Python入门之迭代器/生成器/yield的表达方式/面向过程编程
本章内容
迭代器
面向过程编程
一、什么是迭代
二、什么是迭代器
三、迭代器演示和举例
四、生成器yield基础
五、生成器yield的表达式形式
六、面向过程编程
============================================================
一、什么是迭代
迭代是重复反馈过程的活动,其目的通常是为了逼近所需目标或结果。每一次对过程的重复称为一次“迭代”,而每一次迭代得到的结果会作为下一次迭代的初始值。
# 我们以前学习的while按照如下执行,会一直执行下去; # 但是,while只是一个开关作用,while在这里并没有体现出迭代的精髓"每一次迭代得到的结果会作为下一次迭代的初始值" while True: print('Hello World!')
# 下面我们遍历列表,其中每一次的n都是基于上一次的n,依次遍历 # 这里就体现了迭代的精髓“每一次的迭代的结果编程下一次迭代的初始值” l = ['a', 'b', 'c'] n = 0 while n < len(l): print(l(n)) n += 1
二、什么是迭代器
要想了解迭代器到底是什么,必须了解一个概念,即什么是可迭代对象。
在Python中,可迭代对象都内置有_iter_方法,拥有_iter_方法的对象,就是可迭代对象。
# 以下都是可迭代对象(字符串,列表,元组,字典,集合,文件)
str = 'hello' list1 = [1, 2, 3] tup1 = (4,5,6) dic = {'x': 1} s1 = {'a', 'b', 'c'} f = open('a.txt', 'w', encoding='utf-8') # 需要注意文件由于本身过大的特性,必须被定义为可迭代对象,不然很容易内存溢出
三、迭代器对象
1. 什么是迭代器对象
迭代器,就是迭代取值的工具。可迭代的对象,执行._iter_()方法得到的返回值就是迭代器对象。我们以前学过的字符串,列表,元组,字典,集合都是可迭代对象,执行内置的._iter_()方法得到对应的迭代器对象,根据部分对象的特征,我们可以根据索引取出特定的值,但是我们取值受限于索引,依赖什么就受限于什么。
在Python中,我们要进行迭代处理的对象很多,但是它们并没有上面对象的特点。先天的不足,只能通过别的方法实现,这里我们可以通过迭代器对象,使用迭代器对象的._next_()方法,逐一取出,避免这种限制。
迭代器,就是我们自己把对应的对象处理,处理成带有迭代性质的对象。
# 集合 s1 = {'a', 'b', 'c'} # 可迭代对象s1集合,执行内置的._iter_()方法,获得迭代器对象,然后就可以逐一取出来 iter_s1 = s1._iter_() print(iter_s1._next_()) print(iter_s1._next_()) print(iter_s1._next_())
# 字典 dic1 = {'x':1, 'y':2, 'z':3} # 可迭代对象dic1字典,执行内置的._iter_()方法,获得迭代器对象,然后就可以逐一取出来 iter_dic1 = dic1._iter_() print(iter_dic1._next_()) print(iter_dic1._next_()) print(iter_dic1._next_())
# 列表 L1 = [2,3,4,] # 可迭代对象L1列表,执行内置的._iter_()方法,获得迭代器对象,然后可以逐一取出来 iter_L1 = L1._iter_() print(iter_L1._next_()) print(iter_L1._next_()) print(iter_L1._next_())
# 字符串 str1 = 'hello' # 可迭代对象str1字符串,执行内置的._iter_()方法,获得迭代器对象,然后逐一取出 iter_str1 = iter_str1._iter_() print(iter_str1._next_()) print(iter_str1._next_()) print(iter_str1._next_()) print(iter_str1._next_()) print(iter_str1._next_())
# 我们在遍历字符串的时候,发现会报错,那就引入抛出异常机制

# 文件 f1 = open('a.txt', 'r', encoding = 'utf-8') # 可迭代对象f1文件,执行内置的._iter_()方法,获取迭代器对象,然后逐一取出 iter_f1 = f1._iter_() while True: try: print(iter_f1._next_()) except StopIteration: break
# 迭代文件的时候,你会发现打印出来,有空行,因为在文件中换行是由‘\n’代表的

