大数据作业2
1.了解对比Hadoop不同版本的特性,可以用图表的形式呈现。
Hadoop是一个能够对大量数据进行分布式处理的软件框架。 Hadoop 以一种可靠、高效、可伸缩的方式进行数据处理。
Hadoop的发行版除了有Apache hadoop外cloudera,hortonworks,mapR,华为,DKhadoop等都提供了自己的商业版本。
商业发行版主要是提供了更为专业的技术支持,这对于大型企业更为重要,不同发行版都有自己的一些特点,本文就各发行版做简单对比介绍。
对比版选择:DKhadoop发行版、cloudera发行版、hortonworks发行版。
1、DKhadoop发行版:有效的集成了整个HADOOP生态系统的全部组件,并深度优化,重新编译为一个完整的更高性能的大数据通用计算平台,实现了各部件的有机协调。因此DKH相比开源的大数据平台,在计算性能上有了高达5倍(最大)的性能提升。DKhadoop将复杂的大数据集群配置简化至三种节点(主节点、管理节点、计算节点),极大的简化了集群的管理运维,增强了集群的高可用性、高可维护性、高稳定性。
2、Cloudera发行版:CDH是Cloudera的hadoop发行版,完全开源,比Apache hadoop在兼容性,安全性,稳定性上有增强。
3、€Hortonworks发行版:Hortonworks 的主打产品是Hortonworks Data Platform (HDP),也同样是100%开源的产品,其版本特点:HDP包括稳定版本的Apache Hadoop的所有关键组件;安装方便,HDP包括一个现代化的,直观的用户界面的安装和配置工具。
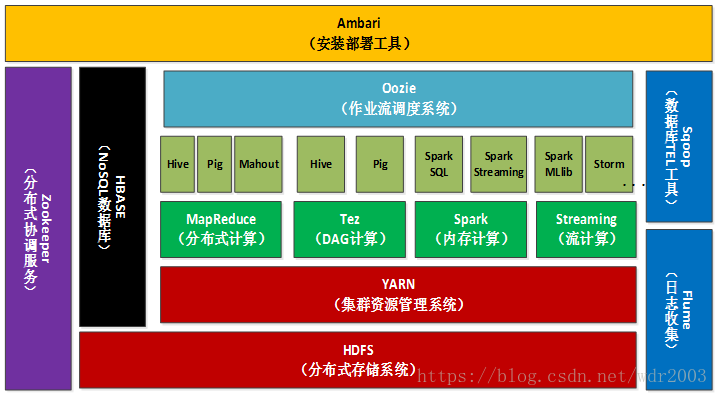
2.Hadoop生态的组成、每个组件的作用、组件之间的相互关系,以图例加文字描述呈现。
Hadoop生态系统概况
Hadoop是一个能够对大量数据进行分布式处理的软件框架。具有可靠、高效、可伸缩的特点。
Hadoop的核心是HDFS和MapReduce,hadoop2.0还包括YARN。
下图为hadoop的生态系统:
HDFS(Hadoop分布式文件系统)
源自于Google的GFS论文,发表于2003年10月,HDFS是GFS克隆版。
是Hadoop体系中数据存储管理的基础。它是一个高度容错的系统,能检测和应对硬件故障,用于在低成本的通用硬件上运行。HDFS简化了文件的一致性模型,通过流式数据访问,提供高吞吐量应用程序数据访问功能,适合带有大型数据集的应用程序。
HDFS主要有以下几个部分组成:
- Client:切分文件;访问HDFS;与NameNode交互,获取文件位置信息;与DataNode交互,读取和写入数据。
- NameNode:Master节点,在hadoop1.X中只有一个,管理HDFS的名称空间和数据块映射信息,配置副本策略,处理客户端请求。对于大型的集群来讲,Hadoop1.x存在两个最大的缺陷:
- 1)对于大型的集群,namenode的内存成为瓶颈,namenode的扩展性的问题;
- 2)namenode的单点故障问题。
- 针对以上的两个缺陷,Hadoop2.x以后分别对这两个问题进行了解决。
- 对于缺陷1)提出了Federation namenode来解决,该方案主要是通过多个namenode来实现多个命名空间来实现namenode的横向扩张。从而减轻单个namenode内存问题。
- 针对缺陷2),hadoop2.X提出了实现两个namenode实现热备HA的方案来解决。其中一个是处于standby状态,一个处于active状态。
- DataNode:Slave节点,存储实际的数据,汇报存储信息给NameNode。
- Secondary NameNode:辅助NameNode,分担其工作量;定期合并fsimage和edits,推送给NameNode;紧急情况下,可辅助恢复NameNode,但Secondary NameNode并非NameNode的热备。
目前,在硬盘不坏的情况,我们可以通过secondarynamenode来实现namenode的恢复。
Mapreduce(分布式计算框架)
源自于google的MapReduce论文,发表于2004年12月,Hadoop MapReduce是google MapReduce 克隆版。MapReduce是一种计算模型,用以进行大数据量的计算。其中Map对数据集上的独立元素进行指定的操作,生成键-值对形式中间结果。Reduce则对中间结果中相同“键”的所有“值”进行规约,以得到最终结果。MapReduce这样的功能划分,非常适合在大量计算机组成的分布式并行环境里进行数据处理。
