Kubernetes调度器
概况
在Kubernetes中,调度(scheduling)指的是确保Pod匹配到合适的节点,以便kubectl能够运行Pod。调度的工作由调度器和控制器协调完成。
调度器通过Kubernetes的监测(Watch)机制来发现集群中新创建且尚未被调度到节点上的Pod。调度器会将所发现的每一个未调度的Pod调度到一个合适节点上来运行。调度器会根据上下文的调度原则来做出调度选择。控制器会将调度写入Kubernetes的API Server中。
Kube-Scheduler
Kube-Scheduler是Kubernetes集群的默认调度器,并且是集群控制面的一部分。对每一个新创建的Pod或者未被调度的Pod,Kube-Scheduler会选择一个最优的节点去运行这个Pod。
在一个集群中,满足一个Pod调度请求的所有节点称之为可调度节点。如果没有任何一个节点能满足Pod的资源请求,那么这个Pod将一直停留在未调度状态直到调度器能够找到合适的Node。
调度器先在集群中找到一个Pod的所有可调度节点,然后根据一系列函数对这些可调度节点打分,从中选出得分最高的节点来运行Pod。之后,调度器将这个调度决定通知给Kube-Apiserver,这个过程称之为绑定(Bind)。
在做调度决定时需要考虑的因素包括:单独和整体的资源请求、硬件/软件/策略限制、亲和和以及反亲和要求、数据局部性、负载间的干扰等。
kube-scheduler 调度流程
Kube-Scheduler主要作用就是根据特定的调度算法和调度策略将Pod调度到合适的Node节点上,是一个独立的二进制程序,启动之后会一直监听API Server,获取到PodSpec.NodeName未空的Pod,对每个Pod都会创建一个Binding。
kube-scheduler给一个Pod做调度选择时包含两个步骤:
过滤(Filtering)
打分(Scoring)
过滤(Filtering)
Pod内的每一个容器对资源都有不同的需求,而且Pod本身也有不同的需求。因此Pod在被调度到节点上之前,根据这些特定的调度需求,需要对集群中的节点进行一次过滤。
过滤阶段会将所有满足Pod调度需求的节点选出来。如PodFitsResources过滤函数会检查候选节点的可用资源能否满足Pod的资源请求。在过滤之后,得出一个节点列表,里面包含了所有可调度节点;通常情况下,这个节点列表包含不止一个节点。如果这个列表是空的,代表这个Pod不可调度。
打分(Scoring)
打分阶段,调度器会为Pod从所有可调度节点中选取一个最合适的节点。根据当前启动的打分规则,调度器会给每一个可调度节点进行打分。最后,kube-scheduler会将Pod调度到得分最高的节点上。如果存在多个得分最高的节点,kube-scheduler会从中随机选择一个。
配置调度策略
可以通过修改配置文件(KubeSchedulerConfiguration)中的调度策略(Scheduling Policies)和调度配置(Scheduling Profiles),可以定义自己的配置调度器的过滤和打分行为。调度策略(Scheduling Policies)允许你配置过滤所用的断言(Predicates)和打分所用的优先级(Priorities);调度配置(Scheduling Profiles)允许你配置实现不同调度阶段的插件,包括:QueueSort、Filter、Score、Bind、Reserve、Permit 等等。
Predicates常用过滤算法
- PodFitsResources:节点上剩余的资源是否大于Pod请求的资源
- PodFitsHost:如果Pod 指定了NodeName,检查节点名称是否和NodeName匹配
- PodFitsHostPorts:节点上已经使用的port是否和Pod申请的port冲突
- PodSelectorMatches:过滤掉和Pod指定的label不匹配的节点
- NoDiskConflict:已经mount的volume和Pod指定的volume不冲突,除非它们都是只读的
- CheckNodeDiskPressure:检查节点磁盘空间是否符合要求
- CheckNodeMemoryPressure:检查节点内存是否够用
Priorities优先级
Priorities优先级是由一系列键值对组成的,键是该优先级的名称,值是它的权重值,常用选项有
