ETCD
ETCD
慨念
etcd是Go编写的分布式、高可用的一致性键值存储系统,用于提供可靠性的分布式键值存储、配置共享和服务发现等功能:具有以下特点
- 简单易用
易使用:基于HTTP+JSON的API,使用Curl就可以轻松使用
易部署:使用Go语言编写,支持跨平台部署,维护简单 - 可靠
强一致:使用Raft算法充分保证了分布式系统数据的一致性
高可用:具有容错能力,假设集群有N个节点,当有(n-1)/2节点发生故障时,依然能提供服务
持久化:数据更新后,会通过WAL格式数据持久化到磁盘,支持Snapshot快照 - 快速:每个实例每秒可支持一千次写操作,极限写性能可到10K OPS
- 安全:可选SSL客户认证机制
在分布式系统中,如何管理节点间的状态一直是一个难题,etcd像是专门为集群环境的服务发现
和注册而设计,它提供了数据TTL失效、数据改变监视、多值、目录监听、分布式锁原子操作等
功能,可以方便的跟踪并管理集群节点的状态。
主要功能
- 基本的key-value存储
- 监听机制
- key的过期及续约机制,用于监控和服务发现
- 原子Compare And Swap和Compare And Delete,用于分布式锁和leader选举
键值对存储
etcd 是一个键值存储的组件,其他的应用都是基于其键值存储的功能展开。
- 采用kv型数据存储,一般情况下比关系型数据库快。
- 支持动态存储(内存)以及静态存储(磁盘)。
- 分布式存储,可集成为多节点集群。
- 存储方式,采用类似目录结构(B+tree)
- 只有叶子节点才能真正存储数据,相当于文件。
- 叶子节点的父节点一定是目录,目录不能存储数据。
服务注册与发现
服务注册与发现(Service Discovery)要解决的是分布式系统中最常见的问题之一,即在同一个分布式集群中的进程或服务如何才能找到对方并建立连接。从本质上说,服务发现就是要了解集群中是否有进程在监听 UDP 或者 TCP 端口,并且通过名字就可以进行查找和链接。
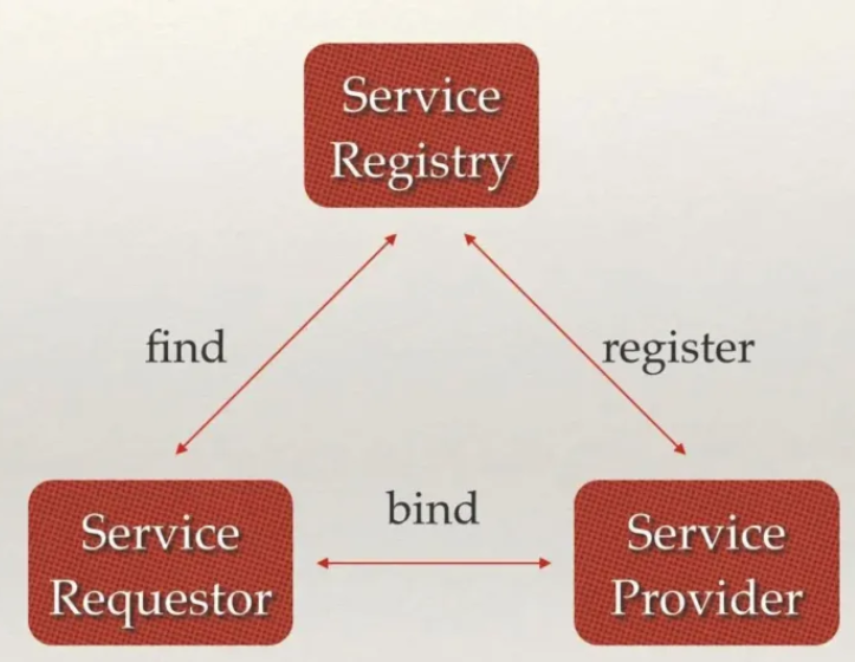
- 强一致性、高可用的服务存储目录。
- 基于 Raft 算法的 etcd 天生就是这样一个强一致性、高可用的服务存储目录。
- 一种注册服务和服务健康状况的机制。
- 用户可以在 etcd 中注册服务,并且对注册的服务配置 key TTL,定时保持服务的心跳以达到监控健康状态的效果。
- 一种查找和连接服务的机制。通过在etcd指定的主题下注册的服务也能在对应的主题下查找到。为了确保连接,我们可以在每个服务机器上都部署一个Proxy模式的etcd,这样就可以确保访问etcd集群的服务都能够互相连接。
消息发布与订阅
- 在分布式系统中,最适用的一种组件间通信方式就是消息发布与订阅。
- 即构建一个配置共享中心,数据提供者在这个配置中心发布消息,而消息使用者则订阅他们关心的主题,一旦主题有消息发布,就会实时通知订阅者。
- 通过这种方式可以做到分布式系统配置的集中式管理与动态更新。
- 应用中用到的一些配置信息放到etcd上进行集中管理。
- 应用在启动的时候主动从etcd获取一次配置信息,同时,在etcd节点上注册一个Watcher并等待,以后每次配置有更新的时候,etcd都会实时通知订阅者,以此达到获取最新配置信息的目的。
![]()

TTL & CAS
Etcd 进行Leader选举的实现主要依赖于etcd自带的两个核心机制,分别是TTL和Atomic Compare-and-Swap。
- TTL(time to live)指的是给一个key设置一个有效期,到期后这个key就会被自动删掉,这在很多分布式锁的实现上都会用到,可以保证锁的实时有效性。
- Atomic Compare-and-Swap(CAS)指的是在对key进行赋值的时候,客户端需要提供一些条件,当这些条件满足后,才能赋值成功。这些条件包括:
- prevExist:key当前赋值前是否存在
- prevValue:key当前赋值前的值
- prevIndex:key当前赋值前的Index
这样的话,key的设置是有前提的,需要知道这个key当前的具体情况才可以对其设置。
