机器学习笔记之线性回归、岭回归、Lasso回归
0x00 概述
线性回归作为一种回归分析技术,其分析的因变量属于连续型变量,如果因变量转变为离散型变量,将转换为分类问题。
回归分析属于有监督学习问题,本博客将重点回顾标准线性回归知识点,并就线性回归中可能出现的问题进行简单探讨,引出线性回归的两个变种岭回归以及Lasso回归,最后通过sklearn库模拟整个回归过程。
0x01 线性回归的一般形式

0x02 线性回归中可能遇到的问题
''' 1. 求解损失函数的最小值有两种方法:梯度下降法以及正规方程,两者的对比在附加笔记中有列出。 2. 特征缩放:即对特征数据进行归一化操作,进行特征缩放的好处有两点,一是能够提升模型的收敛速度,因为如果特征间的数据相差级别较大的话,以两个特征为例,以这两个特征为横纵坐标绘制等高线图,绘制出来是扁平状的椭圆,
这时候通过梯度下降法寻找梯度方向最终将走垂直于等高线的之字形路线,迭代速度变慢。但是如果对特征进行归一化操作之后,整个等高线图将呈现圆形,梯度的方向是指向圆心的,迭代速度远远大于前者。二是能够提升模型精度。 3. 学习率α的选取:如果学习率α选取过小,会导致迭代次数变多,收敛速度变慢;学习率α选取过大,有可能会跳过最优解,最终导致根本无法收敛。 '''
0x03 过拟合问题及其解决方法
以下面一张图片展示过拟合问题

解决方法:
(1):丢弃一些对我们最终预测结果影响不大的特征,具体哪些特征需要丢弃可以通过PCA算法来实现;
(2):使用正则化技术,保留所有特征,但是减少特征前面的参数θ的大小,具体就是修改线性回归中的损失函数形式即可,岭回归以及Lasso回归就是这么做的。
0x04 线性回归代码示例
import matplotlib.pyplot as plt import numpy as np from sklearn import datasets, linear_model, discriminant_analysis, cross_validation def load_data(): diabetes = datasets.load_diabetes() return cross_validation.train_test_split(diabetes.data, diabetes.target, test_size=0.25, random_state=0) def test_LinearRegression(*data): X_train, X_test, y_train, y_test = data #通过sklearn的linear_model创建线性回归对象 linearRegression = linear_model.LinearRegression() #进行训练 linearRegression.fit(X_train, y_train) #通过LinearRegression的coef_属性获得权重向量,intercept_获得b的值 print("权重向量:%s, b的值为:%.2f" % (linearRegression.coef_, linearRegression.intercept_)) #计算出损失函数的值 print("损失函数的值: %.2f" % np.mean((linearRegression.predict(X_test) - y_test) ** 2)) #计算预测性能得分 print("预测性能得分: %.2f" % linearRegression.score(X_test, y_test)) if __name__ == '__main__': #获得数据集 X_train, X_test, y_train, y_test = load_data() #进行训练并且输出预测结果 test_LinearRegression(X_train, X_test, y_train, y_test)
0x05 岭回归与Lasso回归
岭回归与Lasso回归的出现是为了解决线性回归出现的过拟合以及在通过正规方程方法求解θ的过程中出现的x转置乘以x不可逆这两类问题的,这两种回归均通过在损失函数中引入正则化项来达到目的,具体三者的损失函数对比见下图:
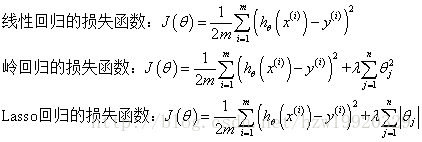
其中λ称为正则化参数,如果λ选取过大,会把所有参数θ均最小化,造成欠拟合,如果λ选取过小,会导致对过拟合问题解决不当,因此λ的选取是一个技术活。
岭回归与Lasso回归最大的区别在于岭回归引入的是L2范数惩罚项,Lasso回归引入的是L1范数惩罚项,Lasso回归能够使得损失函数中的许多θ均变成0,这点要优于岭回归,因为岭回归是要所有的θ均存在的,这样计算量Lasso回归将远远小于岭回归。