MapReduce计算框架发展到现在有两个版本的MapReduce的API,针对MR1主要组件有以下几个部分组成:
(1)JobTracker:Master节点,只有一个,主要任务是资源的分配和作业的调度及监督管理,管理所有作业,作业/任务的监控、错误处理等;将任务分解成一系列任务,并分派给TaskTracker。
(2)TaskTracker:Slave节点,运行Map Task和Reduce Task;并与JobTracker交互,汇报任务状态。
(3)Map Task:解析每条数据记录,传递给用户编写的map(),并执行,将输出结果写入本地磁盘。
(4)Reducer Task:从Map Task的执行结果中,远程读取输入数据,对数据进行排序,将数据按照分组传递给用户编写的reduce函数执行。
在这个过程中,有一个shuffle过程,对于该过程是理解MapReduce计算框架是关键。该过程包含map函数输出结果到reduce函数输入这一个中间过程中所有的操作,称之为shuffle过程。在这个过程中,可以分为map端和reduce端。
Map端:
1) 输入数据进行分片之后,分片的大小跟原始的文件大小、文件块的大小有关。每一个分片对应的一个map任务。
2) map任务在执行的过程中,会将结果存放到内存当中,当内存占用达到一定的阈值(这个阈值是可以设置的)时,map会将中间的结果写入到本地磁盘上,形成临时文件这个过程叫做溢写。
3) map在溢写的过程中,会根据指定reduce任务个数分别写到对应的分区当中,这就是partition过程。每一个分区对应的是一个reduce任务。并且在写的过程中,进行相应的排序。在溢写的过程中还可以设置conbiner过程,该过程跟reduce产生的结果应该是一致的,因此该过程应用存在一定的限制,需要慎用。
4) 每一个map端最后都只存在一个临时文件作为reduce的输入,因此会对中间溢写到磁盘的多个临时文件进行合并Merge操作。最后形成一个内部分区的一个临时文件。
Reduce端:
1) 首先要实现数据本地化,需要将远程节点上的map输出复制到本地。
2) Merge过程,这个合并过程主要是对不同的节点上的map输出结果进行合并。
3) 不断的复制和合并之后,最终形成一个输入文件。Reduce将最终的计算结果存放在HDFS上。
针对MR2是新一代的MR的API。其主要是运行在Yarn的资源管理框架上。
Yarn(资源管理框架)
YARN (Yet Another Resource Negotiator,另一种资源协调者)是一种新的 Hadoop 资源管理器,它是一个通用资源管理系统,可为上层应用提供统一的资源管理和调度,它的引入为集群在利用率、资源统一管理和数据共享等方面带来了巨大好处。
YARN的基本思想是将JobTracker的两个主要功能(资源管理和作业调度/监控)分离,主要方法是创建一个全局的ResourceManager(RM)和若干个针对应用程序的ApplicationMaster(AM)。这里的应用程序是指传统的MapReduce作业或作业的DAG(有向无环图)。
该框架是hadoop2.x以后对hadoop1.x之前JobTracker和TaskTracker模型的优化,而产生出来的,将JobTracker的资源分配和作业调度及监督分开。该框架主要有ResourceManager,Applicationmatser,nodemanager。其主要工作过程如下:
- ResourceManager主要负责所有的应用程序的资源分配,
- ApplicationMaster主要负责每个作业的任务调度,也就是说每一个作业对应一个ApplicationMaster。
- Nodemanager是接收Resourcemanager 和ApplicationMaster的命令来实现资源的分配执行体。
ResourceManager在接收到client的作业提交请求之后,会分配一个Conbiner,这里需要说明一下的是Resoucemanager分配资源是以Conbiner为单位分配的。第一个被分配的Conbiner会启动Applicationmaster,它主要负责作业的调度。Applicationmanager启动之后则会直接跟NodeManager通信。
