机器学习笔记之线性回归最小二乘法(公式推导和非调包实现)
0x00 概述
博主前面一篇文章讲述了二维线性回归问题的求解原理和推导过程,以及使用python自己实现算法,但是那种方法只能适用于普通的二维平面问题,
今天博主来讲一下线性回归问题中更为通用的方法,也是我们实际开发中会经常用到的一个数学模型,常用的解法就是最小二次乘法和梯度下降法.博主今天对最小二乘法进行推导并使用Python代码自定义实现,废话不多说,开始吧:
0x01 公式推导
假如现在有一堆这样的数据,

然后我们已经通过某种方式得到了数据所对应的模型
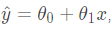
但是因为y^ 毕竟是通过训练模型所得到的预测值,所以 y ^与 y之间必定存在误差如图所示:
也就是说存在一个这样的等式
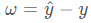
其中 ω 的值代表误差值.现在不妨我们再来将训练数据换一下变成
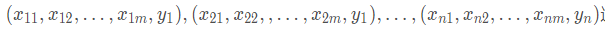
这里有n项数据,其中每项数据的前 m 个数据代表特征值,最后的一个数据代表标签值(也就是真实的 y 值),对这个数据我们通过线性模型也可以将数据对应的模型写出来:y ^ = θ 0 + θ 1 x 1 + θ 2 x 2 + ⋯ + θ m x m不妨简化一下换成矩阵的形式表示:

上面这个函数方程即表示我们的拟合曲线,再结合我们前面分析的误差结论可知(因为误差值可正可负,这里加减就无所谓了):
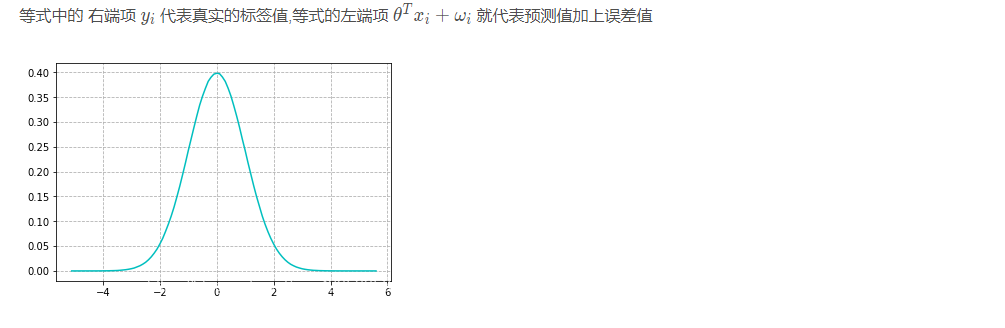
上图这个图应该很眼熟吧,没错就是表示正态分布(也称高斯分布)的统计图,其实现实生活中,误差的波动性也大多遵循这个规律.是什么意思呢?我们可以把图中的横坐标想作误差值,而纵坐标想成概率值,那么从图中我们可以发现一个很有意思的规律,误差值的绝对值越大那么它出现的概率反而会越小越趋近于0,误差值在0附近时可以看它们出现的概率是最大的,也就是说那种极大或者极小的误差值是占少数的.我们现在要引出一个函数也就是高斯分布的概率密度函数:
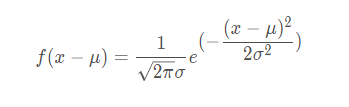
不懂概率密度函数的小伙伴也别急,你就把这个函数的自变量想成事件,然后函数的值想作此事件发生的概率即可;
既然误差遵循这个规律,那么我们就可以把前面我们得到的模型公式和概率密度函数联合起来就有:
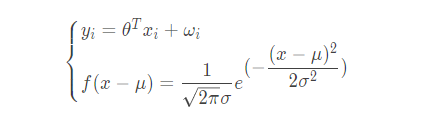
将 ω i 代入概率密度函数就有
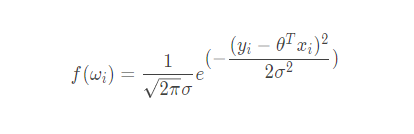
我们通常习惯用 p ( A ∣ B ) p(A|B)p(A∣B) 来表示B事件发生后A事件发生的概率,前面的公式也就可以变成:

