Linux操作系统基
阅读目录:
第一节:操作系统的基础知识以及LInux系统的入门
第二节:文件管理和重定向
第三节:用户组权限的详细介绍
第四节:文件权限管理
第五节:文本处理
第六节:软件管理
内容:
第一节:操作系统的基础知识以及LInux系统的入门
1、什么是计算机操作系统
操作系统是一个用来协调、管理和控制计算机硬件和软件的资源的系统程序,它位于硬件和应用程序之间。
2、什么是系统内核
操作系统内核是一个管理和控制程序,负责管理计算机的所有的物理资源,其中包括:文件系统、内存管理、设备管理、进程管理、网络管理。
3、操作系统分类
服务器OS:RHEL、CentOS、Windows server
桌面OS:Windows、MAC OS 、Fedora
移动设备OS:Android,IOS,(YunOS?)
4、操作系统流派
目前常用的大多数操作系统都源于Unix,或者借鉴了最初的Unix,如:Windows,Mac OS x,Linux,历史原因都与Unix有一定的关系。
5、安装、配置Linux
由于测试方便,使用虚拟机来安装Linux做说明。一般使用VMware WorkStation或者virtualBox 这两种虚拟软件。我使用的是前者。
① 下载安装VMware,具体步骤可以问某度。
② 下载合适版本的Linux发行版镜像文件,我使用的是CentOS 6.9。第一次使用,建议安装everything版本
镜像文件常用的网站:
https://wiki.centos.org/Download
https://mirror.aliyun.com
https://mirror.sohu.com
https://mirror.163.com
③ 开始新建虚拟机,根据自己的笔记本硬件情况,选择合理的参数,注意:选择稍后安装镜像。网络三种模式:桥接模式,NAT模式,仅主机模式,根据自己的需求选择合适的模式。注意要区分三者的含义:(简短说一下)-----------参考:https://www.cnblogs.com/linjiaxin/p/6476480.html
——桥接模式:wmnet0作为虚拟交换机,虚拟机通过交换机链接外网,宿主机跟虚拟机在同一个网段
——NAT模式:即转换模式,宿主机网卡跟虚拟机NAT设备连在一起,NAT设备和DHCP服务器连在WMnet8虚拟交换机上。
——仅主机模式:Host-Only模式其实就是NAT模式去除了虚拟NAT设备,然后使用VMware Network Adapter VMnet1虚拟网卡连接VMnet1虚拟交换机来与虚拟机通信的,Host-Only模式将虚拟机与外网隔开,使得虚拟机成为一个独立的系统,只与主机相互通讯。
④ 安装过程中的各种选项的含义:
a) install or upgrade an existing system:安装或升级现有的系统
b) install system witn basic video driver:安装系统和基本的视频驱动程序
c) rescue installed system:救援安装系统
d) boot from local drive:从本地硬盘启动
⑤ 其他的步骤自己多摸索一下。
6、Unix认识
① 什么是Unix
Unix就是一个操作系统
② Unix的发展史
在Unix的发展路上,有很多故事,可以查看一些书籍了解。
7、不同风格的语言的简单介绍,后期在Python中会有详细说明
汇编语言,最接近底层的语言,但是无法移植。
C语言(Rust语言),系统级别的开发语言,移植性还是差,需要在某平台编译后,才能在相应的平台运行。
应用编程,Python的特点是 write once , run anywhere,代码简介,但是运行慢。基于VM虚拟机运行。
8、开发接口标准
ABI:Application Binary Interface 描述了应用程序和OS之间的底层的接口,允许编译好的代码在使用兼容ABI的提醒中无需改动就能运行
API:Application Programming interface 定义了源代码和库之间中接口,因此同样的源代码可以在支持这个api的任何系统中编译
9、硬件平台:
cpu平台主要有:X86,ARM,PowerPC(苹果),Power(IBM),UltraSparc(sun),Alpha(hp)
10、Linux并不是Unix
Linux是类Unix,是参考了Unix的风格而形成的另一种操作系统。而所谓的Linux是指kernel,平时所说的Linux操作系统是指发行版,是Linux内核+GNU提供的应用程序
11、常见的发行版
ReadHat、Debian、SUSE
ReadHat ---------> CentOS
Debain ---------> Ubuntu
SUSE ---------> openSUSE
作为码农,常用的系统有:ArchLinux --------->支持程序的滚动更。如果为了装X,可以使用Mac OS X。
Linux分支参考网站:http://futurist.se/gldt/
12、关于版本号
内核版本号:3.10.0-693.el7

注:1、版本号的第二位数字,可以确定Linux内核版本的类型
开发版本:第二位数字是奇数 3.9.1......
稳定版本:第二位数字是偶数 3.10.0......
2、发行版本号版本:与内核版本号不同 内核版本号:4.17.9
13、开源协议
开源 open source ,软件和源代码提供给所有人自由分发软件和源代码,能够修改和创建衍生作品
软件分类:
商业版,共享版,自由版
① 常见的开源协议
GPLv2、GPLv3、LGPL:通用公共许可copyleft------->GNU提供
Apache,BSD,MIT。。。
② 开源协议
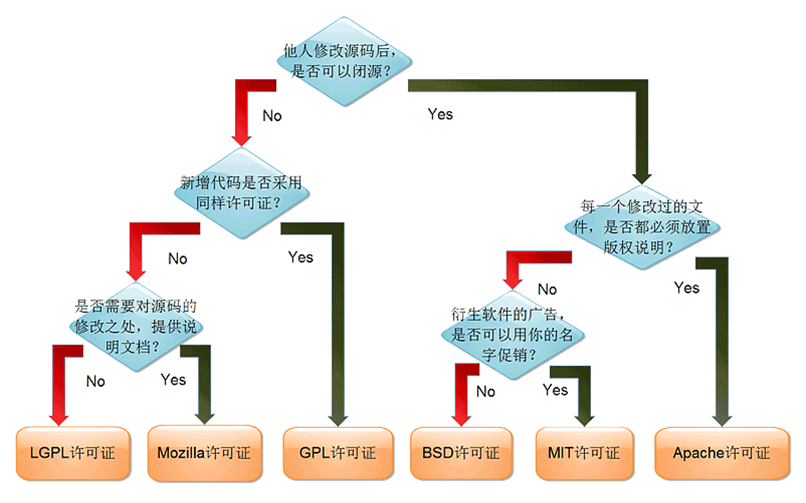
注:协议很重要,同样的应用程序在不同的发行版上可能使用情况不经相同。
14、Linux的哲学思想
① 一切皆文件,包括硬件
② 小型,单一用途的程序(功能尽量单一)--------> 目前是一个程序集合多个单一功能的程序完成复杂的功能
③ 链接程序,完成复杂的任务,需要用户窜起来
④ 避免令人困惑的用户界面
⑤ 配置数据存储在文件中-----为了通用
15、图形界面分类
GUI:graphical user interface 图形化界面接口
桌面系统的发行方式:
Gnome:C开发的
KDE:C++开发的
XFCE:用于嵌入式较多(轻量级桌面)
CLI:command line interfacce 命令行接口
sh > bsh
csh,bash,zsh
shell -----特质命令行shell
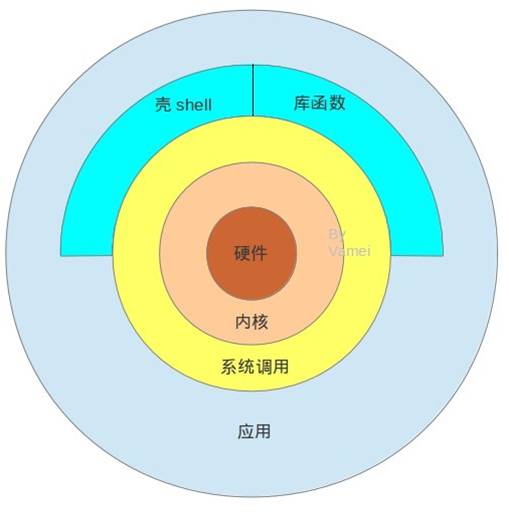
16、什么是shell
shell是LInux的用户界面,提供了一种用户可以和内核交互操作的一种接口,接受用户输入的命令并把它送入内核去执行。
也成为Linux的命令解释器
查看当前shell:echo $SHELL
显示当前系统的所有shell : cat /etc/shells
17、什么是程序
程序 = 指令 + 数据
程序 = 算法 + 数据结构
以算法为中心,数据结构服务于算法,这就是过程是编程
以数据为中心,算法服务于数据,这就是对象式编程
18、终端类型以及用户登录
物理终端 /dev/console
虚拟终端 /dev/tty# [1-6] Ctrl+ Alt +F[1-6]
伪终端 /dev/pts/# (ssh远程连接,图形界面开启的终端)
图形终端 /dev/tty7
串行终端 /dev/ttyS#
查看当前设备的终端设备命令:tty
19、命令分类、执行命令
命令分:内部命令、外部命令
内部命令:shell自带的命令
help 回车:查看所有的内部命令列表
enable -n cmd :禁用某个命令
enable -n:查看被 禁用的命令
enable cmd :启用某个命令
外部命令:文件系统路径下有对应的可执行文件
which cmd :查看某个命令的位置 或者 whereis
注:用type cmd 查看命令是否是内部命令
执行命令回车即可,如果同时执行多个命令,使用分号隔开,如:ls /etc;date
一个命令可以使用\ 分多行
取消和结束命令执行:Ctrl+c Ctrl+d
20、命令别名alias
alias cmd= ‘CMD’
unalias cmd:取消别名
别名的配置文件:
~/.bashrc : 仅对当前用户
/etc/bashrc :对所有用户有效
21、时间和日期
Linux的两种时钟:
系统时钟:由Linux内核通过CPU的工作频率进行的
硬件时钟:主板
相关命令:date,hwclock
hwclock :硬件时钟
hwclock -s :硬件时钟同步为系统时钟
-w :系统时钟同步为硬件时钟
date:系统时间
+%a : 周几的缩写
+%A : 周几的全写
+%b :几月的缩写 +%h
+%B :几月的全写
+%c :本地日期时间
+%C :2018的20
+%d :某月的几号 %e
+%D :日期 07/25/18
+%F : 日期 2018-07-25
+%g :2018的18
+%H :几点-24小时制 00-23
+%I :几点-12小时制 00-12
+%j :一年的第几天
+%k : 0-23
+%l : 0-12
+%m : 月
+%M :分钟
+%T : 08:42:11
+%u : 一周的第几天 Monday是第一天 1-7
+%w : 一周的第几天 SUNday是第一天 0-6
+%U :一年的第几周
+%y : 2018 的18
+%Y :年
设置时间:date [-u] [MMDDhhmm][[cc]YY][.SS]]
cal:日历
cal -y 显示当年全部日历
22、关机、重启
关机:halt。poweroff , init0(centos6)
重启:reboot ,init6
-f:强制
-p:切断电源
关机或重启:shutdown
-r:重启
-h:halt
-c:取消
now 立刻
+m:几分钟后
23、Linux用户分类
管理员 uid 0
普通用户:
系统用户: 1-499 1-999
登录用户: 500+ 1000+
注:root用户命令行提示是 #,普通用户命令行提示符是 $.
24、用户登录:
whoami,who,w


[root@localhost ~]$ w 7:26:39 up 1:10, 4 users, load average: 0.05, 0.05, 0.01 USER TTY FROM LOGIN@ IDLE JCPU PCPU WHAT root tty1 :0 16:18 1:10m 4.05s 4.05s /usr/bin/Xorg : root pts/0 :0.0 16:18 1:07m 0.02s 0.02s /bin/bash root pts/1 192.168.112.1 17:23 2:43 0.00s 0.00s -bash root pts/3 192.168.112.1 08:58 0.00s 0.64s 0.17s w
25、screen使用
screen -S name:创建一个名字为name的新会话
screen -ls:显示所有的会话
screen -r name: 恢复name会话
Ctrl + a.d 剥离当前会话 也就是关掉当前的会话
26、echo 回显
-n:不加换行符
[root@localhost ~]$ echo -n 'jak'
jak[root@localhost ~]$
-e:显示控制符 如 :\t
[root@localhost ~]$ echo -n -e 'jak\tda\b'
jak d[root@localhost ~]$
常见的控制符:
\a ::发出警告声
\b :退格
\c: 最后不加换行符
\n :换行且光标移动至行首
\r :回车 ,即光标移动行首,但不换行
\t : 制表符tab
\\ :插入\
27、括号扩展
echo hi{1,2}
echo {1,2}{3,4}
cd ~username :切换到用户家目录
echo {1..20} {a..z}
28、命令替换
ls -l $(cd /etc/sysconfig/) :$(cd /etc/sysconfig/) 把得到的结果传递给另一个命令
反引号:命令替换 :
echo hostname ----- echo `hostname`
双引号:弱引用:
[root@localhost ~]$ echo "$PS1"
\033[30;33m[\u@\h \W]$ \033[0m
单引号:强引用:是啥就是啥不会替换
[root@localhost ~]$ echo '$PS1'
$PS1
29、Linux的两棵树
文件树-/,进程树-init
FHS:文件系统层级结构标准
一切皆文件:
登录进shell,每时每刻都处于某个路径下:
当前目录:current dir
工作目录:working dir
相对路径:
绝对路径:
程序文件
/bin /sbin /usr/bin, /usr/sbin ,/usr/local/bin,/usr/local/sbin
Linux的进程管理:
Linux启动后,内核创建进程,对进程进行管理,但是全部由内核管理会导致内核压力过大,所以内核创建一个init进程,由此进程管理后续生成的进程。
在LInux中不同的版本中,init不同(这里特指CentOS),centos5 sysv init,centos6 upstart,centos7 systemd。
什么是僵尸进程:zombie
在Linux中,模拟的是白发人送黑发人,即子进程是黑发人,子进程结束后,父进程才能结束,否则,父进程结束了,子进程没有结束,但是子进程处于僵尸状态。
30、命令历史
history 默认保存1000条 $HISTSIZE ------> printenv
HISTCONTROL =
ignoredups # 忽略相邻重复的
ignorespace # 忽略以空白开头的命令
ignoreboth # 两者都忽略
会保存在用户家目录下的.bash_history
history:
-c:清空命令历史
-d offset:删除历史中指定的第offset个命令
n :显示最近的n条历史
-a:追加本次回话新执行的命令到历史文件中
-r:将.bash_history显示到屏幕上
-w:保存历史列表到指定文件中
-n :读历史文件中没有读过的行到历史列表中
重复前一个命令:有4中方法
使用向上键
使用!!