- LeastRequestedPriority:通过计算CPU和内存的使用率来决定权重,使用率越低权重越高,当然正常肯定也是资源是使用率越低权重越高,能给别的Pod运行的可能性就越大
- SelectorSpreadPriority:为了更好的高可用,对同属于一个Deployment或者RC下面的多个Pod副本,尽量调度到多个不同的节点上,当一个Pod被调度的时候,会先去查找该Pod对应的controller,然后查看该controller下面的已存在的Pod,运行Pod越少的节点权重越高
- ImageLocalityPriority:就是如果在某个节点上已经有要使用的镜像节点了,镜像总大小值越大,权重就越高
- NodeAffinityPriority:这个就是根据节点的亲和性来计算一个权重值
Scheduler framework
在具体的调度流程中,默认调度器会首先调用一组叫作Predicate的调度算法,来检查每个Node。然后,再调用一组叫作Priority的调度算法,来给上一步得到的结果里的每个Nod 打分。最终的调度结果,就是得分最高的那个Node。
Kubernetes调度器中大多数的调度功能,通过调度框架(framework)这一插件架构中一个一个具体的调度插件实现。它通过向现有的调度器添加了一组新的"插件"API,编译过程中插件编与调度器打包。
调度框架(framework)定义了一些扩展点。调度器插件注册后在一个或多个扩展点处被调用。 这些插件中的一些可以改变调度决策,而另一些仅用于提供信息。
每次调度一个Pod的尝试都分为两个阶段,调度周期和绑定周期。
- 调度周期为Pod选择一个节点,绑定周期将该决策应用于集群。
- 调度周期和绑定周期一起被称为“调度上下文”。
调度周期是串行运行的,而绑定周期可能是同时运行的。
如果确定Pod不可调度或者存在内部错误,则可以终止调度周期或绑定周期。 Pod将返回队列并重试。
下图显示了一个Pod的调度上下文以及调度框架公开的扩展点。 在此图片中,"过滤器"等同于"断言","评分"相当于"优先级函数"。
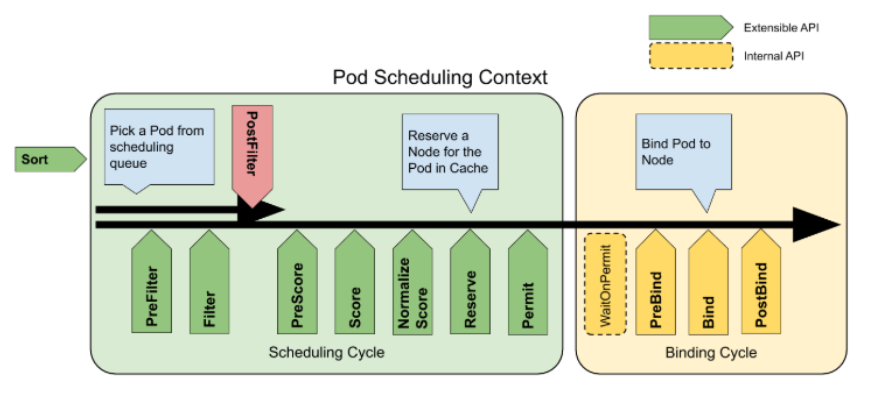
一个插件可以在多个扩展点处注册,以执行更复杂或有状态的任务。
调度框架扩展点
-
Sort
用于对调度队列进行排序。队列排序插件本质上提供less(Pod1, Pod2)函数,一次只能启动一个队列插件。 -
PreFilter
用于预处理Pod相关信息,或者检查集群或Pod必须满足的某些条件。如果PreFilter插件返回错误,则调度周期将终止。 -
Filter
用于过滤出不能运行该Pod的节点。对于每个节点,调度器将按照其配置顺序调用这些过滤插件。如果任何过滤插件将节点标记为不可行,则不会为该节点调用剩下的过滤插件。节点可以被同时进行评估。 -
PostFilter
插件在Filter后调用,但仅在该Pod没有可行的节点时调用。插件按其配置的顺序调用。如果任何PostFilter插件标记节点为"Schedulable",则其余插件不会调用。典型的PostFilter实现是抢占,试图通过抢占其他Pod的资源使该Pod可以调度。 -
PreScore
插件用于执行"前置评分(pre-scoring)"工作,即生成一个可共享状态供Score插件使用。如果PreScore插件返回错误,则该调度周期将终止。 -
Score
用于对过滤阶段的节点进行过滤。调度器将为每个节点调用每个评分插件。将有一个定义明确的整数范围,代表最小和最大分数。在标准化评分阶段后,调度器将根据配置的插件权重合并所有插件的节点分数。 -
NormalizeScore
插件用于在调度器计算Node排名之前修改分数。在此扩展到注册的插件被调用时会使用同一插件的Score结果,每个插件在每个调度周期调用一次。 -
Reserve
Reserve是一个信息扩展点。管理运行时状态的插件(也称为有状态插件)应用使用此扩展点,以便调度器在节点给指定Pod预留了资源时能够通知该插件。这是在调度器真正将Pod绑定到节点之前发生的,并且它存在是为了防止在调度器等待绑定成功时发送竞争情况。 -
Permit
是调度周期的最后一步,一旦Pod处于保留状态,它将在绑定周期结束时触发Unreserve插件(失败时)或PostBind插件(成功时)
