
匈牙利算法
值得一看(就看上面两篇吧,这篇是仿照上面两篇写的,连图都不是自己的)
这是本蒟蒻的第一篇blog,我知道很差,请不要吐槽啦
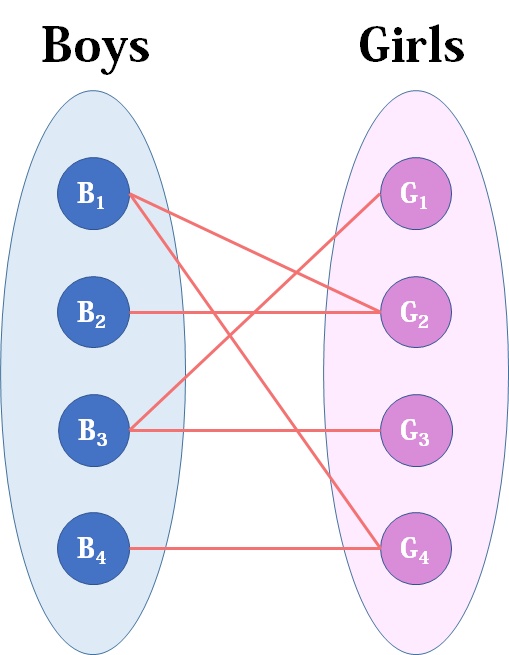
(图片来源于推荐博客2)
图中每一条连线代表这两个boy girl有好感,只有有连线的boy girl才可能匹配
每个boy只能匹配一个girl,每个girl也只能匹配一个boy
若每个boy都能有自己的girl,称为完美匹配
让boy与girl的匹配对数最大的,称为最大匹配
现在,我们的任务是要求这些有连线的boy girl的最大匹配数,这就是匈牙利算法的用处
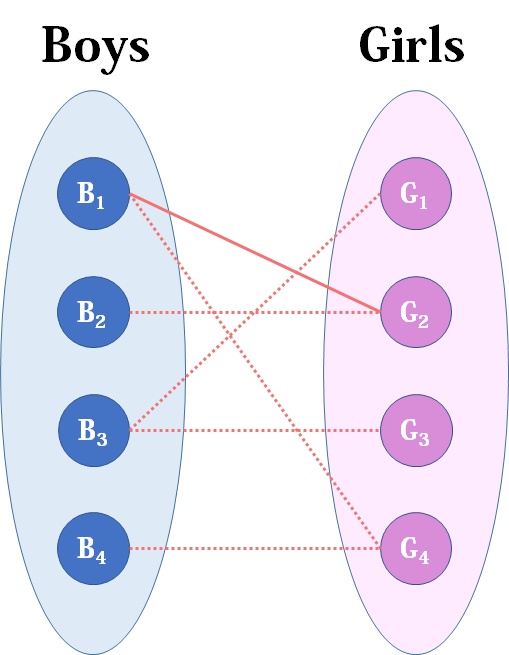
(图片来源于推荐博客2)
就如现在,从B1看起,发现他与G2有暧昧,就将他俩暂时牵红绳。
但接着看B2,发现他与G2也有暧昧,于是B1与G2分手,B2 G2在一起,再回到B1,还好他与G4也有暧昧,于是将他俩搞在一起(这其实是一个递归的过程)、
我们可以发现B2->G2->B1->G5是路,然后可以发现(B2,G2)(B1,G5),所以路要长对数就越多,所以其实我们就是在寻找一条增广路。
(摘自以上blog)
1. 匈牙利算法寻找最大匹配,就是通过不断寻找原有匹配M的增广路径,因为找到一条M匹配的增广路径,就意味着一个更大的匹配M' , 其恰好比M 多一条边。
2. 对于图来说,最大匹配不是唯一的,但是最大匹配的大小是唯一的。
代码:
vis[]代表本次匹配时的girl是否有新的boyfriend,每次一个新的匹配前都要清零,不用担心vis[a[i].to]=1,却没有return会影响后面的dfs,若vis[a[i].to]=1却没return,说明这个点不能回退
c[]表示此girl所归属的boy

推荐题:洛谷P1129

