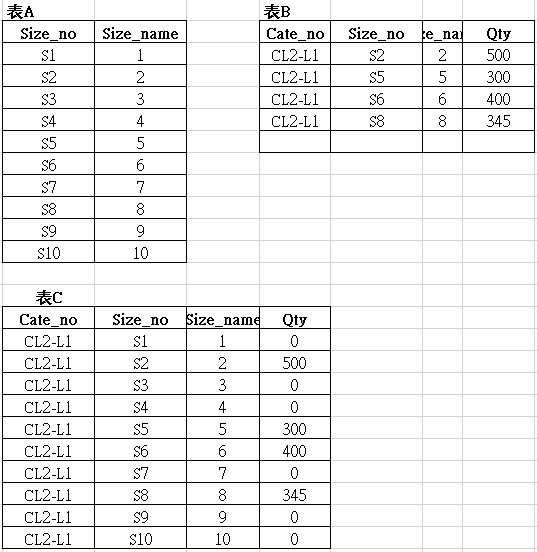
SQL:
select b.Cate_no, a.Size_no, a.Size_name,
isnull(c.Qty,0) 'Qty' from (select distinct Cate_no from 表B) b
cross join 表A a left join 表B c on b.Cate_no=c.Cate_no and a.Size_no=c.Size_no
23.题为:有两个表, t1, t2,
Table t1:
SELLER | NON_SELLER
----- -----
A B
A C
A D
B A
B C
B D
C A
C B
C D
D A
D B
D C
Table t2:
SELLER | COUPON | BAL
----- --------- ---------
A 9 100
B 9 200
C 9 300
D 9 400
A 9.5 100
B 9.5 20
A 10 80
要求用SELECT 语句列出如下结果:
------如A的SUM(BAL)为B,C,D的和,B的SUM(BAL)为A,C,D的和.......
且用的方法不要增加数据库负担,如用临时表等.
NON-SELLER| COUPON | SUM(BAL) ------- --------
A 9 900
B 9 800
C 9 700
D 9 600
A 9.5 20
B 9.5 100
C 9.5 120
D 9.5 120
A 10 0
B 10 80
C 10 80
D 10 80
SQL:未找到
***********************************************************************************
24.问题:
一百个账户各有100$,某个账户某天如有支出则添加一条新记录,记录其余额。一百天后,请输出每天所有账户的余额信息
这个问题的难点在于每个用户在某天可能有多条纪录,也可能一条纪录也没有(不包括第一天)
返回的记录集是一个100天*100个用户的纪录集
思路:
1.创建表并插入测试数据:我们要求username从1-100
CREATE TABLE [dbo].[TABLE2] (
[username] [varchar] (50) NOT NULL , --用户名
[outdate] [datetime] NOT NULL , --日期
[cash] [float] NOT NULL --余额
) ON [PRIMARY
declare @i int
set @i=1
while @i<=100
begin
insert table2 values(convert(varchar(50),@i),'2001-10-1',100)
insert table2 values(convert(varchar(50),@i),'2001-11-1',50)
set @i=@i+1
end
insert table2 values(convert(varchar(50),@i),'2001-10-1',90)
select * from table2 order by outdate,convert(int,username)
2.组合查询语句:
a.我们必须返回一个从第一天开始到100天的纪录集:
如:2001-10-1(这个日期是任意的)到 2002-1-8
由于第一天是任意一天,所以我们需要下面的SQL语句:
select top 100 dateadd(d,convert(int,username)-1,min(outdate)) as outdate
from table2
group by username
order by convert(int,username)
这里的奥妙在于:
convert(int,username)-1(记得我们指定用户名从1-100 :-))
group by username,min(outdate):第一天就可能每个用户有多个纪录。
返回的结果:
outdate
------------------------------------------------------
2001-10-01 00:00:00.000
.........
2002-01-08 00:00:00.000
b.返回一个所有用户名的纪录集:
select distinct username from table2
返回结果:
username
--------------------------------------------------
1
10
100
......
99
c.返回一个100天记录集和100个用户记录集的笛卡尔集合:
select * from
(
select top 100 dateadd(d,convert(int,username)-1,min(outdate)) as outdate
from table2
group by username
order by convert(int,username)
) as A
CROSS join
(
select distinct username from table2
) as B
order by outdate,convert(int,username)
返回结果100*100条纪录:
outdate username
2001-10-01 00:00:00.000 1
......
2002-01-08 00:00:00.000 100
d.返回当前所有用户在数据库的有的纪录:
select outdate,username,min(cash) as cash from table2
group by outdate,username
order by outdate,convert(int,username)
返回纪录:
outdate username cash
2001-10-01 00:00:00.000 1 90
......
2002-01-08 00:00:00.000 100 50
e.将c中返回的笛卡尔集和d中返回的纪录做left join:
select C.outdate,C.username,
D.cash
from
(
select * from
(
select top 100 dateadd(d,convert(int,username)-1,min(outdate)) as outdate
from table2
group by username
order by convert(int,username)
) as A
CROSS join
(
select distinct username from table2
) as B
) as C
left join
(
select outdate,username,min(cash) as cash from table2
group by outdate,username
) as D
on(C.username=D.username and datediff(d,C.outdate,D.outdate)=0)
order by C.outdate,convert(int,C.username)
注意:用户在当天如果没有纪录,cash字段返回NULL,否则cash返回每个用户当天的余额
outdate username cash
2001-10-01 00:00:00.000 1 90
2001-10-01 00:00:00.000 2 100
......
2001-10-02 00:00:00.000 1 90
2001-10-02 00:00:00.000 2 NULL <--注意这里
......