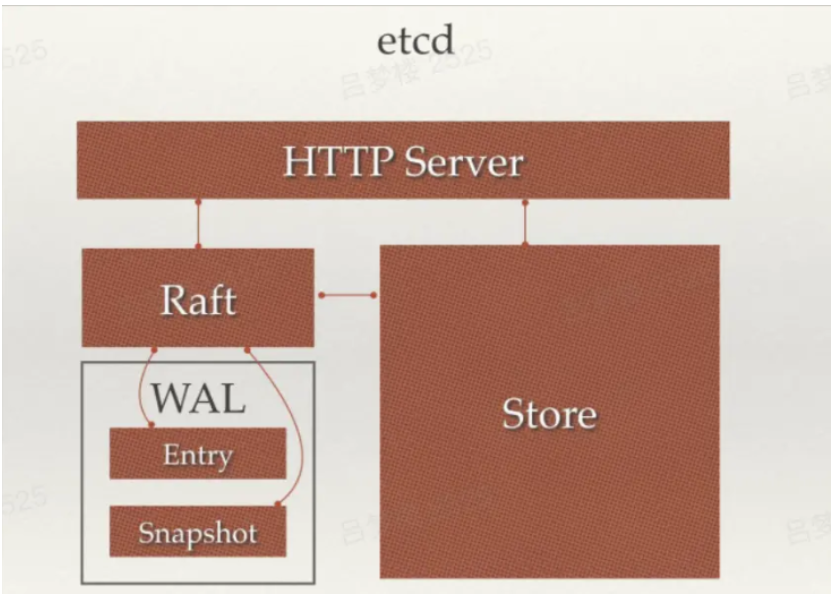
ETCD框架
从ETCD框架图中可以看到,主要分四个部分
- HTTP Server:用于处理用户发送的API请求以及其他etcd节点的同步与心跳信息请求
- Store:用于处理etcd支持的各类功能的事物,包括数据索引、节点状态变更、监控与反馈、事件处理与执行等。是etcd对用户提供的大多数API功能的具体实现
- Raft:Raft强一致性算法的具体实现,是etcd的核心
- WAL:Write Ahead Log(预写式日志),是etcd的数据存储方式。除了在内存中存有所有数据的状态以及节点的索引外,etcd就通过WAL进行持久化存储。WAL中,所有的数据提交前都会事先记录日志。Snapshot是为了防止数据过多而进行的状态快照;Entry表示存储的具体日志内容。
![]()
Raft协议
Raft协议基于quorum机制,即大多数同意原则,任何的变更都需超过半数的成员确认。
http://thesecretlivesofdata.com/raft/
慨念
角色
Raft协议一共包含三类角色:
- Leader(领袖):领袖由群众选举投票选举产生,每次选举,只能选出一名领袖。
- Candidate(候选人):当没有领袖时,某些群众可以称为候选人,然后去竞争领袖的位置
- Follower(群众)
在选举过程中,还会出现以下几个概念
- Leader Election:(领袖选举):简称选举,即为从侯选人中选出领袖。
- Term(任期):其实为一个递增的连续数字,每一次选举都会先将Term+1,每一次任期就会重新发起一次领袖选举
- Election Timeout(选举超时):就是一个超时时间,当群众超时未收到领袖发过来的心跳时,会重新进行选举
角色转换
- 群众 -> 候选人:当开始选举,或选举超时时;
- 候选人 -> 候选人:当"选举超时"时,或者开始新的"任期";
- 候选人 -> 领袖:获取大多数投票时;
- 候选人 - > 群众:其他节点称为领袖,或者开始新的"任期";
- 领袖 -> 群众:自己的Term ID比其他节点Term ID小时,会自动放弃自己的领袖身份;

选举
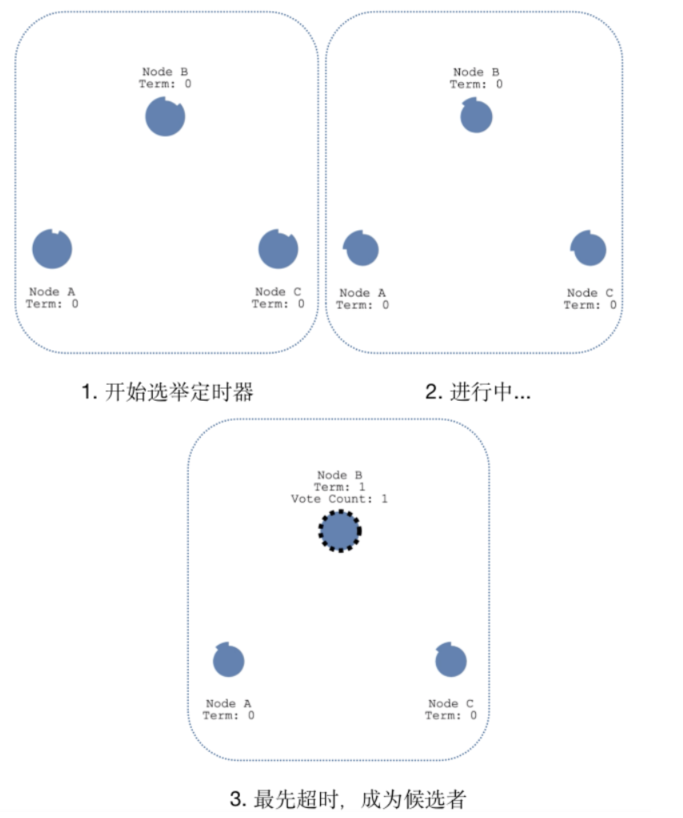
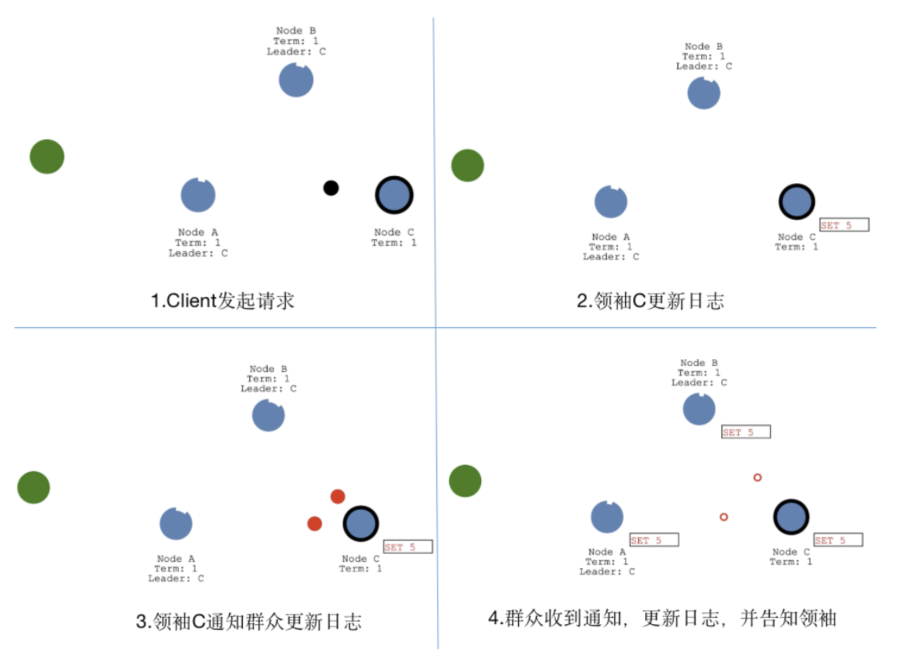
领袖选举
"选举定时器"为每个节点的"超时时间"

成为候选人:每个节点都有自己的"超时时间",超时时间时随机产生的,区间值为"150~300ms",所以出现相同随机时间的概率很小,因为B节点最先超时,这时B节点将称为候选人
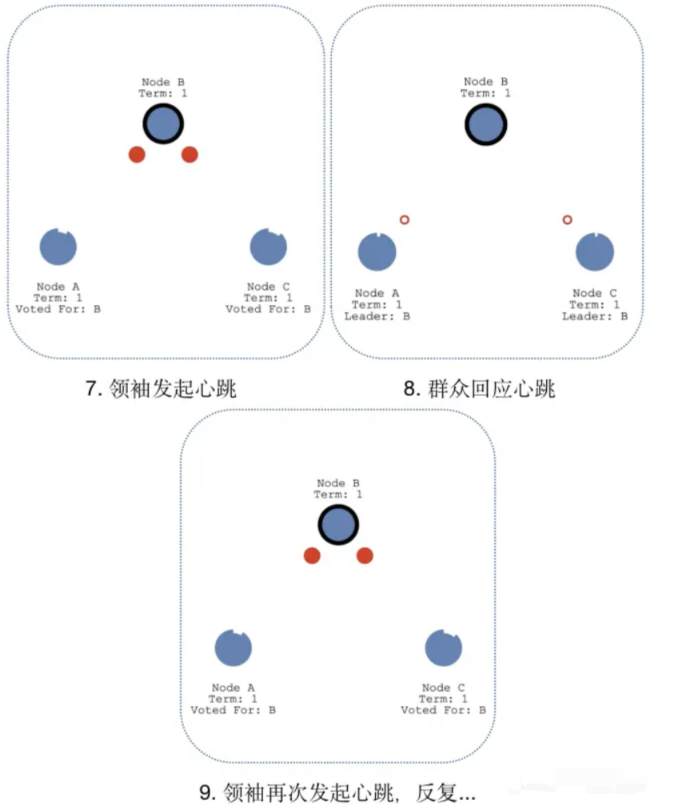
选举领袖:候选人B开始发起投票,群众A和C返回投票,当候选人B获得大多数的投票后,选举成功,候选人B称为领袖。
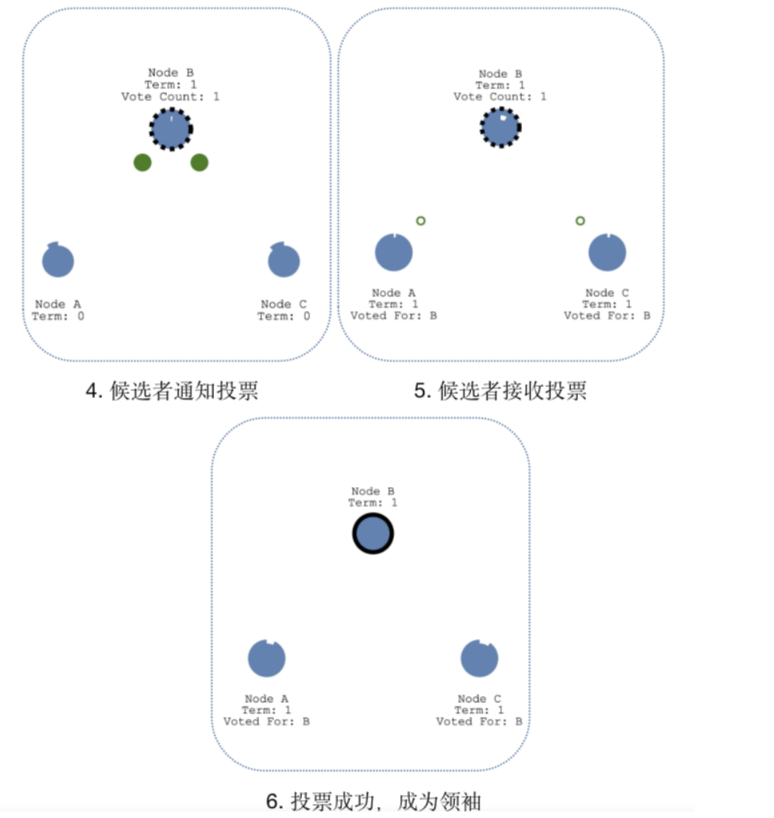
心跳探测:为了时刻宣誓自己的领袖地位,领袖B需要时刻向群众发起心跳,当群众A和C收到领袖B的心跳后,群众A和C的"超时时间"会重置为0,然后重新计数,依次反复
领袖的广播心跳必须短于"选举定时器"的超时时间,否则群众会频繁成为候选人,频繁发起选举投票,出现更换Leader的情况。
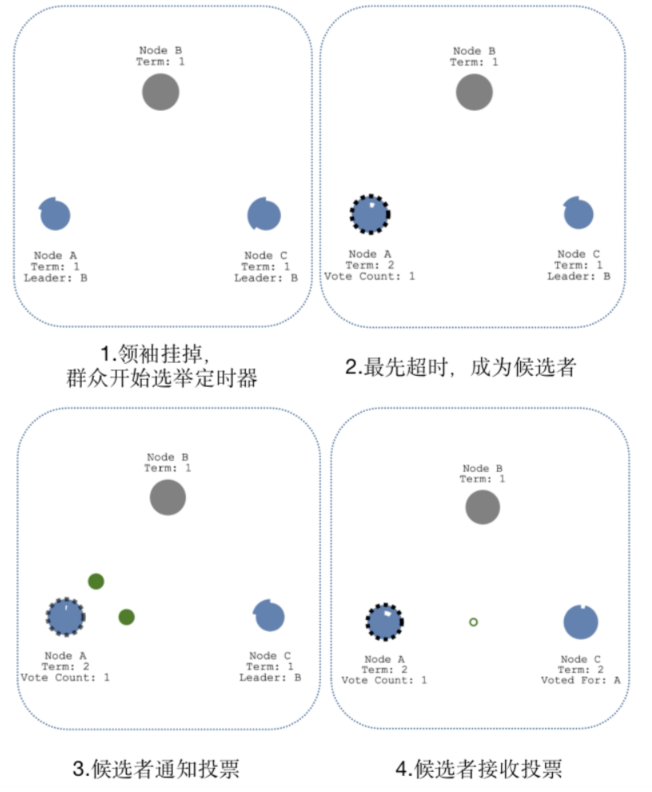
领袖挂掉
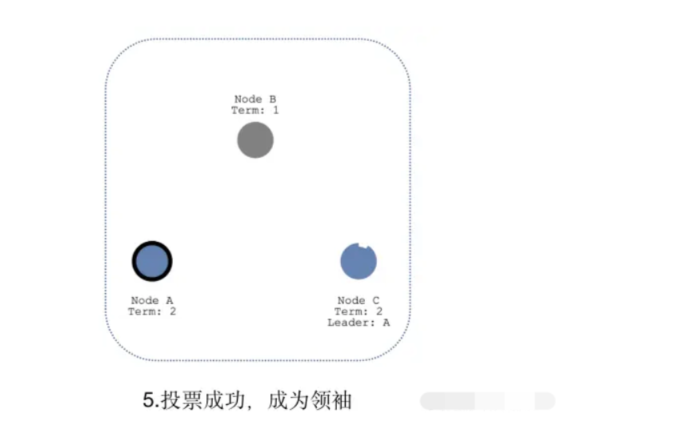
当领袖B挂了,群众A和C的"选举定时器"会一直运行,直到超时,当群众A先超时时,会自动成为候选人,然后后续流程与"领袖选举"一致,即通知投票 -> 接收投票 -> 成为领袖 -> 心跳探测。
多个候选者时
当出现多个候选者A和D时,两个候选者会同时发起投票,如果票数不同,最先得到大部分投票的节点自动成为领袖;如果获取票数相同,会重新发起新一轮投票,Term+1.
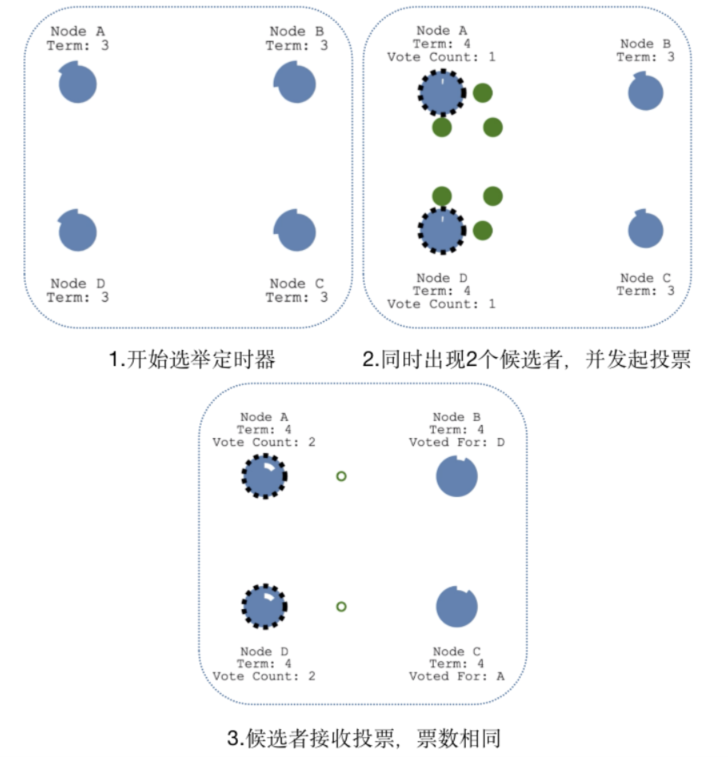
当C成为新的候选者时,此时的任期Term为5,发起新一轮的投票,其他节点发起投票后,会更新自己的任期值,最后选择新的领袖为C节点。

