
Kubernetes控制器工作流程
Kubernetes控制器会监视资源的创建/更新/删除事件,并触发Reconcile函数作为响应。
Kubernetes水平触发API的实现方式为:监视系统的实际状态,并与对象的Spec中定义的期望状态进行对比,然后调用Reconcile函数来调整实际状态,使之与期望状态相匹配。
控制器结构
每个控制器都有两个核心组件:Informer/sharedInformer和Workqueue,其中Informer/sharedInformer 负责watch Kubernetes资源对象的状态变化,将后将相关时间发送到Workqueue中,最后有控制器的work从Workqueue中取出事件交给控制器处理程序进行处理。
Informer
控制器的主要作用是watch资源对象的当前状态和期望状态,然后发送指令来调整当前状态,使之更接近期望状态。为了获得资源对象当前状态的详细信息,需要向API Server发送请求。
但频繁的调用API Server 非常消耗集群资源,因此为了能够多次get/list对象,Kubernetes引用了client-go库提供的缓存机制。控制器不需要频繁的调用API Server,只有当资源对象被创建/修改或删除时,才需要获取相关事件。client-go库提供了ListWatcher接口来获取资源的全部Object,缓存在内存中;然后控制器调用Watch api去watch 缓存在内存中的数据。
SharedInformer
由于Kubernetes中运行了很多的控制器,有很多资源需要管理,难免会出现一份资源受多个控制器管理的情况,为了应对这种情况,可以通过SharedInformer来创建一份供多个控制器共享的缓存。
