机器学习笔记之决策树分类Decision Tree
0x01 什么是决策树
决策树(decision tree)是一种依托于策略抉择而建立起来的树。机器学习中,决策树是一个预测模型;他代表的是对象属性与对象值之间的一种映射关系。 树中每个节点表示某个对象,而每个分叉路径则代表的某个可能的属性值,从根节点到叶节点所经历的路径对应一个判定测试序列。决策树可以是二叉树或非二叉树,也可以把他看作是 if-else 规则的集合,也可以认为是在特征空间上的条件概率分布。决策树在机器学习模型领域的特殊之处,在于其信息表示的清晰度。决策树通过训练获得的 “知识”,直接形成层次结构。这种结构以这样的方式保存和展示知识,即使是非专家也可以很容易地理解。
决策树的优点:
- 决策树算法中学习简单的决策规则建立决策树模型的过程非常容易理解,
- 决策树模型可以可视化,非常直观
- 应用范围广,可用于分类和回归,而且非常容易做多类别的分类
- 能够处理数值型和连续的样本特征
决策树的缺点:
- 很容易在训练数据中生成复杂的树结构,造成过拟合(overfitting)。剪枝可以缓解过拟合的负作用,常用方法是限制树的高度、叶子节点中的最少样本数量。
- 学习一棵最优的决策树被认为是NP-Complete问题。实际中的决策树是基于启发式的贪心算法建立的,这种算法不能保证建立全局最优的决策树(Random Forest 引入随机能缓解这个问题)。
一棵“树”,目的和作用是“决策”。一般来说,每个节点上都保存了一个切分,输入数据通过切分继续访问子节点,直到叶子节点,就找到了目标,或者说“做出了决策”。举个例子: 现在有人给你介绍对象,你打听到对方的特点:白不白,富不富,美不美,然后决定去不去相亲。根据以往经验,我们给出所有可能性:
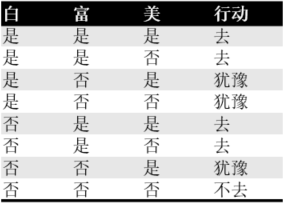
有人给介绍新的对象的时候,我们就要一个个特点去判断,于是这种判断的过程就可以画成一棵树,例如根据特点依次判断:
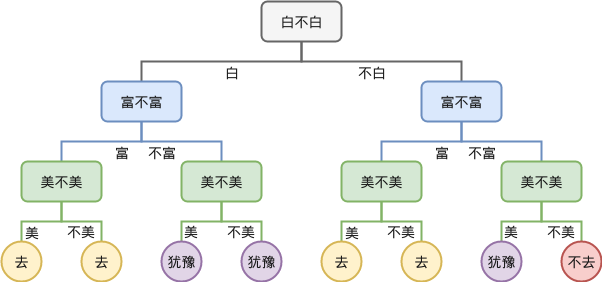
这就是决策树,每一层我们都提出一个问题,根据问题的回答来走向不同的子树,最终到达叶子节点时,做出决策(去还是不去)。可以看到,决策树没有任何特别的地方。
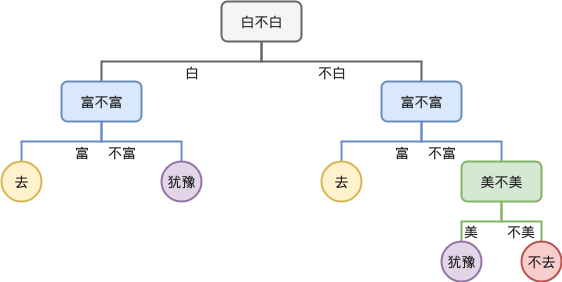
当然,如果我们先考虑富不富,再考虑白不白,则得到的树又不相同:

所以,决策树其实就是根据已知的经验来构建一棵树。可以认为是根据数据的某个维度进行切分,不断重复这个过程。当然,如果切分的顺序不同,会得到不同的树。
如果仔细观察,我们发现决策树中有一些叶子节点是可以合并的,合并之后,到达某个节点时就不需要进行额外的决策,例如切分顺序“白,富,美”得到的决策树合并后如下:
而“富,白,美”的决策树合并后变成
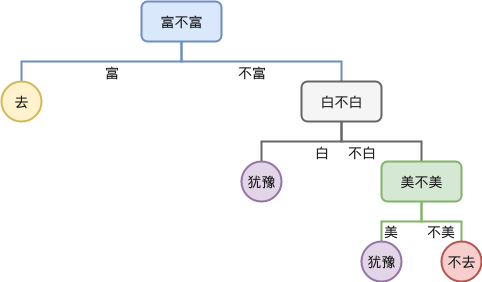
可以看到上面这棵树则只有 4 个叶子节点,少于“白,富,美”的 5 个节点。这就是决策树间最大的区别,不同决策树合并后得到树叶子节点的个数是不同的,后面我们会看到,叶子节点越少,往往决策树的泛化能力越高,所以可以认为训练决策树的一个目标是减少决策树的叶子节点 。
0x02 决策树分类算法
2.1 基于ID3算法的决策分析
ID3是由J.Ross Quinlan在1986年开发的一种基于决策树的分类算法。该算法是以信息论为基础,以信息熵核信息增益为衡量标准,从而实现对数据的归纳分类。根据信息增益运用自顶向下的贪心策略是ID3建立决策树的主要方法。运用ID3算法的主要优点是建立的决策树的规模比较小,查询速度比较快。这个算法建立在“奥卡姆剃刀”的基础上,即越是小型的决策树越优于大的决策树。但是,该算法在某些情况下生成的并不是最小的树型结构。
信息量
信息量在是作为信息“多少”的度量,这里的信息就是你理解的信息,比如一条新闻,考试答案等等。假设我们听到了两件事,分别如下:
- 事件A:巴西队进入了2018世界杯决赛圈。
- 事件B:中国队进入了2018世界杯决赛圈。
仅凭直觉来说,事件B的信息量比事件A的信息量要大。究其原因,是因为事件A发生的概率很大,事件B发生的概率很小。所以当越不可能的事件发生了,我们获取到的信息量就越大。越可能发生的事件发生了,我们获取到的信息量就越小。那么:
- 信息量和事件发生的概率相关,事件发生的概率越低,传递的信息量越大
- 信息量应当是非负的,必然发生的事件的信息量为零(必然事件是必然发生的,所以没有信息量。几乎不可能事件一旦发生,具有近乎无穷大的信息量。)
- 两个事件的信息量可以相加,并且两个独立事件的联合信息量应该是他们各自信息量的和
如已知事件Xi已发生,则表示Xi所含有或所提供的信息量:
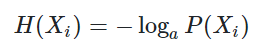
如果是以2为底数,单位是bit;如果以e为底数,单位是nat;如果以10为底数,单位是det;
例如,今天下雨的概率是0.5,则包含的信息量为 −log20.5=1比特;同理,下雨天飞机正常起飞的概率为0.25,则信息量为−log20.25=2比特。
信息熵
信息熵(Entropy)是接受信息量的平均值,用于确定信息的不确定程度,是随机变量的均值。信息熵越大,信息就越凌乱或传输的信息越多,熵本身的概念源于物理学中描述一个热力学系统的无序程度。信息熵的处理信息是一个让信息的熵减少的过程。
假设X是一个离散的随机变量,且它的取值范围为x1,x2,…,xn,每一种取到的概率分别是 p1,p2,…,pn,那么 X 的熵定义为:
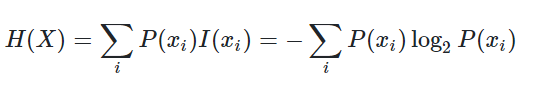
条件熵