2002-01-08 00:00:00.000 100 50
f.好了,现在我们最后要做的就是,如果cash为NULL,我们要返回小于当前纪录日期的第一个用户余额(由于我们使用order by cash,所以返回top 1纪录即可,使用min应该也可以),这个余额即为当前的余额:
case isnull(D.cash,0)
when 0 then
(
select top 1 cash from table2 where table2.username=C.username
and datediff(d,C.outdate,table2.outdate)<0
order by table2.cash
)
else D.cash
end as cash
g.最后组合的完整语句就是
select C.outdate,C.username,
case isnull(D.cash,0)
when 0 then
(
select top 1 cash from table2 where table2.username=C.username
and datediff(d,C.outdate,table2.outdate)<0
order by table2.cash
)
else D.cash
end as cash
from
(
select * from
(
select top 100 dateadd(d,convert(int,username)-1,min(outdate)) as outdate
from table2
group by username
order by convert(int,username)
) as A
CROSS join
(
select distinct username from table2
) as B
) as C
left join
(
select outdate,username,min(cash) as cash from table2
group by outdate,username
) as D
on(C.username=D.username and datediff(d,C.outdate,D.outdate)=0)
order by C.outdate,convert(int,C.username)
返回结果:
outdate username cash
2001-10-01 00:00:00.000 1 90
2001-10-01 00:00:00.000 2 100
......
2002-01-08 00:00:00.000 100 50
***********************************************************************************
25.取出sql表中第31到40的记录(以自动增长ID为主键)
SQL1: select top 10 * from t where id not in (select top 30 id from t order by id ) orde by id
SQL2: select top 10 * from t where id in (select top 40 id from t order by id) order by id desc
26.有表a存储二叉树的节点,要用一条sql语句查出所有节点及节点所在的层.
表a
c1 c2 A ----------1
---- ---- / \
A B B C --------2
A C / / \
B D D N E ------3
C E / \ \
D F F K I ---4
E I
D K
C N
所要得到的结果如下
jd cs
----- ----
A 1
B 2
C 2
D 3
N 3
E 3
F 4
K 4
I 4
有高手指导一下,我只能用pl/sql写出来,请教用一条sql语句的写法
SQL: select c2, level + 1 lv
from test start
with c1 = 'A' connect by c1 = prior c2
union
select 'A', 1 from dual
order by lv;
结果:
C2 LV
-- ----------
A 1
B 2
C 2
D 3
E 3
N 3
F 4
I 4
K 4
已选择9行。
27.表内容:
2005-05-09 胜
2005-05-09 胜
2005-05-09 负
2005-05-09 负
2005-05-10 胜
2005-05-10 负
2005-05-10 负
如果要生成下列结果, 该如何写sql语句?
日期 胜 负
2005-05-09 2 2
2005-05-10 1 2
SQL1:select rq, sum(case when shengfu='胜' then 1 else 0 end)'胜',sum(case when shengfu='负' then 1 else 0 end)'负' from #tmp group by rq
SQL2:select N.rq,N.勝,M.負 from (
select rq,勝=count(*) from #tmp where shengfu='胜'group by rq)N inner join
(select rq,負=count(*) from #tmp where shengfu='负'group by rq)M on N.rq=M.rq
SQL3:select a.col001,a.a1 胜,b.b1 负 from
(select col001,count(col001) a1 from temp1 where col002='胜' group by col001) a,
(select col001,count(col001) b1 from temp1 where col002='负' group by col001) b
where a.col001=b.col001
28.表中有A B C三列,用SQL语句实现:当A列大于B列时选择A列否则选择B列,当B列大于C列时选择B列否则选择C列。
SQL:select (case when a>b then a else b end ),
(case when b>c then b esle c end)
from table_name
29.请取出tb_send表中日期(SendTime字段)为当天的所有记录?(SendTime字段为datetime型,包含日期与时间)
SQL:select * from tb where datediff(dd,SendTime,getdate())=0
30.一张表,里面有3个字段:语文,数学,英语。其中有3条记录分别表示语文70分,数学80分,英语58分,请用一条sql语句查询出这三条记录并按以下条件显示出来(并写出您的思路):
大于或等于80表示优秀,大于或等于60表示及格,小于60分表示不及格。
显示格式:
语文 数学 英语
及格 优秀 不及格
SQL:
select
(case when 语文>=80 then '优秀'
when 语文>=60 then '及格'
else '不及格') as 语文,
(case when 数学>=80 then '优秀'
when 数学>=60 then '及格'
else '不及格') as 数学,
(case when 英语>=80 then '优秀'
when 英语>=60 then '及格'
else '不及格') as 英语,
from table
31.在sqlserver2000中请用sql创建一张用户临时表和系统临时表,里面包含两个字段ID和IDValues,类型都是int型,并解释下两者的区别?
用户临时表:create table #xx(ID int, IDValues int)
系统临时表:create table ##xx(ID int, IDValues int)
区别:
用户临时表只对创建这个表的用户的Session可见,对其他进程是不可见的.
当创建它的进程消失时这个临时表就自动删除.
全局临时表对整个SQL Server实例都可见,但是所有访问它的Session都消失的时候,它也自动删除
32.Sqlserver2000是一种大型数据库,他的存储容量只受存储介质的限制,请问它是通过什么方式实现这种无限容量机制的。
它的所有数据都存储在数据文件中(*.dbf),所以只要文件够大,SQL Server的存储容量是可以扩大的.