2. 迭代器之for循环的应用
for循环,是一种迭代器循环,因为for要调用可迭代对象内置的._iter_()方法,而且关键字in之后必须跟可迭代对象或者迭代器。
#基于for循环,我们可以完全不再依赖索引去取值了 dic={'a':1,'b':2,'c':3} for k in dic: print(dic[k]) # for循环的工作原理 #1:执行in后对象的dic.__iter__()方法,得到一个迭代器对象iter_dic #2: 执行next(iter_dic),将得到的值赋值给k,然后执行循环体代码 #3: 重复过程2,直到捕捉到异常StopIteration,结束循环
3. 迭代器的优点
1. 提供了一种可以不依赖索引的取值方式
2. 在内存中只生成一个迭代器对象,每次产生一个值,不用把对象完整的加载到内存,更加节省内存
# 下图中,iter_l的内存信息,你会看到内存中标记的是ist_iterator对象
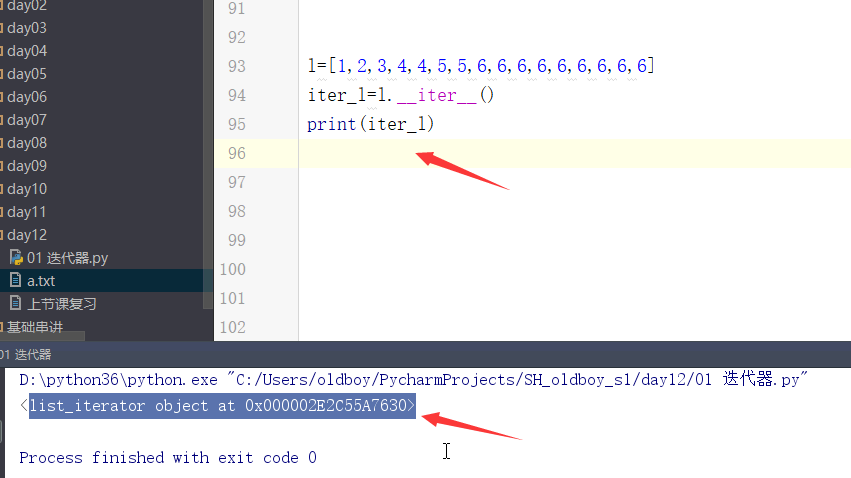
4. 迭代器的缺点
1. 只能用_next_()方法,一个一个取出来,取值效率低
2. 取值方向只能往后取,而且是一次性使用,无法往复取值
5. 可迭代对象 VS 迭代器对象

# 补充说明, 文件有时候本身较大,一次全部加载到内存,费事费力,所以要被定义为一个迭代器对象,每次取一点,节省内存,提升效率
四、生成器yield基础
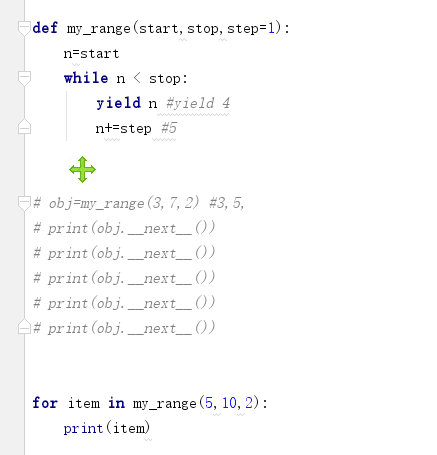
1. 生成器本身就是迭代器,相当于我们借助函数,自己制造了一个迭代器。
生成器的用法其实就是迭代器的用法。
yield的用法(面向任何可迭代对象):
函数内包含yield关键字,再调用函数,就不会执行函数体代码,拿到的返回值就是一个生成器对象。
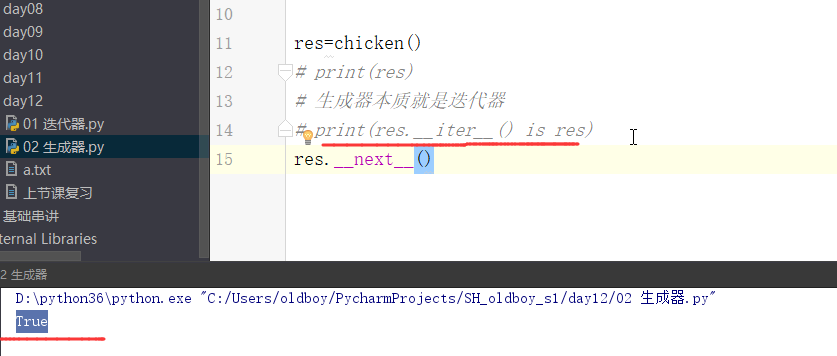
# 注意下图中,内存的标记为生成器generator