使用 !-1
Ctrl +p 回车执行
!:0 :执行前一条命令(去除参数)
!n :执行对应序号的命令
!-n : 执行倒数第n条命令
重新调用前一个命令中的最后一个参数:
!$ 或者 Alt +。 或者 ESc放开在按。
31、获取帮助
内部命令: help history
外部命令:
--help -h 获取帮助
man and info ------- /usr/share/man
程序自带的帮助信息
whatis:显示命令的简短描述,使用数据库,刚装不能立即使用,makewhatis|mandb制作数据库
whatis cat
--help:
[]:可选项
<>或CAPS:表示变化的数据
...表示一个列表
x|y|z:或者的关系
-abc: -a -b -c
{}:分组
man:手册页放在/usr/share/man
man页面分组为不同的章节
man命令的配置文件:/etc/man.config | man_db.conf
MANPATH /PATH/TO/SOMEWHERE: 指明man文件搜索位置
man -M /PATH/TO/SOMEWHERE COMMAND: 到指定位置下搜索COMMAND命令的手册页并显示
man章节:
1、用户命令
2、系统调用
3、C库调用
4、设备文件以及特殊文件
5、配置文件格式
6、游戏
7、杂项
· 8、管理类命令
9、linux内核API
man帮助段落说明:
NAME:名称及简要说明
SYNOPSIS:用法格式
DESCRIPTION:详细描述
OPTIONS:选项说明
EXAMPLES:实例
查看手册:man 1 cat
列出所有帮助:man -a cat
搜索man手册:man -k cat
翻看man手册技巧:
空格:向下翻屏
b:向上翻屏
d:向下翻半屏
u:向上翻半屏
#:定位到第几行
enter:向下一行
y:向上一行
1G:回到顶部
G:到尾部
/keyword :查找关键字,使用N/n翻 ,向后搜
?keyword:查找关键字,使用N/n翻 ,向前搜
info:info cat
方向键翻
tab键,移动到下一个链接
enter:进入选定的链接
s:文本搜索
q:退出
本地帮助文档:
/usr/share/doc目录
常见文档:readme,install,changes
注:
exec bash:exec执行程序,替换当前的进程,可以通过pstree看出来
通过在线文档获取帮助:第三方应用官方文档
http://www.nginx.org
http://tomcat.apache.org
http://httpd.apache.org
http://www.python.org
通过发行版官方的文档光盘或网站可以获得,安装指南、部署指南、虚拟化指南等,红帽知识库和官方在线文档
http://kbase.redhat.com
http://www.redhat.com/docs
http://access.redhat.com
第二节:文件管理和重定向
1、文件系统与目录结构
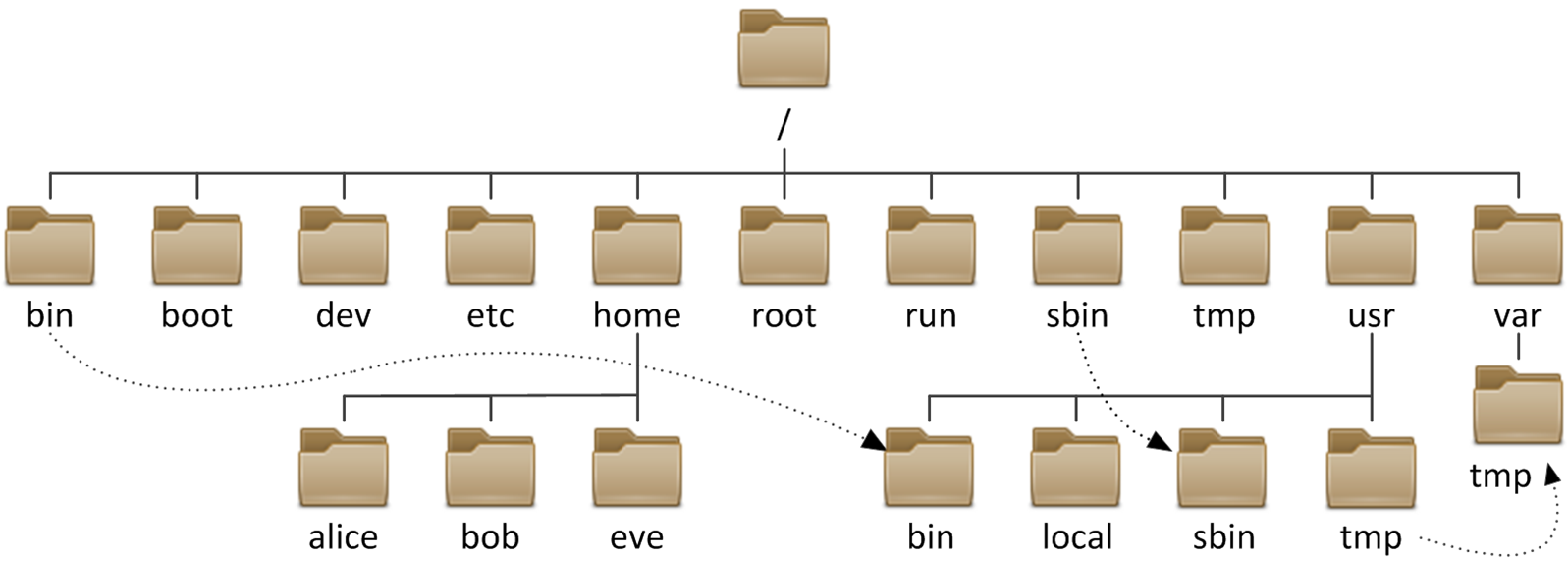
① 文件系统:
1)在Linux系统中,所有的文件和目录都被组织成一个单根的倒置树状,文件系统从根目录下开始,用“/” 表示。在Linux中文件名称是严格区分大小写,以.开头的文件为隐藏文件。路径的分隔是 "/" 。
注:了解两个特殊的目录
1、. 表示当前目录,即用户所在的工作目录。
2、..表示父目录,即当前目录的上一层目录。
2)Linux文件系统分层结构遵循FHS(FilesystemHierarchy Standard)即文件系统层级结构标准
查看FHS文档:http://www.pathname.com/fhs/
3)Linux中每一个分区都是一个文件系统。
4)根,整个系统启动时加载文件的唯一入口。
5) 文件有两类数据:
元数据:metadata
数据:data
② 目录结构:
1)文件命名规则:
-
-
- 文件名最长255个字节
- 包括路径在内的文件名称最长4095个字节
- 颜色表示(ANSI规定):蓝色(目录)、绿色(可执行文件)、红色(压缩文件)、浅蓝色(链接文件)、灰色(其他文件)、紫色(套接字)
- 文件名的命名可以使用除了 / 以外 的任何字符,但是一般不推荐 使用特殊字符。
- 标准Linux文件系统(ext4,xfs),文件名称严格区分大小写。
-
③ 文件系统结构中重要的目录:
/boot :引导文件存放的目录,内核文件(vmlinuz)、引导加载器(BootLoader,grub)都存放与此。
/bin : 供所有用户使用的基本命令,不能关联至独立分区,OS启动即会用到的程序。不能作为其他分区的访问入口,只能在根分区上。
/sbin :管理类的基本命令,不能关联至独立分区,OS启动就会用到的程序。
/lib :启动时程序依赖的基本共享库文件以及内核模块文件(/lib/modules)。
/lib64 :专用于x86_64系统上的辅助共享文件库存放位置
/etc :配置文件
/home/USERNAME :普通用户的家目录
/root : 管理员的家目录
/media :便携式设备的挂载点
/mnt :临时文件系统挂载点
/dev :设备文件及特殊文件的存储位置
b:block device -----随机访问(块设备)
c:character device ------线性访问 (字符设备)
/opt :第三方用用程序的安装位置
/srv :系统上运行的服务用到的数据
/tmp :临时文件存储位置,如果文件30天没动,会自动删除。
/usr :universal shared,read-only data----->可以单独分区的(也就是说可以作为某个分区的入口)
bin:保证系统拥有完整功能而提供的应用程序,也就是说启动操作系统后,启动一些服务
lib64:只存在于64位的系统
lnclude:c程序的头文件
share :结构化独立的数据,如:doc,man等
local :第三方应用程序的安装位置(bin ,sbin ,lib,lb64,etc,share)
/var :variable data files
cache:应用程序的缓存数据目录
lib:应用程序状态信息数据
local:专用于为/usr/local下的应用程序存储可变数据
lock:锁文件
log:日志目录及文件
opt:专用于为/opt下的应用程序存储可变数据
run:运行中的进程相关数据,通常用于存储进程pid文件
spool:应用程序数据池
tmp:保存系统两次重启之间产生的临时数据。
/proc:用于输出内核与进程信息相关的虚拟文件系统
/sys :用于输出当前系统上硬件设备相关新消息虚拟文件系统
/selinux:security enhanced linux,selinux相关的安全策略等信息的存储位置。
selinux对于初学linux的比较难,所以建议在平时实验中关掉selinux
getenforce:获取selinux的状态:
enforcing:开启的
permissive:许可的,会有警告,但是不影响操作
disabled:禁止的
setenforce:设置selinux的状态
0:许可,1:开启的,或者直接修改配置文件,以便以后再登录不再修改 /etc/selinux/config
总结:
二进制程序:/bin, /sbin, /usr/bin, /usr/sbin, /usr/local/bin, /usr/local/sbin
库文件:/lib, /lib64, /usr/lib, /usr/lib64, /usr/local/lib, /usr/local/lib64
配置文件:/etc, /etc/DIRECTORY, /usr/local/etc
帮助文件:/usr/share/man, /usr/share/doc, /usr/local/share/man, /usr/local/share/doc
2、Linux下的文件类型
-:普通文件
d:目录文件
l :链接文件
c:字符文件
b:块文件
s:套接字文件
p:管道文件
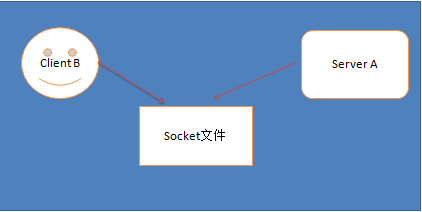
如图:服务器端、客户端都是自己,那么服务器进程和客户进程相互通信就使用套接字文件。省去了数据报文封装等。
3、显示当前工作目录
-
- 每个shell和系统进程都有一个当前的工作目录
- CWD:current work directory
- 显示当前shell CWD的绝对路劲
pwd:打印工作路径
注:/var/www/a.txt
a.txt :基名
/var/www/:目录名
4、更改目录
cd :可以绝对路径,cd /home/log 可以相对路径 cd home/log
cd .. :切换到父目录
cd - :当前目录和前一个目录相互切换
-P:指向符号链接的目标目录
-L:指向符号链接的目录
相关环境变量:printenv可以查看到
PWD:当前目录路径
OLDPWD:上一次目录路径
[root@localhost tmp]# ls -al total 80 drwxrwxrwt. 17 root root 4096 Jul 28 05:22 . dr-xr-xr-x. 25 root root 4096 Jul 28 00:36 .. drwxr-xr-x. 2 root tom 4096 Jul 28 05:21 a drwxr-xr-x. 2 root tom 4096 Jul 28 05:12 b drwxr-xr-x. 2 root root 4096 Jul 28 02:53 bin -rw-r--r--. 1 root root 183 Jul 28 03:18 e drwx------. 2 root root 4096 Jul 28 01:46 .esd-0 drwx------. 2 jack3 users 4096 Jul 28 01:51 .esd-506 drwx------. 2 jack jack 4096 Jul 28 01:51 .esd-507 lrwxrwxrwx. 1 root tom 1 Jul 28 05:22 f -> a drwxrwxrwt. 2 root root 4096 Jul 28 01:51 .ICE-unix drwxr-xr-x. 2 root root 4096 Jul 28 03:02 lo3od -rw-r--r--. 1 root root 0 Jul 28 03:01 lsada55ad5sda5sda5dsa drwxr-xr-x. 5 root root 4096 Jul 28 03:13 m -rw-r--r--. 1 root tom 1838 Jul 28 05:09 passwd lrwxrwxrwx. 1 root tom 6 Jul 28 05:09 passwd.1 -> passwd drwx------. 2 jack3 users 4096 Jul 28 02:54 pulse-VGs41aKnJWMa drwxr-xr-x. 2 root root 4096 Jul 28 02:45 s drwxr-xr-x. 2 root root 4096 Jul 28 02:53 sbin drwxr-xr-x. 4 root root 4096 Jul 28 02:53 usr drwxr-xr-x. 4 root root 4096 Jul 28 02:52 x -r--r--r--. 1 root root 11 Jul 28 01:51 .X0-lock drwxrwxrwt. 2 root root 4096 Jul 28 01:51 .X11-unix [root@localhost tmp]# cd -P f [root@localhost a]# cd .. [root@localhost tmp]# cd -L f [root@localhost f]# pwd /tmp/f [root@localhost f]#
5、列出目录内容
列出当前目录的内容或指定目录
用法: ls [options] [fies or dir]
ls -a :显示所有文件包括隐藏文件
ls -A:显示所有文件,除了. 和 ..