SQL Server 2000 数据库有三种类型的文件:
主要数据文件
主要数据文件是数据库的起点,指向数据库中文件的其它部分。每个数据库都有一个主要数据文件。主要数据文件的推荐文件扩展名是 .mdf。
次要数据文件
次要数据文件包含除主要数据文件外的所有数据文件。有些数据库可能没有次要数据文件,而有些数据库则有多个次要数据文件。次要数据文件的推荐文件扩展名是 .ndf。
日志文件
日志文件包含恢复数据库所需的所有日志信息。每个数据库必须至少有一个日志文件,但可以不止一个。日志文件的推荐文件扩展名是 .ldf。
33.从table1,table2中取出如table3所列格式数据,注意提供的数据及结果不准确,只是作为一个格式向大家请教。
如使用存储过程也可以。
table1
月份mon 部门dep 业绩yj
-------------------------------
一月份 01 10
一月份 02 10
一月份 03 5
二月份 02 8
二月份 04 9
三月份 03 8
table2
部门dep 部门名称dname
--------------------------------
01 国内业务一部
02 国内业务二部
03 国内业务三部
04 国际业务部
table3 (result)
部门dep 一月份 二月份 三月份
--------------------------------------
01 10 null null
02 10 8 null
03 null 5 8
04 null null 9
SQL1:
select a.部门名称dname,b.业绩yj as '一月份',c.业绩yj as '二月份',d.业绩yj as '三月份'
from table1 a,table2 b,table2 c,table2 d
where a.部门dep = b.部门dep and b.月份mon = '一月份' and
a.部门dep = c.部门dep and c.月份mon = '二月份' and
a.部门dep = d.部门dep and d.月份mon = '三月份' and
SQL2:
select a.dep,
sum(case when b.mon=1 then b.yj else 0 end) as '一月份',
sum(case when b.mon=2 then b.yj else 0 end) as '二月份',
sum(case when b.mon=3 then b.yj else 0 end) as '三月份',
sum(case when b.mon=4 then b.yj else 0 end) as '四月份',
sum(case when b.mon=5 then b.yj else 0 end) as '五月份',
sum(case when b.mon=6 then b.yj else 0 end) as '六月份',
sum(case when b.mon=7 then b.yj else 0 end) as '七月份',
sum(case when b.mon=8 then b.yj else 0 end) as '八月份',
sum(case when b.mon=9 then b.yj else 0 end) as '九月份',
sum(case when b.mon=10 then b.yj else 0 end) as '十月份',
sum(case when b.mon=11 then b.yj else 0 end) as '十一月份',
sum(case when b.mon=12 then b.yj else 0 end) as '十二月份',
from table2 a left join table1 b on a.dep=b.dep
34.一个表中的Id有多个记录,把所有这个id的记录查出来,并显示共有多少条记录数。
select id, Count(*) from tb group by id having count(*)>1
select * from(select count(ID) as count from table group by ID)T where T.count>1
35.drop ,delete ,truncate 区别drop
隐式提交,不能回滚,
删除表结构及所有从数据,将表所占空间全部释放。
删除表的结构所依赖的约束,触发器,索引,依赖于该表的存储过程/函数将保 留,但是变为invalid状态。
delete
逐行删除,并且同时将该行的的删除操作记录在redo和undo表空间中以便进行回滚(rollback)和重做操作。
truncate
删除所有数据,TRUNCATE不记录日志 , 表结构及其列、约束、索引等保持不变。
36.select 1 ,count(1) 两个用法?
select 1 from table 增加临时列,每行的列值是写在select后的数,这条sql语句中是1
count(1) 表的行数
37.exists 介绍
1.子查询与外表的字段有关系时
select 字段1 , 字段2 from 表1 where exists (select 字段1 , 字段2 from 表2 where 表2.字段2 = 表1.字段2)
这时候,此SQL语句相当于一个关联查询。
它先执行表1的查询,然后把表1中的每一条记录放到表2的条件中去查询,如果存在,则显示此条记录
2.子查询与外表的字段没有任何关联
Select 字段1 , 字段2 from 表1 where exists ( select * from 表2 where 表2.字段 = ‘ 条件‘)
在这种情况下,只要子查询的条件成立,就会查询出表1中的所有记录,反之,如果子查询中没有查询到记录,则表1不会查询出任何的记录。
当子查询与主表不存在关联关系时,简单认为只要exists为一个条件判断,如果为true,就输出所有记录。如果为false则不输出任何的记录。
38.exists与in 区别?
in是在内存里遍历比较,而exists需要查询数据库,所以当B表数据量较大时,exists效率优于in。
exists()会执行A.length次,它并不缓存exists()结果集,因为exists()结果集的内容并不重要,重要的是其内查询语句的结果集空或者非空,空则返回false,非空则返回true。
外表大,用IN;内表大,用EXISTS
not in 和not exists
如果查询语句使用了not in 那么内外表都进行全表扫描,没有用到索引;
而not extsts 的子查询依然能用到表上的索引。
所以无论那个表大,用not exists都比not in要快。
39.on 与 where 区别?
on条件是在生成临时表时使用的条件
where条件是在临时表生成好后,再对临时表进行过滤的条件
on后的条件用来生成左右表关联的临时表,where后的条件对临时表中的记录进行过滤。
40.HERE、HAVING和ON的比较
WHERE和HAVING关键字都可以对查询结果进行筛选,两者的区别是WHERE的作用时间是在计算之前就完成的,而having是在计算后才起作用的。HAVING只会在检索出所有记录之后才对结果集进行过滤
ON关键字实际上也是对数据进行筛选,只不过是在多表关联时使用。需要注意的是,在我们常用的操作中,表关联是最耗时的操作之一。尤其是两张大表的关联
41.优化修改删除语句
如果你同时修改或删除过多数据,会造成cpu利用率过高从而影响别人对数据库的访问。
如果你删除或修改过多数据,采用单一循环操作,那么会是效率很低,也就是操作时间过程会很漫长。
delete tb where id<1
delete tb where id>=1 and id<2
delete tb where id>=2 and id<3
42.根据如下三张表查询
S (SNO,SNAME) 学生关系。SNO 为学号,SNAME 为姓名
C (CNO,CNAME,CTEACHER) 课程关系。CNO 为课程号,CNAME 为课程名,CTEACHER 为任课教师
SC(SNO,CNO,SCGRADE) 选课关系。SCGRADE 为成绩
1). 找出没有选修过“李明”老师讲授课程的所有学生姓名
Select SNAME FROM S Where NOT EXISTS( Select * FROM SC,C Where SC.CNO=C.CNO AND CNAME='李明' AND SC.SNO=S.SNO)