在决策树的切分里,事件 xi 可以认为是在样本中出现某个标签/决策。于是 P(xi)可以用所有样本中某个标签出现的频率来代替。但我们求熵是为了决定采用哪一个维度进行切分,因此有一个新的概念条件熵:

这里我们认为 Y 就是用某个维度进行切分,那么 y 就是切成的某个子集合于是 H(X|Y=y) 就是这个子集的熵。因此可以认为就条件熵是每个子集合的熵的一个加权平均/期望。
信息增益
信息熵表示的是不确定度。均匀分布时,不确定度最大,此时熵就最大。当选择某个特征对数据集进行分类时,分类后的数据集信息熵会比分类前的小,其差值表示为信息增益。信息增益(Kullback-Leibler divergence)用于度量属性A对降低样本集合X熵的贡献大小。信息增益可以衡量某个特征对分类结果的影响大小。信息增益越大,越适用对X进行分析。
有了信息熵的定义后,信息增益的概念便很好理解了,表示分类后,数据整体信息熵的差值。我们假设特征集中有一个离散特征a,它有V个可能的取值a1,a2,…,aV,如果使用特征a来对样本D进行划分,那么会产V个分支节点,其中第v个分支节点中包含的样本集。我们记为Dv。于是,可计算出特征a对样本集D进行划分所获得的信息增益为:
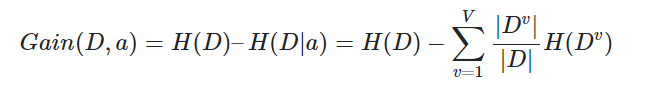
解释下上面公式,其实特征a对样本集D进行划分所获得的信息增益 即为 样本集D的信息熵减去经过划分后各个分支的信息熵之和。由于每个分支节点,所包含的样本数不同,所有在计算每个分支的信息熵时,需要乘上对应权重 ,即样本数越多的分支节点对应的影响越大。
,即样本数越多的分支节点对应的影响越大。
ID3算法流程
输入:数据集D,特征集A
输出:ID3决策树
- 对当前样本集合计算出所有属性信息的信息增益
- 先选择信息增益最大的属性作为测试属性,将测试属性相同的样本转化为同一个子样本
- 若子样本集的类别属性只含有单个属性,则分支为叶子节点,判断其属性值并标上相应的符号,然后返回调用处,否则对子样本递归调用本算法。
ID3算法的应用
我们以实际案例来更加深入的学习整个算法流程。

计算过程如下:

ID3算法的Python实现
from math import log import operator # 计算香农熵 def calculate_entropy(data): label_counts = {} for feature_data in data: laber = feature_data[-1] # 最后一行是laber if laber not in label_counts.keys(): label_counts[laber] = 0 label_counts[laber] += 1 count = len(data) entropy = 0.0 for key in label_counts: prob = float(label_counts[key]) / count entropy -= prob * log(prob, 2) return entropy # 计算某个feature的信息增益 # index:要计算信息增益的feature 对应的在data 的第几列 # data 的香农熵 def calculate_relative_entropy(data, index, entropy): feat_list = [number[index] for number in data] # 得到某个特征下所有值(某列) uniqual_vals = set(feat_list) new_entropy = 0 for value in uniqual_vals: sub_data = split_data(data, index, value) prob = len(sub_data) / float(len(data)) new_entropy += prob * calculate_entropy(sub_data) # 对各子集香农熵求和 relative_entropy = entropy - new_entropy # 计算信息增益 return relative_entropy # 选择最大信息增益的feature def choose_max_relative_entropy(data): num_feature = len(data[0]) - 1 base_entropy = calculate_entropy(data)#香农熵 best_infor_gain = 0 best_feature = -1 for i in range(num_feature): info_gain=calculate_relative_entropy(data, i, base_entropy) #最大信息增益 if (info_gain > best_infor_gain): best_infor_gain = info_gain best_feature = i return best_feature def create_decision_tree(data, labels): class_list=[example[-1] for example in data] # 类别相同,停止划分 if class_list.count(class_list[-1]) == len(class_list): return class_list[-1] # 判断是否遍历完所有的特征时返回个数最多的类别 if len(data[0]) == 1: return most_class(class_list) # 按照信息增益最高选取分类特征属性 best_feat = choose_max_relative_entropy(data) best_feat_lable = labels[best_feat] # 