ls -l :显示详细信息,文件元数据等
ls -R:递归显示目录下的内容
ls -ld: 目录和符号链接信息
ls -1 :文件分行显示
ls -S : 按从小到大排序
ls -t :按照mtime排序
ls -u :配合-t选项,显示并按atime从新到旧排序
ls -X :按照文件后缀排序
ls -i :显示inode号
6、查看文件状态
stat:
[root@localhost etc]$ stat /etc/passwd File: `/etc/passwd' Size: 1611 Blocks: 8 IO Block: 4096 regular file Device: 803h/2051d Inode: 926217 Links: 1 Access: (0644/-rw-r--r--) Uid: ( 0/ root) Gid: ( 0/ root) Access: 2018-07-26 18:20:01.950396837 +0800 Modify: 2018-07-25 18:14:43.467998719 +0800 Change: 2018-07-25 18:14:43.468998720 +0800
文件包含两种数据:元数据metadata,数据data
三个时间戳:
access time:访问时间,atime,读取文件内容
modify time:修改时间,mtime,改变文件内容(数据)
change time:改变时间,ctime,元数据发生改变
7、文件通配符
常用文件通配符:
*:匹配任意个字符
?:匹配有且只有一个
~:当前用户的家目录
~mage:用户mage的家目录
~+:当前工作目录
~-:前一个工作目录
[0-9]:匹配数字集合,其中的一个
[a-z],[A-Z]:匹配字母集合,不区分大小写
[waf]:匹配列表中的任何一个字符
[^wad]:匹配集合外的任何一个字符
预定义的字符类:用 man 7 glob查看
[:digit:]:任意数字 0-9
[:lower:] :任意小写字母
[:upper:] :任意大写字母
[:alpha:] :任意字母
[:alnum:]:任意数字和字母
[:blank:]:水平空白
[:punct:] :标点符号
[:space:] : 水平或垂直空白字符
[:print:] :可打印字符
[:cntrl:] :控制(非打印字符)
[:graph:] :图形字符
[:xdigit:] : 十六进制字符
注:命令行开头使用 \ 表示使用命令本身,忽略别名
8、创建空文件和刷新时间
touch命令:
touch [options] FILE
-a :仅改变atime和ctime
-m :仅改变mtime和ctime
-t [[CC]YY]MMDDhhmm[.ss]:指定atime和mtine
-c :如果文件不存在,则不予以创建(默认是创建的)
9、复制文件和目录--cp
复制CP:
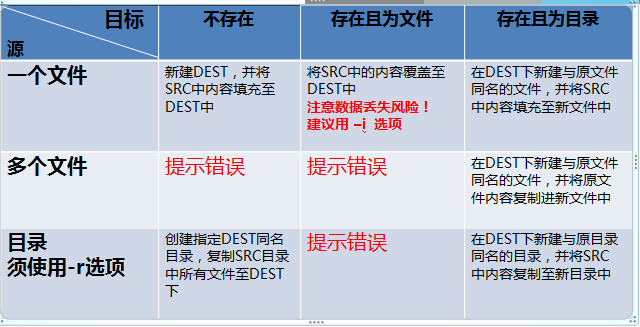
cp常用选项:复制就是创建新文件!
-i :覆盖当前提示
-r,-R: 递归复制目录及内部的所有的内容
-d:不复制源文件,只复制链接名,只针对软连接(符号链接)
lrwxrwxrwx. 1 root root 6 Jul 27 05:37 /etc/passwd.2 -> passwd cp -d /etc/passwd.2 /tmp/ lrwxrwxrwx. 1 root root 6 Jul 27 16:32 passwd.2 -> passwd ------password处于闪烁状态
-a:此选项如同:-drp,常用于目录复制
--preserve[=ATTR_LIST] :属性列表,使复制的内容保持原有的某些属性
mode:权限
ownership:属主属组
timestamp:时间
link:链接
xattr:扩展属性
context:保持selinux安全上下文
all:所有属性
-p:等同于--preserve=mode,ownership,timestamp
-v:详细信息
-f:强制复制,不需要问是否覆盖等。
-u:只复制源比目标更新文件或目标不存在的文件
--backup=numbered 目标存在,覆盖先前备份加数字后缀
[root@localhost tmp]$ cp --backup=numbered /etc/passwd ./ cp: overwrite `./passwd'? y [root@localhost tmp]$ ls fonts orbit-gdm pulse-Itk8L8wAIJOk virtual-root.7vnhSk virtual-root.N0565Z gconfd-gdm passwd pulse-Uu1TjyAHWxiC virtual-root.AxT2s0 virtual-root.wVSgSR gconfd-root passwd.~1~ shadow virtual-root.iV4aSv yum.log
注:
cp是做了别名的 cp = ‘cp -i’,如果让以原命令执行,在开头加一个 \
cp -t DST RUS :-t选项,使目标位置放到前面
10、移动和重命名文件
① 什么是移动:
移动,在同一个分区移动速度很快,但是跨分区就很慢,因为,在同一个分区的时候,只是修改了路径而已,其他的都不变,而跨分区,需要创建文件,同时移动数据内容,所以很慢,取决于自己的io吞吐能力。
② 常用选项 :类似于cp,但是不同 -r 选项
mv [option] [-T] source dest
mv [option] dest source
mv [option] -t dirctory source
-i :交互式
-f :强制
注:在同一个目录下移动,就是重命名。否则就是真正的移动。
11、删除和重命名:文件
rm [option] FILE
常用选项:
-i:交互式
-f:强制删除
-r:递归删除
--no-preserve-root :do not treat ‘/’ specially
12、目录操作常用命令
tree 显示目录树
-d:只显示目录
-L level :指定显示的层级数目
-P pattern :只显示由指定的pattern匹配到的路径
mkdir:创建目录
-p :存在不报错,且可自动创建所需的各目录
-v:详细信息
-m mode:创建目录是直接指定权限
rmdir:删除 ----空----目录
-p:递归删除父空目录
-v
rm -r :递归删除目录树(删除非空)
注:生成中,使用mv 而不用rm
13、关于索引节点的介绍
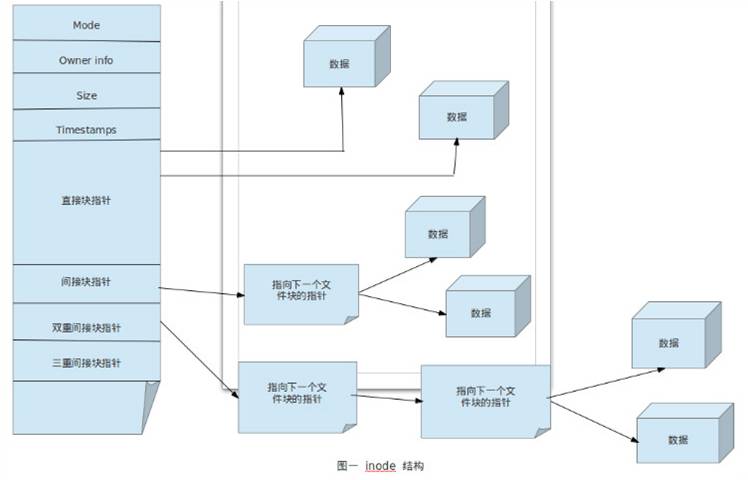
①:什么是inode
inode(index node):表中包含文件所有文件列表。,一个节点(索引节点)是在一个表项,包括有关文件的信息(元数据),包括:
文件类型,权限,UID,GID,链接数(指向这个文件名路径名称的个数),该文件的大小和不同的时间戳,指向磁盘上文件的数据块指针,有关文件的其他数据。
②:inode表结构:
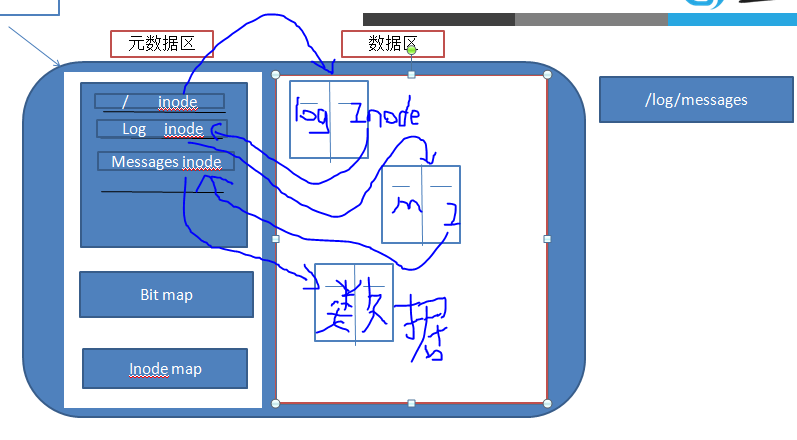
磁盘被文件系统分成数据区和元数据区:
元数据(inode保存元数据):除了文件名,因为文件名在目录上。如下图:如何查找一个数据
根是目录,对一个Inode号,在数据区找到对应得数据块,在数据块中又有log对应得Inode号,在找到log的数据块,一步一步最后找到messages的数据内容
, ③:文件操作命令与inode的关系:
-
-
- cp与inode:分配一个空闲的inode号,在inode表中生成新条目在目录中创建一个目录项,将名称与inode编号关联宝贝数据生成新的文件
- rm与inode:链接数递减,从而释放的inode号可以被重用,吧数据块放在空闲列表中,删除目录项,数据实际上不会被马上删除,但当另一个文件使用数据块时将被覆盖。(bit map、inode map标记为0)
- mv与inode:如果目标和源在相同的文件系统,用心的文件名创建对应的行的目录项,删除就得目录项对应的旧的文件名,不影响inode表(除了时间戳)或磁盘上的数据位置:没有 数据被移动。如果不在同一个文件系统中,mv相当于cp和rm。
-
注:ext4 对单个文件的大小有限制,而xfs 对其没有限制。btrfs还在试验中!
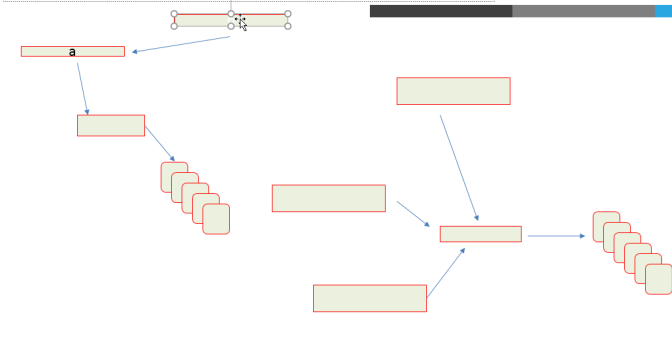
14、硬链接和软链接
① 硬链接特点:
-
-
- 创建硬链接会增加额外的记录项以应用文件
- 对应于同一文件系统上的一个物理文件
- 每个项目引用相同的inode号
- 创建连接数递增
- 不能跨越分区
- 删除文件时:
-
rm命令递减技术的链接
文件要存在,至少有一个链接数
当链接数为0时,该文件被删除
语法:ln filename [linkname]
②软链接特点(符号链接)
-
-
- 一个符号链接指向一个文件
- ls -l的显示链接的名称和引用的文件
- 一个符号链接的内容 是它引用文件的文件名称
- 可以对目录进行!!!!!!!