2). 列出有二门以上(含两门)不及格课程的学生姓名及其平均成绩
Select S.SNO,S.SNAME,AVG_SCGRADE=AVG(SC.SCGRADE) FROM S,SC,( Select SNO FROM SC Where SCGRADE<60 GROUP BY SNO HAVING COUNT(DISTINCT CNO)>=2 )A Where S.SNO=A.SNO AND SC.SNO=A.SNO GROUP BY S.SNO,S.SNAME
3). 列出既学过“1”号课程,又学过“2”号课程的所有学生姓名
Select S.SNO,S.SNAME FROM S,( Select SC.SNO FROM SC,C Where SC.CNO=C.CNO AND C.CNAME IN('1','2') GROUP BY SNO HAVING COUNT(DISTINCT CNO)=2 )SC Where S.SNO=SC.SNO
4). 列出“1”号课成绩比“2”号同学该门课成绩高的所有学生的学号
Select S.SNO,S.SNAME FROM S,( Select SC1.SNO FROM SC SC1,C C1,SC SC2,C C2 Where SC1.CNO=C1.CNO AND C1.NAME='1' AND SC2.CNO=C2.CNO AND C2.NAME='2' AND SC1.SCGRADE>SC2.SCGRADE )SC Where S.SNO=SC.SNO
5). 列出“1”号课成绩比“2”号课成绩高的所有学生的学号及其“1”号课和“2”号课的成绩
Select S.SNO,S.SNAME,SC.[1号课成绩],SC.[2号课成绩] FROM S,( Select SC1.SNO,[1号课成绩]=SC1.SCGRADE,[2号课成绩]=SC2.SCGRADE FROM SC SC1,C C1,SC SC2,C C2 Where SC1.CNO=C1.CNO AND C1.NAME='1' AND SC2.CNO=C2.CNO AND C2.NAME='2' AND SC1.SCGRADE>SC2.SCGRADE )SC Where S.SNO=SC.SNO
6).求其中同一个号码的两次通话之间间隔大于10秒的通话记录ID
SELECT DISTINCT a.id FROM dbo.hc a left join dbo.hc b ON a.主叫号码=b.主叫号码
WHERE a.id<>b.id AND (DATEDIFF(second,a.通话起始时间,b.通话结束时间)>10 AND DATEDIFF(second,b.通话起始时间,a.通话结束时间)>10)Sql Server关于按周统计的问题
7).统计Sql Server里一个销售明细表里某个时间段的销售额,而且要按周进行比较
select sum(销售金额), datename(week, 销售日期-1) from sales where 销售日期 betwee begindate and enddate group by datename(week, 销售日期-1)
8).使用标准SQL嵌套语句查询选修课程名称为’税收基础’的学员学号和姓名?
select s# ,sn from s where S# in(select S# from c,sc where c.c#=sc.c# and cn=’税收基础’)
9).使用标准SQL嵌套语句查询选修课程编号为’C2’的学员姓名和所属单位?
select sn,sd from s,sc where s.s#=sc.s# and sc.c#=’c2’
10).使用标准SQL嵌套语句查询不选修课程编号为’C5’的学员姓名和所属单位?
select sn,sd from s where s# not in(select s# from sc where c#=’c5’)
11).查询选修了课程的学员人数
select 学员人数=count(distinct s#) from sc
12).查询选修课程超过5门的学员学号和所属单位?
select sn,sd from s where s# in(select s# from sc group by s# having count(distinct c#)>5)
13).查询A(ID,Name)表中第31至40条记录,ID作为主键可能是不是连续增长的列
select top 10 * from A where ID >(select max(ID) from (select top 30 ID from A order by A) T) order by A
14).查询表A中存在ID重复三次以上的记录
SELECT * from A WHERE ID in(select ID from A group by ID having COUNT(ID)>3)
43.testtable1和testtable2表联合查询testtable1:id department
1 设计
2 市场
3 售后
testtable2:id dptID name
1 1 张三
2 1 李四
3 2 王五
4 3 彭六
5 4 陈七
结果:
id dptID department name
1 1 设计 张三
2 1 设计 李四
3 2 市场 王五
4 3 售后 彭六
5 4 黑人 陈七
SQL:
SELECT testtable2.* , ISNULL(department,'黑人')
FROM testtable1 right join testtable2 on testtable2.dptID = testtable1.ID
44.有表A,结构如下:
A: p_ID p_Num s_id
1 10 01
1 12 02
2 8 01
3 11 01
3 8 03
其中:p_ID为产品ID,p_Num为产品库存量,s_id为仓库ID。请用SQL语句实现将上表中的数据合并,合并后的数据为:
p_ID s1_id s2_id s3_id
1 10 12 0
2 8 0 0
3 11 0 8
其中:s1_id为仓库1的库存量,s2_id为仓库2的库存量,s3_id为仓库3的库存量。如果该产品在某仓库中无库存量,那么就是0代替。
SQL:
select p_id ,
sum(case when s_id=1 then p_num else 0 end) as s1_id
,sum(case when s_id=2 then p_num else 0 end) as s2_id
,sum(case when s_id=3 then p_num else 0 end) as s3_id
from myPro group by p_id
45.产品销售数据厍cpxs中所有表如下:
产品表: 产品编号,产品名称,价格,库存量。
销售商表: 客户编号,客户名称,地区,负责人,电话。
产品销售表: 销售日期,产品编号,客户编号,数量,销售额。
1.在cpxs数据库的产品表中增加”产品简介“列,之后在删除该列。
ALTER TABLE [dbo].[product]
ADD [产品简介] text
ALTER TABLE [dbo].[product]
DROP COLUMN [产品简介]
2.将产品数据库的产品表中每种商品的价格打8UPDATE [dbo].[product] SET [价格]=[价格]*0.8
3.将产品数据库的产品表中价格打8折后低于50元的商品删除DELETE [dbo].[product] WHERE [价格]<50
4.查找价格在2000~2900元之间的商品名。
SELECT [产品名称] FROM [dbo].[product] WHERE [价格] BETWEEN 2000 AND 2900
5.计算所有商品的总价格。
SELECT SUM([价格]*[库存量]) FROM [dbo].[product]
6.在产品销售数据库上创建电冰箱产品表的视图bxcp。
CREATE VIEW [dbo].[bxcp] AS SELECT dbo.product.* FROM dbo.product WHERE [产品名称]='电冰箱'
7.在bxcp视图中查询库存量在100台以下的产品编号。
SELECT * FROM [dbo].[bxcp] WHERE [库存量]<100
8.使用EXISTS关键字引入的子查询与使用IN关键字引入的子查询在语法上有哪些不同?
