Eureka从Apollo迁移到单独Eureka
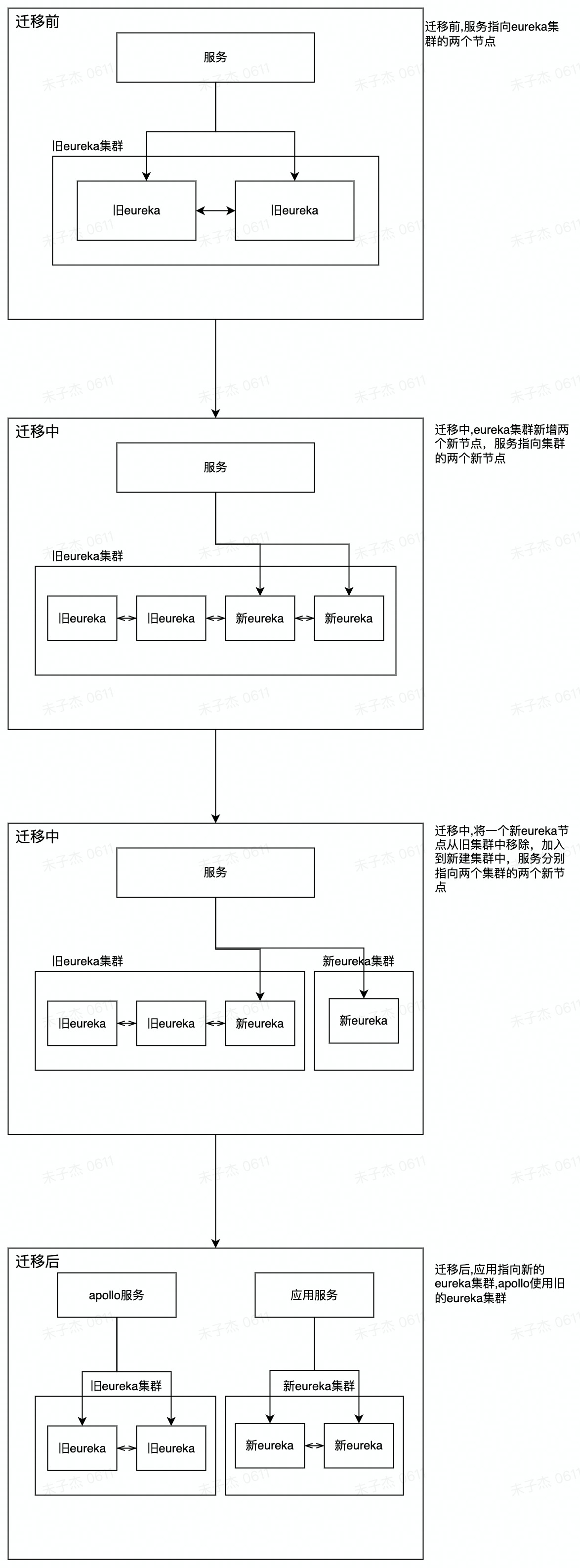
迁移物理架构演变
Eureka升级准备
- 验证新Eureka 和旧Eureka 主机网络是否连通
- 备份Apollo 数据库 apolloconfigdb中serverconfig表eureka.service.url字段的Value 值
升级过程
扩容旧eureka集群
-
Docker 启动新的Eureka,EUREKA_SERVER指定新旧所有Eureka 路径,提前替换好IP和EUREKA_SERVER=http://192.168.1.1:8761/eureka/,http://192.168.1.2:8761/eureka/,http://192.168.2.1:8520/eureka,http://192.168.2.2:8520/eureka
此处不在指定旧Eureka的SPRING_APPLICATION_NAME192.168.1.1:8761docker run -d -p 8761:8761 --name eureka \ -e "IP=192.168.2.1" \ -e "HOST_NAME=host1" \ -e "APP_PORT=8761" \ -e "APP_VERSION=" \ -e "JAVA_OPTS=JAVA_OPTS=-Xms4096m -Xmx4096m -XX:CICompilerCount=8 -XX:ActiveProcessorCount=2 -XX:+UseG1GC -XX:+UseFastAccessorMethods -XX:+UseStringDeduplication -XX:+UseCompressedOops -XX:+OptimizeStringConcat" -e "EUREKA_SERVER=http://192.168.2.1:8761/eureka/,http://192.168.2.2:8761/eureka/,http://192.168.1.1:8520/eureka/,http://192.168.1.2:8520/eureka/" \ -e "EUREKA_INSTANCE_HOSTNAME=192.168.2.1" \ -e "EUREKA_SERVER_ENABLESELFPRESERVATION=false" \ -e "EUREKA_SERVER_USE-READ-ONLY-RESPONSE-CACHE=false" \ -e "EUREKA_SERVER_RESPONSE-CACHE-UPDATE-INTERVAL-MS=5000" \ -e "EUREKA_SERVER_EVICTIONINTERVALTIMERINMS=5000" \ -e "EUREKA_INSTANCE_LEASERENEWALINTERVALINSECONDS=5" \ -e "EUREKA_INSTANCE_LEASEEXPIRATIONDURATIONINSECONDS=10" \ -e "EUREKA_SERVER_PEER-NODE-READ-TIMEOUT-MS=2000" \ -e "EUREKA_INSTANCE_IP-ADDRESS=192.168.2.1" \ --label "appname=eureka" freemanliu/eureka:v1.0.0;Jvm 内存配置:
-
-Xmx在这里会替代掉-XX的三个参数,确认选择-Xmx还是
-XX:+UnlockExperimentalVMOptions
-XX:+UseCGroupMemoryLimitForHeap
-XX:MaxRAMFraction=2-Xms4096m
-Xmx4096m -XX:+UnlockExperimentalVMOptions
-XX:+UseCGroupMemoryLimitForHeap
-XX:MaxRAMFraction=2 -
如果仍旧采用上面的配置:
-XX:+UnlockExperimentalVMOptions
-XX:+UseCGroupMemoryLimitForHeap
-XX:MaxRAMFraction=2 这里的XX:MaxRAMFraction=2有些浪费。需要调整为:
-XX:+UnlockExperimentalVMOptions
-XX:+UseCGroupMemoryLimitForHeap
-XX:MaxRAMPercentage=80.0 //这里采用百分比使用浮点数,不可用整数。 -
直接采用:采用-Xms4096m -Xmx4096m
-XX:CICompilerCount: 设置的相对较大可以一定程度提升JIT编译的速度,默认为2(编译用的)