上式即表示我们通过训练模型得到准确值的概率,这个式子只是求单个数据得到真实值的概率,我们现在要来求全部数据都预测正确的概率,因为每个预测事件都是相互独立,的所以求全部正确概率只需要将所有单个的概率乘起来即可,那么就有:
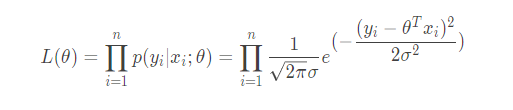
这个函数有个官方的名称叫做似然函数,它表示参数 θ 所对应的模型预测值全部与真实值相匹配的概率,也可以把它看做预测模型与数据的真实模型的相似度,显然看着上面的式子都很头大,很难计算,不妨将它转化一下.两边同时取对数:
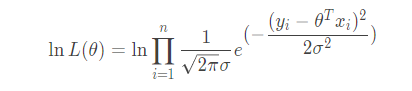
它表示对数似然函数,这里图方便后面化简就取以 e 为底的对数,去了对数之后不妨来看有什么好处,我们来化简一下:
因为对数内部的乘法可以展开为外部的加法即log(ab)=loga+logb,所以:
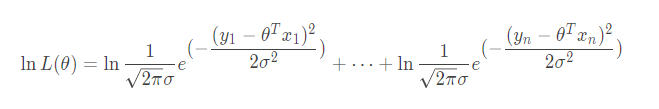
把它在弄好看一点:
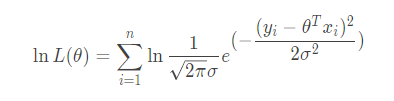
再次利用对数的乘法变加法性质展开得:
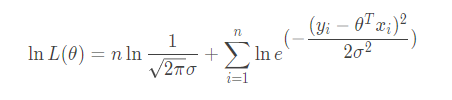
我们都知对数有这样一个性质: loga an=n 那么就有:
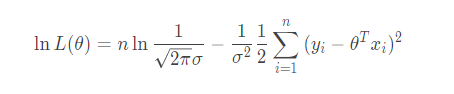
为了便于观察,我们把常数项用 t 来代替掉:
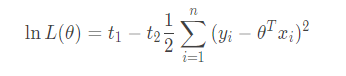

0x02 矩阵的乘法(补充)

0x03 求偏导



0x04 代码实现
- 有了计算方式,那么使用代码来实现就简单了
- 先定义计算 θ \thetaθ 的函数
import matplotlib.pyplot as plt import numpy as np def train_model(x_data,y_data): # 逻辑很简单就是把求theta的公式实现了一遍 matrix_x = np.matrix(x_data) matrix_y = np.matrix(y_data) matrix_x_T = matrix_x.T t1 = np.dot(matrix_x_T,matrix_x) t1_I = t1.I t2 = np.dot(t1_I,matrix_x_T) theta = np.dot(t2,matrix_y) return theta
- 定义使用模型进行预测的函数:
def predict(model,x_data): # 这里因为我们传入的x_data是 n×m,model是 m×1,所以反过来乘代码逻辑就会简单许多 return np.dot(np.matrix(x_data),model)
- 加载数据
# 导入自带的波士顿房价数据 from sklearn.datasets import load_boston boston_data = load_boston().data train_x = boston_data[:,:-1] # 这里需要注意的波士顿原本数据内只有12个特征值,前面也说过我们的模型有一个单出来的 theta0 # 那么我们只需要在数据中认为的假如一列特征列,全部置一即可 # 也就是 t_0x_0+t_1x_1+...+t_12x_12 # 我们把方程中的t_0全部变为1即可 ones_x = np.ones(train_x.shape[0]) train_x = np.column_stack((ones_x,train_x)) train_y = boston_data[:,-1:]
- 训练模型
model = train_model(train_x,train_y) model.shape # (13,1)
- 预测数据
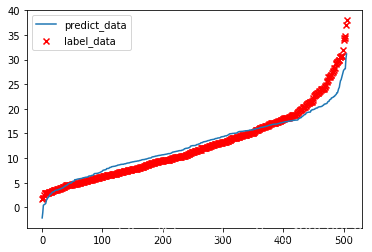
p_y = predict(model,train_x)
p_y = np.sort(np.array(p_y)[:,0])
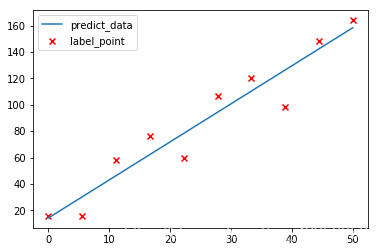
- 在图上绘制数据
plt.scatter(np.arange(0,506),np.sort(boston_data[:,-1]),marker="x",c="r",label="label_data") plt.plot(np.arange(0,506),p_y,label="predict_data") plt.legend()
0x05 转载

 浙公网安备 33010602011771号
浙公网安备 33010602011771号