该特征的label decision_tree = {best_feat_lable: {}} # 构建树的字典 del(labels[best_feat]) # 从labels的list中删除该label feat_values = [example[best_feat] for example in data] unique_values = set(feat_values) for value in unique_values: sub_lables=labels[:] # 构建数据的子集合,并进行递归 decision_tree[best_feat_lable][value] = create_decision_tree(split_data(data, best_feat, value), sub_lables) return decision_tree # 当遍历完所有的特征时返回个数最多的类别 def most_class(classList): class_count={} for vote in classList: if vote not in class_count.keys():class_count[vote]=0 class_count[vote]+=1 sorted_class_count=sorted(class_count.items,key=operator.itemgetter(1),reversed=True) return sorted_class_count[0][0] # 工具函数输入三个变量(待划分的数据集,特征,分类值)返回不含划分特征的子集 def split_data(data, axis, value): ret_data=[] for feat_vec in data: if feat_vec[axis]==value : reduce_feat_vec=feat_vec[:axis] reduce_feat_vec.extend(feat_vec[axis+1:]) ret_data.append(reduce_feat_vec) return ret_data
参考链接:https://segmentfault.com/a/1190000015083169
ID3算法的优点与缺点
ID3算法的优点:
- 算法结构简单;
- 算法清晰易懂;
- 非常灵活方便;
- 不存在无解的危险;
- 可以利用全部训练例的统计性质进行决策,从而抵抗噪音。
ID3算法简单,但是其缺点也不少:
- ID3算法采用信息增益来选择最优划分特征,然而人们发现,信息增益倾向与取值较多的特征,对于这种具有明显倾向性的属性,往往容易导致结果误差;
- ID3算法没有考虑连续值,对与连续值的特征无法进行划分;
- ID3算法无法处理有缺失值的数据;
- ID3算法没有考虑过拟合的问题,而在决策树中,过拟合是很容易发生的;
- ID3算法采用贪心算法,每次划分都是考虑局部最优化,而局部最优化并不是全局最优化,当然这一缺点也是决策树的缺点,获得最优决策树本身就是一个NP难题,所以只能采用局部最优;
2.2 基于C4.5算法的分类决策树
C4.5是J.Ross Quinlan基于ID3算法改进后得到的另有一个分类决策树算法。C4.5是算法继承了ID3算法的优点,且改进后的算法产生的分类规则易于理解,准确率高。同时,该算法也存在一些缺点,如算法效率低,值适合用于能够驻留于内存的数据集。正在ID3算法的基础上,C4.5算法进行了以下几点改进:
- 用信息增益率来选择属性,克服了ID3算法选择属性时偏向选择取值多的属性的不足
- 在决策树的构造过程中进行剪枝,不考虑某些具有很好元素的节点。
- 能够完成对联系属性的离散化处理。
- 能够对不完整数据进行处理。
以信息增益作为准则来进行划分属性有什么缺点?假设有14个样本的数据,增加一列特征data = [1,2,3,4,5,6,7,8,9,10,11,12,13,14],根据公式,可以算出对应的信息增益为:Gain(D,data) = 0.940, 我们发现,它所对应的信息增益远大于其他特征,所以我们要以data特征,作为第一个节点的划分。这样划分的话,将产生14个分支,每个分支对应只包含一个样本,每个分支节点的纯度已达到最大,也就是说每个分支节点的结果都非常确定。但是,这样的决策树,肯定不是我们想要的,因为它根本不具备任何泛化能力。如何避免这个问题呢,我们引入增益率这个概念,改为使用增益率来作为最优划分特征的标准。
信息增益率

C4.5算法应用实例

C4.5算法Python实现
from treeNode import TreeNode import pandas as pd import numpy as np class DecisionTreeC45: def __init__(self, X, Y): self.X_train = X self.Y_train = Y self.root_node = TreeNode(None, None, None, None, self.X_train, self.Y_train) self.features = self.get_features(self.X_train) self.tree_generate(self.root_node) def get_features(self, X_train_data): features = dict() for i in range(len(X_train_data.columns)): feature = X_train_data.columns[i] features[feature] = list(X_train_data[feature].value_counts().keys()) return