使用了SharedInformer之后,不管有多少个控制器同时读取事件,SharedInformer 只会调用一个Watch API 来watch API Server,大大降低API Server的负载。
Workqueue
由于SharedInformer提供的缓存时共享的,所以无法跟踪每个控制器,这就需要控制器自己实现排队和
重试机制。因此大多数Resource Event Handler所做的工作只是将事件放入消费者工作队列中。每当资源被修改时,Resource Event Handler 就会放入一个key到Workqueue中。key的表示形式为<resource_namespace>/<resource_name>,如果提供了<resource_namespace>,key的表现形式为<resource_name>,每个事件都以key作为标识,因此每个消费者都可以使用worker从Workqueue中读取key。所有的读取动作都是穿行的,这就保证了不会出现两个worker同时读取同一个key的情况。
workqueue是主要用来辅助Informer对事件进行分发的队列,主要流程如下
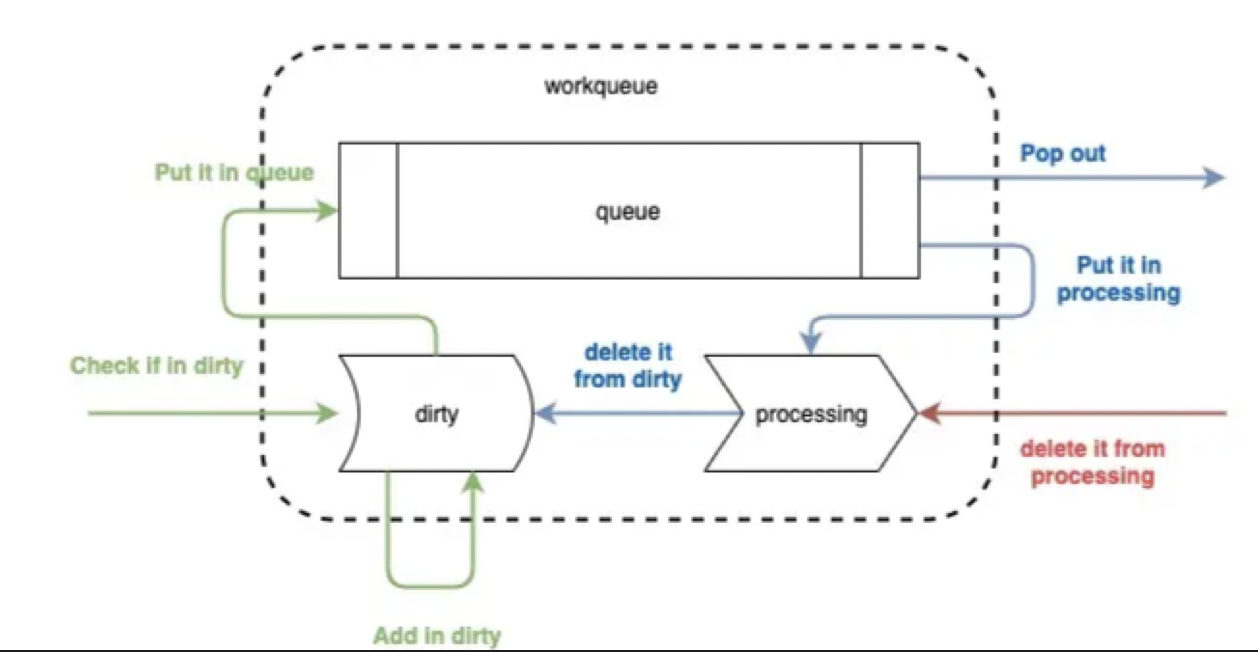
workqueue主要分为三部分,一是一个先入先出的队列,由切片来实现;另外两个是名为dirty和processing的map。
workqueue整个工作流程分为三个动作,add/get/done
