Python面试题之集合推导式、字典推导式
集合推导式
集合推导式(set comprehensions)跟列表推导式也是类似的, 唯一的区别在于它们使用大括号{}表示。
Code: sets = {x for x in range(10)} Result: {0, 1, 2, 3, 4, 5, 6, 7, 8, 9}

集合解析把列表解析中的中括号变成大括号,返回集合。
下面我们来个应用场景,一直一个列表中有很多元素,我们做到快速去重。
Code: heavy = {x for x in [2, 3, 5, 3, 5, 2, 6]} print(heavy) Result: {2, 3, 5, 6}
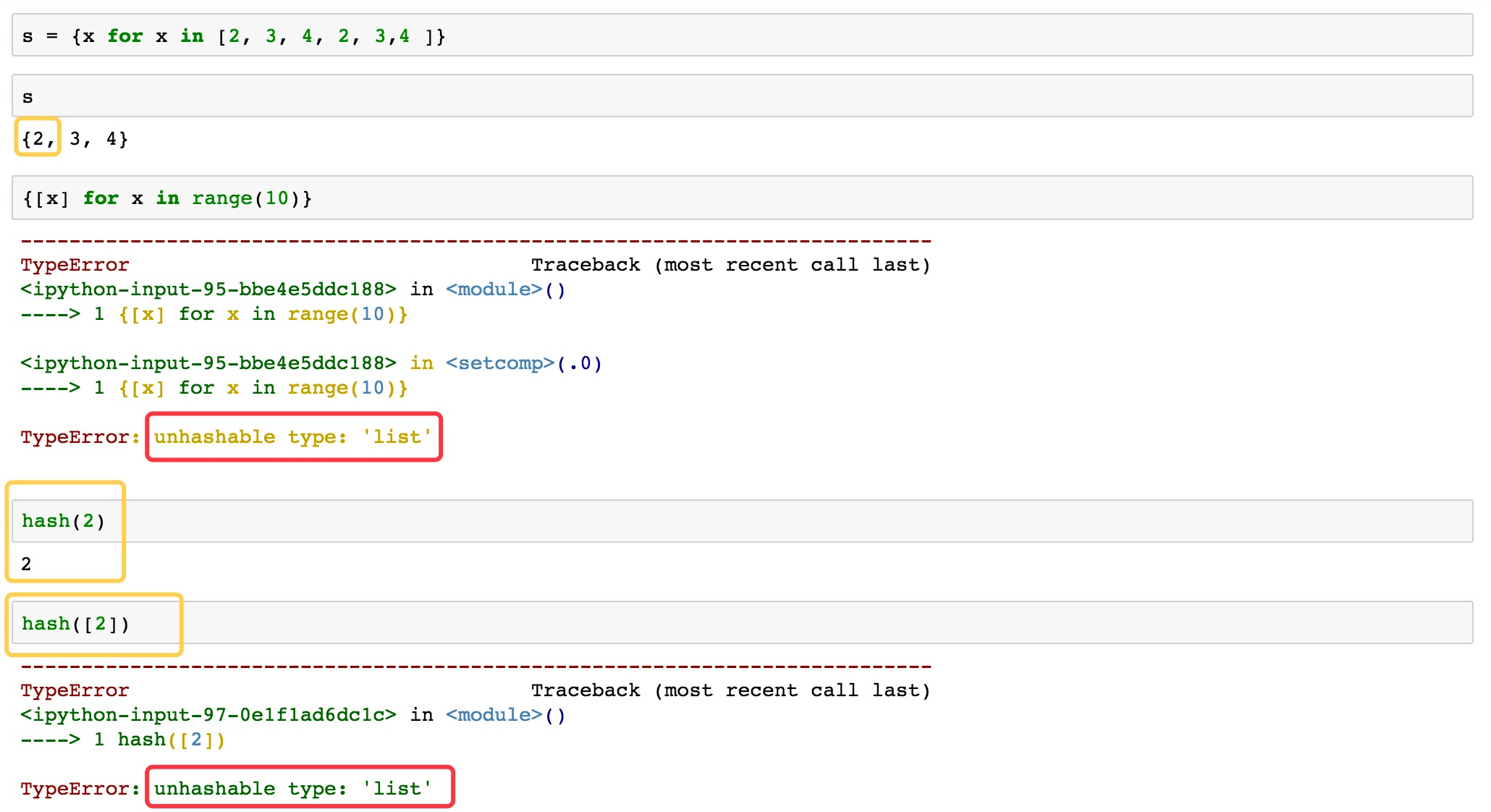