features def tree_generate(self, tree_node): X_data = tree_node.X_data Y_data = tree_node.Y_data # get all features of the data set features = list(X_data.columns) # 如果Y_data中的实例属于同一类,则置为单结点,并将该类作为该结点的类 if len(list(Y_data.value_counts())) == 1: tree_node.category = Y_data.iloc[0] tree_node.children = None return # 如果特征集为空,则置为单结点,并将Y_data中最大的类作为该结点的类 elif len(features) == 0: tree_node.category = Y_data.value_counts(ascending=False).keys()[0] tree_node.children = None return # 否则,计算各特征的信息增益,选择信息增益最大的特征 else: ent_d = self.compute_entropy(Y_data) XY_data = pd.concat([X_data, Y_data], axis=1) d_nums = XY_data.shape[0] max_gain_ratio = 0 feature = None for i in range(len(features)): v = self.features.get(features[i]) Ga = ent_d IV = 0 for j in v: dv = XY_data[XY_data[features[i]] == j] dv_nums = dv.shape[0] ent_dv = self.compute_entropy(dv[dv.columns[-1]]) if dv_nums == 0 or d_nums == 0: continue Ga -= dv_nums / d_nums * ent_dv IV -= dv_nums/d_nums*np.log2(dv_nums/d_nums) if IV != 0.0 and (Ga/IV) > max_gain_ratio: max_gain_ratio = Ga/IV feature = features[i] # 如果当前特征的信息增益比小于阈值epsilon,则置为单结点,并将Y_data中最大的类作为该结点的类 if max_gain_ratio < 0: tree_node.feature = None tree_node.category = Y_data.value_counts(ascending=False).keys()[0] tree_node.children = None return if feature is None: tree_node.feature = None tree_node.category = Y_data.value_counts(ascending=False).keys()[0] tree_node.children = None return tree_node.feature = feature # 否则,对当前特征的每一个可能取值,将Y_data分成子集,并将对应子集最大的类作为标记,构建子结点 # get all kinds of values of the current partition feature branches = self.features.get(feature) # branches = list(XY_data[feature].value_counts().keys()) tree_node.children = dict() for i in range(len(branches)): X_data = XY_data[XY_data[feature] == branches[i]] if len(X_data) == 0: category = XY_data[XY_data.columns[-1]].value_counts(ascending=False).keys()[0] childNode = TreeNode(tree_node, None, None, category, None, None) tree_node.children[branches[i]] = childNode # return # error, not should return, but continue continue Y_data = X_data[X_data.columns[-1]] X_data.drop(X_data.columns[-1], axis=1, inplace=True) X_data.drop(feature, axis=1, inplace=True) childNode = TreeNode(tree_node, None, None, None, X_data, Y_data) tree_node.children[branches[i]] = childNode # print("feature: " + str(tree_node.feature) + " branch: " + str(branches[i]) + "\n") self.tree_generate(childNode) return def compute_entropy(self, Y): ent = 0; for cate in Y.value_counts(1): ent -= cate*np.log2(cate); return ent