在YARN中,资源管理由ResourceManager和NodeManager共同完成,其中,ResourceManager中的调度器负责资源的分配,而NodeManager则负责资源的供给和隔离。ResourceManager将某个NodeManager上资源分配给任务(这就是所谓的“资源调度”)后,NodeManager需按照要求为任务提供相应的资源,甚至保证这些资源应具有独占性,为任务运行提供基础的保证,这就是所谓的资源隔离。
在Yarn平台上可以运行多个计算框架,如:MR,Tez,Storm,Spark等计算,框架。
Sqoop(数据同步工具)
Sqoop是SQL-to-Hadoop的缩写,主要用于传统数据库和Hadoop之间传输数据。数据的导入和导出本质上是Mapreduce程序,充分利用了MR的并行化和容错性。其中主要利用的是MP中的Map任务来实现并行导入,导出。Sqoop发展到现在已经出现了两个版本,一个是sqoop1.x.x系列,一个是sqoop1.99.X系列。对于sqoop1系列中,主要是通过命令行的方式来操作。
- sqoop1 import原理:从传统数据库获取元数据信息(schema、table、field、field type),把导入功能转换为只有Map的Mapreduce作业,在mapreduce中有很多map,每个map读一片数据,进而并行的完成数据的拷贝。
- sqoop1 export原理:获取导出表的schema、meta信息,和Hadoop中的字段match;多个map only作业同时运行,完成hdfs中数据导出到关系型数据库中。
- Sqoop1.99.x是属于sqoop2的产品,该款产品目前功能还不是很完善,处于一个测试阶段,一般并不会应用于商业化产品当中。
Mahout(数据挖掘算法库)
Mahout起源于2008年,最初是Apache Lucent的子项目,它在极短的时间内取得了长足的发展,现在是Apache的顶级项目。相对于传统的MapReduce编程方式来实现机器学习的算法时,往往需要话费大量的开发时间,并且周期较长,而Mahout的主要目标是创建一些可扩展的机器学习领域经典算法的实现,旨在帮助开发人员更加方便快捷地创建智能应用程序。
Mahout现在已经包含了聚类、分类、推荐引擎(协同过滤)和频繁集挖掘等广泛使用的数据挖掘方法。除了算法,Mahout还包含数据的输入/输出工具、与其他存储系统(如数据库、MongoDB 或Cassandra)集成等数据挖掘支持架构。
mahout的各个组件下面都会生成相应的jar包。此时我们需要明白一个问题:到底如何使用mahout呢?
实际上,mahout只是一个机器学习的算法库,在这个库当中是想了相应的机器学习的算法,如:推荐系统(包括基于用户和基于物品的推荐),聚类和分类算法。并且这些算法有些实现了MapReduce,spark从而可以在hadoop平台上运行,在实际的开发过程中,只需要将相应的jar包即可。
Hbase(分布式列存数据库)
源自Google的Bigtable论文,发表于2006年11月,传统的关系型数据库是对面向行的数据库。HBase是Google Bigtable克隆版,HBase是一个针对结构化数据的可伸缩、高可靠、高性能、分布式和面向列的动态模式数据库。和传统关系数据库不同,HBase采用了BigTable的数据模型:增强的稀疏排序映射表(Key/Value),其中,键由行关键字、列关键字和时间戳构成。HBase提供了对大规模数据的随机、实时读写访问,同时,HBase中保存的数据可以使用MapReduce来处理,它将数据存储和并行计算完美地结合在一起。
Hbase表的特点
- 大:一个表可以有数十亿行,上百万列;
- 无模式:每行都有一个可排序的主键和任意多的列,列可以根据需要动态的增加,同一张表中不同的行可以有截然不同的列;
- 面向列:面向列(族)的存储和权限控制,列(族)独立检索;
- 稀疏:空(null)列并不占用存储空间,表可以设计的非常稀疏;
- 数据多版本:每个单元中的数据可以有多个版本,默认情况下版本号自动分配,是单元格插入时的时间戳;
-
数据类型单一:Hbase中的数据都是字符串,没有类型。
Hbase物理模型
每个column family存储在HDFS上的一个单独文件中,空值不会被保存。
Key 和 Version number在每个 column family中均有一份;
HBase 为每个值维护了多级索引,即:”key, column family, column name, timestamp”,其物理存储:- Table中所有行都按照row key的字典序排列;