集合推导式生成内容,结果要是可hash的:
字典推导式
字典推导式(dict comprehensions)和列表推导的使用方法也是类似的。
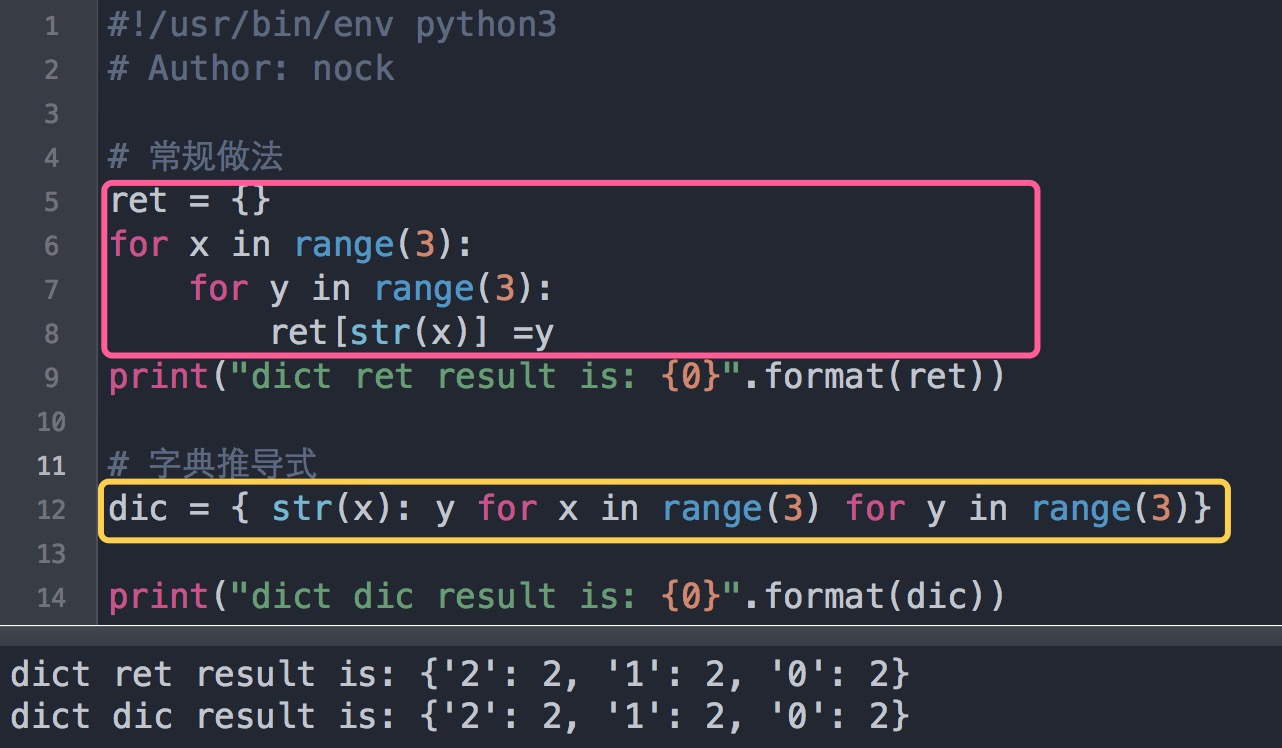
字典解析也是使用大括号包围,并且需要两个表达式,一个生成key, 一个生成value 两个表达式之间使用冒号分割,返回结果是字典.
说了这么多推导式,为什么没有元组推导式呢,元组和列表的操作几乎是一样的,除了不可变特性以外
Code: tuple([x for x in range(10)]) Result: (0, 1, 2, 3, 4, 5, 6, 7, 8, 9)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号