# 生成器的本质就是迭代器,下面res._iter_() 就是 res本身
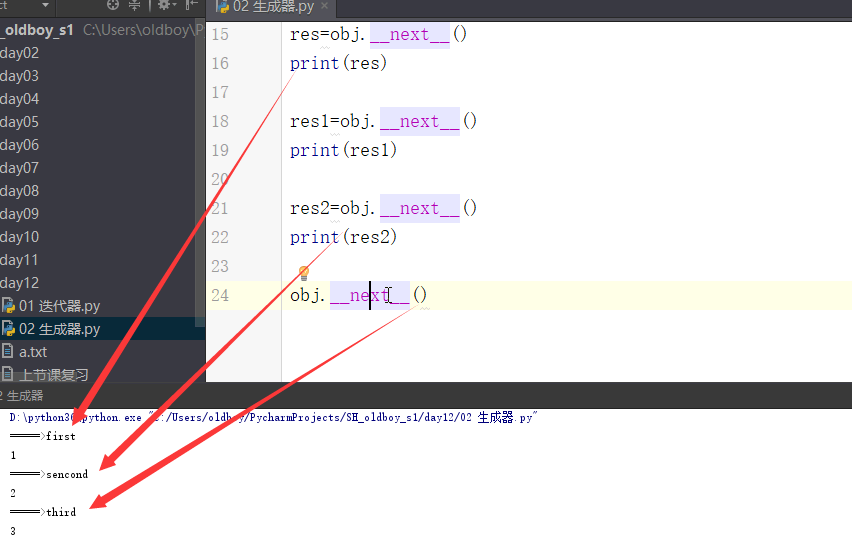
2. yeild的过程

3. yield的功能
1. yield与return类似,都可以返回值,不同之处在于,yield可以返回多个值而且可以暂停,在暂停的基础上再次执行;return就不一样了,代表函数的结束。
2. yield可以让已经封装好的函数能够使用_iter_和_next_方法
3. yield遵循迭代器的取值方式,函数的触发执行和函数的保存都是通过yeild保存。
def start(): print('Starting.......') while True: x = yield #此处是yield的表达式形式 print(x) f = start() next(f) #next(g) == g.send(None) ''' send的效果: 1. 将携带的值传给yield,不是x,然后yield在复制给x 2. send()方法具有和next()方法一样的功能,能在传值的基础上继续执行,直到再次碰到 yield结束 ''' g.send(2)
yield表达式形式,例如 x = yield, 生成器会有一个send操作
send的效果:
1. 先从为暂停位置的那个yiled传一个值,然后yield会把值,赋值给x
2. 与next的功能一样
3. send 传多个值时, 必须以元组的形式,保持有序,不能修改
def start(): print('Starting.......') while True: x = yield #此处是yield的表达式形式 print(x) start() start() # 到这里就不会运行print('Starting.......'),因为再次调用函数,解释器在检测语法 的时候,检测到有yield,那么在执行该函数的时候就不会运行
# 结合上面,下面实例是可变长度参数的应用实例
def foo(func): def foo1(*args, **kwargs): g = func(*args, **kwargs) next(g) return g return foo1 @foo def eater(name): print('%s starts to ear' % name) foo_list = [] while True: food = yield food_list food_list.append(food) print('%s starts to eat %s' % (name, food)) print(food_list) m = eater('Alex') m.send('Bread')

# 结合上面理论,理解以下yield表达式的范例


4. yield总结
1. 为我们提供了一种自定义迭代器的方式,可以在函数内用yield关键字;调用函数拿到的结果就是生成器,可以利用生成器的迭代器方法
2. yield可以像return一样用于返回值;return一次只能返回一次,而且代表函数结束,yield可以返回多次值
3. yield可以保存函数的执行状态

六、 面向过程编程
1. 什么是面向过程编程
这个概念的核心对象是‘过程’,解决问题的过程,即先做什么,后做什么
2. 基于面向过程编写程序,就像设计一条流水线,类似机械的思维方式
3. 优点和缺点
优点:复杂问题流程化,进而简单化
缺点:可扩展性差,修改流水线的任意一个部分,都会牵一发而动全身
应用:固定场景,扩展性要求不高,典型案例如linux内核,git,httpd等等
4. 实例:
流水线1:
用户输入用户名、密码 ===》 用户验证 ===》 欢迎界面
流水线2:
用户发起sql请求 ===》sql解析 ===》执行功能

 浙公网安备 33010602011771号
浙公网安备 33010602011771号