- Table在行的方向上分割为多个Region;
- Region按大小分割的,每个表开始只有一个region,随着数据增多,region不断增大,当增大到一个阀值的时候,region就会等分会两个新的region,之后会有越来越多的region;
- Region是Hbase中分布式存储和负载均衡的最小单元,不同Region分布到不同RegionServer上。、
- Region虽然是分布式存储的最小单元,但并不是存储的最小单元。Region由一个或者多个Store组成,每个store保存一个columns family;每个Strore又由一个memStore和0至多个StoreFile组成,StoreFile包含HFile;memStore存储在内存中,StoreFile存储在HDFS上。
Zookeeper(分布式协作服务)
源自Google的Chubby论文,发表于2006年11月,Zookeeper是Chubby克隆版,主要解决分布式环境下的数据管理问题:统一命名,状态同步,集群管理,配置同步等。
Zookeeper的主要实现两步:
- 选举Leader
- 同步数据。这个组件在实现namenode的HA高可用性的时候,需要用到。
Pig(基于Hadoop的数据流系统)
由yahoo!开源,设计动机是提供一种基于MapReduce的ad-hoc(计算在query时发生)数据分析工具
定义了一种数据流语言—Pig Latin,将脚本转换为MapReduce任务在Hadoop上执行。通常用于进行离线分析。
Hive(基于Hadoop的数据仓库)
由facebook开源,最初用于解决海量结构化的日志数据统计问题。
Hive定义了一种类似SQL的查询语言(HQL),将SQL转化为MapReduce任务在Hadoop上执行。通常用于离线分析。
Flume(日志收集工具)
Cloudera开源的日志收集系统,具有分布式、高可靠、高容错、易于定制和扩展的特点。
它将数据从产生、传输、处理并最终写入目标的路径的过程抽象为数据流,在具体的数据流中,数据源支持在Flume中定制数据发送方,从而支持收集各种不同协议数据。同时,Flume数据流提供对日志数据进行简单处理的能力,如过滤、格式转换等。此外,Flume还具有能够将日志写往各种数据目标(可定制)的能力。总的来说,Flume是一个可扩展、适合复杂环境的海量日志收集系统。
Oozie
在Hadoop中执行的任务有时候需要把多个Map/Reduce作业连接到一起,这样才能够达到目的。在Hadoop生态圈中,有一种相对比较新的组件叫做Oozie,它让我们可以把多个Map/Reduce作业组合到一个逻辑工作单元中,从而完成更大型的任务。
Oozie是一种Java Web应用程序,它运行在Java servlet容器——即Tomcat——中,并使用数据库来存储以下内容:
1、工作流定义
2、当前运行的工作流实例,包括实例的状态和变量
Oozie工作流是放置在控制依赖DAG(有向无环图 Direct Acyclic Graph)中的一组动作(例如,Hadoop的Map/Reduce作业、Pig作业等),其中指定了动作执行的顺序。我们会使用hPDL(一种XML流程定义语言)来描述这个图。
Spark
Spark 是专为大规模数据处理而设计的快速通用的计算引擎。Spark是UC Berkeley AMP lab (加州大学伯克利分校的AMP实验室)所开源的类Hadoop MapReduce的通用并行框架,Spark,拥有Hadoop MapReduce所具有的优点;但不同于MapReduce的是——Job中间输出结果可以保存在内存中,从而不再需要读写HDFS,因此Spark能更好地适用于数据挖掘与机器学习等需要迭代的MapReduce的算法。
Spark 是一种与 Hadoop 相似的开源集群计算环境,但是两者之间还存在一些不同之处,这些有用的不同之处使 Spark 在某些工作负载方面表现得更加优越,换句话说,Spark 启用了内存分布数据集,除了能够提供交互式查询外,它还可以优化迭代工作负载。
Spark 是在 Scala 语言中实现的,它将 Scala 用作其应用程序框架。与 Hadoop 不同,Spark 和 Scala 能够紧密集成,其中的 Scala 可以像操作本地集合对象一样轻松地操作分布式数据集。
