
Python3的八大数据类型
python3数据类型主要分为八大类:
- Numbers(数字)(整型int、浮点型float)
- String(字符串)
- List(列表)
- Tuple(元组)
- Dictionary(字典)
- Set(集合)
- bool(布尔值)与None
可变类型与不可变类型
可变数据类型:值发生改变时,内存地址不变,即id不变,证明在改变原值。如:列表,字典
不可变类型:值发生改变时,内存地址也发生改变,即id也变,证明是没有在改变原值,是产生了新的值。如:整型、字符串
1、数字类型:
python3的数字类型包括:
- int,initeger(长整型)
- float(浮点型)
- complex(复数)
- bool(布尔型)
Python3 中,bool 是 int 的子类,True 和 False 可以和数字相加, True==1、False==0 会返回 True,但可以通过 is 来判断类型。
>>> issubclass(bool, int)
True
>>> True==1
True
>>> False==0
True
>>> True+1
2
>>> False+1
1
>>> 1 is True
False
>>> 0 is False
False
可用type和isinstance(x,y)进行判断
>>> a=12 >>> type(a) <class 'int'> >>> isinstance(a,int) True
关于输出两位小数的补充
方式1: 使用字符串的 format 方法
price = 10.56789
formatted_price = "{:.2f}".format(price)
print(formatted_price) # 输出:10.57
方式2: 使用 f-string 格式化字符串(Python 3.6+)
price = 10.56789
formatted_price = f"{price:.2f}"
print(formatted_price) # 输出:10.57
方式3: 使用 % 运算符
price = 10.56789
formatted_price = "%.2f" % price
print(formatted_price) # 输出:10.57
2、字符串 string
字符串用单引号 ' 或双引号 " 括起来,同时使用反斜杠 \ 转义特殊字符。加号 + 是字符串的连接符, 星号 * 表示复制当前字符串,与之结合的数字为复制的次数,同时支持索引截取
str = 'Runoob'
print (str) # 输出字符串
print (str[0:-1]) # 输出第一个到倒数第二个的所有字符
print (str[0]) # 输出字符串第一个字符
print (str[2:]) # 输出从第三个开始的后的所有字符
print (str * 2) # 输出字符串两次,也可以写成 print (2 * str)
print (str + "TEST") # 连接字符串
部分内置方法:
.strip()方法可以用于去除字符串两端的空白字符(包括空格、制表符、换行符等)。它会返回去除空白字符的新字符串。
.join()方法,将可迭代的对象,迭代后使用指定的字符进行拼接
hobby = ['hejiu', 'chouyan', 'majiang'] a = ', '.join(hobby) print(a, type(a)) # hejiu, chouyan, majiang <class 'str'>
str的内置方法中.is开头的都是判断,返回布尔值。如:
- str.isalnum() 所有字符都是数字或者字母
- str.isalpha() 所有字符都是字母
- str.isdigit() 所有字符都是数字
- str.isspace() 所有字符都是空白字符、t、n、r
3、列表 list