- 可以跨分区
- 执行的是另一个文件的路径,其大小为指向的路径字符串的长度,不增加或减少目标文件的inode的一弄计数
-
语法:ln -s filename linkname
软链接(左)、硬链接模拟图:
15、确定文件内容,类型
file [option] filename
-b :列出文件辨识结果时,不显示文件名称
-f filelist 列出文件filelist中文件名的文件类型 如:a.txt里有 /etc/passwd /etc/shadow
-F :使用指定的分隔符替换输出文件名后默认的 “:”分隔符
-L 查看对应软链接对应文件的文件类型
[root@localhost tmp]$ file -b passwd.2 ASCII text [root@localhost tmp]$ file passwd.2 passwd.2: ASCII text [root@localhost tmp]$ file passwd.2 shadow passwd.2: ASCII text shadow: ASCII text [root@localhost tmp]$ file -F - passwd.2 passwd.2- ASCII text [root@localhost tmp]$ file -L shadow.1 shadow.1: ASCII text
16、标准输入和输出
打开的文件都有文件描述符:fd--file descriptor
Linux给程序提供了三种I/O设备:
标准输入stdin ----0 默认接受来自键盘的输入 ------ /dev/sdtin
标准输出stdout -----1 默认输出到终端屏幕 ------ /dev/stdout
标准错误stderr -----2 默认输出到终端 ------ /dev/stdout
① stdout 和 stderr 可以重定向到某个文件
支持的操作符:
> :stdout重定向到文件
2> :stderr重定向到文件
&> :把所有输出重定向到文件
> :文件内容会被覆盖
set -C 禁止将内容覆盖已有文件,但是可追加
> | file 强制覆盖
set + C 允许覆盖
>> 原有内容基础上,追加内容
2> :覆盖重定向错误输出数据流
2>> : 追加
两者各自定向只不同位置
command > /path/to/file1 2> /pah/to/file2
合并到同一个位置
&> 覆盖重定向
&>>: 追加重定向
command > /path/to/file.out 2>&1 (顺序很重要)
command >> /path/to/file.out 2>&1
():合并多个程序的stdout
(cal 2007;cal2008)> all.txt
②输入重定向很少用但是也有特殊用法:
[root@localhost tmp]$ tr 'a-z' 'A-Z' < /etc/issue
CENTOS RELEASE 6.9 (FINAL)
KERNEL \R ON AN \M
[root@localhost tmp]$ echo 'ssssssss' > b.txt
[root@localhost tmp]$ clear
[root@localhost tmp]$ cat > a.txt < b.txt
[root@localhost tmp]$ cat a.txt b.txt
ssssssss
ssssssss
[root@localhost tmp]$ cat > b.txt << EOF > 2 > 2 > 2 > EOF [root@localhost tmp]$ cat b.txt 2 2 2
17、tr命令
tr :转换和删除字符
tr [option] [file]
-c -C:取字符集的补集
-d :删除所有属于第一字符集的字符
echo 'helo23l2o' | tr -d -c [[:digit:]] 232
-s :把里连续重复的字符单独一个字符表示
echo 'helo23l22o' | tr -s 2 helo23l2o
echo 'helo23l22o' | tr -s 2 helo23l2o
-t :将第一个字符集对应字符转化为第二个字符集对应的字符
18、管道
管道(使用符号 | 表示)用来连接命令
命令1 | 命令2 | 命令3 |。。。
ls | tr 'a-z' 'A-Z'
管道中的 - 符号
将 /home 里面的文件打包,但打包的数据不是记录到文件,而是传送到 stdout,经过管道后,将 tar -cvf - /home 传送给后面的 tar -xvf - , 后面的这个 - 则是取前一个命令的 stdout, 因此,就不需要使用临时file了
tar -cvf - /home | tar -xvf -
[root@localhost tmp]$ echo '/etc/passwd' | file Usage: file [-bchikLNnprsvz0] [--apple] [--mime-encoding] [--mime-type] [-e testname] [-F separator] [-f namefile] [-m magicfiles] file ... file -C [-m magicfiles] file [--help] [root@localhost tmp]$ echo '/etc/passwd' | file - /dev/stdin: ASCII text
注:多重管道,最后一重是在子shell中进行的
19、文本查看器:
less:一页一页的查看输入 ls -l /ec/ |less (快捷键使用跟man一样)
more:翻到最后直接退出,less不会
cat:
tac :倒序查看
20、tee命令(重定向到多个目标)
cat /etc/passwd |tr -d 'abc'| tee /tmp/mypass :即输出到屏幕,又输出到某个文件
第三节:用户组权限的详细介绍
1、解释Linux的安全模型-特定资源给 用户使用
Authentication:认证
Authorization:授权
Adition:审计
① 用户user
令牌token.identity
Linux用户:Username/UID
管理员:root / 0
普通用户:1-65535
系统用户:1-499,1-999(CentOS7)
对守护进程获取资源进行权限分配,不能登录系统
登录用户:500+ ,1000+ (CentOS7)
交互式登录
② 组group
LInux组:groupname/ GID
管理员组:root 、0
普通组:
系统组: 1-499 ,1-999
普通组:500+,1000+
③ 安全上下文
运行中的程序就是进程,进程时没有特殊权限的,进程的权限取决于是谁发起了该进程。
root : /bin/cat
jack :/bin/cat
进程能够访问资源的权限取决于进程的运行者身份。
④ 组的类别
Linux组的类别
用户的主要组(primary group)
用户必须属于一个且只有一个主组
组名同用户名,且仅包含一个用户,私有组
用户的附加组(supplementary group)
一个用户可以属于0个或者多个附加组
⑤ 用户和组的配置文件
Linux用户和组的主要的配置文件
/etc/passwd
/etc/group
/etc/shadow
/etc/gshadow
passwd文件格式:jack:x:500:500::/home/jack:/bin/bash
-
-
-
-
- 用户名
- 密码占位符
- UID
- GID
- 注释
- 家目录
- 默认使用shell
-
-
-
shadow文件格式;root:$6$B10sAzu4L7s.p0Vc$8ksttW0UABIDQ/4LNl8bmW0UUORvZ1HYmkZp18mvKPK0tUcV90TesKjIYQhiikFyfFWSm
-
-
-
-
- 用户名
- 加盐后加密的密码
- 最近一次被改动的时间
- 密码再过几天可以被修改
- 密码再过几天必须变更
- 密码过期前几天系统提醒用户
- 密码过几天后锁定
- 1970/1/1起,多少天后账号失效
-
-
-
group文件格式: bin:x:1:bin,daemon
-
-
-
-
- 组名
- 组密码占位符
- GID
- 以当前组作为附加组的用户列表
-
-
-
gshadow文件格式:bin:::bin,daemon
-
-
-
-
- 组名
- 组密码
- 组管理员列表,更改组密码和成员用 gpasswd
- 以当前组为附加组的用户列表
-
-
-
2、用户和组管理命令
用户管理命令
useradd,usermod,userdel
组管理命令
groupadd ,groupmod,groupdel
用户管理:
① 用户创建:useradd
-u :UID
-o :不检查UID的唯一性(跟-u一起使用)
-g :GID
-c :注释信息
-d :用户家目录
-s :默认shell
-G :附加组,组必须事先存在
-N :不创建私用组做主组,使用users组作为主组
-r :创建系统用户 1-499 ,1-999
-m :创建家目录,用于系统用户
-M :不创建家目录,用于非系统用户
默认值设定:/etc/default/useradd文件中
显示或更改默认设置:
useradd -D
useradd -D -s SHELL 等
② 用户属性修改
usermod:选项跟useradd的一样使用,但是注意,修改附加组,不加-a,会覆盖之前的附加组
③ 用户删除
userdel:不会删除家目录,使用-r
④ 查看用户相关的ID 信息
id :
-u:uid -g :gid -G :显示用户所属的组的ID -n :显示名称,需要ugG配合
组管理命令:
① 创建组
groupadd
-g :GID
-r :创建系统组
② 修改和删除组
groupmod
-g :修改gid
-n :新名字
groupdel
③ 更改组密码
gpasswd
-a user :将user添加至指定组中
-d user :从指定组中移除用户user
-A user1 user2 设置有管理权限的用户列表
newgrp:临时切换主组
如果用户不属于此组,则需要租密码
3、切换用户或以其他用户的身份执行命令
su Username:只是简单的切换一下身份
su - Username :用这个用户重新登录(完全切换)
su -l userr1 -c 'whoami' : 以user1的身份运行一条命令(-l login 等于 - )
4、设置密码:
passwd [option] username
-d:删除指定用户的密码
-l :锁定指定用户
-u:解锁指定用户
-e :强制用户下次登录修改密码
-f :强制操作
-n :指定最短使用期限 天
-x :最大使用期限
-w :提前多少天开始警告
--stdin:从标准输入接受用户密码
echo ‘password' | passwd --stdin UserName
第四节:文件权限管理
1、文件权限
文件的权限主要针对三类对象定义:
owner:属主,u
group:属组,g
other:其他,o
每个文件针对没类访问者都定义了三种权限
r:readable
w:writeable
x:eXcutable
r、w、x对文件和目录的意义:
文件:
r:可使用文件查看类工具获取其内容
w:可修改其内容
x:可以把次文件提请内核启动为一个进程
目录:
r:可以使用ls查看此目录中文件列表
w:可在此目录中创建文件,也可以删除此目录中的文件
x:可以使用ls -l 查看此目录中文件列表,可以cd进入此目录
用8进制表示:
--- 000 0
--x 001 1
-w- 010 2
-wx 011 3
r-- 100 4
r-x 101 5
rw- 110 6
rwx 111 7
例如: 640:rw-r----- 755:rwxr-xr-x
2、修改文件权限的命令:chmod
chmod [option]..octal-mode file
-R:递归修改权限
chmod [option]...mode[,mode] ....file ...
mode:
通过八进制数对权限修改:
chmod 77 passwd ---- 077,默认左侧补0
修改一类用户的所有权限:
u=
g=
o=
ug=
a= 所有的
u=,g=
如:chmod g=rw issue
修改某一类户某一位的权限:
u+
u-
如:
chmod u+x issue
chmod og-x issue
chmod a+x issue
修改所有用户的某类权限
chmod +x issue 都加
chmod +r issue 都加
chmod +w issue 只能给属主加 (默认不可以让其他类用户都有权限,否则所有用户都有权限操作)
注 :shell默认有文件或目录创建时的遮罩码umask:配置文件在/root/ .bashrc 或者 .bashrc_profile 配置
umask: 查看
umask #: 设定
(管理员)默认是0022 创建目录 777-022 创建文件 666-022 默认权限
(普通用户)002
针对文件,即便umask是023这样的,666-023=643,即other有执行权限的,默认权限都会加1,为644
mode [option]... --reference=file FILE:参考file的权限,作为FILE 的权限
3、修改文件的属主和属组 (普通用户没有权限修改属主属组)
修改文件的属主:chown
chown [option]...[owner][:[group]] FILE...
用法:
chown:也可以修改属组
chown user1:user1 issue
chown user1.user1 issue
chown -R hi.dir/ 递归
chown [OPTION]... --reference=RFILE FILE...