// EXISTS 方式
SELECT * FROM A WHERE EXISTS(SELECT * FROM B WHERE B.id=A.uid);
// in 方式
SELECT * FROM A WHERE id IN (SELECT id FROM B);46.删除姓名、年龄重复的记录
Id name age salary
1 yzk 80 1000
2 yzk 80 2000
3 tom 20 20000
4 tom 20 20000
5 im 20 20000
//取得不重复的数据
select * from Persons where Id in(SELECT MAX(Id) AS Expr1 FROM Persons GROUP BY Name, Age)
根据姓名、年龄分组,取出每组的Id最大值,然后将Id最大值之外的排除。
删除重复的数据:
delete from Persons where Id not in(SELECT MAX(Id) AS Expr1 FROM Persons GROUP BY Name, Age)
47.本题用到下面三个关系表题目:
条件查询:
1、在GRADE表中查找80-90份的学生学号和分数
select 学号,分数 from grade where 分数 between 80 and 90
2、在GRADE 表中查找课程编号为003学生的平均分
select avg(分数) from grade where 课程编号='003'
3、在GRADE 表中查询学习各门课程的人数
select课程编号,count(学号) as 人数from grade group by 课程编号
4、查询所有姓张的学生的学号和姓名
select 姓名,学号 from student_info where 姓名 like '张%'
嵌套查询:
1、 查询和学号’0001’的这位同学性别相同的所有同学的姓名和出生年月
select 姓名,出生年月 from student_info where 性别 in(select 性别 from student_info where sno='0001')
2、 查询所有选修课程编号为0002 和0003的学生的学号、姓名和性别
select 学号,姓名,性别 from student_info where 学号 in(select 学号 from grade where 课程编号='0002' and 学号 in(select 学号 from grade where 课程编号='0001'))
3、 查询出学号为0001的学生的分数比0002号学生最低分高的课程编号的课程编号和分数
select 课程编号, 分数 from grade where 学号='0001' and 分数>(select min(分数) from grade where 学号='0002')
多表查询:
1、 查询分数在80-90分的学生的学号、姓名、分数
select student_info.学号,student_info.姓名,grade.分数 from student_info,grade where grade.分数 between 80 and 90
2、 查询学习了’C语言’课程的学生学号、姓名和分数
select student_info.学号,student_info.姓名,grade.成绩from student_info,grade,curriculum where student_info.学号=grade.学号and grade.课程号=curriculum.课程号and curriculum.课程名='C语言'
3、 查询所有学生的总成绩,要求列出学号、姓名、总成绩,没有选课的学生总成绩为空。
select grade.学号,student_info.姓名,sum(grade.成绩) as 总成绩from student_info,grade where grade.学号=student_info.学号group by grade.学号,student_info.姓名
48.本题用到下面三个关系表:
CARD 借书卡: (CNO 卡号,NAME 姓名,CLASS 班级)
BOOKS 图书: (BNO 书号,BNAME 书名,AUTHOR 作者,PRICE 单价,QUANTITY 库存册数 )
BORROW 借书记录: (CNO 借书卡号,BNO 书号,RDATE 还书日期
备注:限定每人每种书只能借一本;库存册数随借书、还书而改变。
1、要求实现如下处理:
写出自定义函数,要求输入借书卡号能得到该卡号所借书金额的总和:
CREATE FUNCTION getSUM
(
@CNO int
)
RETURNS int
AS
BEGIN
declare @sum int
select @sum=sum(price) from BOOKS where bno in (select bno from BORROW where cno=@CNO)
return @sum
END
GO
2、找出借书超过5本的读者,输出借书卡号及所借图书册数。
select CNO,count(BNO) as 借书数量from BORROW group by CNO having count(BNO)>3
3、查询借阅了"水浒"一书的读者,输出姓名及班级。
select name,class from card where cno in( select cno from borrow where bno in(select bno from BOOKS where bname='水浒'))
4、查询过期未还图书,输出借阅者(卡号)、书号及还书日期。
select CNO,BNO,RDATE from borrow where getdate()>RDATE
5、查询书名包括"网络"关键词的图书,输出书号、书名、作者。
select bno,bname,author from books where bname like '网络%'
6、查询现有图书中价格最高的图书,输出书名及作者。
select bname,author from books where price in(select max(price) from books )
7、查询当前借了"计算方法"但没有借"计算方法习题集"的读者,输出其借书卡号,并按卡号降序排序输出。
select cno from borrow where bno in (select bno from books where bname='计算方法') and cno not in ( select cno from borrow where bno in(select bno from books where bname='计算方法习题集')) order by cno desc
或
SELECT a.CNO
FROM BORROW a,BOOKS b
WHERE a.BNO=b.BNO AND b.BNAME=N'计算方法'
AND NOT EXISTS(
SELECT * FROM BORROW aa,BOOKS bb
WHERE aa.BNO=bb.BNO
AND bb.BNAME=N'计算方法习题集'
AND aa.CNO=a.CNO)
ORDER BY a.CNO DESC
8、将"C01"班同学所借图书的还期都延长一周。
update borrow set rdate=dateadd(day,7,rdate) from BORROW where cno in(select cno from card where class='一班')
9、从BOOKS表中删除当前无人借阅的图书记录。
DELETE A FROM BOOKS a
WHERE NOT EXISTS(
SELECT * FROM BORROW
WHERE BNO=a.BNO)
10、如果经常按书名查询图书信息,请建立合适的索引。
CREATE CLUSTERED INDEX IDX_BOOKS_BNAME ON BOOKS(BNAME)
11、在BORROW表上建立一个触发器,完成如下功能:如果读者借阅的书名是"数据库技术及应用",就将该读者的借阅记录保存在BORROW_SAVE表中(注ORROW_SAVE表结构同BORROW表)
CREATE TRIGGER TR_SAVE ON BORROW
FOR INSERT,UPDATE
AS
IF @@ROWCOUNT>0
INSERT BORROW_SAVE SELECT i.*
FROM INSERTED i,BOOKS b