参考链接:https://github.com/Rudo-erek/decision-tree/blob/master/decisionTreeC45.py
2.3 基于分类回归树(CART)的决策划分
在数据挖掘中,决策树主要有两种类似:分类树和决策树。分类树的输出是样本的类别,回归树的输出是一个实数。分类和回归树,即CART(Classification And Regression Tree),最先由Breiman等提出,也属于一类决策树。CART算法由决策树生成和决策树剪枝两部分组成:
- 决策树生成:基于训练数据集生成决策树,生成的决策树要尽量的大
- 决策树剪枝:用验证数据集对以生成的树进行剪枝并选择最优子树,这时用损失函数最小作为剪枝的标准。
CART算法既可以用于创建分类树,也可以用于创建回归树。CART算法的重要特点包含以下三个方面:
- 二分(Binary Split):在每次判断过程中,都是对样本数据进行二分。CART算法是一种二分递归分割技术,把当前样本划分为两个子样本,使得生成的每个非叶子结点都有两个分支,因此CART算法生成的决策树是结构简洁的二叉树。由于CART算法构成的是一个二叉树,它在每一步的决策时只能是“是”或者“否”,即使一个feature有多个取值,也是把数据分为两部分
- 单变量分割(Split Based on One Variable):每次最优划分都是针对单个变量。
- 剪枝策略:CART算法的关键点,也是整个Tree-Based算法的关键步骤。剪枝过程特别重要,所以在最优决策树生成过程中占有重要地位。有研究表明,剪枝过程的重要性要比树生成过程更为重要,对于不同的划分标准生成的最大树(Maximum Tree),在剪枝之后都能够保留最重要的属性划分,差别不大。反而是剪枝方法对于最优树的生成更为关键。
- CART树生成就是递归的构建二叉决策树的过程,对回归使用平方误差最小化准则,对于分类树使用基尼指数(Gini index)准则,进行特征选择,生成二叉树。
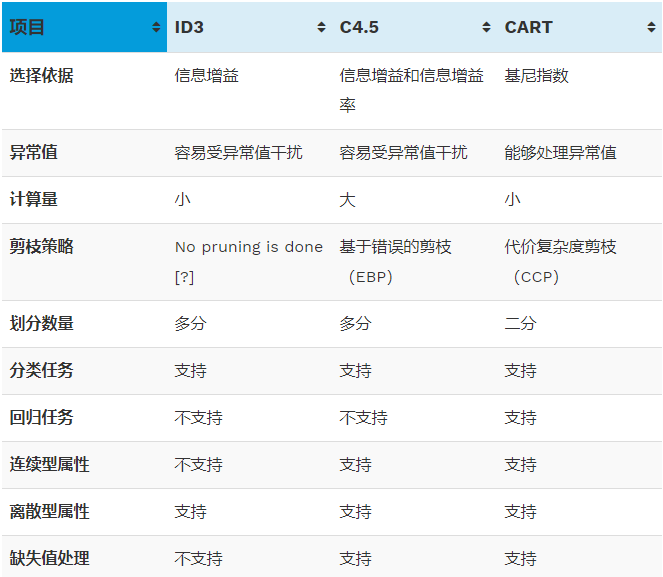
ID3、C4.5、CART之间的区别
基尼指数

其中算法的停止条件有:
- 节点中的样本个数小于预定阈值,
- 样本集的Gini系数小于预定阈值(此时样本基本属于同一类),
- 或没有更多特征。
应用实例:决策划分
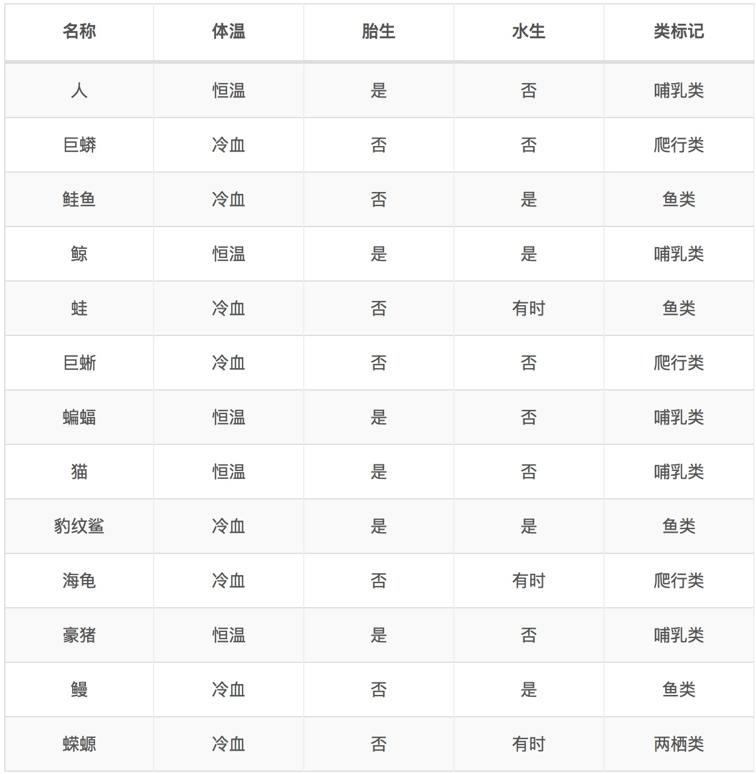
针对上述离散型数据,按照体温为恒温和非恒温进行划分。其中恒温时包括哺乳类5个、鸟类2个,非恒温时包括爬行类3个、鱼类3个、两栖类2个,如下所示我们计算D1,D2的基尼指数。
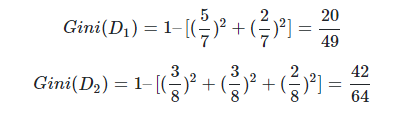
然后计算得到特征体温(A1)下数据集的Gini指数,最后我们选择Gain_Gini最小的特征和相应的划分。
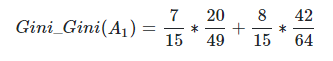
CART算法Python实现
from treeNode import TreeNode import pandas as pd import numpy as np class DecisionTreeCART: def __init__(self, X, Y): self.X_train = X self.Y_train = Y self.root_node = TreeNode(None, None, None, None, self.X_train, self.Y_train) self.features = self.get_features(self.X_train) self.tree_generate(self.root_node) def get_features(self, X_train_data): features = dict() for i in range(len(X_train_data.columns)): feature = X_train_data.columns[i] features[feature] = list(X_train_data[feature].value_counts().keys()) return features def tree_generate(self, tree_node): X_data = tree_node.X_data Y_data = tree_node.Y_data # get all features of the data set features = list(X_data.columns) # 如果Y_data中的实例属于同一类,则置为单结点,并将该类作为该结点的类 if len(list(Y_data.value_counts())) == 1: tree_node.category = Y_data.iloc[0] tree_node.children = None return # 如果特征集为空,则置为单结点,并将Y_data中最大的类作为该结点的类 elif len(features) == 0: tree_node.category = Y_data.value_counts(ascending=False).keys()[0] tree_node.children = None return # 否则,计算各特征的基尼指数,选择基尼指数最小的特征 else: # gini_d = self.compute_gini(Y_data) XY_data = pd.concat([X_data, Y_data], axis=1) d_nums = XY_data.shape[0] min_gini_index = 1 feature = None feature_value = None for i in range(len(features)): # 当前特征有哪些取值 # v = self.features.get(features[i]) v = XY_data[features[i]].value_counts().keys() # 当前特征的取值只有一种 if len(v) <= 1: continue # 当前特征的每一个取值分为是和不是两类 for j in v: Gini_index = 0 dv = XY_data[XY_data[features[i]] == j] dv_nums = dv.shape[0] dv_not = XY_data[XY_data[features[i]] != j] dv_not_nums = dv_not.shape[0] gini_dv = self.compute_gini(dv[dv.columns[-1]]) gini_dv_not = self.compute_gini(dv_not[dv_not.columns[-1]]) if d_nums == 0: continue Gini_index += dv_nums / d_nums * gini_dv + dv_not_nums / d_nums * gini_dv_not if Gini_index < min_gini_index: min_gini_index = Gini_index feature = features[i] feature_value = j if feature is None: tree_node.category = Y_data.value_counts(ascending=False).keys()[0] tree_node.children = None return tree_node.feature = feature # 否则,对当前特征的最小基尼指数取值,将Y_data分成两类子集,构建子结点 # get all kinds of values of the current partition feature # branches = list({feature_value, "!"+str(feature_value)}) # branches = list(XY_data[feature].value_counts().keys()) tree_node.children = dict() for i in range(2): # 左分支,左分支为是的分支 if i == 0: X_data = XY_data[XY_data[feature] == feature_value] X_data.drop(feature, axis=1, inplace=True) child_name = feature_value # 右分支,右分支为否的分支 else: X_data = XY_data[XY_data[feature] != feature_value] child_name = "!" + str(feature_value) # 可能出现节点没有数据的情况吗? # if len(X_data) == 0: # print("I'm a bug") # category = XY_data[XY_data.columns[-1]].value_counts(ascending=False).keys()[0] # childNode = TreeNode(tree_node, None, None, category, None, None) # tree_node.children[child_name] = childNode # # return # # error, not should return, but continue # continue Y_data = X_data[X_data.columns[-1]] X_data.drop(X_data.columns[-1], axis=1, inplace=True) # X_data.drop(feature, axis=1, inplace=True) childNode = TreeNode(tree_node, None, None, None, X_data, Y_data) tree_node.children[child_name] = childNode # print("feature: " + str(tree_node.feature) + " branch: " + str(branches[i]) + "\n") self.tree_generate(childNode) return def compute_gini(self, Y): gini = 1 for cate in Y.value_counts(1): gini -= cate*cate return gini
参考链接:https://github.com/Rudo-erek/decision-tree/blob/master/decisionTreeCART.py
2.4 基于随机森林的决策分类
随机森林是包含多个决策树的分类器。随机森林算法是由 Leo Breiman和Adele Cutler发展推论出的。随机森林,顾名思义就是用随机的方式建立一个森林,森林里面由很多的决策树组成,且这些决策树之间没有关联。
