SfMLearner论文笔记——Unsupervised Learning of Depth and Ego-Motion from Video
1. Abstract
- 提出了一种无监督单目深度估计和相机运动估计的框架
- 利用视觉合成作为监督信息,使用端到端的方式学习
- 网络分为两部分(严格意义上是三个)
- 单目深度估计
- 多视图姿态估计
- 解释性网络(论文后面提到训练了第三个网络)
2. Introduction
- 计算机几何视觉难以重建真实的场景模型
- 由于非刚性、遮挡、纹理缺失等情况的存在
- 人类在很短的时刻可以推断自我运动以及三维场景的结构,为什么?
- 一个假设就是人类在移动中通过观察大量的场景,已经进化出一个对真实世界丰富的、具有结构层次的理解力。通过这些上百万次的观察,人们已经认识到了世界的规律性—路是平的,大楼是直立的等,于是在进入一个新的场景,即使通过一个单目图像。我们也可以运用这些先验知识来识别场景。
- 很自然地,我们就想到通过训练一个观察图像序列的网络来模拟这种能力,这个网络的目的在于通过预测相机运动和场景结构来解释观察到的内容。
- 端到端的方式。直接从输入的像素来估计相机运动(6个自由度的变化矩阵)和场景结构(每个像素的深度)
- 视觉合成作为度量。
- 无监督的方法。直接使用图像序列进行训练,不需要人工标记甚至相机运动信息。
- 本文方法建立一个观点的基础上:只有当场景的中间预测与相机姿态与真实场景一致的时候,几何视觉合成系统才会表现的很好。
- 但是对于某些场景(例如纹理缺失),几何和姿态估计的不好会导致视觉合成的错误,由此相同模型在面对另一类场景(布局和场景结构更多样)时,会非常失败。
- 本文的目标是构建整个视觉合成的流程,作为CNN的推理过程,通过学习深度和相机姿态的中间估计,以达到网络解释内容与真实世界一致的效果。
3. Related Work
3.1 SFM
3.2 Warping-based view synthesis
3.3 Learning single-view 3D from registered 2D views
3.4 Unsupervised/Self-supervised learning from video
4. 方法
4.1 视觉合成作为监督
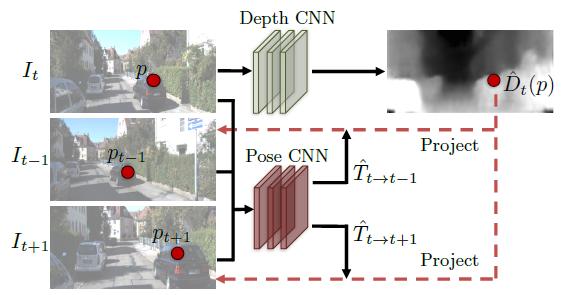
注:
可见性(visibility):指两个不同的目标视图在生成新视图的过程中,warp到新视角的同一点。当新视角的一个3D点被另一个3D点遮挡的时候,就会出现这种情况。
4.2 基于图像渲染的可微分深度

4.4 克服梯度局限性
- 梯度来源于\(I(p_{t})\)与相邻四个点\(I(p_s)\)的像素差
- 如果利用ground-truth深度和姿态得到的投影像素\(p_s\)(这是一个精确值)位于低纹理区域,或当前估计不够准确时,网络会一直训练。
- 两种典型的处理这种问题的方法
- 使用带有bottleneck层的encoder-decoder网络架构,从而约束深度网络的输出平滑,并且促使有意义的梯度区域传给周围像素;