日志复制
复制状态机
复制状态机的基本思想是一个分布式的状态机,系统由多个复制单元组成,每个复制单元均是一个状态机,他的状态保存在操作日志中。如下图所示,服务器上的一致性模块复制接收外部命令,然后追加到自己的操作日志中,它与其他服务器上的一致性模块进行通信,以保证每一个服务器上的操作日志最终都以相同顺序包含相同指令。一旦指令被正确复制,那么每一个服务器的状态机都将按照操作日志的顺序来执行,然后输出结果给客户端。
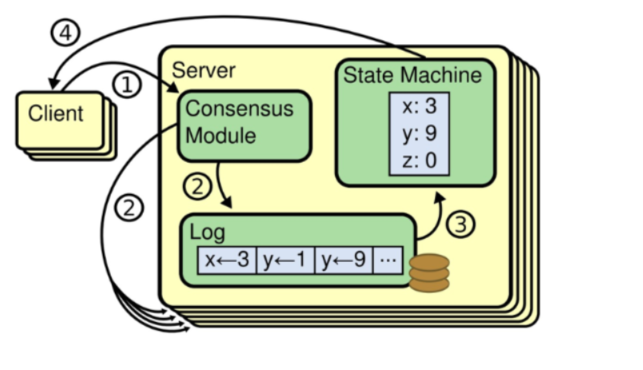
数据同步流程
数据同步流程借鉴了"复制状态机思想",都是先"提交",在"应用"。当Client发起数据更新请求,请求会到领袖节点C,节点C会更新日志数据,然后通知群众节点也更新日志,当群众节点更新日志成功后,会返回成功通知给领袖C,至此完成完成了"提交"操作;当领袖C收到通知后,会更新本地数据,并通知群众也更新本地数据,同时会返回成功通知给Client,至此完成了"应用"操作,如果后续Client又有新的数据更新操作,会重复上诉流程。

日志原理
每一个日志条目一般包括三个属性,整数索引Log Index、任期号Term和指令Commond。每个条目所包含的"整数索引"即该条目在日志文件中的槽位,"任期号"对应到图中就是每个带方块中的数字,用于检测在不同服务器上日志的不一致问题,指令即用于被状态机执行的外部命令,图中就是带箭头的数字。
领袖决定什么时候将日志条目应用到状态机是安全的,即可被提交的呢?一旦领袖创建的条目已经被复制到半数以上的节点上了,那么这个条目就被称为可提交的。如,图中的9号条目在其中4个节点(一共7个节点)上具有复制,所以9号条目是可被提交的;但10号条目只在三个节点上有复制,因此10号条目不是可被提交的。
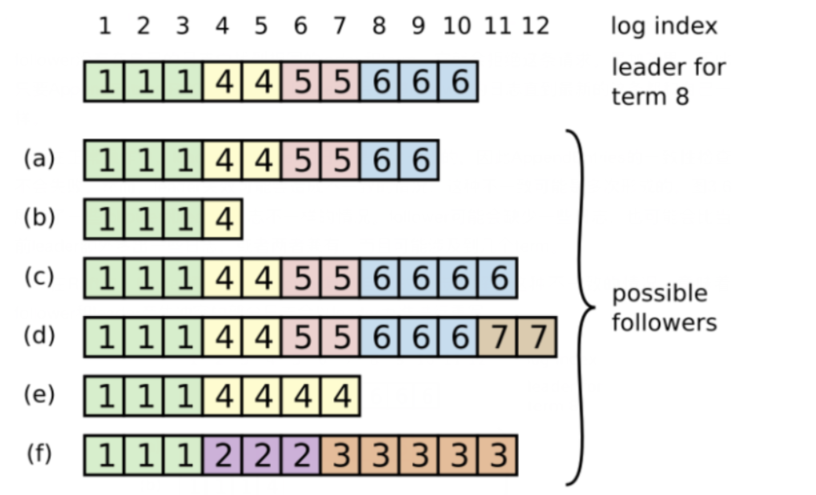
一般情况下,Leader和Follower的日志都是保持一致的,如果Leader节点在故障前没有向其他节点完全复制日志文件之前的所有条目,会导致日不一致问题。在Raft算法中,Leader会强制Follower和自己的日志保持一致,因此Follower的冲突日志会被领导者的日志强制覆写。为了实现这一原理,就需要知道Follower与Leader日志不一致的位置,那么Leader是如何精确找到每个Follower日志不一致的槽位呢?
Leader为每一个Follower维护了一个nextIndex,它表示领袖将要发送给该追随者的下一条日志条目的索引,当一个Leader赢得选举时,它会假设每个Follower上的日志都与自己保持一致,于是先将nextIndex初始化为它最新日志条目所引述+1,在上图中,由于Leader最新的日志条目index是10,所以nextIndex的初始值为11。当Leader向Follower发送AppendEntries RPC时,它携带了(item_id,nextIndex-1)二元组信息,item_id即为nextIndex-1这个槽位的日志条目的Term。Follower接收到AppendEntries RPC消息后,会进行一致性检查,即搜索自己的日志文件中是否存在这样的日志条目,如果不存在,就像Leader返回AppendEntries RPC失败,然后领导人会将nextIndex递减,然后进行重试,直到成功为止。之后的逻辑就比较简单,Follower将nextIndex之前的日志全部保留,之后的全部删除,然后将Leader的nextIndex之后的日志全部同步过来。
以上面的图为例。Leader的nextlndex为11,向b发送AppendEntries RPC(6,10),发现b没有,继续发送(6,9)(6,8) (5,7) (5,6) (4,5),最后发送(4,4)才找到,所以对于b,nextlndex=4之后的日志全部删除,然后将Leader的nextlndex=4的日志全部追加过来。
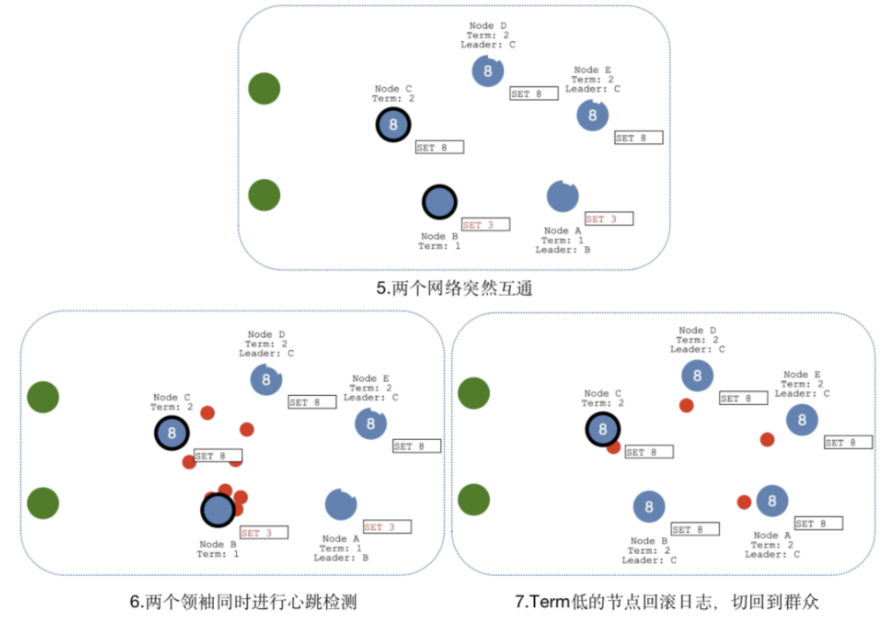
脑裂情况
当网络问题导致脑裂,出现双Leader情况时,每个网络可以理解为一个独立的网络,因为最先的Leader独自在一个区,所以向他提交的数据不可能被复制到大多数节点上,所以数据永远不会被提交,这种情况在图四中出现(SET 3没有提交)
