
推荐系统之CTR预估-FNN模型解析
原论文:Deep learning over multi-field categorical data
地址:https://arxiv.org/pdf/1601.02376.pdf
一、问题由来
基于传统机器学习模型(如LR、FM等)的CTR预测方案又被称为基于浅层模型的方案,其优点是模型简单,预测性能较好,可解释性强;缺点主要在于很难自动提取高阶组合特征携带的信息,目前一般通过特征工程来手动的提取高阶组合特征。而随着深度学习在计算机视觉、语音识别、自然语言处理等领域取得巨大成功,其在探索特征间高阶隐含信息的能力也被应用到了CTR预测中。较早有影响力的基于深度学习模型的CTR预测方案是在2016年提出的基于因子分解机的神经网络(Factorization Machine supported Neural Network, FNN)模型,就是我们今天要分享的内容,一起来看下。
二、模型原理
FNN模型如下图所示:

对图中的一些变量进行一下解释:x是输入的特征,它是大规模离散稀疏的。它可以分成N个Field,每一个Field中,只有一个值为1,其余都为0(即one-hot)。Field i的则可以表示成 ,
为Field i的embedding矩阵。
为embedding后的向量。它由一次项
,二次项
组成,其中K是FM中二次项的向量的维度。而后面的
则为神经网络的全连接层的表示。
详细解释一下基于FM的预训练:嵌入后的向量 =
,其中
就是FM里面的一次性系数,而
就是二次项的系数,可以详细对照看FM的公式:
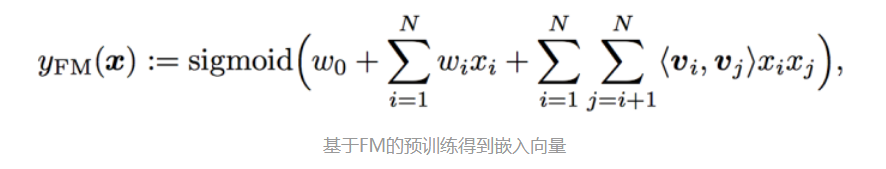
我们可以看出这个模型有着十分显著的特点:
1. 采用FM预训练得到的隐含层及其权重作为神经网络的第一层的初始值,之后再不断堆叠全连接层,最终输出预测的点击率。
2. 可以将FNN理解成一种特殊的embedding+MLP,其要求第一层嵌入后的各领域特征维度一致,并且嵌入权重的初始化是FM预训练好的。
3. 这不是一个端到端的训练过程,有贪心训练的思路。而且如果不考虑预训练过程,模型网络结构也没有考虑低阶特征组合。
为了方便理解,如下图所示,FNN = FM + MLP ,相当于用FM模型得到了每一维特征的嵌入向量,做了一次特征工程,得到特征送入分类器,不是端到端的思路,有贪心训练的思路。

三、FNN的优缺点
优点:每个特征的嵌入向量是预先采用FM模型训练的,因此在学习DNN模型时,训练开销降低,模型能够更快达到收敛。
缺点:
-
Embedding 的参数受 FM 的影响,不一定准确
-
预训练阶段增加了计算复杂度,训练效率低
-
FNN 只能学习到高阶的组合特征;模型中没有对低阶特征建模。
-

 浙公网安备 33010602011771号
浙公网安备 33010602011771号