Python 中使用最频繁的数据类型。
列表可以完成大多数集合类的数据结构实现。列表中元素的类型可以不相同,它支持数字,字符串甚至可以包含列表(所谓嵌套)。
列表是写在方括号 [ ] 之间、用逗号分隔开的元素列表。
和字符串一样,列表同样可以被索引和截取,列表被截取后返回一个包含所需元素的新列表。
列表截取的语法格式如下:
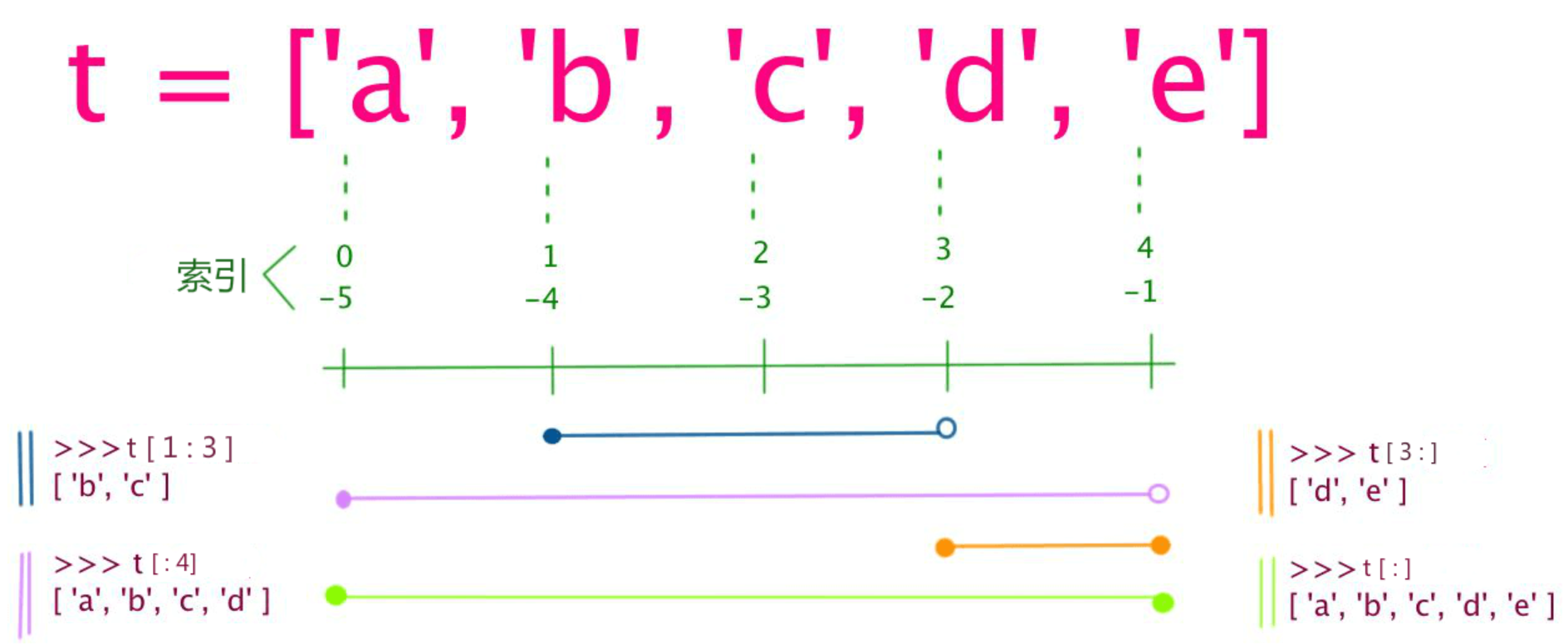
注意:带-的下标,list[:-3]表示从左边-3索引位置开始到结束,list也支持:+ 列表连接运算符, * 重复操作。
list = [ 'abcd', 786 , 2.23, 'runoob', 70.2 ]
tinylist = [123, 'runoob']
print (list[:-3]) # 从第二个开始输出到第三个元素
print (list[2:]) # 输出从第三个元素开始的所有元素
print (tinylist * 2) # 输出两次列表
print (list + tinylist) # 连接列表
注意:
- List写在方括号之间,元素用逗号隔开。
- 和字符串一样,list可以被索引和切片。
- List可以使用+操作符进行拼接。
- List中的元素是可以改变的(支持很多方法来增删改查)。
list的内置方法
extend
将一个可迭代对象一次性扩充到一个列表中
list.extend(iterable)
4、元组 tuple
元组(tuple)与列表类似,可以理解为:不可修改元素的list。元组写在小括号 () 里,元素之间用逗号隔开。元组中的元素类型也可以不相同:tuple = ( 'abcd', 786 , 2.23, 'runoob', 70.2 )
tinytuple = (123, 'runoob')
print (tuple[2:]) # 输出从第三个元素开始的所有元素
print (tinytuple * 2) # 输出两次元组
print (tuple + tinytuple) # 连接元组
虽然tuple的元素不可改变,但它可以包含可变的对象,比如list列表。
构造包含 0 个或 1 个元素的元组比较特殊,所以有一些额外的语法规则:
tup1 = () # 空元组
tup2 = (20,) # 一个元素,需要在元素后添加逗号
注意:
- 1、与字符串一样,元组的元素不能修改。
- 2、元组也可以被索引和切片,方法一样。
- 3、注意构造包含 0 或 1 个元素的元组的特殊语法规则。
- 4、元组也可以使用+操作符进行拼接。
5、字典 dictionary
列表是有序的对象集合,字典是无序的对象集合。两者之间的区别在于:字典当中的元素是通过键来存取的,而不是通过偏移存取。
字典是一种映射类型,字典用 { } 标识,它是一个无序的 键(key) : 值(value) 的集合。
键(key)必须使用不可变类型。在同一个字典中,键(key)必须是唯一的。
dict = {}
dict['one'] = "1111"
dict[2] = "2222"
tinydict = {'name': 'runoob','code':1, 'site': 'www.runoob.com'}
print (dict['one']) # 输出键为 'one' 的值
print (dict[2]) # 输出键为 2 的值
print (tinydict) # 输出完整的字典
print (tinydict.keys()) # 输出所有键
print (tinydict.values()) # 输出所有值
注意:
- 字典是一种映射类型,它的元素是键值对。
- 字典的关键字必须为不可变类型,且不能重复。
- 创建空字典使用 { }。
字典解包补充{**dict1}
Python中,{**dict1} 是一种字典解包的用法,它允许将一个字典 dict1 解包成一个新的字典。