WHERE i.BNO=b.BNO
AND b.BNAME=N'数据库技术及应用'
12、建立一个视图,显示"力01"班学生的借书信息(只要求显示姓名和书名)。
CREATE VIEW V_VIEW
AS
select name,bname
from books,card,borrow
where borrow.cno=card.cno and borrow.bno=books.bno and class='一班'
13、查询当前同时借有"计算方法"和"组合数学"两本书的读者,输出其借书卡号,并按卡号升序排序输出。
select a.cno from borrow a,borrow b
where a.cno=b.cno and
a.bno in(select bno from books where bname='计算方法') and
b.bno in(select bno from books where bname='组合数学')
order by a.cno asc
或
SELECT a.CNO
FROM BORROW a,BOOKS b
WHERE a.BNO=b.BNO
AND b.BNAME IN('计算方法','组合数学')
GROUP BY a.CNO
HAVING COUNT(*)=2
ORDER BY a.CNO asc
14、用事务实现如下功能:一个借书卡号借走某书号的书,则该书的库存量减少1,当某书的库存量不够1本的时候,该卡号不能借该书
alter PROCEDURE pro_jieshu
@cno int,
@bno int,
@date datetime
AS
BEGIN
begin tran
declare @quantity int
select @quantity=quantity from books where bno=@bno
insert into borrow values(@cno,@bno,@date)
update books set quantity=@quantity-1 where bno=@bno
if(@quantity>0)
begin
commit tran
end
else
begin
print '已无库存'
rollback
end
END
GO
49.本题用到如下四张表Student(S#,Sname,Sage,Ssex) 学生表
Course(C#,Cname,T#) 课程表
SC(S#,C#,score) 成绩表
Teacher(T#,Tname) 教师表
题目:
1)查询“001”课程比“002”课程成绩高的所有学生的学号;
select a.S# from (select s#,score from SC where C#='001') a,(select s#,score
from SC where C#='002') b
where a.score>b.score and a.s#=b.s#;
2)查询平均成绩大于60分的同学的学号和平均成绩;
select S#,avg(score) from sc group by S# having avg(score) >60;
3)查询所有同学的学号、姓名、选课数、总成绩;
select Student.S#,Student.Sname,count(SC.C#),sum(score) from Student left Outer join SC on Student.S#=SC.S# group by Student.S#,Sname
4)查询姓“李”的老师的个数;
select count(distinct(Tname)) from Teacher where Tname like '李%';
5)查询没学过“叶平”老师课的同学的学号、姓名;
select Student.S#,Student.Sname from Student
where S# not in (select distinct( SC.S#) from SC,Course,Teacher where SC.C#=Course.C# and Teacher.T#=Course.T# and Teacher.Tname='叶平');
6)查询学过“001”并且也学过编号“002”课程的同学的学号、姓名;
select Student.S#,Student.Sname from Student,SC where Student.S#=SC.S# and SC.C#='001'and exists( Select * from SC as SC_2 where SC_2.S#=SC.S# and SC_2.C#='002');
7)查询学过“叶平”老师所教的所有课的同学的学号、姓名;
select S#,Sname from Student where S# in (select S# from SC ,Course ,Teacher where SC.C#=Course.C# and Teacher.T#=Course.T# and Teacher.Tname='叶平'
group by S# having count(SC.C#)=(select count(C#) from Course,Teacher where Teacher.T#=Course.T# and Tname='叶平'));
8)查询课程编号“002”的成绩比课程编号“001”课程低的所有同学的学号、姓名;
Select S#,Sname from (select Student.S#,Student.Sname,score ,(select score from SC SC_2 where SC_2.S#=Student.S# and SC_2.C#='002') score2
from Student,SC where Student.S#=SC.S# and C#='001') S_2 where score2 <score;
9)查询所有课程成绩小于60分的同学的学号、姓名;
select S#,Sname from Student where S# not in (select Student.S# from Student,SC where S.S#=SC.S# and score>60);
10)查询没有学全所有课的同学的学号、姓名;
select Student.S#,Student.Sname from Student,SC
where Student.S#=SC.S# group by Student.S#,Student.Sname having count(C#) <(select count(C#) from Course);
11)查询至少有一门课与学号为“1001”的同学所学相同的同学的学号和姓名;
select S#,Sname from Student,SC where Student.S#=SC.S# and C# in select C# from SC where S#='1001';
12)查询至少学过学号为“001”同学所有一门课的其他同学学号和姓名;
select distinct SC.S#,Sname from Student,SC where Student.S#=SC.S# and C# in (select C# from SC where S#='001');
13)把“SC”表中“叶平”老师教的课的成绩都更改为此课程的平均成绩;
update SC set score=(select avg(SC_2.score) from SC SC_2 where SC_2.C#=SC.C# ) from Course,Teacher where Course.C#=SC.C# and Course.T#=Teacher.T# and Teacher.Tname='叶平');
14)查询和“1002”号的同学学习的课程完全相同的其他同学学号和姓名;
select S# from SC where C# in (select C# from SC where S#='1002')
group by S# having count(*)=(select count(*) from SC where S#='1002');
15)删除学习“叶平”老师课的SC表记录;
Delete SC from course ,Teacher
where Course.C#=SC.C# and Course.T#= Teacher.T# and Tname='叶平';
16)向SC表中插入一些记录,这些记录要求符合以下条件:没有上过编号“003”课程的同学学号、2、号课的平均成绩;