尽管创建 Spark 是为了支持分布式数据集上的迭代作业,但是实际上它是对 Hadoop 的补充,可以在 Hadoop 文件系统中并行运行。通过名为 Mesos 的第三方集群框架可以支持此行为。Spark 由加州大学伯克利分校 AMP 实验室 (Algorithms, Machines, and People Lab) 开发,可用来构建大型的、低延迟的数据分析应用程序。
Tez
Tez是一个针对Hadoop数据处理应用程序的新分布式执行框架。Tez是Apache最新的支持DAG作业的开源计算框架,它可以将多个有依赖的作业转换为一个作业从而大幅提升DAG作业的性能。Tez并不直接面向最终用户——事实上它允许开发者为最终用户构建性能更快、扩展性更好的应用程序。Hadoop传统上是一个大量数据批处理平台。但是,有很多用例需要近乎实时的查询处理性能。还有一些工作则不太适合MapReduce,例如机器学习。Tez的目的就是帮助Hadoop处理这些用例场景。
Tez项目的目标是支持高度定制化,这样它就能够满足各种用例的需要,让人们不必借助其他的外部方式就能完成自己的工作,如果 Hive和 Pig 这样的项目使用Tez而不是MapReduce作为其数据处理的骨干,那么将会显著提升它们的响应时间。Tez构建在YARN之上,后者是Hadoop所使用的新资源管理框架。
Storm
Storm为分布式实时计算提供了一组通用原语,可被用于“流处理”之中,实时处理消息并更新数据库。这是管理队列及工作者集群的另一种方式。 Storm也可被用于“连续计算”(continuous computation),对数据流做连续查询,在计算时就将结果以流的形式输出给用户。它还可被用于“分布式RPC”,以并行的方式运行昂贵的运算。
Storm可以方便地在一个计算机集群中编写与扩展复杂的实时计算,Storm用于实时处理,就好比 Hadoop 用于批处理。Storm保证每个消息都会得到处理,而且它很快——在一个小集群中,每秒可以处理数以百万计的消息。更棒的是你可以使用任意编程语言来做开发。
3.官网学习Hadoop的安装与使用,用文档的方式列出步骤与注意事项。
一.hadoop安装及注意事项
1.安装hadoop的环境,必须在你的系统中有java的环境。
2.必须安装ssh,有的系统默认就安装,如果没有安装需要手动安装。
可以用yum install -y ssh 或者 rpm -ivh ssh的rpm包进行安装
二.安装并配置java环境
hadoop需要在java的环境中运行,需要安装JDK。
1.在官网上下载jdk,网址:http://www.oracle.com/technetwork/java/javase/downloads/index-jsp-138363.html
a.进入选择相应的rpm包或者tar包,进行安装。我这里是下载的rpm包,因为这样比较方便。用rpm包不需要进行环境变量的配置就可以使用了。
# rpm -ivh /usr/java/jdk1.8.0_60.rpm
b.检查java环境是否安装成功,敲入如下命令:
# java -version 显示相应的版本号
# javac javac相应的信息
# java java相应的信息
如以上打印出来了,就表示成功。
三.下载并安装hadoop
1.进入hadoop的官网进行下载相应hadoop的版本。地址为:http://hadoop.apache.org/releases.html
a.下载相应的tar包
b.进行tar解包
# tar -ivh /usr/local/hadoop/hadoop-2.7.1.tar.gz
c.修改相应的配置文件信息,制定相应的java_home
#vi /usr/local/hadoop/hadoop-2.7.1/ etc/hadoop/hadoop-env.sh
# set to the root of your Java installation
export JAVA_HOME=/usr/java/latest #显示当前jdk安装的目录 一般rpm是安装在 usr 目录下
d.配置hadoop的环境变量(使hadoop的命令加到path中,就可以使用hadoop的相关命令)
1.编辑/etc/profile文件,在文件的后面加上如下代码:
HADOOP_HOME=/usr/local/hadoop/hadoop-2.7.1
PATH=$HADOOP_HOME\bin:$PATH
export HADOOP_HOME PATH
2.使修改的文件生效
source /etc/profile
这样就可以进入hadoop的安装目录去进行相关的命令操作了!