修改文件的属组:chgrp
4、文件访问控制列表FACL
ACL:Access Control List,事先灵活的权限管理
除了文件的所有者,所属组和其他人,可以对更多的用户设置权限,让某用户对该文件有了一定的权限
CentOS7 默认创建的XFS和EXT4文件系统具有ACL功能。CentOS7之前版本,默认手工创建ext4文件系统无ACL功能,需手动增加
tune2fs -o acl /dev/sdb1
mount -o acl/dev/sdb1 /mnt/test
ACL生效顺序:所有者,自定义用户,自定义组,其他人 (属主-属组-属主facl-属组facl-其他)
使用:ls查看文件属性,最后多了一个+
添加:
setfacl -m u:user1:rw a.txt
setfacl -m g:user1:rw a.txt
查看:
getfacl
[root@localhost ~]# setfacl -m u:tom2:r /etc/passwd [root@localhost ~]# getfacl /etc/passwd getfacl: Removing leading '/' from absolute path names # file: etc/passwd # owner: root # group: root user::rw- user:tom2:r-- group::r-- mask::r-- other::r-- [root@localhost ~]# su - tom2 -c 'ls -al /etc/passwd' -rw-r--r--+ 1 root root 1838 Jul 28 03:40 /etc/passwd [root@localhost ~]# su - tom2 -c 'tail -1 /etc/passwd' tom2:x:557:557::/home/tom2:/bin/bash [root@localhost ~]# setfacl -x u:tom2:r /etc/passwd setfacl: Option -x: Invalid argument near character 8 [root@localhost ~]# setfacl -x u:tom2 /etc/passwd [root@localhost ~]# getfacl Usage: getfacl [-aceEsRLPtpndvh] file ... Try `getfacl --help' for more information. [root@localhost ~]# getfacl /etc/passwd getfacl: Removing leading '/' from absolute path names # file: etc/passwd # owner: root # group: root user::rw- group::r-- mask::r-- other::r--
删除:
setfacl -x u:user1 a.txt
5、LInux文件系统上的特殊权限
SUID、SGID、Sticky
① 权限有:r、w、x -------user、group、other
② 安全上下文
前提:进程有属主和属组,文件有属主和属组
1)任何一个可执行的程序文件能不能启动为今晨,取决于发起者对程序文件是否拥有执行权限
2)启动为进程之后,其进程的属主为发起者,进程的属组为发起者所属的组
3)进程访问文件的权限,取决于进程的发起者
a、进程的发起者,同文件的属主,则应用文件属主权限
b、进程的发起者,属于文件的属组,则应用文件属组权限
c、应用文件“其他”求权限
③ SUID:
1)任何一个可执行程序文件能不能启动为进程,取决发起者对程序文件是否拥有可执行权限
2)启动为进程之后,其进程的属主为源程序文件的属主
权限设定:
chmod u+s FILE 以该文件的属主的权限运行,普通用户不能执行某文件,但是+s后,就可以执行,但是是以该文件的属主的身份执行
chmod u-s FILE
注:如上设定,如果原来属主没有执行权限,那么现实s为大写S,否则小写s
④ SGID
默认情况下,用户创建文件时,其属组为此用户所属的基本组,一旦某目录被设定了SGID,则对此目录有写权限的用户在此目录中创建的文件所属的组为此目录的属组
权限设定:
chmod g+s DIR...
chmod g-s DIR...
⑤Sticky
对于一个多人可写的目录,如果设置了Sticky,则每个用户只能删除自己的文件。
权限设定:
chmod o+t DIR...
chmod o-t DIR...
⑥ 同样特殊权限也可以用八进制表示
SUID SGID STICKY
000 0
001 1
010 2
011 3
100 4
101 5
110 6
111 7
如:chmod 4777 /tmp/a.txt 4表示:100 s--
注:
-
-
-
- FACL针对某个用户
- 特殊权限针对所有用户
- SGID和Sticky 一般只用于目录操作
-
-
第五节:文本处理
1、常用文本查看工具:
cat,tac,more,less
head,tail
tail -f:可以监视追加的新内容
wc:单词统计
sort:排序
uniq:去重
diff:文件对比
patch:打补丁
2、文件查看
cat、tac、rev
cat:
-E:显示行结束符$
-n :编号
-A:显示所有的控制符
-b:非空行编号
-s:压缩连续的空行成一行
tac:文件整体倒序
rev:每行都倒序
3、分页查看文件内容
more
less : 类似man翻页和查询
4、显示文件文本前几行后几行
head :
-c #:指定获取前几个字节
-n #:指定获取前几行
-# :指定行数
tail :
-c #: 指定获取后#字节
-n #: 指定获取后#行
-#:
-f: 跟踪显示文件fd新追加的内容,常用日志监控
tailf 类似 tail -f ,当文件不增长时不访问文件
5、按列抽取文本cut和 合并文件paste
cut [option] ...FILE
-d :指明分隔符,默认tab
-f :
#:第#个字段
#,#[,#]:离散的多个字段
#-#:连续的多个字段,例如 1-4
混合使用:1-3,7
-c : 按字符切割
--output-delimiter=STRING指定输出分隔符
例如:
显示文件或STDIN数据的指定列
cut -d: -f1 /etc/passwd
cat /etc/passwd | cut -d: -f7
cut -c2-5 /usr/share/dict/words
paste :合并两个文件同行号的列到一行
paste [OPTION]... [FILE]...
-d 分隔符:指定分隔符,默认用TAB
-s : 所有行合成一行显示
paste f1 f2
paste -s f1 f2
6、文本分析工具
文本数据统计:wc
计数单词总数、行总数、字节总数和字符总数
可以对文件或STDIN中的数据运行
wc story.txt
39 237 1901 story.txt
行数 字数 字节数
常用选项
-l 只计数行数
-w 只计数单词总数
-c 只计数字节总数
-m 只计数字符总数
-L 显示文件中最长行的长度
整理文本:sort
把整理过的文本显示在STDOUT,不改变原始文件
sort [options] file(s)
常用选项
-r 执行反方向(由上至下)整理
-R 随机排序
-n 执行按数字大小整理
-f 选项忽略(fold)字符串中的字符大小写
-u 选项(独特,unique)删除输出中的重复行
-t c 选项使用c做为字段界定符
-k X 选项按照使用c字符分隔的X列来整理能够使用多次
1 [root@localhost /tmp]$ cat a.txt 2 nana:30:5.5 3 apple:10:2.5 4 pear:90:2.3 5 orange:20:3.4 6 [root@localhost /tmp]$ sort -n -t: -k2 a.txt 7 apple:10:2.5 8 orange:20:3.4 9 nana:30:5.5 10 pear:90:2.3
比较文件:diff 和 patch
从输入中删除前后相接的重复的行 uniq
uniq [OPTION]... [FILE]...
-c: 显示每行重复出现的次数
-d: 仅显示重复过的行
-u: 仅显示不曾重复的行
注:连续且完全相同方为重复
常和sort 命令一起配合使用:
sort userlist.txt | uniq -c
1 以冒号分隔,取出/etc/passwd文件的第6至第10行,并将这些信息按第3个字段的数值大小进行排序;最后仅显示的各自的第1个字段; 2 3 [root@localhost /tmp]$ head -10 passwd | tail -5 | sort -n -k3 -t: | cut -d: -f1 4 lp 5 sync 6 shutdown 7 halt 8 mail
7、Linux文本处理三剑客
grep:文本过滤(模式:pattern)工具(grep,egrep,fgrep(不支持正则表达式))
sed:stream editor,文本编辑工具
awk:Linux上的实现gawk,文本报告生成器
① grep:Global search REgular expression and Print out the line
作用:文本搜索工具,根据用户指定的模式对目标文本逐行进行匹配检查,打印匹配到的行。
模式:由正则表达式字符及文本字符所编写的过滤条件。
REGEXP:由一类特殊字符文本字符所编写的模式,其中有些字符不表达字符字面意义,而表示控制或者通配的功能。
分为两类:
基本正则表达式;BRE
扩展正则表达式:ERE
注:通过正则表达式引擎对文本逐行匹配检测。
grep [option] pattern [file]:
选项:
--color=auto:对匹配到的文本着色显示
-v:显示不能够被pattern匹配到的行
-i:忽略字符大小写
-o:仅显示匹配到的字符串
-q:静默模式,不输出任何信息
注:
echo $? 命令结束后的退出码qw
0 :执行正常
1-255
-A #:显示匹配到的行的后几行
-B #:前几行
-C #:前后几行
-E:使用egrep,即扩展正则比倒是
egrep:
egrep = grep -E
1)正则表达式元字符:
基本正则表达式元字符:
字符匹配:
-
-
-
-
- .:匹配任意单个字符
- [] :匹配指定范围内的任意单个字符
- [^] :匹配指定范围外的任意单个字符
- [:digit:] .........跟glob一样
-
-
-
次数匹配:用在指定次数的字符后面,用于指定前面的字符要出现的次数
-
-
-
-
- * :匹配前面的字符任意次 工作在贪婪模式
- .* :任意长度的任意字符
- \? :匹配掐面的字符0或1次
- \+ :匹配前面的字符至少出现一次
- \{m\} :匹配前面的字符出现m次
- \{m,n\} :至少m次,最多n次
- \{,n\} :0-n次
-
-
-
位置锚定:
-
-
-
-
- ^ :行首锚定
- $ :行尾锚定
- ^pattern$ :用于模式匹配整行
- ^$ :空行
- ^[[:space:]]*$ :可能空行,可能空字符的行
- \< 或 \b :词首锚定
- \> 或 \b :词尾锚定
- \<pattern\> :整个单词
-
-
-
分组:
\(\) :将一个或多个字符捆绑在一起,当作一个整体进行处理
如: \(xy\)*ab \(c\|C\)at :cat或Cat
注:
分组括号中的模式匹配到的内容会被正则表达式引擎记录于内部的变量中,这些变量的命名方式为: \1,\2,\3
\1:从左侧起,第一个左括号以及与之匹配的右括号之间的模式所匹配到的字符:
\(ab\+\(xy\)*\) :
\1 :ab\+\(xy\)*
\2 :xy
后向引用:引用前面的分组括号中的模式所匹配到的字符(而非模式本身)
\| :或者
2)扩展的正则表达式元字符:
字符匹配:
. :任意单个字符
[] :字符集中的任意个
[^]:字符集外的任意个
次数匹配:
* :任意次
?:0-1次
+:至少一次
{m}:m次
{m,n}:m-n次
位置锚定:
^
$
\< \> \b \b (除了这个,基本都不用转义)
分组和引用
() \1 \2
或者
a|b C|cat C或cat
1 1、显示/proc/meminfo文件中以大小s开头的行;(要求:使用两种方式) 2 3 [root@localhost /tmp]$ grep '^\(s\|S\)' meminfo 4 SwapCached: 0 kB 5 SwapTotal: 2097148 kB 6 SwapFree: 2097148 kB 7 Shmem: 1044 kB 8 Slab: 78240 kB 9 SReclaimable: 15956 kB 10 SUnreclaim: 62284 kB 11 s: 12313KB 12 13 14 [root@localhost /tmp]$ grep '^[sS]' meminfo 15 SwapCached: 0 kB 16 SwapTotal: 2097148 kB 17 SwapFree: 2097148 kB 18 Shmem: 1044 kB 19 Slab: 78240 kB 20 SReclaimable: 15956 kB 21 SUnreclaim: 62284 kB 22 s: 12313KB 23 24 2、显示/etc/passwd文件中不以/bin/bash结尾的行; 25 [root@localhost /tmp]$ grep '\/bin\/bash$' passwd 26 root:x:0:0:root:/root:/bin/bash 27 jack3:x:506:100::/home/jack3:/bin/bash 28 jack:x:507:507::/home/jack:/bin/bash 29 tom:x:508:508::/home/tom:/bin/bash 30 alex:x:555:100::/home/alex:/bin/bash 31 jack2:x:556:556::/home/jack2:/bin/bash 32 tom2:x:557:557::/home/tom2:/bin/bash 33 34 35 3、显示/etc/passwd文件中ID号最大的用户的用户名; 36 sort -n -k3 -t: passwd | cut -d: -f1|tail -1 37 38 39 4、如果用户root存在,显示其默认的shell程序; 40 # id root &> /dev/null && grep "^root\>" /etc/passwd | cut -d: -f7 41 42 5、找出/etc/passwd中的两位或三位数; 43 # grep -o "\<[0-9]\{2,3\}\>" /etc/passwd 44 45 6、显示/etc/rc.d/rc.sysinit文件中,至少以一个空白字符开头的且后面存非空白字符的行; 46 # grep "^[[:space:]]\+[^[:space:]]" /etc/grub2.cfg 47 48 7、找出"netstat -tan"命令的结果中以'LISTEN'后跟0、1或多个空白字符结尾的行; 49 # netstat -tan | grep "LISTEN[[:space:]]*$" 50 51 8、添加用户bash、testbash、basher以及nologin(其shell为/sbin/nologin);而后找出/etc/passwd文件中用户名同shell名的行; 52 # grep "^\([[:alnum:]]\+\>\).*\1$" /etc/passwd
② sed:stream editor:
sed是一种流编辑器,它一次处理一行内容。处理时,把当前处理的行存储在临时缓冲区中,称为“模式空间”(pattern space),接着用sed命令处理缓冲区中的内容,处理完成后,把缓冲区的内容送往屏幕。然后读入下行,执行下一个循环。如果没有使诸如‘D’的特殊命令,那会在两个循环之间清空模式空间,但不会清空保留空间。这样不断重复,直到文件末尾。文件内容并没有改变,除非你使用重定向存储输出。
功能:主要用来自动编辑一个或多个文件,简化对文件的反复操作,编写转换程序等
格式:
sed [option] 'script' file ...