Insert SC select S#,'002',(Select avg(score)
from SC where C#='002') from Student where S# not in (Select S# from SC where C#='002');
17)按平均成绩从高到低显示所有学生的“数据库”、“企业管理”、“英语”三门的课程成绩,按如下形式显示: 学生ID,,数据库,企业管理,英语,有效课程数,有效平均分
SELECT S# as 学生ID
,(SELECT score FROM SC WHERE SC.S#=t.S# AND C#='004') AS 数据库
,(SELECT score FROM SC WHERE SC.S#=t.S# AND C#='001') AS 企业管理
,(SELECT score FROM SC WHERE SC.S#=t.S# AND C#='006') AS 英语
,COUNT(*) AS 有效课程数, AVG(t.score) AS 平均成绩
FROM SC AS t
GROUP BY S#
ORDER BY avg(t.score)
18)查询各科成绩最高和最低的分:以如下形式显示:课程ID,最高分,最低分
SELECT L.C# As 课程ID,L.score AS 最高分,R.score AS 最低分
FROM SC L ,SC AS R
WHERE L.C# = R.C# and
L.score = (SELECT MAX(IL.score)
FROM SC AS IL,Student AS IM
WHERE L.C# = IL.C# and IM.S#=IL.S#
GROUP BY IL.C#)
AND
R.Score = (SELECT MIN(IR.score)
FROM SC AS IR
WHERE R.C# = IR.C#
GROUP BY IR.C#
);
19)按各科平均成绩从低到高和及格率的百分数从高到低顺序
SELECT t.C# AS 课程号,max(course.Cname)AS 课程名,isnull(AVG(score),0) AS 平均成绩
,100 * SUM(CASE WHEN isnull(score,0)>=60 THEN 1 ELSE 0 END)/COUNT(*) AS 及格百分数
FROM SC T,Course
where t.C#=course.C#
GROUP BY t.C#
ORDER BY 100 * SUM(CASE WHEN isnull(score,0)>=60 THEN 1 ELSE 0 END)/COUNT(*) DESC
20)查询如下课程平均成绩和及格率的百分数(用"1行"显示): 企业管理(001),马克(002),OO&UML (003),数据库(004)
SELECT SUM(CASE WHEN C# ='001' THEN score ELSE 0 END)/SUM(CASE C# WHEN '001' THEN 1 ELSE 0 END) AS 企业管理平均分
,100 * SUM(CASE WHEN C# = '001' AND score >= 60 THEN 1 ELSE 0 END)/SUM(CASE WHEN C# = '001' THEN 1 ELSE 0 END) AS 企业管理及格百分数
,SUM(CASE WHEN C# = '002' THEN score ELSE 0 END)/SUM(CASE C# WHEN '002' THEN 1 ELSE 0 END) AS 马克思平均分
,100 * SUM(CASE WHEN C# = '002' AND score >= 60 THEN 1 ELSE 0 END)/SUM(CASE WHEN C# = '002' THEN 1 ELSE 0 END) AS 马克思及格百分数
,SUM(CASE WHEN C# = '003' THEN score ELSE 0 END)/SUM(CASE C# WHEN '003' THEN 1 ELSE 0 END) AS UML平均分
,100 * SUM(CASE WHEN C# = '003' AND score >= 60 THEN 1 ELSE 0 END)/SUM(CASE WHEN C# = '003' THEN 1 ELSE 0 END) AS UML及格百分数
,SUM(CASE WHEN C# = '004' THEN score ELSE 0 END)/SUM(CASE C# WHEN '004' THEN 1 ELSE 0 END) AS 数据库平均分
,100 * SUM(CASE WHEN C# = '004' AND score >= 60 THEN 1 ELSE 0 END)/SUM(CASE WHEN C# = '004' THEN 1 ELSE 0 END) AS 数据库及格百分数
FROM SC
21)查询不同老师所教不同课程平均分从高到低显示
SELECT max(Z.T#) AS 教师ID,MAX(Z.Tname) AS 教师姓名,C.C# AS 课程ID,MAX(C.Cname) AS 课程名称,AVG(Score) AS 平均成绩
FROM SC AS T,Course AS C ,Teacher AS Z
where T.C#=C.C# and C.T#=Z.T#
GROUP BY C.C#
ORDER BY AVG(Score) DESC
22)查询如下课程成绩第 3 名到第 6 名的学生成绩单:企业管理(001),马克思(002),UML (003),数据库(004) [学生ID],[学生姓名],企业管理,马克思,UML,数据库,平均成绩
SELECT DISTINCT top 3
SC.S# As 学生学号,
Student.Sname AS 学生姓名
T1.score AS 企业管理,
T2.score AS 马克思,
T3.score AS UML,
T4.score AS 数据库,
ISNULL(T1.score,0) + ISNULL(T2.score,0) + ISNULL(T3.score,0) + ISNULL(T4.score,0) as 总分
FROM Student,SC LEFT JOIN SC AS T1
ON SC.S# = T1.S# AND T1.C# = '001'
LEFT JOIN SC AS T2
ON SC.S# = T2.S# AND T2.C# = '002'
LEFT JOIN SC AS T3
ON SC.S# = T3.S# AND T3.C# = '003'
LEFT JOIN SC AS T4
ON SC.S# = T4.S# AND T4.C# = '004'
WHERE student.S#=SC.S# and
ISNULL(T1.score,0) + ISNULL(T2.score,0) + ISNULL(T3.score,0) + ISNULL(T4.score,0)
NOT IN
(SELECT
DISTINCT
TOP 15 WITH TIES
ISNULL(T1.score,0) + ISNULL(T2.score,0) + ISNULL(T3.score,0) + ISNULL(T4.score,0)
FROM sc
LEFT JOIN sc AS T1
ON sc.S# = T1.S# AND T1.C# = 'k1'
LEFT JOIN sc AS T2
ON sc.S# = T2.S# AND T2.C# = 'k2'
LEFT JOIN sc AS T3
ON sc.S# = T3.S# AND T3.C# = 'k3'
LEFT JOIN sc AS T4
ON sc.S# = T4.S# AND T4.C# = 'k4'
ORDER BY ISNULL(T1.score,0) + ISNULL(T2.score,0) + ISNULL(T3.score,0) + ISNULL(T4.score,0) DESC);
23)统计列印各科成绩,各分数段人数:课程ID,课程名称,[100-85],[85-70],[70-60],[ <60]
SELECT SC.C# as 课程ID, Cname as 课程名称
,SUM(CASE WHEN score BETWEEN 85 AND 100 THEN 1 ELSE 0 END) AS [100 - 85]
,SUM(CASE WHEN score BETWEEN 70 AND 85 THEN 1 ELSE 0 END) AS [85 - 70]