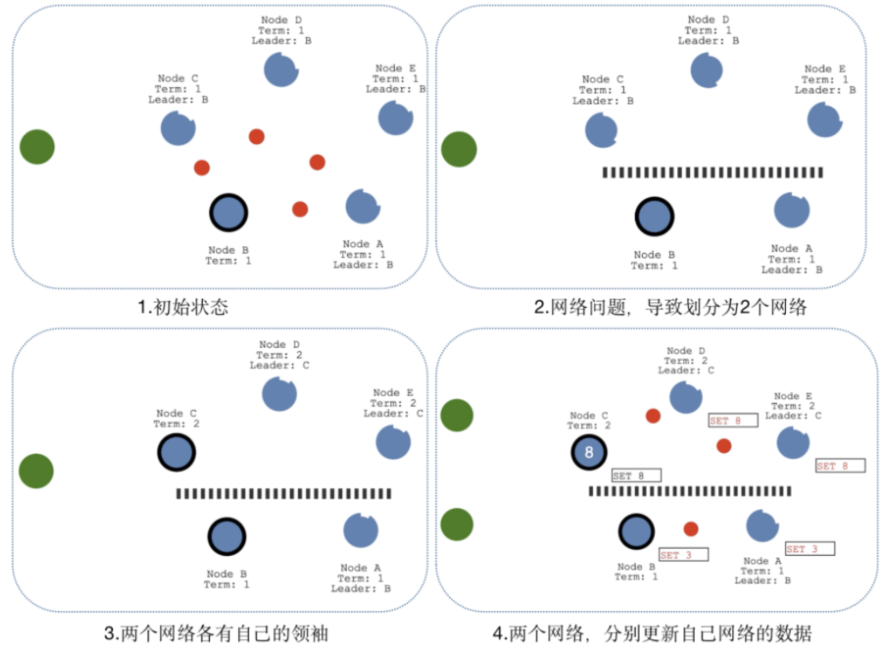
当网络恢复之后,旧的Leader发现集群中的新Leader的Term比自己大,则自动降级为Follower,并从新Leader处同步数据达成集群数据一致,同步数据的方式可以详见"日志原理"。
WAL
ETCD对数据持久化采用的是binlog(日志,也称为WAL,即Write-Ahead-Log)加Snapshot(快照)的方式。
ETCD数据库的所有更新操作都需要先写入到binlog中,而binlog是实时写到磁盘上的,因此这样就可以保证不会丢失数据,即使机器断电,重新启动以后etcd也能通过读取并重放binlog里面的操作记录来重新建立数据库。
ETCD数据的高可用性和一致性是通过Raft算法实现的,Master节点会通过Raft协议向Slave节点复制binlog,Slave节点根据binlog对操作进行重放,以维持数据的多个副本的一致性。也就是说binlog不仅仅是实现数据库持久化的一种手段,其实还是实现不同副本间一致性协议的重要手段。客户端对数据库发起所有写操作都会记录在binlog中,待主节点将更新日志在集群多数节点之间完成同步后,以便内存中的数据库中应用该日志项的内容,进而完成一次客户端的写请求
结构体WAL
结构体WAL,它对外提供了WAL日志文件管理的核心API。在操作WAL日志时,对应的WAL实例有read和append两种模式,新创建的WAL实例处于append模式,该模式下只能向WAL中追加日志。 当恢复一个节点时(例如,宕机节点的重启),就需要读取WAL日志的内容,此时刚打开的WAL实例处于read模式,它只能读取日志记录, 当读取完全部的日志之后,WAL实例转换成append模式,可以继续向其追加日志记录。
WAL文件物理格式
在WAL日志文件中,日志记录是通过Record表示的,该结构体通过Protocol Buffers生成,主要用于序列化和反序列化日志记录。
Etcd所有日志项最终都会被追加存储到WAL文件中,根据Record.Type字段值,可以将日志记录分为如下几种类型。
- metadataType: 该类型日志记录的Data字段中保存了一些元数据,在每个WAL文件的开头,都会记录一条metadataType类型的日志记录。
- entry Type: 该类型日志记录的Data字段中保存的是Entry记录,也就是客户端发送给服务端处理的数据,例如,raftexample示例中客户端发送的键值对数据。
- state Type:该类型日志记录的Data字段中保存了当前集群的状态信息(即HardState),在每次批量写入entry Type类型日志记录之前,都会先写入一条stateType类型的日志记录。代表日志项中存储的内容是Snapshot;
- crc Type:前一个WAL文件里面的数据的crc,也是WAL文件的第一个记录项,该类型的日志记录主要用于数据校验。
- snapshotType: 当前Snapshot的索引{term, index},即当前的Snapshot位于哪个日志记录,不同于stateType,这里只是记录Snapshot的索引,而非snapshot的数据。
每条日志项都有四部分组成:
- Type字段(int64类型):表示该Record实例的类型。
- Crc字段(uint32类型):记录该Record实例的校验码。
- Data字段([]byte 类型):记录真正的日志数据,根据日志的类型不同,Data字段中保存的数据也有所不同。如果snapshotType类型的日志项存储的是快照的日志索引,crcType类型的日志项中则无数据项,其crc字段便充当了数据项
- Padding: 为了保持数据项8子节对其而填充的数据
WAL数据结构定义
type WAL struct {
dir string
dirFile *os.File
metadata []byte
state raftpb.HardState
start walpb.Snapshot
decoder *decoder