随机森林就是通过集成学习的思想将多棵树集成的一种算法,它的基本单元是决策树,而它的本质属于机器学习的一个分支—集成学习(Ensemble Learning)方法。集成学习就是使用一系列学习器进行学习,并将各个学习方法通过某种特定的规则进行整合,以获得比单个学习器更好的学习效果的一种机器学习方法。集成学习通过建立几个模型,并将它们组合来解决单一预测问题。它的工作原理主要是生成多个分类器或模型,各自独立的学习和做出预测。
随机森林是由多棵决策树构成的。对于每棵树,它们使用的训练集是采用放回的方式从总的训练集中采样出来的。而在训练每棵树的节点时,使用特征是从所有特征中,采用按照一定比例随机的无回放的方式抽取的。
随机森林的优点
- 随机森林算法能解决分类与回归两种类型的问题,并在这两个方面都有相当好的估计表现;
- 随机森林对于高维数据集的处理能力令人兴奋,它可以处理成千上万的输入变量,并确定最重要的变量,因此被认为是一个不错的降维方法。此外,该模型能够输出变量的重要性程度,这是一个非常便利的功能。
- 在对缺失数据进行估计时,随机森林是一个十分有效的方法。就算存在大量的数据缺失,随机森林也能较好地保持精确性。
- 当存在分类不平衡的情况时,随机森林能够提供平衡数据集误差的有效方法。
- 模型的上述性能可以被扩展运用到未标记的数据集中,用于引导无监督聚类、数据透视和异常检测;
- 随机森林算法中包含了对输入数据的重复自抽样过程,即所谓的bootstrap抽样。这样一来,数据集中大约三分之一将没有用于模型的训练而是用于测试,这样的数据被称为out of bag samples,通过这些样本估计的误差被称为out of bag error。
- 研究表明,这种out of bag方法的与测试集规模同训练集一致的估计方法有着相同的精确程度,因此在随机森林中我们无需再对测试集进行另外的设置。
- 训练速度快,容易做成并行化方法
随机森林的缺点
- 随机森林在解决回归问题时并没有像它在分类中表现的那么好,这是因为它并不能给出一个连续型的输出。当进行回归时,随机森林不能够作出超越训练集数据范围的预测,这可能导致在对某些还有特定噪声的数据进行建模时出现过度拟合。
- 对于许多统计建模者来说,随机森林给人的感觉像是一个黑盒子——你几乎无法控制模型内部的运行,只能在不同的参数和随机种子之间进行尝试。
随机森林的构造方法
随机森林的建立基本由随机采样和完全分裂两部分组成。
1、随机采样
随机森林对输入的数据进行行、列的采样,但两个采样的方法有所不同。对于行采样,采用的方法是有回放的采样,即在采样得到的样本集合中,可能会有重复的样本。假设输入样本为N个,那么采样的样本也是N个,这样使得在训练时,每科树的输入样本都不是全部的样本,所以相对不容易出现over-fitting。对于列采样,采用的方式是按照一定的比例无放回的抽取,从M个feature中,选择m个样本(n<<M)。
2、完全分裂
在形成决策树的过程中,决策树的每个节点都要按完全分裂的方式来分裂,直到节点不能再分裂。采用这种方式建立出的决策树的某一叶子节点要么是无法继续分裂的,要么里面的所有样本都是指向同一个分类。
接下来,将介绍每科树的构造方法,步骤如下:
- 用N表示训练集的个数,M表示变量的数目
- 用m来表示当在一个节点上做决定时会用到的变量的数量
- 从N个训练案例中采用可重复取样的方式,取样N次,形成一组训练集,并使用这棵树来对剩余变量预测其类别,并对误差进行计算。
- 对于每个节点,随机选择m个基于词典上的变量。根据这m个变量,计算其最佳的分割方式。
- 对于森林中的每棵树都不用采用剪枝技术,每棵树都能完整生长。
森林中任意两棵的相关性与森林中棵树的分类能力是影响随机森林分类效果(误差率)的两个重要因素。任意两棵树之间的相关性越大,错误率越大,每棵树的分类能力越强,整个森林的错误率越低。
随机森林实例
需要处理的问题:利用车厘子的质量、鲜红度、直径、产地及新鲜度预测这种车厘子的价格层次。
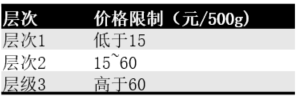
1、将随机森林中的每棵树视为一棵CART树,此处车厘子共有5个特征,因此设定随机深林中有5棵CART树。
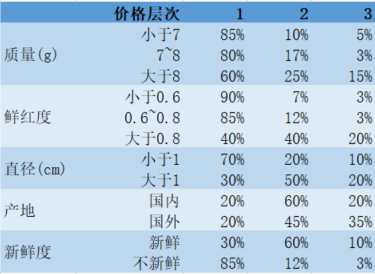
2、对应车厘子信息决定属于哪个价格层次
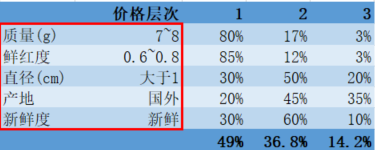
3、最终确定该车厘子可以按照一等(49%)的价格进行销售。
0x03 决策树的剪枝
决策树很容易发生过拟合,可以改善的方法有:
- 通过阈值控制终止条件,避免树形结构分支过细。
- 通过对已经形成的决策树进行剪枝来避免过拟合。
- 基于Bootstrap的思想建立随机森林。
3.1 剪枝的分类
为了避免决策树过拟合 (Overfitting) 样本,决策树要进行剪枝。CART剪枝算法为了能够对未知数据有更好的预测,从 “完全生长” 的决策树底部剪去一些子树,使决策树变小,模型变简单。预剪枝 (Pre-Pruning) 与后剪枝 (Post-Pruning) 是剪枝的两种情况。
预剪枝
预剪枝即是指在决策树的构造过程中,对每个节点在划分前需要根据不同的指标进行估计,如果已经满足对应指标了,则不再进行划分,否则继续划分。
树的增长不能是无限的,因此需要设定一些条件,若树的增长触发某个设定条件时,则树的增长需要进行停止继续。这些设定的条件称作停止条件 (Stopping Criteria), 常用的 停止条件如下:
- 直接指定树的深度
- 直接指定叶子节点个数
- 直接指定叶子节点的样本数
- 对应的信息增益量
- 拿验证集中的数据进行验证,看分割前后,精度是否有提高。
由于预剪枝是在构建决策树的同时进行剪枝处理,所以其训练时间开销较少,同时可以有效的降低过拟合的风险。但是,预剪枝有一个问题,会给决策树带来欠拟合的风险,1,2,3,4指标,不用过多解释,对于5指标来说,
虽然,当前划分不能导致性能提高,但是,或许在此基础上的后续划分,却能使性能显著提高呢?