可以看到,Lasso回归最终会趋于一条直线,原因就在于好多θ值已经均为0,而岭回归却有一定平滑度,因为所有的θ值均存在。
0x06 岭回归以及Lasso回归代码实现
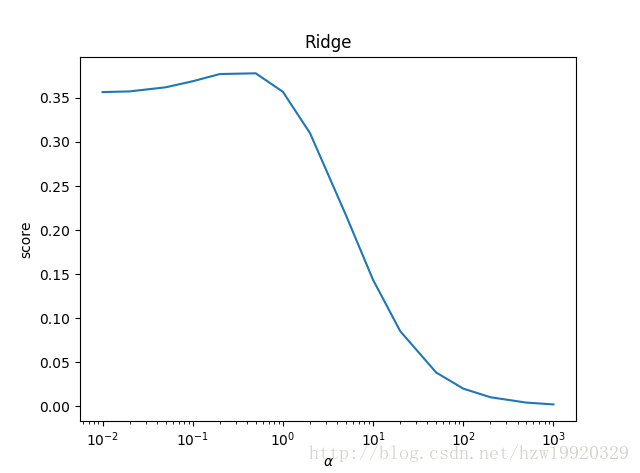
6.1 岭回归代码示例
import matplotlib.pyplot as plt import numpy as np from sklearn import datasets, linear_model, discriminant_analysis, cross_validation def load_data(): diabetes = datasets.load_diabetes() return cross_validation.train_test_split(diabetes.data, diabetes.target, test_size=0.25, random_state=0) def test_ridge(*data): X_train, X_test, y_train, y_test = data ridgeRegression = linear_model.Ridge() ridgeRegression.fit(X_train, y_train) print("权重向量:%s, b的值为:%.2f" % (ridgeRegression.coef_, ridgeRegression.intercept_)) print("损失函数的值:%.2f" % np.mean((ridgeRegression.predict(X_test) - y_test) ** 2)) print("预测性能得分: %.2f" % ridgeRegression.score(X_test, y_test)) #测试不同的α值对预测性能的影响 def test_ridge_alpha(*data): X_train, X_test, y_train, y_test = data alphas = [0.01, 0.02, 0.05, 0.1, 0.2, 0.5, 1, 2, 5, 10, 20, 50, 100, 200, 500, 1000] scores = [] for i, alpha in enumerate(alphas): ridgeRegression = linear_model.Ridge(alpha=alpha) ridgeRegression.fit(X_train, y_train) scores.append(ridgeRegression.score(X_test, y_test)) return alphas, scores def show_plot(alphas, scores): figure = plt.figure() ax = figure.add_subplot(1, 1, 1) ax.plot(alphas, scores) ax.set_xlabel(r"$\alpha$") ax.set_ylabel(r"score") ax.set_xscale("log") ax.set_title("Ridge") plt.show() if __name__ == '__main__': #使用默认的alpha #获得数据集 #X_train, X_test, y_train, y_test = load_data() #进行训练并且预测结果 #test_ridge(X_train, X_test, y_train, y_test) #使用自己设置的alpha X_train, X_test, y_train, y_test = load_data() alphas, scores = test_ridge_alpha(X_train, X_test, y_train, y_test) show_plot(alphas, scores)
6.2 Lasso回归代码示例
import matplotlib.pyplot as plt import numpy as np from sklearn import datasets, linear_model, discriminant_analysis, cross_validation def load_data(): diabetes = datasets.load_diabetes() return cross_validation.train_test_split(diabetes.data, diabetes.target, test_size=0.25, random_state=0) def test_lasso(*data): X_train, X_test, y_train, y_test = data lassoRegression = linear_model.Lasso() lassoRegression.fit(X_train, y_train) print("权重向量:%s, b的值为:%.2f" % (lassoRegression.coef_, lassoRegression.intercept_)) print("损失函数的值:%.2f" % np.mean((lassoRegression.predict(X_test) - y_test) ** 2)) print("预测性能得分: %.2f" % lassoRegression.score(X_test, y_test)) #测试不同的α值对预测性能的影响 def test_lasso_alpha(*data): X_train, X_test, y_train, y_test = data alphas = [0.01, 0.02, 0.05, 0.1, 0.2, 0.5, 1, 2, 5, 10, 20, 50, 100, 200, 500, 1000] scores = [] for i, alpha in enumerate(alphas): lassoRegression = linear_model.Lasso(alpha=alpha) lassoRegression.fit(X_train, y_train) scores.append(lassoRegression.score(X_test, y_test)) return alphas, scores def show_plot(alphas, scores): figure = plt.figure() ax = figure.add_subplot(1, 1, 1) ax.plot(alphas, scores) ax.set_xlabel(r"$\alpha$") ax.set_ylabel(r"score") ax.set_xscale("log") ax.set_title("Ridge") plt.show() if __name__=='__main__': X_train, X_test, y_train, y_test = load_data() # 使用默认的alpha #test_lasso(X_train, X_test, y_train, y_test) # 使用自己设置的alpha alphas, scores = test_lasso_alpha(X_train, X_test, y_train, y_test) show_plot(alphas, scores)
0x07 附上学习笔记



0x08 参考
- python大战机器学习
- Andrew Ng机器学习公开课
- http://www.jianshu.com/p/35e67c9e4cbf
- http://freemind.pluskid.org/machine-learning/sparsity-and-some-basics-of-l1-regularization/#ed61992b37932e208ae114be75e42a3e6dc34cb3
0x09 转载

 浙公网安备 33010602011771号
浙公网安备 33010602011771号