readClose func() error
mu sync.Mutex
enti uint64
encoder *encoder
locks []*fileutil.LockedFile
fp *filePipeline
}
核心字段含义
-
dir (string类型):存放WAL日志文件的目录路径。
-
dirFile ( *as.File类型):根据dir路径创建的File实例。
-
metadata ( []byte类型): 在每个WAL日志文件的头部,都会写入metadata元数据。
-
state ( raftpb.HardState 类型): WAL日志记录的追加是批量的,在每次批量写入entryType类型的日志之后,都会再追加一条stateType类型的日志记录,在HardState中记录了当前的Term、当前节点的投票结果和己提交日志的位置。
-
start(walpb.Snapshot类型):每次读取WAL日志时,并不会每次都从头开始读取,而是通过这里的start宇段指定具体的起始位置。walpb.Snapshot中的Index字段记录了对应快照数据所涵盖的最后一条Entry 记录的索引值, Term字段则记录了对应Entry记录的Term值。 在读取WAL日志文件时,我们就可以根据这些信息,找到合适的位置并开始读取记录。
-
decoder ( *decode「类型): 负责在读取WAL日志文件时,将二进制数据反序列化成Record实例。
-
encoder( *encode「类型):负责将写入WAL日志文件的Record实例进行序列化成二进制数据。
-
mu ( sync.Mutex类型):读写WAL日志时需要加锁同步。
-
enti ( uint64类型):WAL中最后一条Entry记录的索引值。
-
locks ( []*fileutil.LockedFile类型): 当前WAL实例管理的所有WAL日志文件对应的句柄。
-
fp ( *filePipeline类型): filePipeline实例负责创建新的临时文件。
filePipeline,它负责预创建日志文件并为日志文件预分配空间。在filePipeline中会启动一个独立的后台goroutine来创建".tmp”结尾的临时文件,当进行日志文件切换时, 直接将临时文件进行重命名即可使用。newFilePipeline()方法中,除了创建filePipeline实例,还会启动一个后台goroutine来执行filePipeline.run()方法,该后台goroutine中会创建新的临时文件并将其句柄传递到filec通道中。在WAL切换日志文件时会调用filePipeline.Open()方法,从filec通道中获取之前创建好的临时文件
WAL文件初始化
etcd的WAL库提供了初始化方法,应用需要显示调用初始化方法来完成日志初始化的功能,初始化方法主要包括两个函数Create()与Open()
日志创建
Create()所做的事情比较简单,具体如下:
- 创建WAL目录,在临时目录中创建编号为“0-0”的WAL日志文件, WAL日志文件名由两部分组成,一部分是seq(单调递增),另一部分是该日志文件中的第一条日志记录的索引值。
- 预分配第一个WAL日志文件,默认是64MB,使用预分配机制可以提高写入性能
- 向该WAL日志文件中写入一条crcType类型的日志记录、一条metadataType类型的日志记录及一条snapshotType类型的日志记录。
- 创建WAL实例关联的filePipeline实例
- 将临时目录重命名为WAL.dir字段指定的名称。
这里之所以先使用临时目录完成初始化操作再将其重命名的方式,主要是为了让整个初始化过程看上去是一个原子操作
wal.Create()具体实现
// Create creates a WAL ready for appending records. The given metadata is// recorded at the head of each WAL file, and can be retrieved with ReadAll// after the file is Open.