add:将消息推入队列。消息从Informer过来,消息为资源的key,即<resource_namespace>/<resource_name>,以这种形式通知业务逻辑有资源变更的事件,然后使用key去indexer中获取具体资源。如上图绿色所示。在消息key过来之后,先检查dirty中是否存在,若已存在,不做任何处理,标明事件已经在队列中,不需要重复处理rolloutRolling;若dirty不存在,则将该key存入dirty中,再推入队列一份。
get:为handler函数从队列中获取key的过程。将key从队列中pop出来的同时,会将其放入processing中,并删除在dirty中的索引。这一步的原因是将item放入processing中标识正在被处理,同时从dirty删除key,不影响后面的事件入队列。
done:handler处理完key之后,必须执行的一步,想当于给workqueue发一个ack,标明已经处理完毕,该动作仅仅将其从processing中删除。
Deployment控制器
Deployment没有直接管理Pod,而是通过管理RS来实现对Pod副本的控制,Deployment通过对RS的控制实现了版本管理,每次发布对应一个新的版本,每个版本有一个RS,在注释中标明版本号,而RS在每次根据pod template和副本数运行相应的Pod,deployment只需要保证任何情况下RS的状态都在预期,RS保证任何情况下pod的状态在预期。
Deployment工作流程
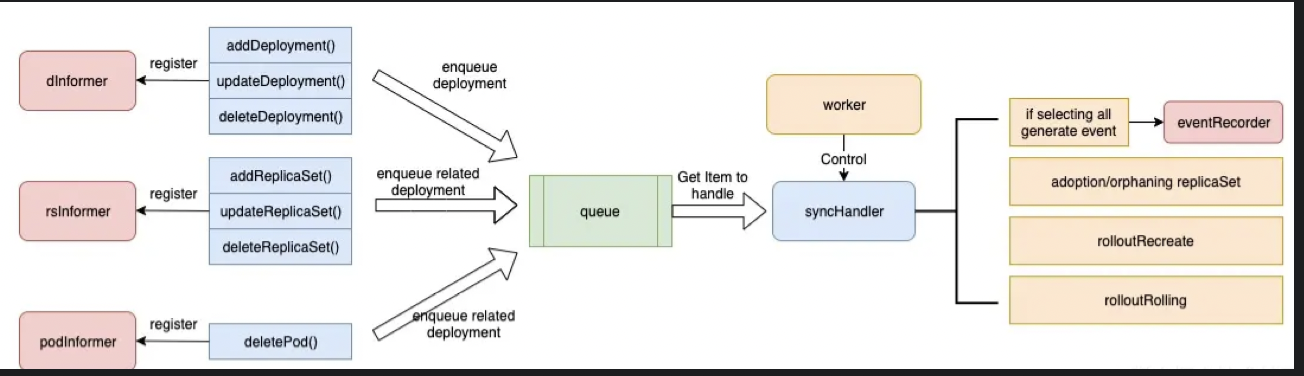
首先Deployment会向三个sharedInformer(deployment informer/rs informer/pod informer)中注册钩子函数,三个钩子函数会在相应事件到来时,将相关deployment推进到workqueue中。