Permit插件在每个Pod调度周期的最后调用,用于防止或延迟Pod的绑定。一个允许插件可以做以下三件事之一:- 批准
一旦所有Permit插件批准Pod后,该Pod将被发送以进行绑定。 - 拒绝
如果任何Permit插件拒绝Pod,则该Pod将被返回到调度队列。 这将触发Unreserve插件。 - 等待(带有超时)
如果一个Permit插件返回“等待”结果,则Pod将保持在一个内部的“等待中”的Pod列表,同时该Pod的绑定周期启动时即直接阻塞直到得到批准。如果超时发生,等待变成拒绝,并且Pod将返回调度队列,从而触发Unreserve插件。
说明: 尽管任何插件可以访问“等待中”状态的Pod列表并批准它们(查看 FrameworkHandle)。 我们期望只有允许插件可以批准处于“等待中”状态的预留Pod的绑定。 一旦Pod被批准了,它将发送到PreBind阶段。
- 批准
-
PreBind
插件用于执行Pod绑定前所需的所有工作。 例如,一个PreBind插件可能需要制备网络卷并且在允许Pod运行在该节点之前将其挂载到目标节点上。如果任何PreBind插件返回错误,则Pod将被拒绝并且退回到调度队列中。 -
Bind
Bind插件用于将Pod绑定到节点上。直到所有的PreBind插件都完成,Bind插件才会被调用。 各Bind插件按照配置顺序被调用。Bind插件可以选择是否处理指定的Pod。 如果某Bind插件选择处理某Pod,剩余的Bind 插件将被跳过。 -
PostBind
这是个信息性的扩展点。 PostBind插件在Pod成功绑定后被调用。这是绑定周期的结尾,可用于清理相关的资源。 -
Unreserve
这是个信息性的扩展点。 如果Pod被保留,然后在后面的阶段中被拒绝,则Unreserve插件将被通。Unreserve插件应该清楚保留Pod的相关状态。
Kube-scheduler主流程分析
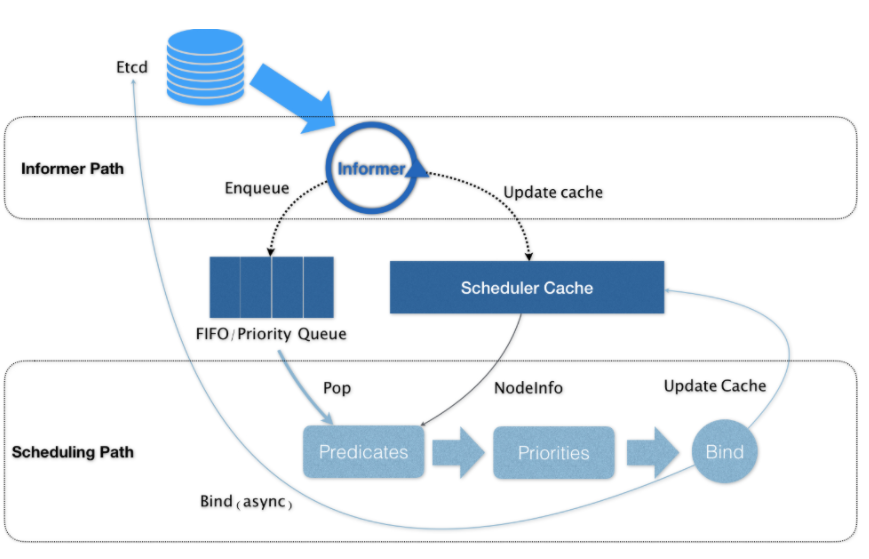
Kebernetes的调度器的核心,实际上就是两个相互独立的控制循环。
第一个控制循环Informer Path待调度Pod添加进调度队列
其中,第一个控制循环,我们可以称之为Informer Path。它的主要目的,是启动一系列Informer,用来监听(Watch)Etcd中Pod、Node、Service等与调度相关的API对象的变化。
比如,当一个待调度Pod(即:它的nodeName字段是空的)被创建出来之后,调度器就会通过Pod Informer 的Handler,将这个待调度Pod添加进调度队列。
在默认情况下,Kubernetes 的调度队列是一个 PriorityQueue(优先级队列),并且当某些集群信息发生变化的时候,调度器还会对调度队列里的内容进行一些特殊操作。这里的设计,主要是出于调度优先级和抢占的考虑。
此外,Kubernetes的默认调度器还要负责对调度器缓存(即:scheduler cache)进行更新。事实上,Kubernetes调度部分进行性能优化的一个最根本原则,就是尽最大可能将集群信息Cache化,以便从根本上提高Predicate和Priority调度算法的执行效率。
第二个控制循环Scheduling Path Predicates算法进行"过滤" , 调用Priorities算法为Node打分
Scheduling Path的主要逻辑,就是不断地从调度队列里出队一个Pod。然后调用Predicates算法进行"过滤"。这一步"过滤"得到的一组Node,就是所有可以运行这个Pod的宿主机列表。当然,Predicates算法需要的Node信息,都是从Scheduler Cache里直接拿到的,这是调度器保证算法执行效率的主要手段之一。
接下来,调度器就会再调用Priorities算法为上述列表里的Node打分,分数从0到10。得分最高的Node,就会作为这次调度的结果。
调度算法执行完成后,调度器就需要将Pod对象的nodeName字段的值,修改为上述Node的名字。这个步骤在Kubernetes里面被称作Bind。
NodeName:一旦Pod的这个字段被赋值,Kubernetes项目就会被认为这个Pod已经经过了调度,调度的结果就是赋值的节点名字。所以,这个字段一般由调度器负责设置。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号