后剪枝
后剪枝则是先根据训练集生成一颗完整的决策树,然后根据相关方法进行剪枝。常用的一种方法是,自底向上,对非叶子节点进行考察,同样拿验证集中的数据,来根据精度进行考察。看该节点划分前和划分后,精度是否有提高,如果划分后精度没有提高,则剪掉此子树,将其替换为叶子节点。
相对于预剪枝来说,后剪枝的欠拟合风险很小,同时,泛化能力往往要优于预剪枝,但是,因为后剪枝先要生成整个决策树后,然后才自底向上依次考察每个非叶子节点,所以训练时间长。
3.2 后剪枝算法
Reduced-Error Pruning (错误率降低剪枝, REP)
REP算法是最简单的后剪枝方法之一 它需要使用一个剪枝验证集来对决策树进行剪枝, 用训练集合来训练数据。 通常取出可用样例的三分之一用作验证集合,用剩余三分之二作训练集合。 它主要用于防止决策树的过度拟合。
决定是否修剪某个结点的步骤如下:
- 删除以该结点作为根结点的子树
- 使该结点成为叶子结点
- 赋予该结点关联的训练数据的最常见分类
- 当修剪后的树对于验证集合的性能与原来的树相同或优于原来的树时,该结点才真正被删除
利用训练集合过拟合的性质,使训练集合数据能够对其进行修正,反复进行上述步骤,采用自底向上的方法处理结点,将那些能够最大限度地提高验证集合的精度的结点删去,直到进一步修剪有害(修剪会减低验证集合的精度)为止。在数据量较少的情况下很少应用REP方法。该方法趋于过拟合,这是因为训练数据集中存在的特性在剪枝过程中都被忽略,当剪枝数据集比训练数据集小得多时这个问题需要特别注意。
Pessimistic Error Pruning (悲观剪枝,PEP)(用于 C4.5)
PEP剪枝算法是在C4.5决策树算法中提出的,该方法基于训练数据的误差评估,因此比起REP剪枝法,它不需要一个单独的测试数据集。但训练数据也带来错分误差偏向于训练集,因此需要加入修正1/2(惩罚因子,用常数0.5),是自上而下的修剪。 之所以叫“悲观”,可能正是因为每个叶子结点都会主观加入一个惩罚因子,“悲观”地提高误判率。
悲观错误剪枝法是根据剪枝前后的误判率来判定子树的修剪。该方法引入了统计学上连续修正的概念弥补REP中的缺陷,在评价子树的训练错误公式中添加了一个常数,假定每个叶子结点都自动对实例的某个部分进行错误的分类。
把一颗子树(具有多个叶子节点)的分类用一个叶子节点来替代的话,在训练集上的误判率肯定是上升的,但是在新数据上不一定。于是我们需要把子树的误判计算加上一个经验性的惩罚因子。对于一颗叶子节点,它覆盖了N个样本,其中有E个错误,那么该叶子节点的误判率为(E+0.5)/N,这个0.5就是惩罚因子。
那么对于一颗拥有L个叶子结点的子树,该子树的误判率估计为:
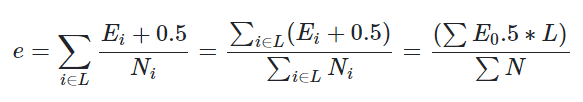
这样的话,我们可以看到一颗子树虽然具有多个子节点,但由于加上了惩罚因子,所以子树的误判率计算未必占到便宜。剪枝后内部节点变成了叶子节点,其误判个数J也需要加上一个惩罚因子,变成J+0.5。使用训练数据,子树总是比替换为一个叶节点后产生的误差小,但是使用修正后有误差计算方法却并非如此,当子树的误判个数大过对应叶节点的误判个数一个标准差之后,就决定剪枝,即满足被替换子树的误判数 – 标准差 > 新叶子的误判数,写成公式为:
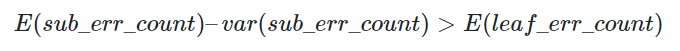
这里出现的标准差如何计算呢?
我们假定一棵子树错误分类一个样本的值为1,正确分类一个样本的值为0,该子树错误分类的概率(误判率)为e,则每分类一个样本都可以近似看作是一次伯努利试验,覆盖N个样本的话就是做N次独立的伯努利试验,因此,我们可以把子树误判次数近似看成是服从B(N, e)的二项分布(二项分布就是重复N次独立的伯努利试验)。因此,我们很容易估计出子该树误判次数均值和标准差:

当然并不一定非要大一个标准差,可以给定任意的置信区间,我们设定一定的显著性因子,就可以估算出误判次数的上下界。对于给定的置信区间,采用下界估计作为规则性能的度量。这样做的结果是对于大的数据集合,该剪枝策略能够非常接近观察精度,随着数据集合的减小,离观察精度越来越远。该剪枝方法尽管不是统计有效的,但是在实践中有效。
PEP采用自顶向下的方式 将符合上述不等式的非叶子结点裁剪掉。该算法看作目前决策树后剪枝算法中精度比较高的算法之一,同时该算法仍存在一些缺陷。首先,PEP算法是唯一使用自顶向上剪枝策略的后剪枝算法,但这样的方法有时会导致某些不该被剪掉的某结点的子结点被剪掉。虽然PEP方法存在一些局限性,但是在实际应用中表现出了较高的精度。
Minimum Error Pruning (最小误差剪枝,MEP)


0x04 参考链接
0x05 转载
https://www.biaodianfu.com/decision-tree.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号