deploymeny启动时,会有一个worker控制的syncHandler函数,实时将workqueue中的item推出,根据item来执行对应的任务,主要包括领养和弃养RS,向EventRecorder分发事件,根据升级策略决定如何处理下级资源。
ReplicaSet认领
在RS的三个钩子函数中,都会涉及到领养的过程。
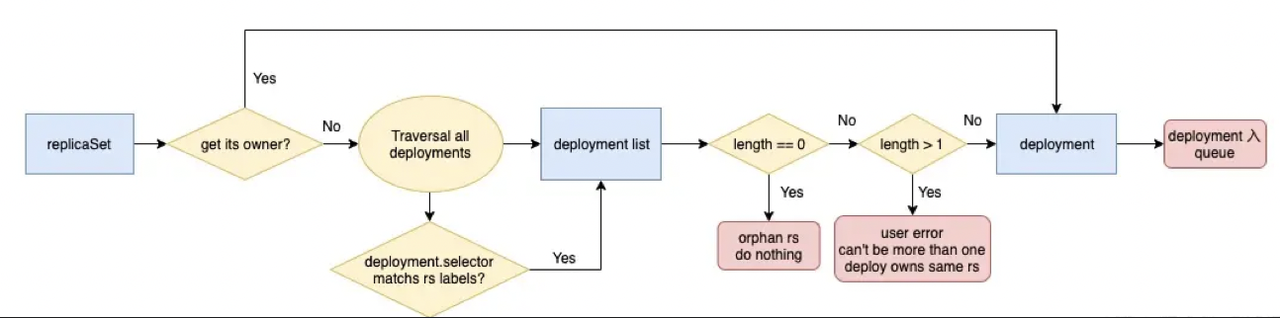
当RS Informer监听到RS的变化后,会根据RS 的ownerReferences字段找到对应的Deployment将其放入Queue;标明该RS已被Deploymeny认领。 若该字段为空,则意味着是个孤儿,将启动认领机制。
认领过程
- 首先,遍历所有的Deploymeny,判断Deployment的Selector是否于当前RS的Labels相匹配,找到所有相匹配的deployment。
- 其次,判断总共有多个个deploymeny,若为0个,表示没人认领,认领流程结束。若大于1个,将抛出异常,因为这是不正常的行为,不允许多个deployment认领一个RS;若有且仅有一个Deployment与之匹配,那么将被该Deployment认领,将其放入Queue。
Deployment领养和弃养
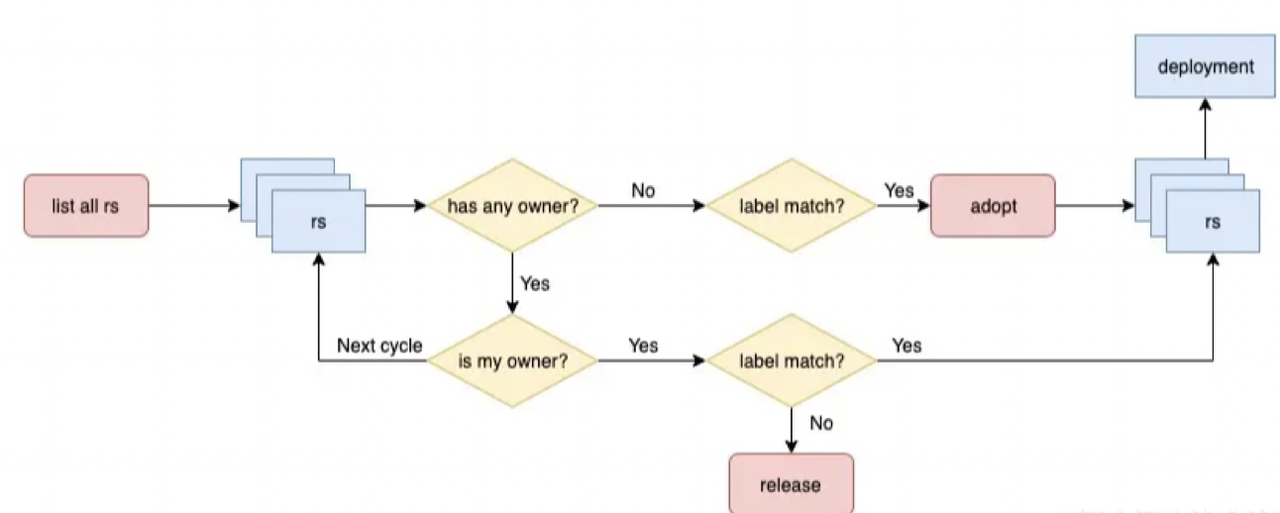
该过程发生在Workqueue中处理item的过程,也是找到当前Deployment拥有所有RS的过程。