func Create(lg *zap.Logger, dirpath string, metadata []byte) (*WAL, error) {
if Exist(dirpath) {
return nil, os.ErrExist
}
if lg == nil {
lg = zap.NewNop()
}
// keep temporary wal directory so WAL initialization appears atomic
// 先在.tmp上修改,修改完后改名,从而保证原子性
tmpdirpath := filepath.Clean(dirpath) + ".tmp"
if fileutil.Exist(tmpdirpath) {
if err := os.RemoveAll(tmpdirpath); err != nil {
return nil, err
}
}
defer os.RemoveAll(tmpdirpath)
if err := fileutil.CreateDirAll(lg, tmpdirpath); err != nil {
lg.Warn(
"failed to create a temporary WAL directory",
zap.String("tmp-dir-path", tmpdirpath),
zap.String("dir-path", dirpath),
zap.Error(err),
)
return nil, err
}
// path: dir/walname
// walname: seq+index
p := filepath.Join(tmpdirpath, walName(0, 0))
// 对当前文件上锁
f, err := fileutil.LockFile(p, os.O_WRONLY|os.O_CREATE, fileutil.PrivateFileMode)
if err != nil {
lg.Warn(
"failed to flock an initial WAL file",
zap.String("path", p),
zap.Error(err),
)
return nil, err
}
// 找到文件末尾
if _, err = f.Seek(0, io.SeekEnd); err != nil {
lg.Warn(
"failed to seek an initial WAL file",
zap.String("path", p),
zap.Error(err),
)
return nil, err
}
// 预分配64MB
if err = fileutil.Preallocate(f.File, SegmentSizeBytes, true); err != nil {
lg.Warn(
"failed to preallocate an initial WAL file",
zap.String("path", p),
zap.Int64("segment-bytes", SegmentSizeBytes),
zap.Error(err),
)
return nil, err
}
// 新建WAL,加上encoder并保存snapshot
w := &WAL{
lg: lg,
dir: dirpath,
metadata: metadata,
}
w.encoder, err = newFileEncoder(f.File, 0)
if err != nil {
return nil, err
}
// 将当前上锁的文件加入到locks数组中(存放已经上锁的文件)
w.locks = append(w.locks, f)
if err = w.saveCrc(0); err != nil {
return nil, err
}
if err = w.encoder.encode(&walpb.Record{Type: metadataType, Data: metadata}); err != nil {
return nil, err
}
if err = w.SaveSnapshot(walpb.Snapshot{}); err != nil {
return nil, err
}
// 将.tmp改名重命名,原子操作
logDirPath := w.dir
if w, err = w.renameWAL(tmpdirpath); err != nil {
lg.Warn(
"failed to rename the temporary WAL directory",
zap.String("tmp-dir-path", tmpdirpath),
zap.String("dir-path", logDirPath),
zap.Error(err),
)
return nil, err
}
var perr error
defer func() {
if perr != nil {
w.cleanupWAL(lg)
}
}()
// directory was renamed; sync parent dir to persist rename
pdir, perr := fileutil.OpenDir(filepath.Dir(w.dir))
if perr != nil {
lg.Warn(
"failed to open the parent data directory",
zap.String("parent-dir-path", filepath.Dir(w.dir)),
zap.String("dir-path", w.dir),
zap.Error(perr),
)
return nil, perr
}
dirCloser := func() error {
if perr = pdir.Close(); perr != nil {
lg.Warn(
"failed to close the parent data directory file",
zap.String("parent-dir-path", filepath.Dir(w.dir)),
zap.String("dir-path", w.dir),
zap.Error(perr),
)
return perr
}
return nil
}
start := time.Now()
// 将上述操作同步
if perr = fileutil.Fsync(pdir); perr != nil {
dirCloser()
lg.Warn(
"failed to fsync the parent data directory file",
zap.String("parent-dir-path", filepath.Dir(w.dir)),
zap.String("dir-path", w.dir),
zap.Error(perr),
)
return nil, perr
}
walFsyncSec.Observe(time.Since(start).Seconds())
if err = dirCloser(); err != nil {
return nil, err
}
return w, nil
}
日志打开
wal模块提供了Open()和OpenForRead()两个函数,两者的区别在于:
使用Open()函数创建的WAL实例读取完全部日志后,可以继续追加日志;而OpenForRead()函数创建的WAL实例只能用于读取日志,不能追加日志.
Open()函数或OpenForRead()函数创建WAL实例之后,就可以调用其ReadAll()方法读取日志了。WAL.ReadAll()方法首先从WAL.start字段指定的位置开始读取日志记录,读取完毕之后,会根据读取的情况进行一系列异常处理。然后根据当前WAL实例的模式进行不同的处理;如果处于读写模式,则需要先对后续的WAL日志文件进行填充并初始化WAL.encoder字段,为后面写入日志做准备;如果处于只读模式下,则需要关闭所有的日志文件。
func (w *WAL) ReadAll() (metadata []byte, state raftpb.HardState, ents []raftpb.Entry, err error) {
w.mu.Lock()
defer w.mu.Unlock()
rec := &walpb.Record{}//创建Record
decoder := w.decoder//解码器,负责读取日志文件,并将日志数据反序列化成Record实例
var match bool //标识是否找到了start字段对应的日志记录
//循环读取WAL日志文件中的数据,多个WAL日志文件的切才是是在decoder中完成的,后面会详细分析其实现
for err = decoder.decode(rec); err == nil; err = decoder.decode(rec) {
switch rec.Type {
case entryType:
e := mustUnmarshalEntry(rec.Data)//反序列化Record.Data中记录的数据,得到Entry
if e.Index > w.start.Index {//将start之后的Entry记录添加到ents中保存
ents = append(ents[:e.Index-w.start.Index-1], e)
}
w.enti = e.Index//记录读取到的最后一条Entry记录的索引值
case stateType:
state = mustUnmarshalState(rec.Data)
case metadataType:
//检测metadata数据是否发生冲突,如果冲突,则抛出异常
if metadata != nil && !bytes.Equal(metadata, rec.Data) {
state.Reset()
return nil, state, nil, ErrMetadataConflict
}
metadata = rec.Data
case crcType:
crc := decoder.crc.Sum32()
if crc != 0 && rec.Validate(crc) != nil {
state.Reset()
return nil, state, nil, ErrCRCMismatch
}
decoder.updateCRC(rec.Crc)//更新deeodr.crc字段
case snapshotType:
var snap walpb.Snapshot
pbutil.MustUnmarshal(&snap, rec.Data)//解析快照相关的数据
if snap.Index == w.start.Index {
if snap.Term != w.start.Term {
state.Reset()