dict1 = {'a': 1, 'b': 2}
dict2 = {'c': 3, 'd': 4}
merged_dict = {**dict1, **dict2}
print(merged_dict) #{'a': 1, 'b': 2, 'c': 3, 'd': 4}
字典的内置方法
.get() (# ps:字典取值建议使用get方法)
>>> dic= {'k1':'jason','k2':'Tony','k3':'JY'}
>>> dic.get('k1')
'jason' # key存在,则获取key对应的value值
>>> res=dic.get('xxx') # key不存在,不会报错而是默认返回None
>>> print(res)
None
>>> res=dic.get('xxx',666) # key不存在时,可以设置默认返回的值
>>> print(res)
666
.pop()
>>> dic= {'k1':'jason','k2':'Tony','k3':'JY'}
>>> v = dic.pop('k2') # 删除指定的key对应的键值对,并返回值
>>> dic
{'k1': 'jason', 'kk2': 'JY'}
>>> v
'Tony'
.popitem()
>>> dic= {'k1':'jason','k2':'Tony','k3':'JY'}
>>> item = dic.popitem() # 随机删除一组键值对,并将删除的键值放到元组内返回
>>> dic
{'k3': 'JY', 'k2': 'Tony'}
>>> item
('k1', 'jason')
.update()
>>> dic= {'k1':'jason','k2':'Tony','k3':'JY'}
>>> dic.update({'k1':'JN','k4':'xxx'})
>>> dic
{'k1': 'JN', 'k3': 'JY', 'k2': 'Tony', 'k4': 'xxx'}
支持只更新其中一部分的 v 值
my_dict = {'key1': 'value1', 'key2': 'value2', 'key3': 'value3'}
# 更新字典中的 'key2' 键的值
my_dict.update({'key2': 'new_value'})
# 输出更新后的字典
print(my_dict)
# 输出: {'key1': 'value1', 'key2': 'new_value', 'key3': 'value3'}
# 更新字典中的 'key4' 键的值
my_dict.update({'key4': 'new_value'})
# 输出更新后的字典
print(my_dict)
# 输出: {'key1': 'value1', 'key2': 'new_value', 'key3': 'value3', 'key4': 'new_value'}
.fromkeys()
>>> dic = dict.fromkeys(['k1','k2','k3'],[])
>>> dic
{'k1': [], 'k2': [], 'k3': []}
.setdefault()
# key不存在则新增键值对,并将新增的value返回
>>> dic={'k1':111,'k2':222}
>>> res=dic.setdefault('k3',333)
>>> res
333
>>> dic # 字典中新增了键值对
{'k1': 111, 'k3': 333, 'k2': 222}
# key存在则不做任何修改,并返回已存在key对应的value值
>>> dic={'k1':111,'k2':222}
>>> res=dic.setdefault('k1',666)
>>> res
111
>>> dic # 字典不变
{'k1': 111, 'k2': 222}
关于字典的补充
