


一、简单做一个分类
1、字符组
字符组 : [字符组] 在同一个位置可能出现的各种字符组成了一个字符组,在正则表达式中用[]表示 字符分为很多类,比如数字、字母、标点等等。 假如你现在要求一个位置"只能出现一个数字",那么这个位置上的字符只能是0、1、2...9这10个数之一。
[0-9]:匹配0到9中的数字 [a-z]、[A-Z]:匹配a到z中的字母
2、字符
|
元字符
|
匹配内容
|
|
.
|
匹配除换行符以外的任意字符
|
|
\w
|
匹配字母或数字或下划线
|
|
\s
|
匹配任意的空白符
|
|
\d
|
匹配数字
|
|
\n
|
匹配一个换行符
|
|
\t
|
匹配一个制表符
|
|
\b
|
匹配一个单词的结尾
|
|
^
|
匹配字符串的开始
|
|
$
|
匹配字符串的结尾
|
|
\W
|
匹配非字母或数字或下划线
|
|
\D
|
匹配非数字
|
|
\S
|
匹配非空白符
|
|
a|b
|
匹配字符a或字符b
|
|
()
|
匹配括号内的表达式,也表示一个组
|
|
[...]
|
匹配字符组中的字符
|
|
[^...]
|
匹配除了字符组中字符的所有字符
|
3、量词
|
量词
|
用法说明
|
|
*
|
重复零次或更多次
|
|
+
|
重复一次或更多次
|
|
?
|
重复零次或一次
|
|
{n}
|
重复n次
|
|
{n,}
|
重复n次或更多次
|
|
{n,m}
|
重复n到m次
|
4、有名分组和无名分组
无名分组使用括号 ( ) 包裹正则表达式的一部分,用于将匹配的内容分组。这些分组会自动编号,从 1 开始。通过这些编号可以引用和操作分组的内容。例如,可以使用 \1、\2 等来引用第一个、第二个无名分组的内容。
有名分组使用 (?P<name> ) 的形式,其中 name 是分组的名称。有名分组的好处是可以使用名称来引用和操作分组的内容,而不需要依赖于编号。可以通过 match.group('name') 的方式来引用有名分组的内容。
import re ## 无名分组 match = re.search(r"(Hello), (World)", "Hello, World!") if match: print(match.group(1)) # 输出第一个无名分组的内容,即 "Hello" print(match.group(2)) # 输出第二个无名分组的内容,即 "World" # 使用有名分组匹配 "Hello" 和 "World" match = re.search(r"(?P<greeting>Hello), (?P<target>World)", "Hello, World!") if match: print(match.group('greeting')) # 输出名为 'greeting' 的有名分组的内容,即 "Hello" print(match.group('target')) # 输出名为 'target' 的有名分组的内容,即 "World"
5、转义
在正则表达式中,有很多有特殊意义的是元字符,比如\n和\s等,如果要在正则中匹配正常的"\n"而不是"换行符"就需要对"\"进行转义,变成'\\'。
在python中,无论是正则表达式,还是待匹配的内容,都是以字符串的形式出现的,在字符串中\也有特殊的含义,本身还需要转义。所以如果匹配一次"\n",字符串中要写成'\\n',那么正则里就要写成"\\\\n",这样就太麻烦了。这个时候我们就用到了r'\n'这个概念,此时的正则是r'\\n'就可以了。

二、

2、几个常用的非贪婪匹配Pattern
*? 重复任意次,但尽可能少重复 +? 重复1次或更多次,但尽可能少重复 ?? 重复0次或1次,但尽可能少重复 {n,m}? 重复n到m次,但尽可能少重复 {n,}? 重复n次以上,但尽可能少重复
3、.*?的用法

. 是任意字符 * 是取 0 至 无限长度 ? 是非贪婪模式。 何在一起就是 取尽量少的任意字符,一般不会这么单独写,他大多用在: .*?x 就是取前面任意长度的字符,直到一个x出现
4、(.*?) 的应用,findall的优先级查询:
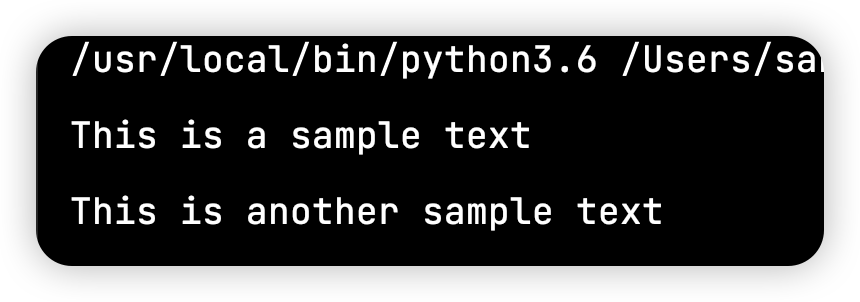
import re text = "This is a sample text. This is another sample text." matches = re.findall("This(.*?)text", text) for match in matches: print(match.strip())

从结果中可以看出,This text没有被打印出来。因为使用了(),优先展示()中的内容
如果想要()外的内容液展示出来,则需要使用非捕获分组(?:.*?),只在.findall()中有效
import re
text = "This is a sample text. This is another sample text."
matches = re.findall("This(?:.*?)text", text)
for match in matches:
print(match.strip())
import re
ret = re.findall('a', 'eva egon yuan') # 返回所有满足匹配条件的结果,放在列表里
print(ret) #结果 : ['a', 'a']
ret = re.search('eg', 'eva egon yuaneg') print(ret) #结果 : 'a' <_sre.SRE_Match object; span=(4, 6), match='eg'>
.group方法
通过调用 group() 方法,我们可以获取匹配到的具体文本。如果字符串没有匹配,则返回None
ret = re.search('eg', 'eva egon yuaneg').group() print(ret) #结果 : 'eg'
3、re.match # 在字符串开头进行匹配
ret = re.match('akl', 'aklaqabc').group() # 同search,不过尽在字符串开始处进行匹配 print(ret) # 结果 akl
4、其他
ret = re.split('[ab]', 'abcd') # 先按'a'分割得到''和'bcd',在对''和'bcd'分别按'b'分割 print(ret) # ['', '', 'cd'] ret = re.sub('\d', 'H', 'eva3egon4yuan4', 1)#将数字替换成'H',参数1表示只替换1个 print(ret) #evaHegon4yuan4 ##substitute 替补 ret = re.subn('\d', 'H', 'eva3egon4yuan4')#将数字替换成'H',返回元组(替换的结果,替换了多少次) print(ret) obj = re.compile('\d{3}') #将正则表达式编译成为一个 正则表达式对象,规则要匹配的是3个数字 ret = obj.search('abc123eeee') #正则表达式对象调用search,参数为待匹配的字符串 print(ret.group()) #结果 : 123 import re ret = re.finditer('\d', 'ds3sy4784a') #finditer返回一个存放匹配结果的迭代器 print(ret) # <callable_iterator object at 0x10195f940> print(next(ret).group()) #查看第一个结果 print(next(ret).group()) #查看第二个结果 print([i.group() for i in ret]) #查看剩余的左右结果
5、split的优先级查询
ret=re.split("\d+","eva3egon4yuan") print(ret) #结果 : ['eva', 'egon', 'yuan'] ret=re.split("(\d+)","eva3egon4yuan") print(ret) #结果 : ['eva', '3', 'egon', '4', 'yuan'] #在匹配部分加上()之后所切出的结果是不同的, #没有()的没有保留所匹配的项,但是有()的却能够保留了匹配的项, #这个在某些需要保留匹配部分的使用过程是非常重要的。