- 该过程会轮询所有RS,如果有ownerReferences,且ownerReferences为当前的Deployment,再判断Label是否满足Deployment的Selector,满足则入队列。若不满足,启动弃养流程,仅仅将RS的ownerReferences 删除,使其成为孤儿,不做其他事情。这也是为什么会在修改了deployment之后会多一个replicat != 0的原因。
- 如果RS没有Owner,是个孤儿,判断Label是否满足Deployment的Selector,若满足条件,则启动领养机制,将其ownerReferences设置为当前Deployment,在放入队列。
rolloutRecreate
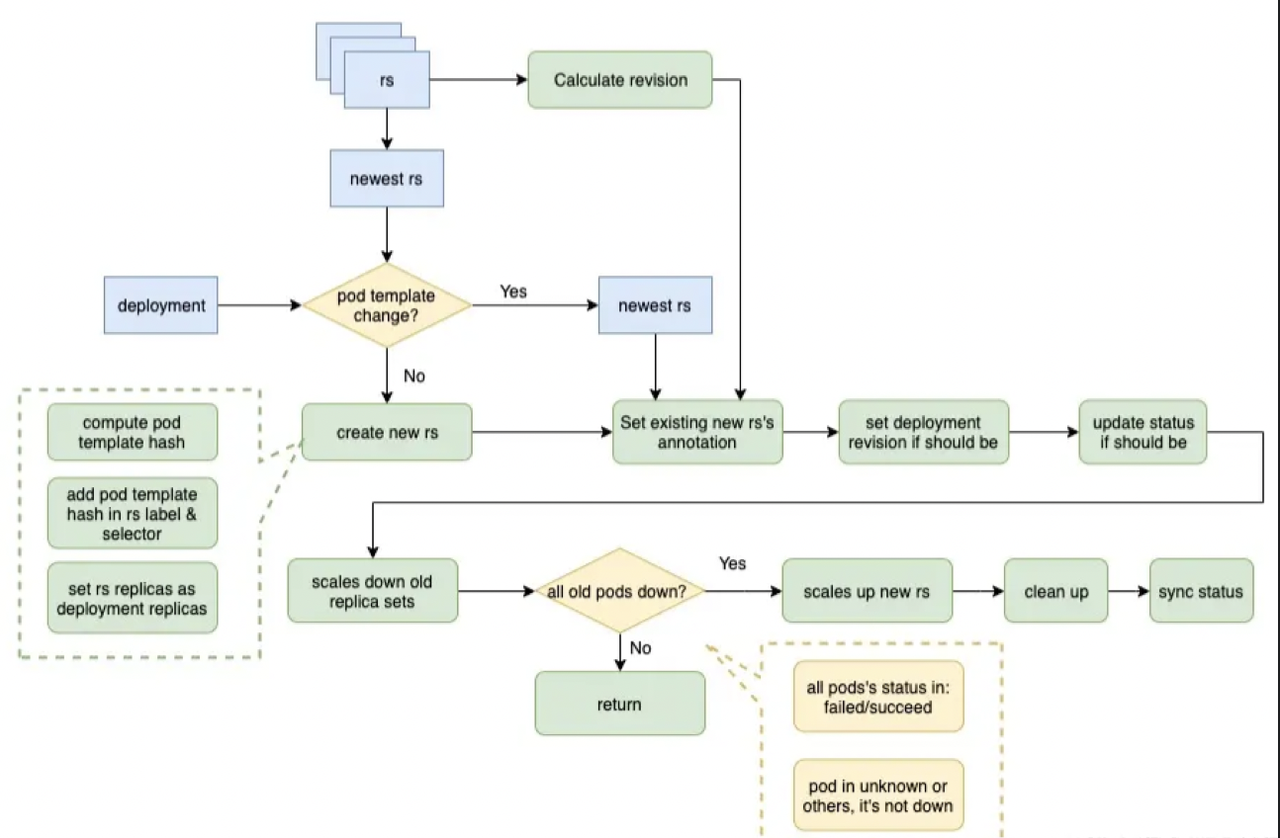
如果Deployment的更新策略是Recreate,其过程是先将旧的Pod删除,再启动新的Pod,过程如下
-
首先根据RS的领养/弃养过程,获得当前Deployment的所有RS,排序找出最新的RS,将其Pod Template与Deployment Pod Template比较,若不一致需要创建新的RS。
-
创建新RS过程为:计算当前Deployment的Pod Template的Hash值,将其增加至RS Label及Selector中。
-
对所有旧的RS计算出最大的Revision,将其加一,作为新RS的Revision,为新的RS设置如下注释:
"deployment.kubernetes.io/revision"
"deployment.kubernetes.io/desired-replicas"
"deployment.kubernetes.io/max-replicas" -
如果当前deployment的Revision不是最新,将其设置为最新;如果需要更新状态,则更新其状态。