return nil, state, nil, ErrSnapshotMismatch
}
match = true//mateh
}
default:
state.Reset()
return nil, state, nil, fmt.Errorf("unexpected block type %d", rec.Type)
}
}
//根据WAL.locks字段是否有位判断当前WAL是什么模式
switch w.tail() {
case nil:
//对于只读模式,并不需妥将全部的日志都读出来,因为以只读模式打开WAL日志文件时,并没有加锁,所以最后一条日志记录可能只写了一半,从而导致io.ErrUnexpectedEOF异常
if err != io.EOF && err != io.ErrUnexpectedEOF {
state.Reset()
return nil, state, nil, err
}
default:
// 对于读写模式,则需将日志记录全部读出来,所以此处不是EOF异常,则报错,将文件指针移动到读取结束的位置,并将文件后续部分全部填充为0
if err != io.EOF {
state.Reset()
return nil, state, nil, err
}
if _, err = w.tail().Seek(w.decoder.lastOffset(), io.SeekStart); err != nil {
return nil, state, nil, err
}
if err = fileutil.ZeroToEnd(w.tail().File); err != nil {
return nil, state, nil, err
}
}
err = nil
if !match {//如采在读取过程中没有找到与start对应的日志记录, 则抛出异常
err = ErrSnapshotNotFound
}
// close decoder, disable reading
if w.readClose != nil {//如采是只读模式,则关闭所有日志文件
w.readClose()//WAL.readClose实际指向的是WAL.CloseAll()方法
w.readClose = nil
}
w.start = walpb.Snapshot{} //清空start字段
w.metadata = metadata
if w.tail() != nil { //如采是读写模式,则初始化WAL.encoder字段, 为后面写入日志做准备
// create encoder (chain crc with the decoder), enable appending
w.encoder, err = newFileEncoder(w.tail().File, w.decoder.lastCRC())
if err != nil {
return
}
}
w.decoder = nil //清空WAL.decoder字段,后续不能再用该WAL实例进行读取了
return metadata, state, ents, err
}
//brs ( []*bufio.Reader类型): 该decoder实例通过该字段中记录的Reader实例读取相应的日志文件,这些日志文件就是wal.openAtlndex()方法中打开的日志文件。
//lastValidOff ( int64类型):读取日志记录的指针。
func (d *decoder) decodeRecord(rec *walpb.Record) error {
if len(d.brs) == 0 {//检测brs字段长度, 决定是否还有日志文件需要读取
return io.EOF
}
//读取第一个日志文件中的第一个日志记录的长度
l, err := readInt64(d.brs[0])
//是否读到文件尾, 或是读取到了预分目己的部分, 这都表示读取操作结束
if err == io.EOF || (err == nil && l == 0) {
// hit end of file or preallocated space
d.brs = d.brs[1:]//更新brs字段,将其中第一个日志文件对应的Reader清除掉
if len(d.brs) == 0 {//如果后面没有其他日志文件可读则返回EOF异常,表示读取正常结束
return io.EOF
}
d.lastValidOff = 0//若后续还有其他日志文件待读取,则需换文件这里重直lastValidOff
return d.decodeRecord(rec)//递归调用decodeRecord()方法
}
if err != nil {
return err
}
//计算当前日志记录的实际长度及填无数据的长度,并创建相应的data切片
recBytes, padBytes := decodeFrameSize(l)
data := make([]byte, recBytes+padBytes)
if _, err = io.ReadFull(d.brs[0], data); err != nil {//从日志文件中读取指定长度的字节数如读取不到指定的字节数, 则会返回EOF异常,此时返回ErrUnexpectedEOF异常
// ReadFull returns io.EOF only if no bytes were read
// the decoder should treat this as an ErrUnexpectedEOF instead.
if err == io.EOF {
err = io.ErrUnexpectedEOF
}
return err
}
//将0-recBytes反序列化成Record
if err := rec.Unmarshal(data[:recBytes]); err != nil {
if d.isTornEntry(data) {
return io.ErrUnexpectedEOF
}
return err
}
// skip crc checking if the record type is crcType
if rec.Type != crcType {
d.crc.Write(rec.Data)
if err := rec.Validate(d.crc.Sum32()); err != nil {//进行crc校验
if d.isTornEntry(data) {
return io.ErrUnexpectedEOF
}
return err
}
}
// record decoded as valid; point last valid offset to end of record
d.lastValidOff += frameSizeBytes + recBytes + padBytes//将lastValidOff后移,准备读取下一条日志记录
return nil
}
追加日志
WAL对外提供了追加日志的方法,分别是Save()方法和SaveSnapshot()方法。WAL.Save()方法先将待写入的Entry记录封装成entryType类型的Record实例,然后将其序列化并追加到日志段文件中,之后将HardState封装成stateType类型的Record实例,并序列化写入日志段文件中,最后将这些日志记录同步刷新到磁盘。WAL.Save()方法的具体实现如下:
func (w *WAL) Save(st raftpb.HardState, ents []raftpb.Entry) error {
w.mu.Lock()
defer w.mu.Unlock()
//边界检查,如果待写入的HardState和Entry数组都为空,则直接返回;否则就需要将修改同步到磁盘上
if raft.IsEmptyHardState(st) && len(ents) == 0 {
return nil
}
mustSync := raft.MustSync(st, w.state, len(ents))
// 遍历待写入的Entry数生且,将每个Entry实例序列化并封装entryType类型的日志记录,写入日志文件
for i := range ents {
if err := w.saveEntry(&ents[i]); err != nil {
return err
}
}
//将状态信息(HardState) 序列化并封装成stateType类型的日志记录,写入日志文件
if err := w.saveState(&st); err != nil {
return err
}
//获取当前日志段文件的文件指针的位置
curOff, err := w.tail().Seek(0, io.SeekCurrent)
if err != nil {
return err
}
//如未写满预分画己的空间, 将新日志刷新到磁盘后,即可返回
if curOff < SegmentSizeBytes {
if mustSync {
return w.sync()
}
return nil
}
//当前文件大小已超出了预分配的空间, 则需进行日志文件的切换
return w.cut()
}
func (w *WAL) saveEntry(e *raftpb.Entry) error {
// TODO: add MustMarshalTo to reduce one allocation.
b := pbutil.MustMarshal(e)//将Entry记录序列化
//将序列化后的数据封装成entryType类型的Record记录
rec := &walpb.Record{Type: entryType, Data: b}
//通过encoder.encode()方法追加日志记录
if err := w.encoder.encode(rec); err != nil {
return err
}
w.enti = e.Index //更新WAL.enti字段, 其中保存了最后一条Entry记录的索引位
return nil
}
func (w *WAL) sync() error {
if w.encoder != nil {
if err := w.encoder.flush(); err != nil {//先使用encoder.flush() 方法进行同步刷新
return err
}
}
start := time.Now()
err := fileutil.Fdatasync(w.tail().File)//使用操作系统的fdatasync将数据真正刷新到磁盘上
duration := time.Since(start)
if duration > warnSyncDuration {//这里会对该刷新操作的执行时间进行监控, 如采刷新操作执行的时间长于指定的时间(默认值是ls),则输出警告日志