-XX:ActiveProcessorCount: 设置容器处理器数量
-XX:+UseG1GC: G1GC(它会从内存中删除垃圾对象)
-XX:+UseStringDeduplication :字符串重复数据消除通过利用许多字符串对象相同的事实来减少Java堆上String对象的内存占用,代替每个String对象指向其自己的字符数组, 相同的String对象可以指向并共享同一字符数组。
-XX:+UseCompressedOops: 普通对象指针压缩。
-XX:+OptimizeStringConcat: 把相邻的(中间没隔着控制语句) StringBuilder合成一个,也会努力的猜长度。
-XX:+AggressiveOpts: 启用这个参数,则每当 JDK 版本升级时,你的 JVM 都会使用最新加入的优化技术(如果有的话)。
-XX:+UseFastAccessorMethods get,set 方法转成本地代码(对于jvm来说是冗余代码,jvm将进行优化)GC配置:
![]()
-
-
将旧的Apollo数据库 apolloconfigdb中serverconfig表eureka.service.url字段的Value中添加新的Eureka 地址
-
几分钟后,验证新/旧Eureka中服务注册数量是否一致,数据是否完全同步此时eureka 集群状态为unavailable-replicas
-
修改服务apollo配置,验证apollo 配置是否保存到config service

业务服务切换到新 eureka
- 修改ansible playbook发布脚本,修改eureka的URL
- 修改单个 服务Apollo 中eureka 配置,将eureka url修改为新的Eureka地址(修改单服务namespace 配置)通过发布一个服务单节点或重启该服务,该服务的单节点将注册在新的eureka上,数据同步到集群的其他unavailable-replicas节点, 验证新的Eureka是否可用
- 修改Apollo 中eureka 配置,将eureka url新的Eureka地址(公共配置和namespace 配置)所有服务依次重启,让服务注册到新的Eureka节点(同时注册到两个新的eureka节点),通过重启的方式注册到新的eureka节点,确保每个服务全部启动,注册到新的eureka节点
- 此过程中,重启过的服务会注册到新的eureka节点,未重启的服务在旧的eureka节点上,集群中的新旧节点状态是unavailable-replicas
- 确保所有服务已全部启动,没有出现启动eureka注册失败的情况,此时所有服务将全部指向新的eureka节点
将新 eureka 组成独立的集群
- 重新部署单节点新eureka,将新eureka 的EUREKA_SERVER变量中移除旧的eureka地址,此时将创建一个新的eureka集群
- 此时验证确保所有服务将会重新注册到新的eureka集群的新节点,此时将会共存两个eureka集群,新eureka集群为单节点,旧eureka集群为三节点
- 再次重新部署另外一台新的eureka,将新eureka 的EUREKA_SERVER变量 中移除旧的eureka地址
- 此时,所有服务将会再次注册到新加入的节点上,新eureka集群状态为available-replicas
- 将apollo 数据库eureka.service.url 中 新的Eureka地址移除,单节点依次重启apollo config
- 此时,旧eureka上没有业务服务注册,新的eureka上没有apollo服务注册
- 更改nginx配置,使eureka域名指向新的地址
- 验证服务是否正常
回滚eureka
- 将Apollo 数据库 apolloconfigdb中serverconfig表eureka.service.url字段的Value中设置为旧Eureka地址
- 修改apollo 中eureka 配置指向旧Eureka
- 修改Ansible playbook发布脚本中eurake 地址
- 重新发布所有服务
- 修改Nginx 配置,指向旧eureka 服务
- 停止新的Eureka
可能出现的问题数据不同步
验证集群节点配置eureka.service.url是否一致
将服务的第二批次节点从旧eureka集群下线时,此时服务的eureka将会从旧的eureka集群切换为新的eureka集群,服务是否可以很快切换到新的 eureka集群,是否会对服务发现造成影响服务

 浙公网安备 33010602011771号
浙公网安备 33010602011771号