-
将旧的RS进行降级,即将其副本数设为0.
-
判断当前所有旧的Pod是否全部停止。判断条件为Pod状态为failed或succeed,unknown或其他状态都不知停止状态;若并非所有Pod都停止了,将退出本次操作,下一个循环继续处理。
-
若所有Pod都停止了,将新的RS进行升级,即将其副本数量设置为Deployment的副本数。
-
最后执行清理工作,如旧的RS过多时,删除多余的RS等。
rolloutRolling
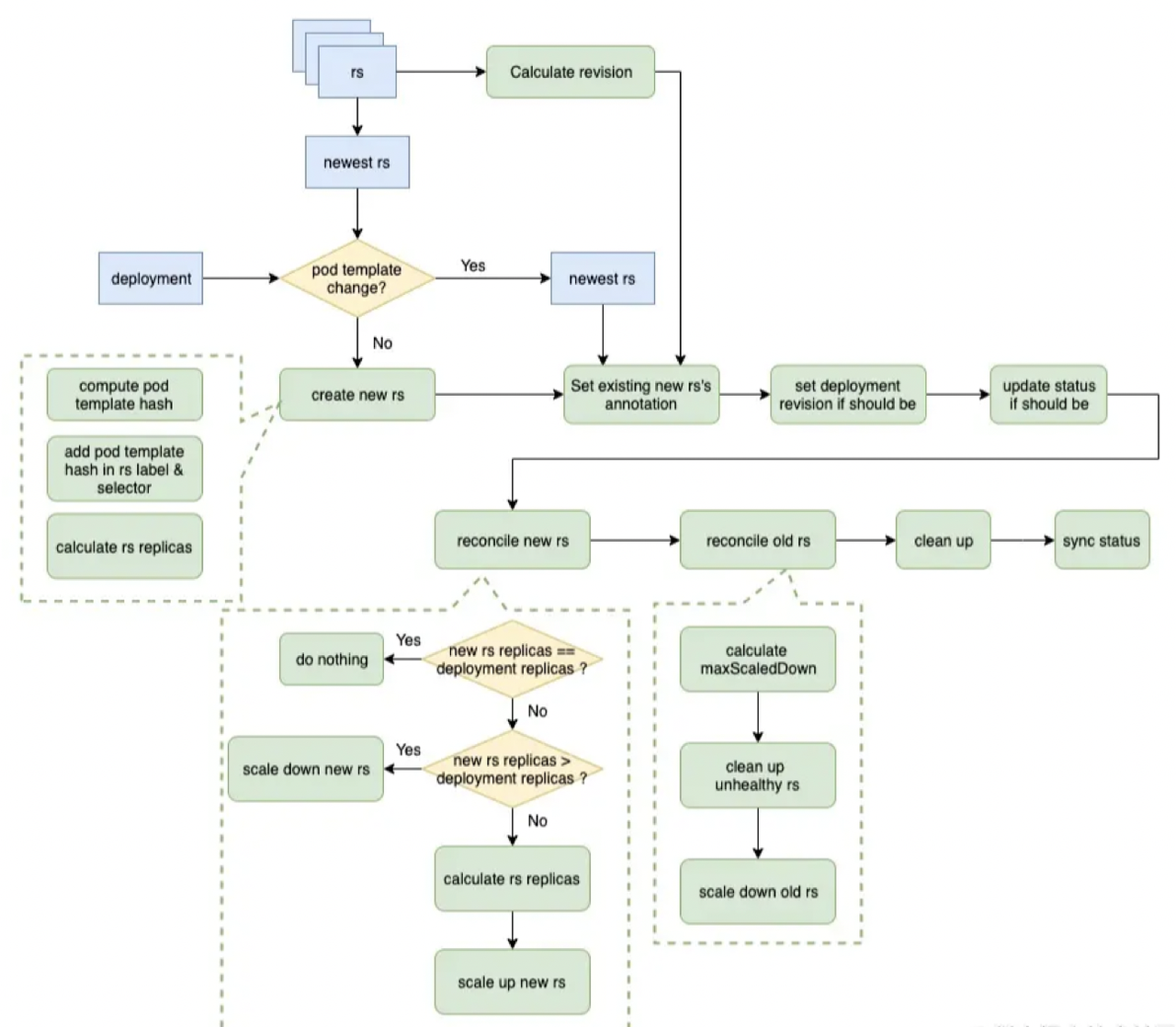
从图中可以看到,从开始到创建RS的过程与rolloutRecreate过程一致,唯一区别在,设置新的RS副本数的过程,在rolloutRolling的过程中,新RS副本数为deployment.replicas + maxSurge - currentPodCount。
- 到增减新旧RS副本数的过程,主要为先scale up新RS,在scale down旧RS。Scale up新RS过程与上诉一致;Scale down旧RS的过程为先计算一个最大Scale down的副本数,若小于0不做任何操作;然后在Scale down的时候做了一个优化,先Scale down不正常的RS,可以保证先删除那些不健康的副本;最后如果还有多余的,在Scale down正常的RS;
- 每次Scale down的副本数为:allAvailablePodCount - minAvailable,即 allAvailablePodCount - (deploy.replicas - maxUnavailable)。