字典的key值必须可hash,即字典的key值必须是不可变数据类型
redis hash 类型无序,跟放的先后顺序无关的
python 的字典是 有序的 字典+列表
6、集合 set
集合(set)是一个无序的不重复元素序列。可以使用大括号 { } 或者 set() 函数创建集合。构成集合的事物或对象称作元素或是成员
基本功能是进行成员关系测试和删除重复元素。
注意:创建一个空集合必须用 set() 而不是 { },因为 { } 是用来创建一个空字典。
创建格式
parame = {value01,value02,...}
或者
set(value)
集合(set)是由一个或数个形态各异的大小整体组成的,构成集合的事物或对象称作元素或是成员。
基本功能是进行成员关系测试和删除重复元素。
可以使用大括号 { } 或者 set() 函数创建集合,注意:创建一个空集合必须用 set() 而不是 { },因为 { } 是用来创建一个空字典。
注:所有的数据类型创建空时候,都可以用单词名称+(),如 set(),list(), dict()
集合的内置方法
# 1.合集/并集(|):求两个用户所有的好友(重复好友只留一个)
>>> friends1 | friends2
{'kevin', 'ricky', 'zero', 'ly', 'Jy', 'qq'}
# 2.交集(&):求两个用户的共同好友
>>> friends1 & friends2
{'ly', 'qq'}
# 3.差集(-):
>>> friends1 - friends2 # 求用户1独有的好友
{'kevin', 'zero'}
>>> friends2 - friends1 # 求用户2独有的好友
{'ricky', 'Jy'}
# 4.对称差集(^) # 求两个用户独有的好友们(即去掉共有的好友)
>>> friends1 ^ friends2
{'kevin', 'zero', 'ricky', 'Jy'}
# 5.值是否相等(==)
>>> friends1 == friends2
False
# 6.父集:一个集合是否包含另外一个集合
# 6.1 包含则返回True
>>> {1,2,3} > {1,2}
True
>>> {1,2,3} >= {1,2}
True
# 6.2 不存在包含关系,则返回False
>>> {1,2,3} > {1,3,4,5}
False
>>> {1,2,3} >= {1,3,4,5}
False
# 7.子集
>>> {1,2} < {1,2,3}
True
>>> {1,2} <= {1,2,3}
True
集合去重会打乱顺序,写一个代码实现既去重又保留之前的顺序
# 针对不可变类型,并且保证顺序则需要我们自己写代码实现,例如 l=[ {'name':'lili','age':18,'sex':'male'}, {'name':'jack','age':73,'sex':'male'}, {'name':'tom','age':20,'sex':'female'}, {'name':'lili','age':18,'sex':'male'}, {'name':'lili','age':18,'sex':'male'}, ] new_l=[] for dic in l: if dic not in new_l: new_l.append(dic) print(new_l) # 结果:既去除了重复,又保证了顺序,而且是针对不可变类型的去重 [ {'age': 18, 'sex': 'male', 'name': 'lili'}, {'age': 73, 'sex': 'male', 'name': 'jack'}, {'age': 20, 'sex': 'female', 'name': 'tom'} ]

 浙公网安备 33010602011771号
浙公网安备 33010602011771号