三.执行相关的命令
1.运行一个MapReduce Job在当地:
进入hadoop的安装目录:$ cd /usr/local/hadoop/hadoop-2.7.1/
一:格式化文件系统 $ bin/hdfs namenode -format
二:开始一个NameNode后台进程 和 DataNode 后台进程。
$ ./sbin/start-dfs.sh
hadoop的后台进程的的日志文件输出到安装目录文件下的logs文件中。
三:进入网站可以进行查看相应的NameNode
NameNode - http://localhost:50070/
四:执行MapReduce Job,必须创建HDFS文件夹
$ bin/hdfs dfs -mkdir /usr
$ bin/hdfs dfs -mkdir /usr/<username>
五:复制输入文件到分布式文件系统
$ bin/hdfs dfs -put etc/hadoop input
六:运行提供的相应的例子
$ bin/hadoop jar share/hadoop/mapreduce/hadoop-maegrop‘./bj-getoutpreduce-examples-2.7.1.jar grep input output ‘dfs[a-z.]+‘
七:检查输出的文件:从分布式文件系统中复制输出文件到本地,并测试。
$ bin/hdfs dfs -get output output
$ cat output/*
或者查看输出文件在分布式文件系统中
$ bin/hdfs dfs -cat output/*
八:停止后台进程
$ sbin/stop-dfs.sh
四.Hadoop的相关命令
所有的Hadoop命令通过bin/ hadoop脚本调用,Hadoop脚本运行不带任何参数打印描述为所有的命令。
1.Usage: hadoop [--config confdir] [--loglevel loglevel] [COMMAND] [GENERIC_OPTIONS] [COMMAND_OPTIONS],这些选项是可选的。
a.--config confdir:覆盖默认的配置目录 . 默认是 ${HADOOP_HOME}/conf
b.--loglevel loglevel:覆盖日志等级。日志等级有:FATAL, ERROR, WARN, INFO, DEBUG, 和 TRACE,默认为INFO等级。
c.GENERIC_OPTIONS :多命令支持的共同选项.
d.COMMAND_OPTIONS:各种命令的选项是在文档描述了Hadoop的共同子项目,HDFS和YARN 在其他的文档中说明。
2.常用操作
a.可以用多个操作命令结合使用,来配置相应的hadoop
1.-archives <comma separated list of archives>:指定用逗号分隔文档,仅适用于job。
2.-conf <configuration file>:指定一个应用的配置文件。
3.-D <property>=<value>:获取属性文件中的值
4.-files <comma separated list of files>:指定以逗号分隔的文件被复制map reduce集群,仅适用于job。
5.-jt <local> or <resourcemanager:port>:指定一个resourcemanager。仅适用于job。
6.-libjars <comma seperated list of jars>:指定以逗号分隔的jar文件,包含在classpath中,仅适用于job。
五.Hadoop的常用命令
所有的hadoop命令是通过hadoop shell 命令执行,包含User Commands和Admininistration Commands。
1.User Commands:在hadoop集群的情况下要慎用。
a.archive:创建一个hadoop archive,
b.checknative: Usage: hadoop checknative [-a] [-h]
-a : 选择全部可用的包
-h:打印帮助信息
c.classpath:Usage: hadoop classpath [--glob |--jar <path> |-h |--help]
--glob:通配符
--jar <path>:write classpath as manifest in jar named path
-h 、--help:打印帮助信息
d.credential:Usage: hadoop credential <subcommand> [options]
1.create alias [-provider provider-path] :
Prompts the user for a credential to be stored as the given alias. The hadoop.security.credential.provider.path within the core-site.xml file will be used unless a -provider is indicated.
2.delete alias [-provider provider-path] [-f]
Deletes the credential with the provided alias. The hadoop.security.credential.provider.path within the core-site.xml file will be used unless a -provider is indicated. The command asks for confirmation unless -f is specified
3.list [-provider provider-path]
Lists all of the credential aliases The hadoop.security.credential.provider.path within the core-site.xml file will be used unless a -provider is indicated.
e.CLASSNAME:Usage: hadoop CLASSNAME
运行一个类名为CLASSNAME的类
f.version:Usage: hadoop version
打印hadoop的版本信息
g.trace:查看和修改Hadoop tracing 设置。可以看相应的官方文档。
h.key:管理keys。
i.jar:Usage: hadoop jar <jar> [mainClass] args...
运行一个jar文件。
适用 yarn jar去运行 YARN 应用程序。
J.fs:可以查看相应的官方文档。
k.distcp:复制文件或者目录,更多查看相应的官方文档。
2.Administration Commands:在hadoop集群的情况下要慎用
后台进程日志:
a.daemonlog:Usage:
hadoop daemonlog -getlevel <host:httpport> <classname>
hadoop daemonlog -setlevel <host:httpport> <classname> <level>
1.-getlevel host:httpport classname:
Prints the log level of the log identified by a qualified classname, in the daemon running at host:httpport. This command internally connects to http://<host:httpport>/logLevel?log=<classname>
2.-setlevel host:httpport classname level
Sets the log level of the log identified by a qualified classname, in the daemon running at host:httpport. This command internally connects to http://<host:httpport>/logLevel?log=<classname>&level=<level>
在后台进程取得或者设置日志等级为相应的类。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号