-n:静默模式,不输出模式空间内的内容,默认打印模式空间中的内容
-r :扩展的正则表达式
-f :文件,指定sed脚本文件
-e ‘script‘ -e ‘script’ :指定多个编辑指令
-i.bak :备份文件并原处编辑
编辑命令:
d:删除
p :打印
i \ :在被指定到的行前面插入文本
a \ :在被指定的行的后面插入文本
\n :换行
r 文件 :在指定位置吧另一个文件的内容插入
w 文件:将符合条件的所有行保存至指定的文件中
= :显示符合条件的行的行号
!:模式空间中匹配行取反处理
c :替换 sed ‘/root/c\superman’ /etc/passwd 但这是直接替换整行了
s/// :查找替换,支持使用其他分隔符,s@@@ s###
替换标记:
g:行内全局替换
p:显示替换成功的行
w /path/to/somefile :将替换成功的行保存至文件中
注: 还可以使用“&”引用前面查找时查找到的整个内容
地址定界:
1)不给地址:对全文进行处理
2)单地址:
#:指定的行,$:最后一行
/pattern/ : 被此模式所能匹配到的每一行
3)地址范围:
#,#
#,+#
/pat1/ ,/pat2/ :模式之间的
# ,/pat/ :第#行到模式匹配到的第一行结束
4)~ :步进:
1~2 奇数行
2~2 偶数行
注:sed的高级编辑命令
P:打印模式空间开端至\n内容,并追加到默认输出之前
h: 把模式空间中的内容覆盖至保持空间中
H:把模式空间中的内容追加至保持空间中
g: 从保持空间取出数据覆盖至模式空间
G:从保持空间取出内容追加至模式空间
x: 把模式空间中的内容与保持空间中的内容进行互换
n: 读取匹配到的行的下一行覆盖至模式空间
N:读取匹配到的行的下一行追加至模式空间
d: 删除模式空间中的行
D:如果模式空间包含换行符,则删除直到第一个换行符的模式空间中的文本,并不会读取新的输入行,而使用合成的模式空间重新启动循环。如果模式空间不包含换行符,则会像发出d命令那样启动正常的新循环
1 练习: 2 1)替换/etc/inittab文件中”id:3:initdefault:"一行中的数字为5 3 sed 's@\(id:\)[0-9]\(:initdefault\)@\15\2' /etc/inittab 4 2)删除/etc/init.d/funcions文件中的空白行 5 sed "/^$/d" /etc/init.d/funcions 6 3)删除/etc/inittab文件中位于行首的#; 7 sed 's@^#@@g' /etc/inittab 8 4)删除/etc/rc.d/rc.sysinit文件中以#后跟至少一个空白字符开头的行的行首的#和空白字符。 9 sed "s@^#[[:space:]]\{1,\}\@@g" /etc/rc.d/rc.sysinit 10 5)删除/boot/grub/grub.conf文件中行首的空白字符。 11 sed "s@^[[:space:]]\{1,\}@@g" /boot/grub/grub.conf 12 6)取出一个文件路径的目录名称,如/etc/sysconfig/network,其目录为/etc/sysconfig,功能类似dirname命令; 13 echo /etc/sysconfig/network | sed "s@[^/]\{1,\}/\?$@@"
③ awk:
Pawk:Aho, Weinberger, Kernighan,报告生成器,格式化文本输出
有多种版本:New awk(nawk),GNU awk( gawk)
gawk:模式扫描和处理语言
基本用法:
awk [options] ‘program’ var=value file…
awk [options] -f programfile var=value file…
awk [options] 'BEGIN{ action;… } pattern{ action;… } END{ action;… }' file ...
awk 程序通常由:BEGIN语句块、能够使用模式匹配的通用语句块、END语句块,共3部分组成
program通常是被单引号或双引号中
选项:
-F 指明输入时用到的字段分隔符
-v var=value: 自定义变量
基本格式:awk [options] 'program' file…
program:pattern{action statements;..}
pattern和action:
pattern部分决定动作语句何时触发及触发事件
BEGIN,END
action statements对数据进行处理,放在{}内指明
print, printf
分割符、域和记录
awk执行时,由分隔符分隔的字段(域)标记$1,$2..$n称为域标识。$0为所有域,注意:和shell中变量$符含义不同
文件的每一行称为记录
省略action,则默认执行 print $0 的操作
awk工作原理:
第一步:执行BEGIN{action;… }语句块中的语句
第二步:从文件或标准输入(stdin)读取一行,然后执行pattern{ action;… }语句块,它逐行扫描文件,从第一行到最后一行重复这个过程,直到文件全部被读取完毕。
第三步:当读至输入流末尾时,执行END{action;…}语句块
BEGIN语句块在awk开始从输入流中读取行之前被执行,这是一个可选的语句块,比如变量初始化、打印输出表格的表头等语句通常可以写在BEGIN语句块中
END语句块在awk从输入流中读取完所有的行之后即被执行,比如打印所有行的分析结果这类信息汇总都是在END语句块中完成,它也是一个可选语句块
pattern语句块中的通用命令是最重要的部分,也是可选的。如果没有提供pattern语句块,则默认执行{ print },即打印每一个读取到的行,awk读取的每一行都会执行该语句块
awk
格式: print item1, item2, ...
print要点:
(1) 逗号分隔符
(2) 输出的各item可以字符串,也可以是数值;当前记录的字段、变量或awk的表达式
(3) 如省略item,相当于print $0
示例:
awk '{print "hello,awk"}'
awk –F: '{print}' /etc/passwd
awk –F: ‘{print “wang”}’ /etc/passwd
awk –F: ‘{print $1}’ /etc/passwd
awk –F: ‘{print $0}’ /etc/passwd
awk –F: ‘{print $1”\t”$3}’ /etc/passwd
tail –3 /etc/fstab |awk ‘{print $2,$4}’
awk变量
变量:内置和自定义变量
FS:输入字段分隔符,默认为空白字符
awk -v FS=':' '{print $1,FS,$3}’ /etc/passwd
awk –F: '{print $1,$3,$7}’ /etc/passwd
OFS:输出字段分隔符,默认为空白字符
awk -v FS=‘:’ -v OFS=‘:’ '{print $1,$3,$7}’ /etc/passwd
RS:输入记录分隔符,指定输入时的换行符
awk -v RS=' ' ‘{print }’ /etc/passwd
ORS:输出记录分隔符,输出时用指定符号代替换行符
awk -v RS=' ' -v ORS='###'‘{print }’ /etc/passwd
NF:字段数量
awk -F: ‘{print NF}’ /etc/fstab,引用内置变量不用$
awk -F: '{print $(NF-1)}' /etc/passwd
NR:记录号
awk '{print NR}' /etc/fstab ; awk END'{print NR}' /etc/fstab
FNR:各文件分别计数,记录号
awk '{print FNR}' /etc/fstab /etc/inittab
FILENAME:当前文件名
awk '{print FILENAME}’ /etc/fstab
ARGC:命令行参数的个数
awk '{print ARGC}’ /etc/fstab /etc/inittab
awk ‘BEGIN {print ARGC}’ /etc/fstab /etc/inittab
ARGV:数组,保存的是命令行所给定的各参数
awk ‘BEGIN {print ARGV[0]}’ /etc/fstab /etc/inittab
awk ‘BEGIN {print ARGV[1]}’ /etc/fstab /etc/inittab
自定义变量:
自定义变量(区分字符大小写)
(1) -v var=value
(2) 在program中直接定义
示例:
awk -v test='hello gawk' '{print test}' /etc/fstab
awk -v test='hello gawk' 'BEGIN{print test}'
awk 'BEGIN{test="hello,gawk";print test}'
awk –F:‘{sex=“male”;print $1,sex,age;age=18}’ /etc/passwd
cat awkscript
{print script,$1,$2}
awk -F: -f awkscript script=“awk” /etc/passwd
printf命令:
格式化输出:printf “FORMAT”, item1, item2, ... (1) 必须指定FORMAT (2) 不会自动换行,需要显式给出换行控制符,\n (3) FORMAT中需要分别为后面每个item指定格式符 格式符:与item一一对应 %c: 显示字符的ASCII码 %d, %i: 显示十进制整数 %e, %E:显示科学计数法数值 %f:显示为浮点数 %g, %G:以科学计数法或浮点形式显示数值 %s:显示字符串 %u:无符号整数 %%: 显示%自身 修饰符: #[.#]:第一个数字控制显示的宽度;第二个#表示小数点后精度,%3.1f -: 左对齐(默认右对齐) %-15s +:显示数值的正负符号 %+d
awk -F: ‘{printf "%s",$1}’ /etc/passwd
awk -F: ‘{printf "%s\n",$1}’ /etc/passwd
awk -F: '{printf "%-20s %10d\n",$1,$3}' /etc/passwd
awk -F: ‘{printf "Username: %s\n",$1}’ /etc/passwd
awk -F: ‘{printf “Username: %s,UID:%d\n",$1,$3}’
/etc/passwd
awk -F: ‘{printf "Username: %15s,UID:%d\n",$1,$3}’
/etc/passwd
awk -F: ‘{printf "Username: %-15s,UID:%d\n",$1,$3}’
/etc/passwd
操作符:
算术操作符: x+y, x-y, x*y, x/y, x^y, x%y -x: 转换为负数 +x: 转换为数值 字符串操作符:没有符号的操作符,字符串连接 赋值操作符: =, +=, -=, *=, /=, %=, ^= ++, -- 下面两语句有何不同 awk ‘BEGIN{i=0;print ++i,i}’ awk ‘BEGIN{i=0;print i++,i}’
比较操作符: ==, !=, >, >=, <, <= 模式匹配符: ~:左边是否和右边匹配包含 !~:是否不匹配 示例: awk –F: '$0 ~ /root/{print $1}‘ /etc/passwd awk '$0~“^root"' /etc/passwd awk '$0 !~ /root/‘ /etc/passwd awk –F: ‘$3==0’ /etc/passwd
逻辑操作符:与&&,或||,非! 示例: awk –F: '$3>=0 && $3<=1000 {print $1}' /etc/passwd awk -F: '$3==0 || $3>=1000 {print $1}' /etc/passwd awk -F: ‘!($3==0) {print $1}' /etc/passwd awk -F: ‘!($3>=500) {print $3}’ /etc/passwd 函数调用: function_name(argu1, argu2, ...) 条件表达式(三目表达式): selector?if-true-expression:if-false-expression 示例: awk -F: '{$3>=1000?usertype="Common User":usertype="Sysadmin or SysUser";printf "%15s:%-s\n",$1,usertype}' /etc/passwd
awk Pattren:
PATTERN:根据pattern条件,过滤匹配的行,再做处理 (1)如果未指定:空模式,匹配每一行 (2) /regular expression/:仅处理能够模式匹配到的行,需要用/ /括起来 awk '/^UUID/{print $1}' /etc/fstab awk '!/^UUID/{print $1}' /etc/fstab (3) relational expression: 关系表达式,结果为“真”才会被处理 真:结果为非0值,非空字符串 假:结果为空字符串或0值 示例: awk -F: 'i=1;j=1{print i,j}' /etc/passwd awk ‘!0’ /etc/passwd ; awk ‘!1’ /etc/passwd awk –F: '$3>=1000{print $1,$3}' /etc/passwd awk -F: '$3<1000{print $1,$3}' /etc/passwd awk -F: '$NF=="/bin/bash"{print $1,$NF}' /etc/passwd awk -F: '$NF ~ /bash$/{print $1,$NF}' /etc/passwd 4) line ranges:行范围 startline,endline:/pat1/,/pat2/ 不支持直接给出数字格式 awk -F: ‘/^root\>/,/^nobody\>/{print $1}' /etc/passwd awk -F: ‘(NR>=10&&NR<=20){print NR,$1}' /etc/passwd (5) BEGIN/END模式 BEGIN{}: 仅在开始处理文件中的文本之前执行一次 END{}:仅在文本处理完成之后执行一次
示例:
awk -F : 'BEGIN {print "USER USERID"} {print $1":"$3} END{print "end file"}' /etc/passwd awk -F : '{print "USER USERID“;print $1":"$3} END{print "end file"}' /etc/passwd awk -F: 'BEGIN{print " USER UID \n--------------- "}{print $1,$3}' /etc/passwd awk -F: 'BEGIN{print " USER UID \n--------------- "}{print $1,$3}'END{print "=============="} /etc/passwd seq 10 |awk ‘i=0’ seq 10 |awk ‘i=1’ seq 10 | awk 'i=!i‘ seq 10 | awk '{i=!i;print i}‘ seq 10 | awk ‘!(i=!i)’ seq 10 |awk -v i=1 'i=!i'
awk action:
常用的action分类 (1) Expressions:算术,比较表达式等 (2) Control statements:if, while等 (3) Compound statements:组合语句 (4) input statements (5) output statements:print等
awk控制语句:
{ statements;… } 组合语句 if(condition) {statements;…} if(condition) {statements;…} else {statements;…} while(conditon) {statments;…} do {statements;…} while(condition) for(expr1;expr2;expr3) {statements;…} break continue delete array[index] delete array exit
awk 控制语句 if-else
语法:if(condition){statement;…}[else statement] if(condition1){statement1}else if(condition2){statement2} else{statement3} 使用场景:对awk取得的整行或某个字段做条件判断 示例: awk -F: '{if($3>=1000)print $1,$3}' /etc/passwd awk -F: '{if($NF=="/bin/bash") print $1}' /etc/passwd awk '{if(NF>5) print $0}' /etc/fstab awk -F: '{if($3>=1000) {printf "Common user: %s\n",$1} else {printf "root or Sysuser: %s\n",$1}}' /etc/passwd awk -F: '{if($3>=1000) printf "Common user: %s\n",$1; else printf "root or Sysuser: %s\n",$1}' /etc/passwd df -h|awk -F% '/^\/dev/{print $1}'|awk '$NF>=80{print $1,$5}‘ awk 'BEGIN{ test=100;if(test>90){print "very good"} else if(test>60){ print "good"}else{print "no pass"}}'