,SUM(CASE WHEN score BETWEEN 60 AND 70 THEN 1 ELSE 0 END) AS [70 - 60]
,SUM(CASE WHEN score < 60 THEN 1 ELSE 0 END) AS [60 -]
FROM SC,Course
where SC.C#=Course.C#
GROUP BY SC.C#,Cname;
24)查询学生平均成绩及其名次
SELECT 1+(SELECT COUNT( distinct 平均成绩)
FROM (SELECT S#,AVG(score) AS 平均成绩
FROM SC
GROUP BY S#
) AS T1
WHERE 平均成绩 > T2.平均成绩) as 名次,
S# as 学生学号,平均成绩
FROM (SELECT S#,AVG(score) 平均成绩
FROM SC
GROUP BY S#
) AS T2
ORDER BY 平均成绩 desc;
25)查询各科成绩前三名的记录:(不考虑成绩并列情况)
SELECT t1.S# as 学生ID,t1.C# as 课程ID,Score as 分数
FROM SC t1
WHERE score IN (SELECT TOP 3 score
FROM SC
WHERE t1.C#= C#
ORDER BY score DESC
)
ORDER BY t1.C#;
26)查询每门课程被选修的学生数
select c#,count(S#) from sc group by C#;
27)查询出只选修了一门课程的全部学生的学号和姓名
select SC.S#,Student.Sname,count(C#) AS 选课数
from SC ,Student
where SC.S#=Student.S# group by SC.S# ,Student.Sname having count(C#)=1;
28)查询男生、女生人数
Select count(Ssex) as 男生人数 from Student group by Ssex having Ssex='男';
Select count(Ssex) as 女生人数 from Student group by Ssex having Ssex='女';
29)查询姓“张”的学生名单
SELECT Sname FROM Student WHERE Sname like '张%';
查30)询同名同性学生名单,并统计同名人数
select Sname,count(*) from Student group by Sname having count(*)>1;
32) 1981年出生的学生名单(注:Student表中Sage列的类型是datetime)
select Sname, CONVERT(char (11),DATEPART(year,Sage)) as age
from student
where CONVERT(char(11),DATEPART(year,Sage))='1981';
32)查询每门课程的平均成绩,结果按平均成绩升序排列,平均成绩相同时,按课程号降序排列
Select C#,Avg(score) from SC group by C# order by Avg(score),C# DESC ;
33)查询平均成绩大于85的所有学生的学号、姓名和平均成绩
select Sname,SC.S# ,avg(score)
from Student,SC
where Student.S#=SC.S# group by SC.S#,Sname having avg(score)>85;
34)查询课程名称为“数据库”,且分数低于60的学生姓名和分数
Select Sname,isnull(score,0)
from Student,SC,Course
where SC.S#=Student.S# and SC.C#=Course.C# and Course.Cname='数据库'and score <60;
35)查询所有学生的选课情况;
SELECT SC.S#,SC.C#,Sname,Cname
FROM SC,Student,Course
where SC.S#=Student.S# and SC.C#=Course.C# ;
36)查询任何一门课程成绩在70分以上的姓名、课程名称和分数;
SELECT distinct student.S#,student.Sname,SC.C#,SC.score
FROM student,Sc
WHERE SC.score>=70 AND SC.S#=student.S#;
37)查询不及格的课程,并按课程号从大到小排列
select c# from sc where scor e <60 order by C# ;
38)查询课程编号为003且课程成绩在80分以上的学生的学号和姓名;
select SC.S#,Student.Sname from SC,Student where SC.S#=Student.S# and Score>80 and C#='003';
39)求选了课程的学生人数
select count(*) from sc;
40)查询选修“叶平”老师所授课程的学生中,成绩最高的学生姓名及其成绩
select Student.Sname,score from Student,SC,Course C,Teacher
where Student.S#=SC.S# and SC.C#=C.C# and C.T#=Teacher.T# and Teacher.Tname='叶平' and SC.score=(select max(score)from SC where C#=C.C# );
41)查询各个课程及相应的选修人数
select count(*) from sc group by C#;
42)查询不同课程成绩相同的学生的学号、课程号、学生成绩
select distinct A.S#,B.score from SC A ,SC B where A.Score=B.Score and A.C# <>B.C# ;
43)查询每门功成绩最好的前两名
SELECT t1.S# as 学生ID,t1.C# as 课程ID,Score as 分数
FROM SC t1
WHERE score IN (SELECT TOP 2 score
FROM SC
WHERE t1.C#= C#
ORDER BY score DESC
)
ORDER BY t1.C#;
44)统计每门课程的学生选修人数(超过10人的课程才统计)。要求输出课程号和选修人数,查询结果按人数降序排列,查询结果按人数降序排列,若人数相同,按课程号升序排列
select C# as 课程号,count(*) as 人数
from sc
group by C#
order by count(*) desc,c#
45)检索至少选修两 门课程的学生学号
select S#
from sc
group by s#
having count(*) > = 2
46)查询全部学生都选修的课程的课程号和课程名
select C#,Cname
from Course
where C# in (select c# from sc group by c#)
47)查询没学过“叶平”老师讲授的任一门课程的学生姓名
select Sname from Student where S# not in (select S# from Course,Teacher,SC where Course.T#=Teacher.T# and SC.C#=course.C# and Tname='叶平');
48)查询两门以上不及格课程的同学的学号及其平均成绩
select S#,avg(isnull(score,0)) from SC where S# in (select S# from SC where score <60 group by S# having count(*)>2)group by S#;
49)检索“004”课程分数小于60,按分数降序排列的同学学号
select S# from SC where C#='004'and score <60 order by score desc;
50)删除“002”同学的“001”课程的成绩
delete from Sc where S#='002'and C#='001';
后续会继续整理归纳
4.查找价格在2000~2900元之间的商品名。