plog.Warningf("sync duration of %v, expected less than %v", duration, warnSyncDuration)
}
syncDurations.Observe(duration.Seconds())
return err
}
//bw ( *iouti l.PageW「ite「类型):PageWriter是带有缓冲区的Writer,在写入时,每写满一个Page大小的缓冲区,就会自动触发一次Flush 操作,将数据同步刷新到磁盘上。每个Page的大小是由walPageBytes常量指定的。
//buf ( []byte类型): 日志序列化之后,会暂存在该缓冲区中, 该缓冲区会被复用, 这就防止了每次序列化创建缓冲区带来的开销。
//uint64buf ( []byte类型):在写入一条日志记录时, 该缓冲区用来暂存一个Frame的长度的数据(Frame 由日志数据和填充数据构成)。
func (e *encoder) encode(rec *walpb.Record) error {
e.mu.Lock()
defer e.mu.Unlock()
e.crc.Write(rec.Data)
rec.Crc = e.crc.Sum32()//计算crc校验码(
var (
data []byte
err error
n int
)
//将待写入到日志记录进行序列化
if rec.Size() > len(e.buf) {//如果日志记录太大,无法复用eneoder.buf这个缓冲区, 则直接序列化
data, err = rec.Marshal()
if err != nil {
return err
}
} else {//复用eneoder.buf这个缓冲区
n, err = rec.MarshalTo(e.buf)
if err != nil {
return err
}
data = e.buf[:n]
}
//计算序列化之后的数据长度,在eneodeFrarneSize()方法中会完成8字节对齐,这里将真正的数据和填充数据看作一个Frame, 返回值分别是整个Frame的长度,以及其中填充数据的长度
lenField, padBytes := encodeFrameSize(len(data))
//将Frame的长度序列化到eneoder.uint64buf数组中,然后写入文件
if err = writeUint64(e.bw, lenField, e.uint64buf); err != nil {
return err
}
if padBytes != 0 {
data = append(data, make([]byte, padBytes)...)//向data中写入填充字节
}
_, err = e.bw.Write(data)//将data中的序列化数据写入文件
return err
}
文件切换
随着WAL日志文件的不断写入, 单个日志文件会不断变大。由于每个日志文件的大小是有上限的,该阀值由SegmentSizeBytes指定(默认值是64MB), 该值也是日志文件预分配磁盘空间的大小。当单个日志文件的大小超过该值时, 就会触发日志文件的切换,该切换过程是在WAL.cut()方法中实现的。WAL.cut()方法首先通过filePipeline获取一个新建的临时文件,然后写入crcType类型、metaType类型、stateType类型等必要日志记录(这个步骤与前面介绍的Create()方法类似),然后将临时文件重命名成符合WAL日志命名规范的新日志文件,并创建对应的encoder实例更新到WAL.encoder字段。
SnapShoter快照
随着节点的运行,会处理客户端和集群中其他节点发来的大量请求,相应的WAL日志量会不断增加,会产生大量的WAL日志文件,另外etcd-raft模块中的raftLog中也会存储大量的Entry记录,这就会导致资源浪费。当节点宕机之后,如果要恢复其状态,则需要从头读取全部的WAL日志文件,这显然是非常耗时的。 为了解决这些问题,etcd会定期创建快照并将其保存到本地磁盘中,在恢复节点状态时会先加载快照文件,使用该快照数据将节点恢复到对应的状态,之后从快照数据之后的相应位置开始读取WAL日志文件,最终将节点恢复到正确的状态。与WAL日志的管理类似,快照管理是snap模块。其中SnapShotter通过文件的方式管理快照数据,它是snapshot模块的核心。在SnapShoter结构体中只有一个dir宇段(string类型),该字段指定了存储快照文件的目录位置。Snapshotter.SaveSnap()方法的主要功能就是将快照数据保存到快照文件中,其底层是通过调用save()方法实现的。save()方法的具体实现如下:
func (s *Snapshotter) save(snapshot *raftpb.Snapshot) error {
start := time.Now()
//创建快照文件名,快照、文件的名称由三部分组成,分别是快照所涵盖的最后一条Entry记录的Term、Index和.snap文件
fname := fmt.Sprintf("%016x-%016x%s", snapshot.Metadata.Term, snapshot.Metadata.Index, snapSuffix)
b := pbutil.MustMarshal(snapshot)//将快照数据进行序列化
crc := crc32.Update(0, crcTable, b)//计算crc
//将序列化后的数据和校验码封装成snappb.Snapshot实例,
//这里简单了解一下raftpb.Snapshot和snappb.Snapshot的区别,前者包含了Snapshot数据及一些元数据(例如,该快照数据所涵盖的最后一条Entry记录的Term和Index);后者则是在前者序列化之后的封笨,其中还记录了相应的校验码等信息
snap := snappb.Snapshot{Crc: crc, Data: b}
d, err := snap.Marshal()
if err != nil {
return err
} else {
marshallingDurations.Observe(float64(time.Since(start)) / float64(time.Second))
}
//将snappb.Snapshot序列化后的数据写入文件,并同步刷新到磁盘
err = pioutil.WriteAndSyncFile(filepath.Join(s.dir, fname), d, 0666)
if err == nil {
saveDurations.Observe(float64(time.Since(start)) / float64(time.Second))
} else {
err1 := os.Remove(filepath.Join(s.dir, fname))
if err1 != nil {
plog.Errorf("failed to remove broken snapshot file %s", filepath.Join(s.dir, fname))
}
}
return err
}
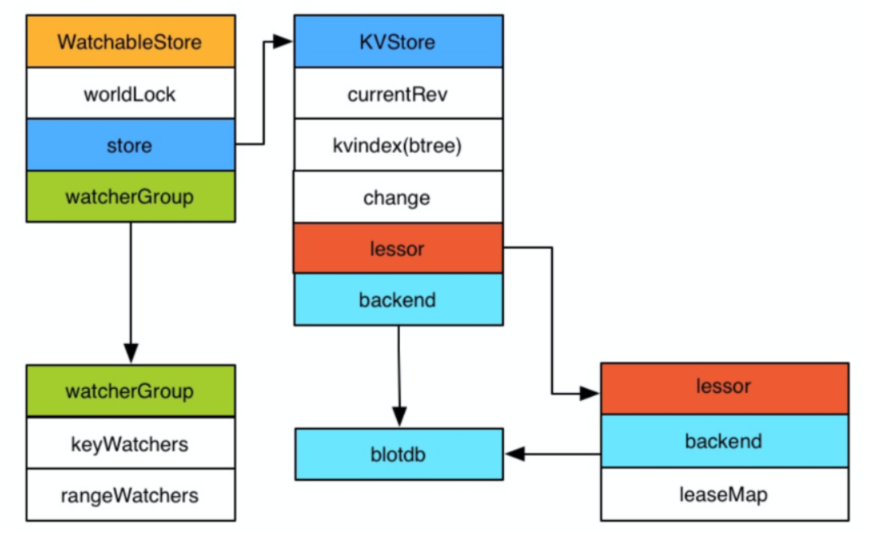
Store
Etcd v3 store分为两部分,一部分是内存中的索引,kvindex是基于google开源的一个golang的btree实现的,另外一部分是后端存储。按照它的设计,backend可以对接多种存储,当前使用的boltdb。boltdb是一个单机的支持事务的kv存储,Etcd的事务是基于boltdb的事务实现的。Etcd在boltdb中存储的key是revision,value是Etcd自己的key-value组合,也就是说Etcd会在boltdb中把每个版本都保存下,从而实现 了多版本机制。
用 etcdctl 通过批量接口写入两条记录:
etcdctl txn <<<'
put key1 "v1"
put key2 "v2"
'
再通过批量接口更新这两条记录:
etcdctl txn <<<'
put key1 "v12"
put key2 "v22"
'
boltdb 中其实有了 4 条数据:
rev={3 0}, key=key1, value="v1"
rev={3 1}, key=key2, value="v2"
rev={4 0}, key=key1, value="v12"
rev={4 1}, key=key2, value="v22"
revision主要由两部分组成,第一部分main rev,每次事务进行加一,第二部分sub rev,同一个事务中每次操作加一。如上所示,第一次操作的main rev是3,第二次4。
通过Ectd的磁盘存储,可以看出如果要从boltdb中查询数据,必须通过revision,但客户端都是通过key来查询value,所以Etcd的内存kvindex保存的就是key和revision之前的映射关系,用来加速查询。
Etcd v3的watch机制支持watch某个固定的key,也支持watch一个范围(可以用于模拟目录的结构的watch),所以watchGroup包含两种watcher,一种是key watchers,数据结构是每个key对应一组watcher,另 外一种是range watchers, 数据结构是一个IntervalTree,方便通过区间查找到对应的watcher。
同时,每个WatchableStore包含两种watcherGroup,一种是synced,一种是unsynced,前者表示该group的watcher数据都已经同步完毕,在等待新的变更,后者表示该group的watcher数据同步落后于当前最新变更,还在追赶。
当Etcd收到客户端的watch请求,如果请求携带了revision参数,则比较请求的revision和store当前的revision,如果大于当前revision,则放入synced组中,否则放入unsynced组。同时Etcd会启动一个后台的goroutine持续同步unsynced的watcher,然后将其迁移到synced组。也就是这种机制下,Etcd v3支持从任意版本开始 watch,没有v2的1000条历史event表限制的问题。
Etcd v2在通知客户端时,如果网络不好或者客户端读取比较慢,发生了阻塞,则会直接关闭当前连接,客户端需要重新发起请求。Etcd v3为了解 决这个问题,专门维护了一个推送时阻塞的watcher队列,在另外的goroutine里进行 重试。
Etcd v3对过期机制也做了改进,过期时间设置在lease上,然后key和lease关联。 这样可以实现多个key关联同一个lease id,方便设置统一的过期时间,以及实现批量续约。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号