while循环 语法:while(condition){statement;…} 条件“真”,进入循环;条件“假”,退出循环 使用场景: 对一行内的多个字段逐一类似处理时使用 对数组中的各元素逐一处理时使用 示例: awk '/^[[:space:]]*linux16/{i=1;while(i<=NF) {print $i,length($i); i++}}' /etc/grub2.cfg awk '/^[[:space:]]*linux16/{i=1;while(i<=NF) {if(length($i)>=10) {print $i,length($i)}; i++}}' /etc/grub2.cfg
do-while循环 语法:do {statement;…}while(condition) 意义:无论真假,至少执行一次循环体 示例: awk 'BEGIN{ total=0;i=0;do{ total+=i;i++;}while(i<=100);print total}‘ for循环 语法:for(expr1;expr2;expr3) {statement;…} 常见用法: for(variable assignment;condition;iteration process) {for-body} 特殊用法:能够遍历数组中的元素 语法:for(var in array) {for-body} 示例: awk '/^[[:space:]]*linux16/{for(i=1;i<=NF;i++) {print $i,length($i)}}' /etc/grub2.cfg break [n] continue [n] next: 提前结束对本行处理而直接进入下一行处理(awk自身循环) awk -F: '{if($3%2!=0) next; print $1,$3}' /etc/passwd
awk数组:
若要遍历数组中的每个元素,要使用for循环 for(var in array) {for-body} 注意:var会遍历array的每个索引 示例: awk 'BEGIN{weekdays["mon"]="Monday";weekdays["tue"] ="Tuesday";for(i in weekdays) {print weekdays[i]}}‘ netstat -tan | awk '/^tcp/{state[$NF]++}END {for(i in state) { print i,state[i]}}' awk '{ip[$1]++}END{for(i in ip) {print i,ip[i]}}' /var/log/httpd/access_log
awk函数:
数值处理: rand():返回0和1之间一个随机数 awk 'BEGIN{srand(); for (i=1;i<=10;i++)print int(rand()*100) }' 字符串处理: length([s]):返回指定字符串的长度 sub(r,s,[t]):对t字符串进行搜索r表示的模式匹配的内容,并将第一个匹配的内容替换为s echo "2008:08:08 08:08:08" | awk 'sub(/:/,“-",$1)' gsub(r,s,[t]):对t字符串进行搜索r表示的模式匹配的内容,并全部替换为s所表示的内容 echo "2008:08:08 08:08:08" | awk ‘gsub(/:/,“-",$0)' split(s,array,[r]):以r为分隔符,切割字符串s,并将切割后的结果保存至array所表示的数组中,第一个索引值为1,第二个索引值为2,… netstat -tan | awk '/^tcp\>/{split($5,ip,":");count[ip[1]]++} END{for (i in count) {print i,count[i]}}'
8、vim使用:
1 vim编辑器 2 3 简介 4 vi: Visual Interface,文本编辑器 5 6 文本:ASCII, Unicode 7 8 文本编辑种类: 9 行编辑器: sed 10 全屏编辑器:nano, vi 11 12 VIM - Vi IMproved 13 14 使用 15 vim:模式化的编辑 16 17 基本模式: 18 编辑模式,命令模式 19 输入模式 20 末行模式: 21 内置的命令行接口 22 23 打开文件: 24 # vim [OPTION]... FILE... 25 +#: 打开文件后,直接让光标处于第#行的行首; 26 +/PATTERN:打开文件后,直接让光标处于第一个被PATTERN匹配到的行的行首; 27 28 模式转换: 29 编辑模式 --> 输入模式 30 i: insert, 在光标所在处输入; 31 a: append, 在光标所在处后面输入; 32 o: 在当前光标所在行的下方打开一个新行; 33 I:在当前光标所在行的行首输入; 34 A:在当前光标所在行的行尾输入; 35 O:在当前光标所在行的上方打开一个新行; 36 c 37 C 38 39 输入模式 --> 编辑模式 40 ESC 41 42 编辑模式 --> 末行模式 43 : 44 45 末行模式 --> 编辑模式 46 47 48 ESC 49 可视模式--->选择内容 50 按v V 51 52 关闭文件: 53 :q 退出 54 :q! 强制退出,丢弃做出的修改; 55 :wq 保存退出 56 :x 保存退出 57 :w /PATH/TO/SOMEWHERE 58 59 ZZ: 保存退出; 60 61 光标跳转: 62 63 字符间跳转: 64 h, j, k, l 65 h: 左 66 l: 右 67 j: 下 68 k: 上 69 70 #COMMAND:跳转由#指定的个数的字符; 71 72 单词间跳转: 73 w:下一个单词的词首 74 e:当前或下一单词的词尾 75 b:当前或前一个单词的词首 76 77 #COMMAND:由#指定一次跳转的单词数 78 79 行首行尾跳转: 80 ^: 跳转至行首的第一个非空白字符; 81 0: 跳转至行首; 82 $: 跳转至行尾; 83 84 行间移动: 85 #G:跳转至由#指定行; 86 G:最后一行; 87 1G, gg: 第一行; 88 89 句间移动: 90 ) 91 ( 92 93 段落间移动: 94 } 95 { 96 97 vim的编辑命令: 98 99 字符编辑: 100 x: 删除光标处的字符; 101 #x: 删除光标处起始的#个字符; 102 103 xp: 交换光标所在处的字符及其后面字符的位置; 104 105 替换命令(r, replace) 106 r: 替换光标所在处的字符 107 108 删除命令: 109 d: 删除命令,可结合光标跳转字符,实现范围删除; 110 d$: 111 d^: 112 d0: 113 114 dw 115 de 116 db 117 118 #COMMAND 119 120 dd: 删除光标所在的行; 121 #dd:多行删除; 122 123 粘贴命令(p, put, paste): 124 p:缓冲区存的如果为整行,则粘贴当前光标所在行的下方;否则,则粘贴至当前光标所在处的后面; 125 P:缓冲区存的如果为整行,则粘贴当前光标所在行的上方;否则,则粘贴至当前光标所在处的前面; 126 127 复制命令(y, yank): 128 y: 复制,工作行为相似于d命令; 129 y$ 130 y0 131 y^ 132 133 ye 134 yw 135 yb 136 137 #COMMAND 138 139 yy:复制行 140 #yy: 复制多行; 141 142 改变命令(c, change) 143 c: 修改 144 编辑模式 --> 输入模式 145 146 c$ 147 c^ 148 c0 149 150 cb 151 ce 152 cw 153 #COMMAND 154 155 cc:删除并输入新内容 156 #cc: 157 158 其它编辑操作 159 160 可视化模式: 161 v: 按字符选定 162 V:按行行定 163 164 Note:经常结合编辑命令; 165 d, c, y 166 167 撤消此前的编辑: 168 u(undo):撤消此前的操作; 169 #u: 撤消指定次数的操作; 170 171 撤消此前的撤消: 172 Ctrl+r 173 174 重复前一个编辑操作: 175 . 176 177 翻屏操作: 178 Ctrl+f: 向文件尾部翻一屏; 179 Ctrl+b: 向文件首部翻一屏; 180 181 Ctrl+d: 向文件尾部翻半屏; 182 Ctrl+u:向文件首部翻半屏; 183 184 vim自带的练习教程: 185 vimtutor 186 187 vim中的末行模式: 188 内建的命令行接口 189 190 (1) 地址定界 191 :start_pos,end_pos 192 #: 具体第#行,例如2表示第2行; 193 #,#: 从左侧#表示行起始,到右侧#表示行结尾; 194 #,+#: 从左侧#表示的行起始,加上右侧#表示的行数; 195 .: 当前行 196 $: 最后一行 197 .,$-1 198 %:全文, 相当于1,$ 199 200 /pat1/,/pat2/: 201 从第一次被pat1模式匹配到的行开始,一直到第一次被pat2匹配到的行结束; 202 #,/pat/ 203 /pat/,$ 204 205 使用方式: 206 后跟一个编辑命令 207 d 208 y 209 w /PATH/TO/SOMEWHERE: 将范围内的行另存至指定文件中; 210 r /PATH/FROM/SOMEFILE:在指定位置插入指定文件中的所有内容; 211 212 (2) 查找 213 /PATTERN:从当前光标所在处向文件尾部查找; 214 ?PATTERN:从当前光标所在处向文件首部查找; 215 n:与命令同方向; 216 N:与命令反方向; 217 218 (3) 查找并替换 219 s: 在末行模式下完成查找替换操作 220 s/要查找的内容/替换为的内容/修饰符 221 要查找的内容:可使用模式 222 替换为的内容:不能使用模式,但可以使用\1, \2, ...等后向引用符号;还可以使用“&”引用前面查找时查找到的整个内容; 223 修饰符: 224 i: 忽略大小写 225 g: 全局替换;默认情况下,每一行只替换第一次出现; 226 227 查找替换中的分隔符/可替换为其它字符,例如 228 s@@@ 229 s### 230 231 练习: 232 1、复制/etc/grub2.cfg至/tmp/目录,用查找替换命令删除/tmp/grub2.cfg文件中的行首的空白字符; 233 %s/^[[:space:]]\+//g 234 235 2、复制/etc/rc.d/init.d/functions文件至/tmp目录,用查找替换命令为/tmp/functions的每行开头为空白字符的行的行首添加一个#号; 236 :%s/^[[:space:]]/#&/ 237 238 多文件模式: 239 vim FILE1 FILE2 FILE3 ... 240 :next 下一个 241 :prev 前一个 242 :first 第一个 243 :last 最后一个 244 245 :wall 保存所有 246 :qall 退出所有 247 248 窗口分隔模式: 249 vim -o|-O FILE1 FILE2 ... 250 -o: 水平分割 251 -O: 垂直分割 252 253 在窗口间切换:Ctrl+w, Arrow 254 255 单文件窗口分割: 256 Ctrl+w,s: split, 水平分割 257 Ctrl+w,v: vertical, 垂直分割 258 259 定制vim的工作特性: 260 配置文件:永久有效 261 全局:/etc/vimrc 262 个人:~/.vimrc 263 264 末行:当前vim进程有效 265 266 (1) 行号 267 显示:set number, 简写为set nu 268 取消显示:set nonumber, 简写为set nonu 269 (2) 括号匹配 270 匹配:set showmatch, 简写为set sm 271 取消:set nosm 272 (3) 自动缩进 273 启用:set ai 274 禁用:set noai 275 (4) 高亮搜索 276 启用:set hlsearch 277 禁用:set nohlsearch 278 (5) 语法高亮 279 启用:syntax on 280 禁用:syntax off 281 (6) 忽略字符的大小写 282 启用:set ic 283 不忽略:set noic 284 (7)set list 285 286 获取帮助: 287 :help 288 :help subject 289 290 问题:如何设置tab缩进为4个字符? 291 292 练习: 293 1、复制/etc/rc.d/init.d/functions文件至/tmp目录;替换/tmp/functions文件中的/etc/sysconfig/init为/var/log; 294 2、删除/tmp/functions文件中所有以#开头,且#后面至少有一个空白字符的行的行首的#号;
第六节:软件管理
1、软件运行环境:
包管理器:
二进制文件、库文件、配置文件、帮助文件
debian:deb文件, dpkg包管理器
redhat: rpm文件, rpm包管理器
rpm: Redhat Package Manager
RPM Package Manager
包命名:
源代码:name-VERSION.tar.gz|bz2|xz
VERSION: major.minor.release
rpm包命名方式:
name-VERSION-release.arch.rpm
例:bash-4.2.46-19.el7.x86_64.rpm
VERSION: major.minor.release
release:release.OS
常见的arch:
x86: i386, i486, i586, i686
x86_64: x64, x86_64, amd64 powerpc: ppc
跟平台无关:noarch
包命名和工具:
包:分类和拆包
Application-VERSION-ARCH.rpm: 主包
Application-devel-VERSION-ARCH.rpm 开发子包
Application-utils-VERSION-ARHC.rpm 其它子包
Application-libs-VERSION-ARHC.rpm 其它子包
包之间:可能存在依赖关系,甚至循环依赖
解决依赖包管理工具:
yum:rpm包管理器的前端工具
apt-get:deb包管理器前端工具
zypper: suse上的rpm前端管理工具
dnf: Fedora 18+ rpm包管理器前端管理工具
库文件:
查看二进制程序所依赖的库文件
ldd /PATH/TO/BINARY_FILE
管理及查看本机装载的库文件
ldconfig 加载库文件
/sbin/ldconfig -p: 显示本机已经缓存的所有可用库文件名及文件路径映射关系
配置文件:/etc/ld.so.conf, /etc/ld.so.conf.d/*.conf
缓存文件:/etc/ld.so.cache
包管理器:
程序包管理器:
功能:将编译好的应用程序的各组成文件打包一个或几个程序包文件,从而方便快捷地实现程序包的安装、卸载、查询、升级和校验等管理操作
包文件组成 (每个包独有)
RPM包内的文件
RPM的元数据,如名称,版本,依赖性,描述等
安装或卸载时运行的脚本
数据库(公共):/var/lib/rpm
程序包名称及版本
依赖关系
功能说明
包安装后生成的各文件路径及校验码信息
程序包来源:
管理程序包的方式:
使用包管理器:rpm
使用前端工具:yum, dnf
获取程序包的途径:
(1) 系统发版的光盘或官方的服务器;
CentOS镜像:
https://www.centos.org/download/
http://mirrors.aliyun.com
http://mirrors.sohu.com
http://mirrors.163.com
(2) 项目官方站点
(3) 第三方组织:
Fedora-EPEL:
Extra Packages for Enterprise Linux
Rpmforge:RHEL推荐,包很全
搜索引擎:
http://pkgs.org
http://rpmfind.net
http://rpm.pbone.net
https://sourceforge.net/
(4) 自己制作
注意:第三方包建议要检查其合法性
来源合法性,程序包的完整性
2、rpm包管理
1)CentOS系统上使用rpm命令管理程序包:
安装、卸载、升级、查询、校验、数据库维护
安装:
rpm {-i|--install} [install-options] PACKAGE_FILE…
-v: verbose
-vv:
-h: 以#显示程序包管理执行进度
rpm -ivh PACKAGE_FILE ...