- 明确多尺度和平滑损失:允许梯度能从更大的区域得到;
- 本文使用了第二种方法。
- 为了平滑损失,在预测深度图时,最小化二阶梯度的\(L_1\)范式
- 最终的目标函数变为:
\[\mathcal{L}_{final}=\sum_{l} \mathcal{L}_{vs}^{l}+\lambda_{s} \mathcal{L}_{smooth}^{l} + \lambda_{e} \sum_{s} \mathcal{L}_{reg}(\hat{E}_{s}^{l}), \tag{9}
\]
* \(l\)表示不同的图像尺度,\(s\)表示源图像,\(\lambda_{s}\)和\(\lambda_{e}\)分别是深度平滑loss和解释性网络正则化的权值。
4.5 网络架构
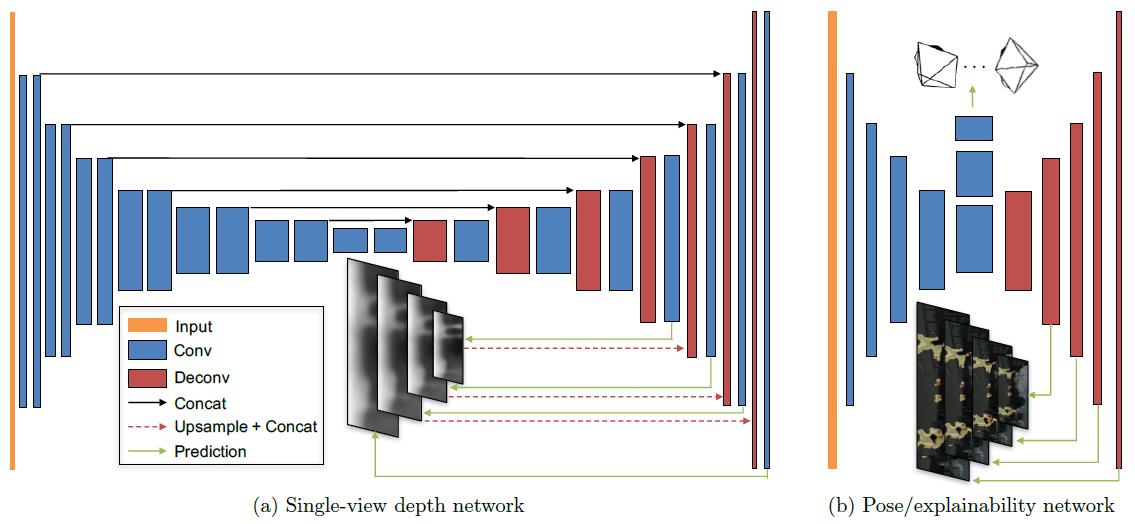
5. 实验
主要使用了KITTI作衡量基准,同时使用了Make3D数据集以评估模型的泛化能力。
训练:
- Tensorflow架构(github也有PyTorch实现)
- \(\lambda_{s}\)设为\(0.5 / l\)(\(l\)是下采样因子),同时\(\lambda_{e}=0.2\)
- 每层都使用Batch Normalization和ReLU
- 优化器使用Adam,\(\beta_{1}=0.9\),\(\beta_2=0.999\)
- 学习率:0.002,mini-batch的size为4,迭代次数150K
- 单目相机拍摄的图像序列,训练时将图片设为128$\times$416
5.1 单目深度估计
- 使用KITTI数据集训练
- 排除所有帧中平均光流小于1个像素的静态场景作训练
- 固定图像序列长度为3帧,将中间帧作为target view,中间帧的\(\pm 1\)帧作为source view
- 一共44540个序列,40109用于训练,4431用于测试。
6. 讨论
考虑了三个未来工作:
- 本文目前的框架没有明确估计动态场景和遮挡(尽管explainability已经将其考虑在内),这两者都是三维场景理解的关键因素。通过motion segmentation建模或许是解决方法之一
- 目前的框架假设内参已知,这限制了对网上视频的应用,未来考虑解决这一问题
- 深度图是三维场景的一种简单表示方法,考虑应用更好的表示,例如体素。
另一个有趣的方向是探究由本文学习得到的系统更详细的细节,尤其是姿态估计时使用某种图像对应,深度估计时识别场景和对象的共同特征,即探究语义分割、对象检测等对本文框架的影响。
参考
[1] Christoph Fehn. Depth-image-based rendering (DIBR), compression, and transmission for a new approach on 3D-TV
[2] https://blog.csdn.net/wangshuailpp/article/details/80098059

 浙公网安备 33010602011771号
浙公网安备 33010602011771号