2)rpm包安装
[install-options]
--test: 测试安装,但不真正执行安装,即dry run模式
--nodeps:忽略依赖关系
--replacepkgs | replacefiles
--nosignature: 不检查来源合法性
--nodigest:不检查包完整性
--noscripts:不执行程序包脚本
%pre: 安装前脚本; --nopre
%post: 安装后脚本; --nopost
%preun: 卸载前脚本; --nopreun
%postun: 卸载后脚本; --nopostun
3) rpm包升级
rpm {-U|--upgrade} [install-options] PACKAGE_FILE...
rpm {-F|--freshen} [install-options] PACKAGE_FILE...
upgrade:安装有旧版程序包,则“升级”
如果不存在旧版程序包,则“安装”
freshen:安装有旧版程序包,则“升级”
如果不存在旧版程序包,则不执行升级操作
rpm -Uvh PACKAGE_FILE ...
rpm -Fvh PACKAGE_FILE ...
--oldpackage:降级
--force: 强制安装
4)升级注意事项
注意:
(1) 不要对内核做升级操作;Linux支持多内核版本并存,因此,对直接安装新版本内核
(2) 如果原程序包的配置文件安装后曾被修改,升级时,新版本的提供的同一个配置文件并不会直接覆盖老版本的配置文件,而把新版本的文件重命名(FILENAME.rpmnew)后保留
5)包查询
rpm {-q|--query} [select-options] [query-options]
[select-options]
-a: 所有包
-f: 查看指定的文件由哪个程序包安装生成
-p rpmfile:针对尚未安装的程序包文件做查询操作
--whatprovides CAPABILITY:查询指定的CAPABILITY由哪个包所提供
--whatrequires CAPABILITY:查询指定的CAPABILITY被哪个包所依赖
rpm2cpio 包文件|cpio –itv 预览包内文件
rpm2cpio 包文件|cpio –id “*.conf” 释放包内文件
[query-options]
--changelog:查询rpm包的changelog
-c: 查询程序的配置文件
-d: 查询程序的文档
-i: information
-l: 查看指定的程序包安装后生成的所有文件
--scripts:程序包自带的脚本
--provides: 列出指定程序包所提供的CAPABILITY
-R: 查询指定的程序包所依赖的CAPABILITY
常用查询用法:
-qi PACKAGE, -qf FILE, -qc PACKAGE, -ql PACKAGE, -qd PACKAGE
-qpi PACKAGE_FILE, -qpl PACKAGE_FILE, ...
-qa
6) 包卸载:
rpm {-e|--erase} [--allmatches] [--nodeps] [--noscripts] [--notriggers] [--test] PACKAGE_NAME ...
7) 包校验
rpm {-V|--verify} [select-options] [verify-options]
S file Size differs
M Mode differs (includes permissions and file type)
5 digest (formerly MD5 sum) differs
D Device major/minor number mismatch
L readLink(2) path mismatch
U User ownership differs
G Group ownership differs
T mTime differs
P capabilities differ
包来源合法性验正及完整性验正
完整性验正:SHA256
来源合法性验正:RSA
公钥加密
对称加密:加密、解密使用同一密钥
非对称加密:密钥是成对儿的
public key: 公钥,公开所有人
secret key: 私钥, 不能公开
导入所需要公钥
rpm -K|checksig rpmfile 检查包的完整性和签名
rpm --import /etc/pki/rpm-gpg/RPM-GPG-KEY-CentOS-7
CentOS 7发行版光盘提供:RPM-GPG-KEY-CentOS-7
rpm -qa “gpg-pubkey*”
8)rpm数据库
数据库重建:
/var/lib/rpm
rpm {--initdb|--rebuilddb}
initdb: 初始化
如果事先不存在数据库,则新建之
否则,不执行任何操作
rebuilddb:重建已安装的包头的数据库索引目录
3、yum管理
1)yum
yum repository: yum repo,存储了众多rpm包,以及包的相关的元数据文件(放置于特定目录repodata下)
文件服务器:
http:// https:// ftp:// file://
2) yum 配置文件
1 yum客户端配置文件: 2 /etc/yum.conf:为所有仓库提供公共配置 3 /etc/yum.repos.d/*.repo:为仓库的指向提供配置 4 仓库指向的定义: 5 [repositoryID] 6 name=Some name for this repository 7 baseurl=url://path/to/repository/ 8 enabled={1|0} 9 gpgcheck={1|0} 10 gpgkey=URL 11 enablegroups={1|0} 12 failovermethod={roundrobin|priority} 13 roundrobin:意为随机挑选,默认值 14 priority:按顺序访问 15 cost= 默认为1000
3)yum仓库
1 yum的repo配置文件中可用的变量: 2 $releasever: 当前OS的发行版的主版本号 3 $arch: 平台,i386,i486,i586,x86_64等 4 $basearch:基础平台;i386, x86_64 5 $YUM0-$YUM9:自定义变量 6 实例: 7 http://server/centos/$releasever/$basearch/ 8 http://server/centos/7/x86_64 9 http://server/centos/6/i384
4) yum源
1 阿里云repo文件: 2 http://mirrors.aliyun.com/repo/ 3 CentOS系统的yum源 4 阿里云:https://mirrors.aliyun.com/centos/$releasever/os/x86_64/ 5 教学环境: 6 http://172.16.0.1/cobbler/ks_mirror/$releasever/ 7 EPEL的yum源: 8 阿里云: 9 https://mirrors.aliyun.com/epel/$releasever/x86_64 10 教学环境: 11 http://172.16.0.1/fedora-epel/$releasever/x86_64/
5)yum命令
1 yum命令的用法: 2 yum [options] [command] [package ...] 3 显示仓库列表: 4 yum repolist 5 显示程序包: 6 yum list 7 yum list [all | glob_exp1] [glob_exp2] [...] 8 yum list {available|installed|updates} [glob_exp1] [...] 9 安装程序包: 10 yum install package1 [package2] [...] 11 yum reinstall package1 [package2] [...] (重新安装) 12 13 升级程序包: 14 yum update [package1] [package2] [...] 15 yum downgrade package1 [package2] [...] (降级) 16 检查可用升级: 17 yum check-update 18 卸载程序包: 19 yum remove | erase package1 [package2] [...] 20 21 查看程序包information: 22 yum info [...] 23 查看指定的特性(可以是某文件)是由哪个程序包所提供: 24 yum provides | whatprovides feature1 [feature2] [...] 25 清理本地缓存: 26 清除/var/cache/yum/$basearch/$releasever缓存 27 yum clean [ packages | metadata | expire-cache | rpmdb | plugins | all ] 28 构建缓存: 29 yum makecache 30 31 32 搜索:yum search string1 [string2] [...] 33 以指定的关键字搜索程序包名及summary信息 34 查看指定包所依赖的capabilities: 35 yum deplist package1 [package2] [...] 36 查看yum事务历史: 37 yum history [info|list|packages-list|packages-info| 38 summary|addon-info|redo|undo| 39 rollback|new|sync|stats] 40 yum history 41 yum history info 6 42 yum history undo 6 43 日志 :/var/log/yum.log 44 45 安装及升级本地程序包: 46 yum localinstall rpmfile1 [rpmfile2] [...] 47 (用install替代) 48 yum localupdate rpmfile1 [rpmfile2] [...] 49 (用update替代) 50 包组管理的相关命令: 51 yum groupinstall group1 [group2] [...] 52 yum groupupdate group1 [group2] [...] 53 yum grouplist [hidden] [groupwildcard] [...] 54 yum groupremove group1 [group2] [...] 55 yum groupinfo group1 [...] 56 57 yum的命令行选项: 58 --nogpgcheck:禁止进行gpg check 59 -y: 自动回答为“yes” 60 -q:静默模式 61 --disablerepo=repoidglob:临时禁用此处指定的repo 62 --enablerepo=repoidglob:临时启用此处指定的repo 63 --noplugins:禁用所有插件
4、系统光盘yum仓库
1 系统安装光盘作为本地yum仓库: 2 (1) 挂载光盘至某目录,例如/mnt/cdrom 3 mount /dev/cdrom /mnt/cdrom 4 (2) 创建配置文件 5 [CentOS7] 6 name= 7 baseurl= 8 gpgcheck= 9 enabled= 10 创建yum仓库: 11 createrepo [options] <directory>
5、编译安装
1 程序包编译安装: 2 Application-VERSION-release.src.rpm --> 安装后,使用rpmbuild命令制作成二进制格式的rpm包,而后再安装 3 源代码-->预处理-->编译-->汇编-->链接-->执行 4 源代码组织格式: 5 多文件:文件中的代码之间,很可能存在跨文件依赖关系 6 C、C++:make 项目管理器 7 configure脚本 --> Makefile.in --> Makefile 8 java: maven
1 C语言源代码编译安装三步骤: 2 1、./configure 3 (1) 通过选项传递参数,指定启用特性、安装路径等;执行时会参考用户的指定以及Makefile.in文件生成Makefile 4 (2) 检查依赖到的外部环境,如依赖的软件包 5 2、make 根据Makefile文件,构建应用程序 6 3、make install 复制文件到相应路径 7 开发工具: 8 autoconf: 生成configure脚本 9 automake:生成Makefile.in 10 注意:安装前查看INSTALL,README 11 12 开源程序源代码的获取: 13 官方自建站点: 14 apache.org (ASF:Apache Software Foundation) 15 mariadb.org 16 ... 17 代码托管: 18 SourceForge.net 19 Github.com 20 code.google.com 21 c/c++编译器: gcc (GNU C Complier) 22 23 24 编译C源代码: 25 准备:提供开发工具及开发环境 26 开发工具:make, gcc等 27 开发环境:开发库,头文件 28 glibc:标准库 29 实现:通过“包组”提供开发组件 30 Development Tools 31 Server Platform Development 32 33 34 35 第一步:configure脚本 36 选项:指定安装位置、指定启用的特性 37 --help: 获取其支持使用的选项 38 选项分类: 39 安装路径设定: 40 --prefix=/PATH: 指定默认安装位置,默认为/usr/local/ 41 --sysconfdir=/PATH:配置文件安装位置 42 System types:支持交叉编译 43 44 45 Optional Features: 可选特性 46 --disable-FEATURE 47 --enable-FEATURE[=ARG] 48 Optional Packages: 可选包 49 --with-PACKAGE[=ARG],依赖包 50 --without-PACKAGE,禁用依赖关系 51 注意:通常被编译操作依赖的程序包,需要安装此程序包的“开发”组件,其包名一般类似于name-devel-VERSION 52 53 第二步:make 54 第三步:make install 55 56 57 58 安装后的配置: 59 (1) 二进制程序目录导入至PATH环境变量中 60 编辑文件/etc/profile.d/NAME.sh 61 export PATH=/PATH/TO/BIN:$PATH 62 (2) 导入库文件路径 63 编辑/etc/ld.so.conf.d/NAME.conf 64 添加新的库文件所在目录至此文件中 65 让系统重新生成缓存: 66 ldconfig [-v] 67 68 (3) 导入头文件 69 基于链接的方式实现: 70 ln -sv 71 (4) 导入帮助手册 72 编辑/etc/man.config|man_db.conf文件 73 添加一个MANPATH

 浙公网安备 33010602011771号
浙公网安备 33010602011771号